说明: Elasticsearch不仅是一个大数据搜索引擎,也是一个大数据分析引擎。它的聚集(aggregation)统计的REST端点可用于实现与统计分析有关的功能。Elasticsearch提供的聚集分为三大类。
- 度量聚集(Metric aggregation):度量聚集可以用于计算搜索结果在某个字段上的数量统计指标,比如平均值、最大值、最小值、总和等。
- 桶聚集(Bucket aggregation):桶聚集可以在某个字段上划定一些区间,每个区间是一个“桶”,然后按照搜索结果的文档内容把文档归类到它所属的桶中,统计的结果能明确每个桶中有多少文档。桶聚集还可以嵌套其他的桶聚集或者度量聚集来进行一些复杂的指标计算。
- 管道聚集(Pipeline aggregation):管道聚集就是把桶聚集统计的结果作为输入来继续做聚集统计,会在桶聚集的结果中追加一些额外的统计数据。
1.1、平均值聚集
平均值聚集用来计算索引中某个数值字段的平均值,对索引sougoulog的字段rank求平均值的聚集请求如下。
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"rank_avg": {
"avg": {
"field": "rank",
"missing": 0
}
}
}
}
在这个请求中,aggs的参数使用了一个类型为avg的聚集,它会对rank字段求平均值,请求中的missing参数表示如果遇到rank字段为null的文档,则当作0计算。这一聚集被命名为rank_avg,当然得新建索引,添加数据。
1.2 最大值和最小值聚集
使用最大值和最小值聚集可以快速地得到搜索结果中某个数值字段的最大值、最小值,例如,获取rank字段的最大值的请求如下。
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"rank_max": {
"max": {
"field": "rank",
"missing": 0
}
}
}
}
同理,如果要得到rank字段的最小值,把聚集类型设置为min即可。
1.3 求和聚集
与平均值聚集类似,求和聚集可以让搜索结果在某个数值字段上求和。
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"rank_sum": {
"sum": {
"field": "rank",
"missing": 0
}
}
}
}
1.4 统计聚集统计
聚集可以一次性返回搜索结果在某个数值字段上的最大值、最小值、平均值、个数、总和。
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"rank_stats": {
"stats": {
"field": "rank",
"missing": 0
}
}
}
}
2.1 百分比聚集
百分比聚集用于近似地查看搜索结果中某个字段的百分比分布数据,你可以根据搜索结果清晰地看出某个值以内的数据在整体数据集中的占比。例如,对sougoulog的rank字段做百分比聚集的请求如下。
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"rank_percent": {
"percentiles": {
"field": "rank"
}
}
}
}
2.2 百分比等级聚集
百分比等级聚集跟百分比聚集的参数恰好相反,传入一组值,就可以看到这个值以内的数据占整体数据的百分比。例如:
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"percent_ranks": {
"percentile_ranks": {
"field": "rank",
"values": [ 10, 50 ]
}
}
}
}
在这个聚集请求中,把聚集类型设置为percentile_ranks表示发起百分比等级聚集,values用来设置需要查看的rank值,可以得到以下结果。
"aggregations" : {
"percent_ranks" : {
"values" : {
"10.0" : 82.98,
"50.0" : 94.22
}
}
}
这个结果表明,有82.98%的文档rank值小于等于10,有94.22%的文档rank值小于等于50。
2 桶聚集
桶聚集会按照某个字段划分出一些区间,把搜索结果的每个文档按照字段所在的区间划分到桶中,桶聚集会返回每个桶拥有的文档数目。桶的数目既可以用参数确定,也可以在执行过程中按照数据内容动态生成。桶的默认上限数目是65535,返回的桶数目超过这个数目会报错。另外,桶聚集可以嵌套其他的聚集来得到一些复杂的统计结果,度量聚集是不能嵌套其他子聚集的。
2.1 范围聚集范围
聚集需要你提供一组左闭右开的区间,在返回的结果中会得到搜索结果的某个字段落在每个区间的文档数目,参数from用于提供区间下界,to用于提供区间上界。统计的字段既可以是数值类型的字段也可以是日期类型的字段。例如:
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"range_rank": {
"range": {
"field": "rank",
"ranges": [
{
"to": 20
},
{
"from": 20,
"to": 50
},
{
"from": 50
}
]
}
}
}
}
此时的聚集类型为range,field设置了统计的字段为rank,ranges提供区间内容,得到的结果如下。
"aggregations" : {
"range_rank" : {
"buckets" : [
{
"key" : "*-20.0",
"to" : 20.0,
"doc_count" : 8895
},
{
"key" : "20.0-50.0",
"from" : 20.0,
"to" : 50.0,
"doc_count" : 521
},
{
"key" : "50.0-*",
"from" : 50.0,
"doc_count" : 584
}
]
}
}
这个结果表示,有8895个文档的rank值小于20,有521个文档的rank值大于等于20小于50,rank值大于等于50的文档有584个。
2.2 日期范围聚集
日期范围聚集是一种特殊的范围聚集,它要求统计的字段类型必须是日期类型,在索引test-3-2-1中保存的日期字段born用的是UTC时间,下面的代码会实现在这个born字段上做日期范围聚集。
POST test-3-2-1/_search
{
"query": {
"match_all": {}
},
"size": 10,
"aggs": {
"range_rank": {
"date_range": {
"field": "born",
"ranges": [
{
"from": "2020-09-11 00:00:00",
"to": "2020-10-11 00:00:00"
},
{
"from": "2020-10-11 00:00:00",
"to": "2020-11-11 00:00:00"
}
]
}
}
}
}
2.3 直方图聚集
直方图聚集经常用于做一些柱状图和折线图的展示,它可以选择一个数值或日期字段,然后根据字段的最小值和区间步长生成一组区间,统计出每个区间的文档数目。例如:
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"histogram_rank": {
"histogram": {
"field": "rank",
"interval": 400,
"extended_bounds": {
"min": 0,
"max": 1500
}
}
}
}
}
上面的请求使用extended_bounds中的max设置区间的上限,使用min设置区间的下限
"aggregations" : {
"histogram_rank" : {
"buckets" : [
{
"key" : 0.0,
"doc_count" : 9760
},
{
"key" : 400.0,
"doc_count" : 9
},
{
"key" : 800.0,
"doc_count" : 231
},
{
"key" : 1200.0,
"doc_count" : 0
}
]
}
}
0表示0-400的数据,400表示4000-800的数据,其他依次类推。
2.4 日期直方图聚集
日期直方图聚集的功能和直方图聚集的基本一样,但它只能在日期字段上做聚集,常用于做时间维度的统计分析。使用它可以非常方便地设置时间间隔,既可以是固定长度的时间间隔,也可以是日历时间间隔,例如你想了解每个月文档的数量分布,由于大小月的关系,应该把时间间隔设置为month,而不是固定为30天。参数calendar_interval用于设置日历时间间隔,可选配置如下。
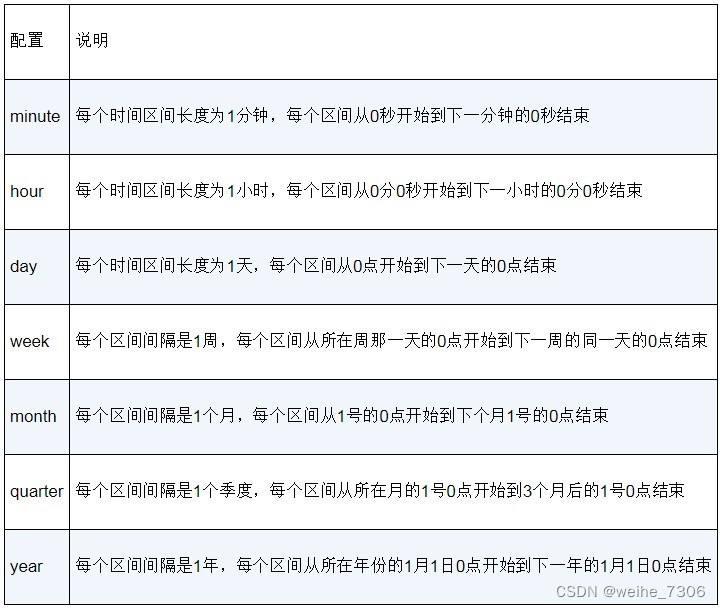
下面来尝试实现日期直方图聚集,只需要传入时间间隔就可以切分区间,不用像范围聚集那样需传入每个区间的边界。
POST test-3-2-1/_search
{
"query": {
"match_all": {}
},
"size": 10,
"aggs": {
"range_rank": {
"date_histogram": {
"field": "born",
"calendar_interval": "month",
"time_zone": "+08:00"
}
}
}
}
2.5 缺失聚集
使用缺失聚集可以很方便地统计出索引中某个字段缺失或者为空的文档数量。例如:
POST test-3-2-1/_search
{
"query": {
"match_all": {}
},
"size": 10,
"aggs": {
"miss": {
"missing": {
"field": "age"
}
}
}
}
该聚集请求直接返回age字段为空的文档数量。
2.6 过滤器聚集
过滤器聚集往往作为其他聚集的父聚集使用,它可以在其他的聚集开始之前去掉一些文档使其不纳入统计,但是过滤器聚集的过滤条件对搜索结果不起作用。也就是说,它只过滤聚集结果,不过滤搜索结果。例如:
POST test-3-2-1/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"filteraggs": {
"filter": {
"term": {
"name.keyword": "张三"
}
},
"aggs": {
"names": {
"terms": {
"field": "name.keyword",
"size": 10
}
}
}
}
}
}
在这个嵌套聚集请求中,先使用过滤器聚集只保留姓名为“张三”的文档,然后嵌套了词条聚集,聚集的结果只出现一个桶,但是搜索结果还是会返回所有的文档。这里设置了size为0没有展示搜索详情,但是如下所示total已经返回了全部文档总数。
2.7 多过滤器聚集
跟过滤器聚集相比,多过滤器聚集允许添加多个过滤条件,每个条件生成一个桶,聚集结果会返回每个桶匹配的文档数。你还可以把不属于任何过滤器的文档全部放入一个名为“other”的桶。例如:
POST test-3-2-1/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"filtersaggs": {
"filters": {
"other_bucket": true,
"filters": {
"zhang": {
"match": {
"name": "张"
}
},
"wang": {
"match": {
"name": "王"
}
}
}
}
}
}
}
这个请求定义了两个过滤条件,分别用match搜索姓名包含“张”和“王”的文档,搜索的结果数会各自返回到桶中,other_bucket参数设置为true表示显示不属于任何过滤器的文档数到名为“other”的桶中
3、管道聚集
前面谈到的聚集都是对索引的文档数据进行统计,但是管道聚集统计的对象不是索引中的文档数据,它是对桶聚集产生的结果做进一步聚集从而得到一些新的统计结果。管道聚集需要你提供一个桶聚集的相对路径来确定统计的桶对象。根据管道聚集出现的位置,管道聚集可以分为父管道聚集和兄弟管道聚集。
3.1 平均桶聚集
假如你通过日期直方图聚集或直方图聚集产生了3个桶,现在你想对这3个桶的统计值取平均值并做展示,这时候就可以使用平均桶聚集,例如:
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"date": {
"date_histogram": {
"field": "visittime",
"fixed_interval": "4m"
},
"aggs": {
"rank_avg": {
"avg": {
"field": "rank"
}
}
}
},
"rank_sum":{
"avg_bucket": {
"buckets_path": "date>rank_avg"
}
}
}
}
“buckets_path”: "date>rank_avg"表示执行顺序,先用date进行时间分割,后面都数据求平均值。
.3.2 求和桶聚集
除了可以对桶聚集的值求平均值,还可以使用sum_bucket对多个桶的值求和。例如:
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"date": {
"date_histogram": {
"field": "visittime",
"fixed_interval": "4m"
},
"aggs": {
"rank_sum": {
"sum": {
"field": "rank"
}
}
}
},
"rank_sum":{
"sum_bucket": {
"buckets_path": "date>rank_sum"
}
}
}
}
3.3 最大桶和最小桶聚集
最大桶和最小桶聚集分别用于求多个桶的最大值和最小值,使用方法与求和桶聚集类似。例如:
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"date": {
"date_histogram": {
"field": "visittime",
"fixed_interval": "4m"
},
"aggs": {
"rank_data": {
"stats": {
"field": "rank"
}
}
}
},
"max_rank":{
"max_bucket": {
"buckets_path": "date>rank_data.max"
}
}
}
}
3.4 差值聚集差值
聚集用于计算直方图聚集的相邻桶数据的增量值,它也是父管道聚集。例如:
POST sougoulog/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"date": {
"date_histogram": {
"field": "visittime",
"fixed_interval": "4m"
},
"aggs": {
"avg_rank": {
"avg": {
"field": "rank"
}
},
"hb":{
"derivative": {
"buckets_path": "avg_rank"
}
}
}
}
}
}
差值聚集可以用于计算相邻桶数据的环比增长值,因此从第二个桶开始才有统计结果,结果如下。
"aggregations" : {
"date" : {
"buckets" : [
{
"key_as_string" : "00:00:00",
"key" : 0,
"doc_count" : 4231,
"avg_rank" : {
"value" : 13.434885369888915
}
},
{
"key_as_string" : "00:04:00",
"key" : 240000,
"doc_count" : 4115,
"avg_rank" : {
"value" : 46.68262454434994
},
"hb" : {
"value" : 33.247739174461024
}
},
{
"key_as_string" : "00:08:00",
"key" : 480000,
"doc_count" : 1654,
"avg_rank" : {
"value" : 47.66142684401451
},
"hb" : {
"value" : 0.9788022996645651
}
}
]
}
}
6.3 使用fielddata聚集
text字段通过前面的讲解,你应该已经学会了Elasticsearch支持的各种常用的聚集方式,然而这些聚集请求的聚集字段均未使用text字段,原因是实现聚集统计时需要使用字段的doc value值,而text字段不支持doc value。为了让text字段也能做聚集统计,Elasticsearch给text字段提供了fielddata字段数据功能,使用该功能可以在内存中临时生成字段的doc value值,从而实现对text字段做聚集统计。字段数据是一种缓存机制,它会取出字段的值放入内存,可用于排序和聚集统计。
先建立一个映射fielddata-test,它只有一个text字段,在映射中开启字段数据功能。
PUT fielddata-test
{
"mappings": {
"properties": {
"content": {
"type": "text",
"fielddata": true
}
}
}
}
然后向其中添加一条数据。
PUT fielddata-test/_doc/1
{
"content":"hello php java"
}
尝试在这个text字段上做词条聚集。
POST fielddata-test/_search
{
"query": {
"match_all": {}
},
"aggs": {
"termdata": {
"terms": {
"field": "content",
"size": 10
}
}
}
}
要显示内存中的content字段数据所占用的大小,可以使用以下代码。
id host ip node field size
EijMhNrDSoy-Bbmo3W8JGA 127.0.0.1 127.0.0.1 node-1 content 512b
字段数据可能会消耗大量内存,为了防止内存被字段数据过度消耗,可以在elasticsearch.yml中使用indices.fielddata.cache.size配置字段数据消耗内存的上限,可以给定一个百分比值,也可以给定具体大小值,该参数配置完后需要重启集群才能生效。
除了内存上限的配置,还可以使用字段数据的断路器,它会评估一个请求使用字段数据消耗的内存量,如果消耗的内存量超过indices.breaker.request.limit中配置的数值,它就会终止该请求继续消耗内存,这种配置可以使用REST端点动态修改,代码如下。
PUT /_cluster/settings
{
"persistent" : {
"indices.breaker.request.limit" : "30%"
}
}
6.4 给聚集请求添加后过滤器
给聚集请求添加后过滤器前面已经介绍过两种过滤器,一种是在布尔查询的过滤上下文中添加搜索条件,另一种是过滤器聚集。本节介绍的后过滤器与它们都有区别。
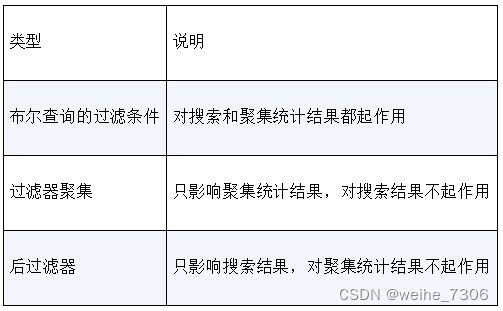
由于后过滤器是在生成聚集统计结果之后对搜索结果进行过滤,所以它对聚集统计的结果没有任何影响,你可以在聚集请求的后面添加一个后过滤器,例如:
POST test-3-2-1/_search
{
"query": {
"match_all": {}
},
"size": 10,
"aggs": {
"names": {
"terms": {
"field": "name.keyword",
"size": 10
}
}
},
"post_filter": {
"term": {
"name.keyword": "张三"
}
}
}
这个请求把后过滤器的过滤条件放到了聚集请求的后面,表示搜索结果只显示名字为“张三”的数据,聚集统计的结果是索引的全部文档,代码如下。
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test-3-2-1",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : "1",
"sex" : false,
"name" : "张三",
"born" : "2020-09-11 00:02:20",
"location" : {
"lat" : 41.12,
"lon" : -71.34
}
}
}
]
},
"aggregations" : {
"names" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "王五",
"doc_count" : 1
},
{
"key" : "张三",
"doc_count" : 1
},
{
"key" : "赵二",
"doc_count" : 1
},
{
"key" : "李四",
"doc_count" : 1
}
]
}
}