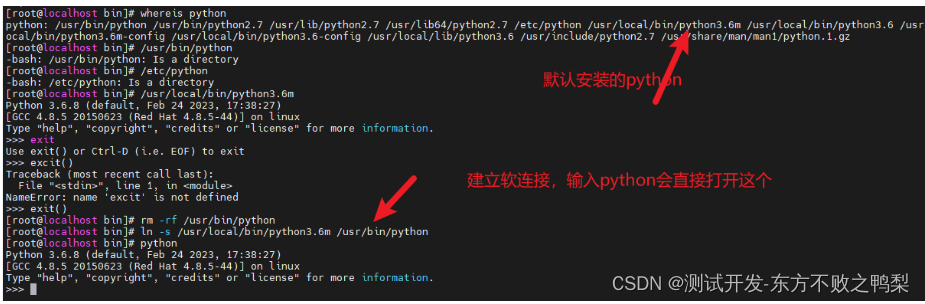
在代码中启动多个进程
使用system库函数启动多个进程

传统的进程调用就是我们在命令框里输入运行某个进程,而我们可以依靠代码,实现让一个进程取启动另一个进程

在进程运行过程我们使用命令ps -elf看到正在运行的有三个进程
system的调用过程
首先./system进程通过system库函数创建sh -c进程,在通过sh -c进程来启动./sleep进程,因此就有上面说的有桑格进程在运行,然后./sleep进程运行结束,跳回sh -c进程,进程在结束,跳回./system进程执行后续操作
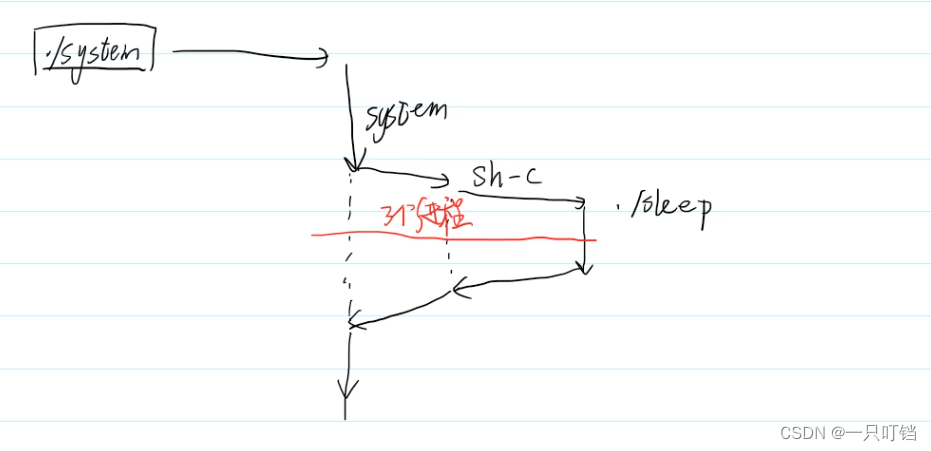
fork系统调用启动多个进程
在执行了
fork指令之后,进程就会将自己复制一份一摸一样的进程出来,里面的代码段,pc指针都相同,这两个进程一个是父进程,一个是子进程,在父进程和子进程中已执行指令和未执行执行指令都是相同的,这个时候如果我们不加以控制这两个进程就会并行的执行相同的指令。
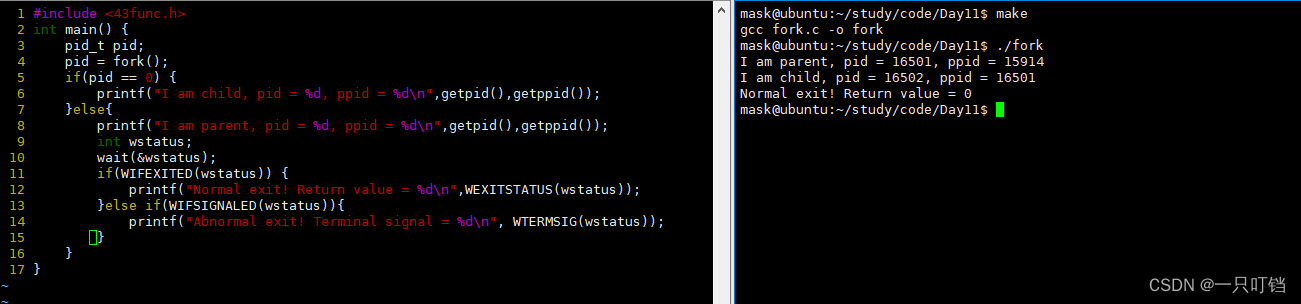
父进程中的fork的放回值是子进程的pid,子进程中的fork返回值是0,这样我们就可以按照其返回值进行判断,让不同的进程走向不同的分支,实现不同的代码
我们可以看到父进程由命令行(bash分支)创建

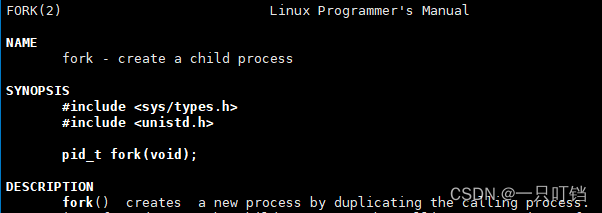
深入fork
fork实现的底层原理
(1)fork调用的时候回拷贝一份task_struct
(2)子进程修改一些必要数据
(3)加入到就绪队列
第一步和第二步不可抢占,时间尽可能短,我们称为进程调用的上半部;第三步是可以抢占的,执行这个操作的时间可以长,我们称为下半部
系统调用是怎样实现的
用户态下不能执行所有的指令,因此cpu的使用状态分为用户态和内核态
需要调用硬件的功能或者硬件发生一些事件,此刻cpu状态就会处于内核态进行处理
硬件中断(用户态—>内核态)
fork的性能
上面那我们说过在执行fork指令之后,进程会复制一个和自己完全一样的进程出来,那么复制出来的进程和我们原来的进程是怎么使用内存空间的呢,这是一个问题,因此fork在进行复制时,其实不会给新的进程分配物理空间,当我们只进行读取操作这样对两个进程都没有影响,但是当某个进程执行写操作,需要修改进程内存中的数据,就会在复制一个修改数据之前的数据块,分配物理内存,让另外一个进程指向这个内存空间
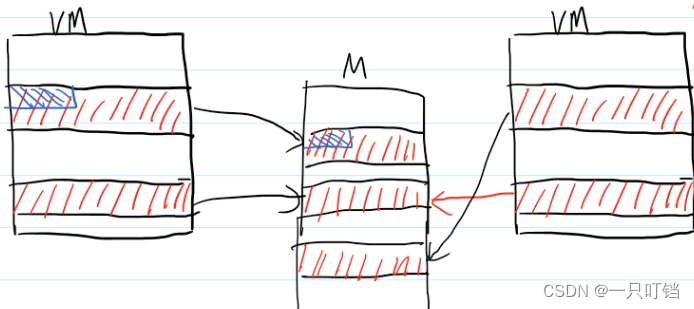
fork的拷贝
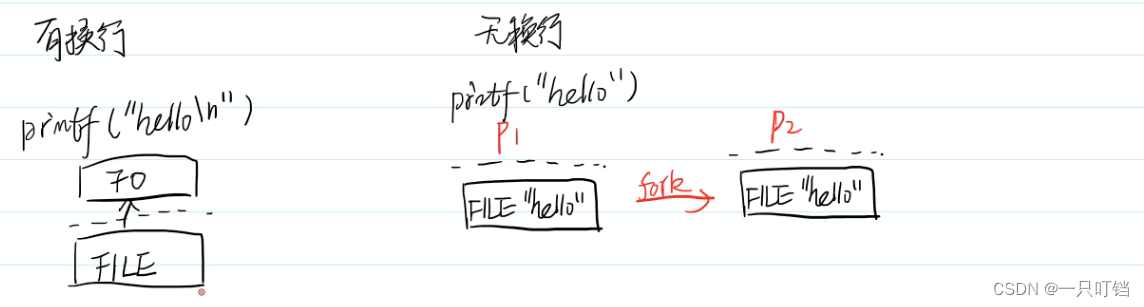
在逻辑上,父子进程的用户态空间(栈,堆,数据段)是拷贝的
在代码中可以看到我们先让父进程睡眠等待子进程输出完毕以及更改数据完毕再执行父进程,但是我们再子进程中修改的数据只影响了子进程中的输出,并没有改变父进程中的数据输出,再次验证了用户态空间(栈,堆,数据段)不是共享的,是拷贝的
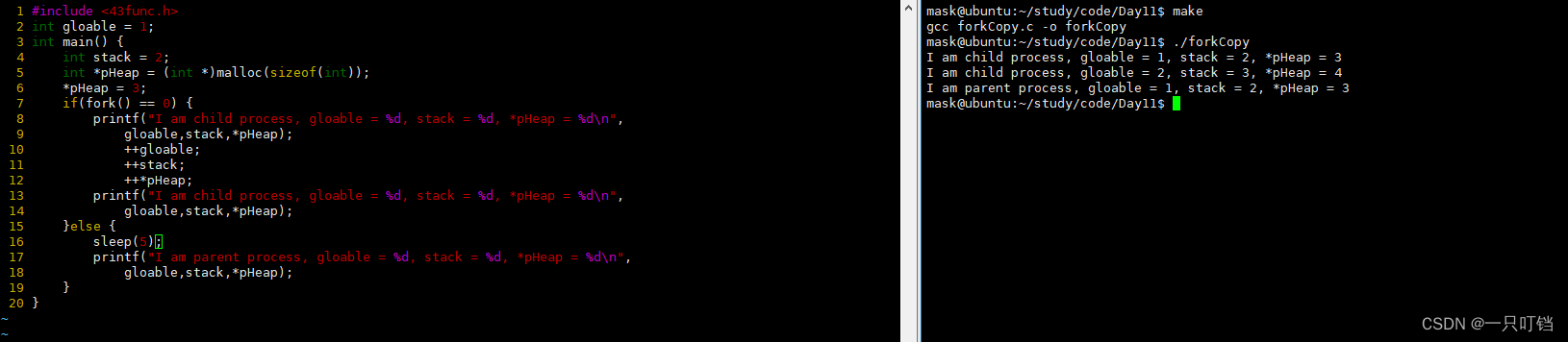
FILE的拷贝
printf的本质:往stdout中写入内容,遇到换行\n或者缓冲区满的时候将数据拷贝到内核文件对象中
内核态是拷贝还是共享
对于文件对象父进程和子进程是共享的,标准输出输入设备父子进程也都是共享的
exec(系统调用)函数族
exec将一个可执行程序加载到本能地进程的地址空间
调用exec会清空数据(栈,堆,数据段),将函数参数中的pathname加载进来,取代原来的代码段,重置PC指针
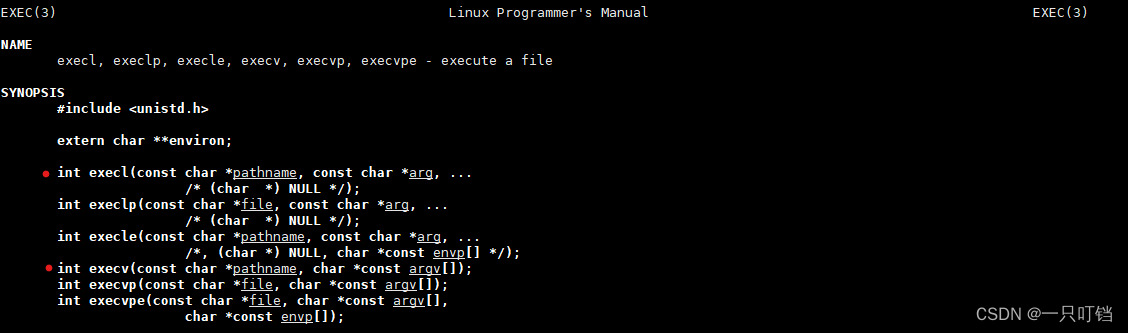
图中标注出来的是需要重点掌握的函数execl l是指list,是可变参数,execv v是指vector元素为指针的数组
execl参数含义:pathname指明可执行参数的路径;第二个或者更多的参数表示要调用程序所需要携带的参数,NULL值表示参数输入完毕,我们也可以看到我们执行了两个程序,但是只使用了一个进程
execl用法
execv用法
以上的方法也可以用system函数实现


使用strtok分割字符串
第一个参数是传入传出参数,只能使用字符数组,不能只用字面值

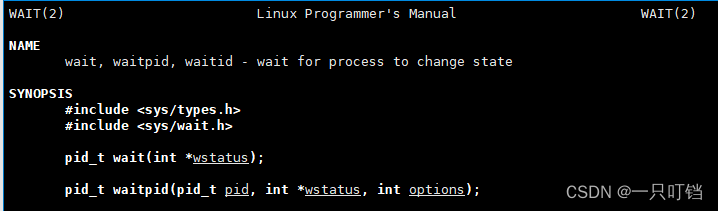
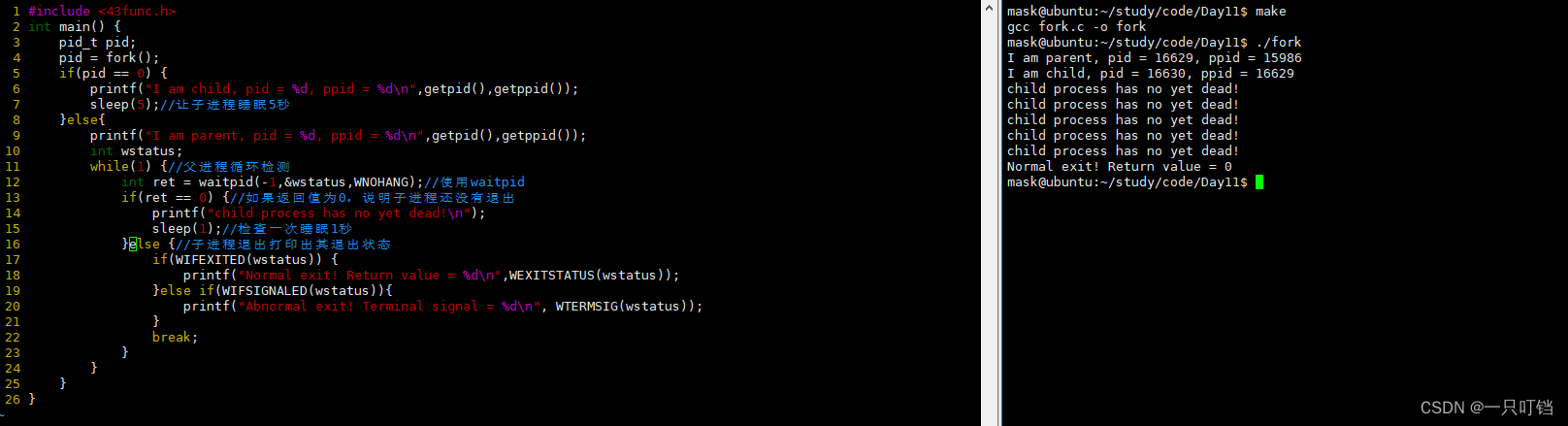
wait
在上面使用fork将进程复制为父子进程的示例中,我们可以看到我们在执行父进程程序之前我们是先对父进程使用sleep(1)让父进程睡眠1秒
在执行,那我们为什么要给父进程执行sleep(1)指令呢,如果不执行又是什么情况,下面是如果不对不父进程执行sleep(1)的输出结果。

看输出结果父子进程的pid没有问题,但是(1)子进程的ppid有问题;(2)以及子进程打印信息的位置有问题,现在子进程打印的位置在命令提示行之后,显示错乱。并且我们可以看到程序先打印了父进程的指令,再打印执行子进程程序,这样导致子进程执行完毕要回收资源时找不到父进程
这就涉及到进程的退出;在
linux里进程退出之后其资源的回收由其父进程回收(调用wait )
我们可以使用wait函数让父进程在子进程销毁之后为子进程回收资源,这样进程的运行又回归正常
子进程未终止,父进程已终止;这样的进程我们称之为孤儿进程,他们需要重新找其他进程作为自己的父进程,一啊不能都是找1进程作为父进程

子进程终止的时候,父进程一直不调用wait,此时进程已经死亡,但是资源还没回收,这样的进程我们称之为僵尸进程
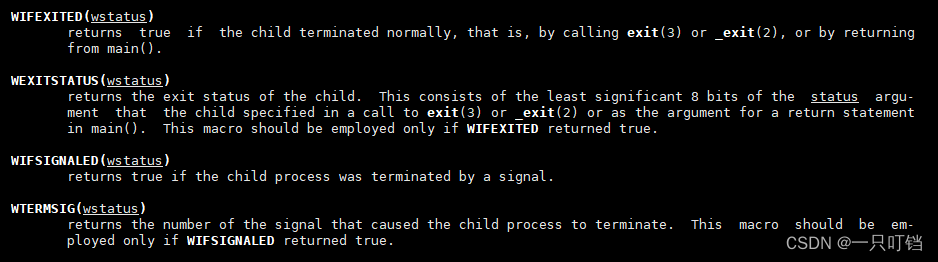
使用wait获取子进程的退出状态
可以根据下面的宏来检测是否为正常退出
可以获取我们的返回值进行放回
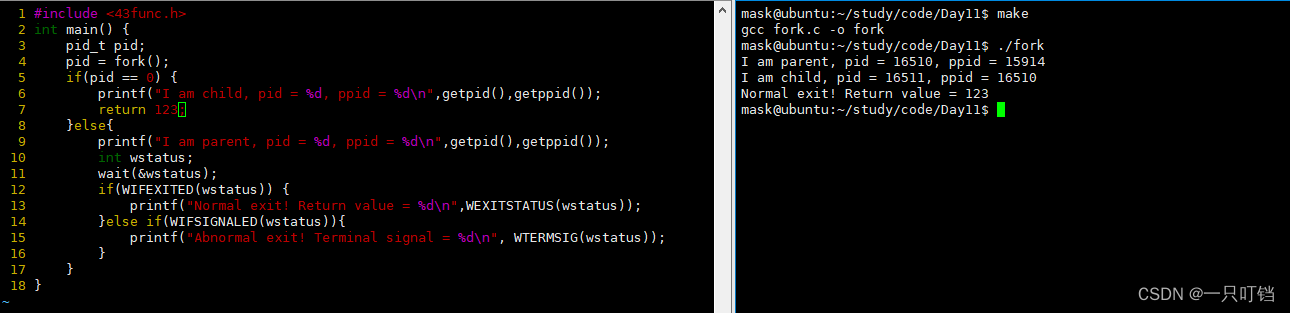
我们用9号信号杀死进程,便会打印出其时非正常退出

wait的缺陷:假如一个父进程有多个子进程,那么wait只能等一个子进程死
waitpid

options可以设置属性,可以设置的值WNOHANG,WNOHANG的作用,过一段时间回来查看以下子进程是否死亡,如果死亡就为子进程回收资源,如果没死那么在过一会再来看,
如果加上WNOHANG属性,那么如果子进程终止返回0;如果进程已终止,就会回收资源
非阻塞通常配合循环使用

pid的值如果是-1,那么就是可以等待任何一个子进程
同步:事件发生的时间顺序总是确定固定的
异步:某件事件发生之后另一个事件不一定执行
进程的正常终止
(1)在main函数中调用return,可以使用echo $?查看返回值
好处:写法方便
坏处:只能退出当前函数,不能退出进程

(2)使用exit(number)可以在进程的任何时刻都可以退出进进程,其中number是其退出进程的返回值
并且我们可以看到printf没有换行符\n,因此打印的数据是hello存储在标准输出stdout文件流里面的,并没有存储在文件对象里面,所以exit()可以帮我么清空文件流,并且将数据显示在屏幕上
如果使用printf加上了换行符\n那么打印的数据就会存储到文件对象中

_exit()作用和exit()的作用是一样的,但是其不会自动清空文件缓冲区数据(标准输出stdout)
_exit()和_Exit()的作用是一样的

进程异常终止
(1)主动异常终止
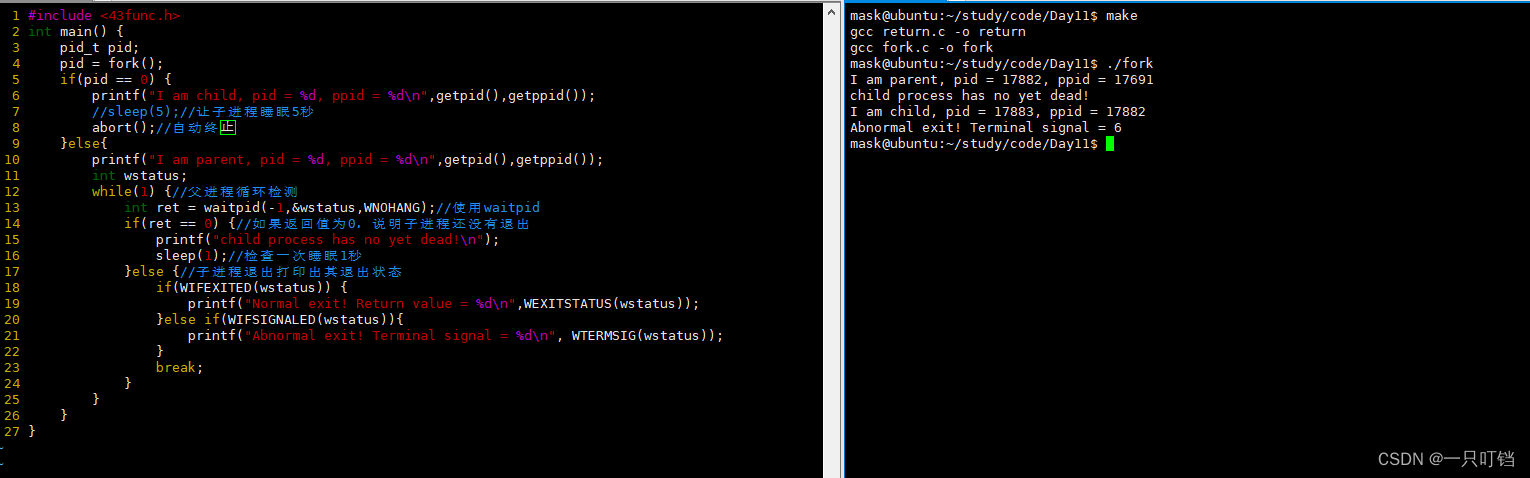
6号信号,自杀信号

(2)另一个进程/硬件发信号终止
进程组
进程组是进程的集合,每个进程只能属于一个进程组,组ID是组长的PID,父子进程属于同一个进程组
即使组长进程终止,组ID也不变
新进程的PID不和组长ID重复
普通组员可以脱离原来的组创建新的组,但是组长不行
获取组ID和设置组ID
getpgid(pid)中的参数pid是指你要获取的进程的pid,如果参数值为0,那么返回值为本进程的父进程PID

通过shell启动的进程是一个新的进程组的组长
因此此进程一已经不能在重新建立新的组
但是其子进程可以创建新的进程组,并且这不会影响之前的父子关系

setpgid(0,0)两个参数的意义,第一个参数表示我们要修改谁的进程组ID,第二个参数表示我们要将目标进程的进程组ID改为多少
因此两个0表示要将本能进程设为新的一个进程组组长

在一个终端(会话)中,有至多一个前台进程组,有任意个后台进程组
使用会话session管理进程组
会话是进程组的集合,创建会话的进程我们称之为会话首进程,会话首进程必定是组长,其也是会话的第一个进程
会话可以连接一个终端,如果有终端连接会话,就会有一个专门的进程去和会话进行交互,这个进程我们称之为控制进程
如果终端关闭,所有会话内的进程会收到一个断开连接信号
获取会话
ID
参数为我们我们想要获取的进程PID,如果参数为0则返回当前进程的会话ID
更改会话ID,实质不是区=去更改会话ID是拿当前的的进程创建新的会话



守护进程daemon
即使是会话(终端)关闭,进程依然可以持续运行,因此守护进程是孤儿进程
守护进程一般以d结尾,例如sshd就是一个守护进程
守护进程特点:
(1)创建新的会话(将父进程终止,重新创建会话)
(2)重置掉当前工作目录pwd和文件创建掩码umask
(3)关闭所有的文件描述符(因此如果守护进程需要输出数据只能输出到日志系统,可以和日志系统进行交互)
守护进程的使用
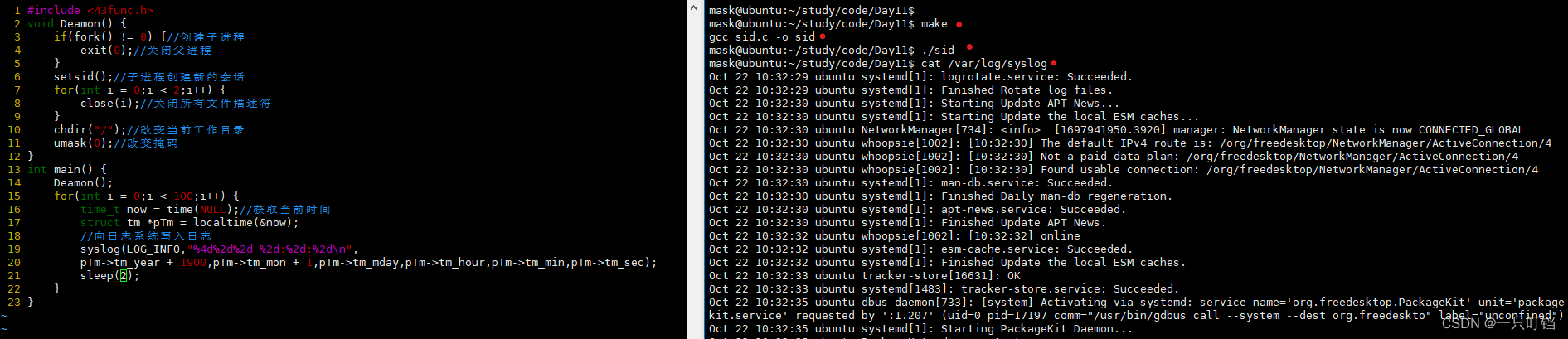
日志系统末尾打印出我们的日志数据

日志系统

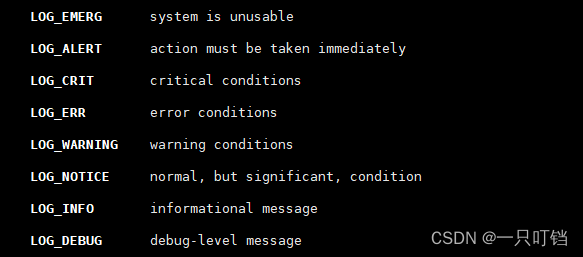
日志系统本质就是一个可写入文件,并且会记录其优先级priority下面就是一些优先级参数
进程间通信(Inter Process Communication ---- IPC)
目的打破进程之间的隔离,从而使得进程之间可以共享数据
IPC包括:
(1)管道–重要;(2)共享内存;(3)信号量;(4)消息队列;(4)信号–重要
有名管道:在文件系统中存在一个管道文件
匿名管道:在文件系统中不存在管道文件,只用于父子进程之间
管道用法popen(库函数)

进程执行popen库函数之后会创建一个子进程,父子进程之间用管道连接在一起,管道两端是文件流
popen库函数的第二个参数type的值可以为w或r;w表示父进程可写入数据到管道文件流FILE内,子进程把自己的stdin重定向为管道;r表示父进程可读取管道文件流FILE,子进程把自己的stdout重定向为管道;
读模式

写模式