摘要
本文介绍常见的分布式共识算法,使用场景,以及相关已经落地了的程序或框架
1. 为什么要分布式共识算法
在分布式系统中,不同节点之间可能存在网络延迟、故障等原因导致彼此之间存在数据不一致的情况,为了保证分布式系统中的数据一致性,因此需要引入共识算法。
在共识算法中,节点通过相互通信来传递数据,并根据一定的规则进行数据处理和验证。一旦多个节点达成一致,系统就会根据达成的共识状态来执行相应的操作。
例如Paxos算法、Raft算法、ZAB等。
2. 算法对比
Paxos和Raft都是强一致性算法,ZAB是最终一致性。
Raft算法中只有leader对外提供服务,follower仅仅是作为副本,也就是一个Raft集群的性能与集群节点数量无关,至于leader的性能有关(可以通过mutil raft提高系统性能,注意是提高整个系统的性能而不是提高单个raft集群的性能)
ZAB算法和Raft算法很详细,都有领导选举和日志复制过程。ZAB中follower节点是可以读的,而写都经过leader,这样就导致哪怕集群达成共识(过半数节点同步了leader的数据),依旧存在某些节点还未达成与leader数据同步,可能存在读取旧数据。
raft与zab的详细对比可以参考:https://www.zhihu.com/question/28242561
Paxos是强一致的,算法比较难理解就不多阐述
3.共识算法的落地
刚刚讲的都是理论算法,大家需要实现这些算法到具体的应用中,不同的系统虽然使用的是同一个算法,但是具体细节上可能会有差异(例如HDFS是复现GFS论文的产物),但是核心不会变,分布式共识算法
我们知道节点数据同步需要同步,但是这些强一致性算法并不适用于数据库主从同步(OLAP或OLTP系统)。原因就是强一致性必然会造成大量的性能损失,这是DB无法接受的。
那么哪些场景需要使用强一致性的算法呢?注册中心
为什么注册中心需要分布式共识算法?
因为注册中心原本就是一个小的存储系统,存储了集群中(或者微服务集群)所有的配置信息,并且可能频繁出现服务或者节点的上下线,需要保证注册中心的高可用则必须要副本冗余,有了副本必然就出现主从数据同步,并且需要强一致性保证服务发现不会出错,由于存储的数据量很小,所有强一致性造成的性能损失也是可以接受的。
4. 常见落地
常见的注册中心框架有nacos(spring cloud),eureka(spring cloud),zookeeper(hadoop),consul,etcd(k8s)
不同注册中心的选型和对比可以看这:https://juejin.cn/post/7068065361312088095
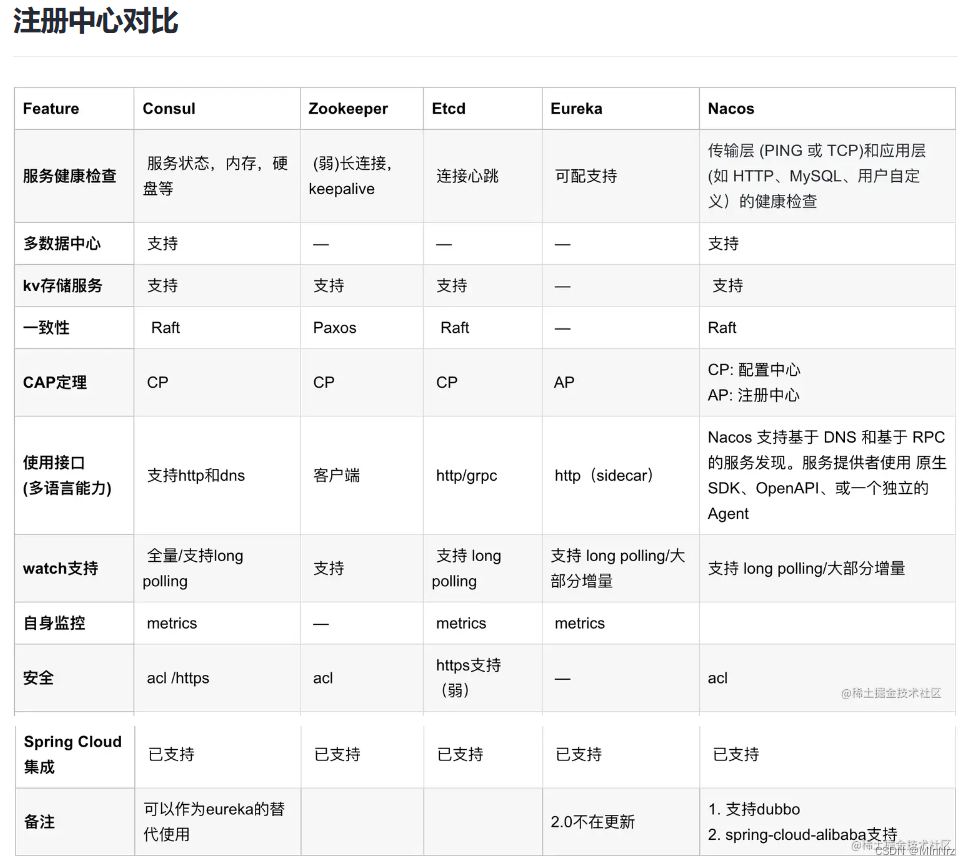
上图中zookeeper应该是使用ZAB算法,ZAB算是Paxos的一种演变。
刚刚说了ZAB并不能保证强一致性,为什么这里zookeep又是CP,可以保证强一致性呢?
原因:zookeeper在实现ZAB后,还加入了一些特殊操作,可以保证zookeeper的强一致性,但是ZAB算法理论并不是强一致性,这就是算法理论和落地之间的不同
eureka使用的是自己设计的一套共识算法,不能保证强一致性,这里不展开了。
具体可以看:https://blog.csdn.net/trntaken/article/details/108949114
zookeeper原生客户端API和Curator客户端都提供了该sync()方法,调用sync()方法之后,zookeeper集群会保证集群所有节点数据都是一致性的,此时客户端再去任意节点读取数据,都能读取最新的数据。
如何选择一个合适的注册中心呢?
这里涉及到技术选型,个人认为主要关注 是否满足需求,社区活跃度,使用成本这几个方面,就不展开了。










![解决使用WebTestClient访问接口报[185c31bb] 500 Server Error for HTTP GET “/**“](https://img-blog.csdnimg.cn/3dac1dcd794f4a03aafb03d6ef634b6a.png#pic_center)