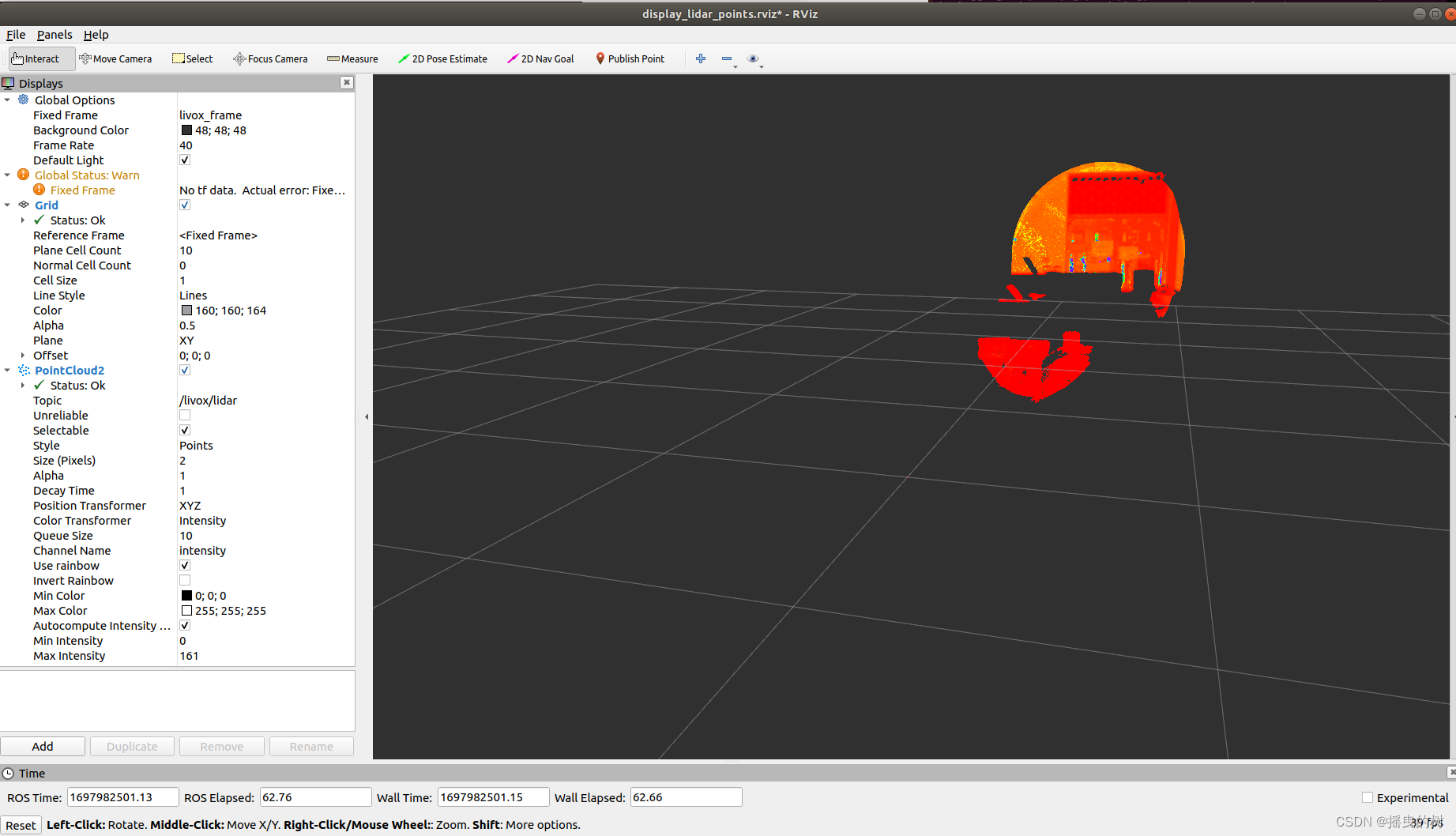
在前面的章节我们已经知道,人类反馈强化学习机制主要包括策略模型、奖励模型、评论模型以及参考模型等部分。需要考 虑奖励模型设计、环境交互以及代理训练的挑战, 同时叠加大语言模型的高昂的试错成本。对于研究人员来说, 使用人类反馈强化学习面临非常大的挑战。RLHF 的稳定训练需要大量的经验和技巧。RLHF 的稳定训练需要大 量的经验和技巧,下面针对 PPO 算法的内部工作原理进行代码示意性分析。
奖励模型训练

奖励模型训练损失代码, 不仅需要拉大奖励模型在 chosen 和 rejected 回复分数上的差距, 也可以将在chosen 数据上的生成损失加入到最终的优化目标中。

PPO 微调
PPO 微调阶段涉及到四个模型, 分别是策略模型、评论模型、奖励模型和参考模型。首先加载这四个模型。

在模型加载完成后对策略模型和评论家模型进行封装, 这两个模型会进行训练并且更新模型参数, 奖励模 型和参考模型则不参与训练。

接下来将进行经验采样的过程, 分为以下几个步骤:(1) 读取输入数据, 并使用策略模型生成对应回复;(2) 使 用奖励模型对回复进行打分;(3) 将回复和策略模型输出概率等信息记录到经验缓冲区内。

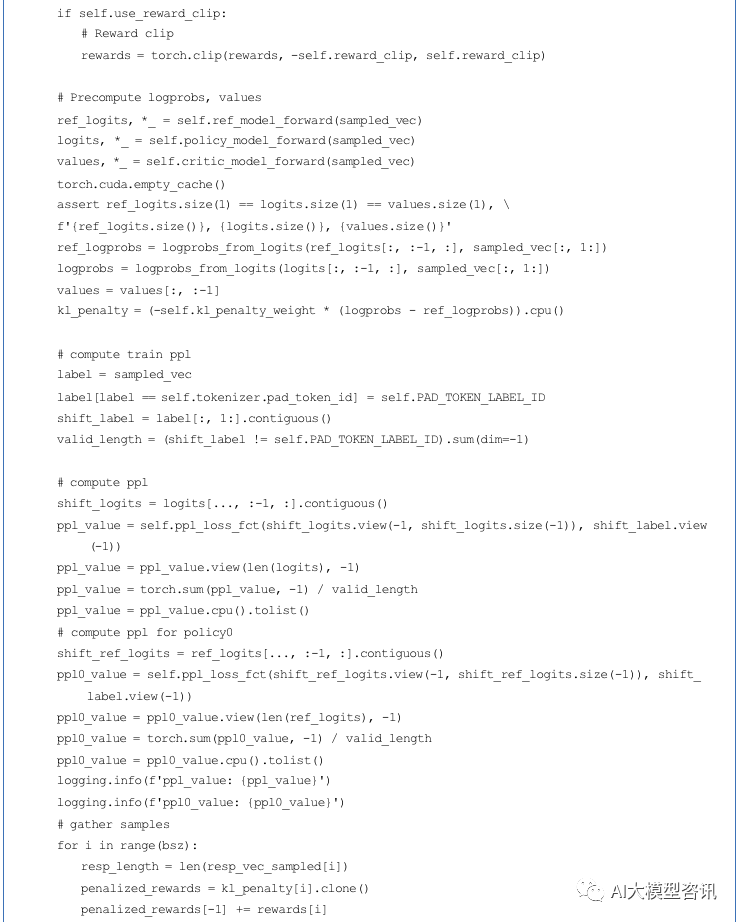

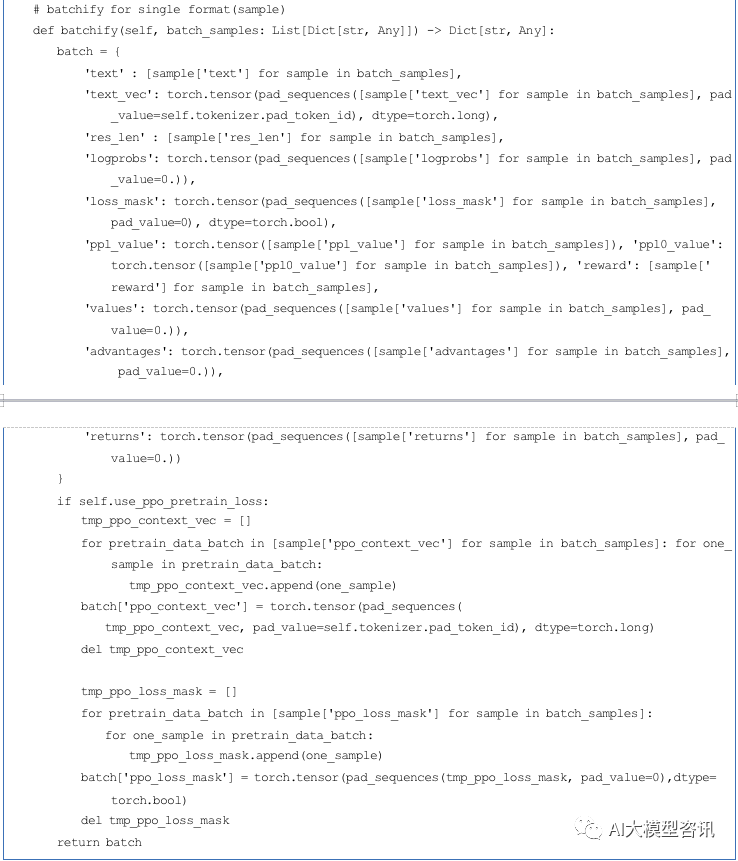
然后, 使用广义优势估计算法, 基于经验缓冲区中的数据来计算优势 (Advantages) 和回报 (Return)。将估计 值重新使用 data_helper 进行封装,来对策略模型和评论模型进行训练。


ps: 欢迎扫码关注公众号^_^.