很久没用mmdetection了,作为目标检测常见的几个深度学习框架,mmdetection用的人还是很多的,其中比较吸引人的一点就是mmdetection集成了非常多的算法,对于想做实验对比和算法学习的人来说,基于这个框架可以事半功倍。因为外面提出的各种各样的算法依赖的环境会有所不同,数据集的格式也有区别,我们单独去跑这一个个算法实际上是很费劲的,所以mmdetection的出现直接把这些算法集成到一个统一的平台,对于大家系统性的学习非常便利。
最近几天摸索了一下,过程还比较顺利,但是摸索也耗时间,所以在这里记一下,既为以后使用方便,也为有需要的人提供参考。
重点说明,本环境未使用 mim库进行环境安装,使用常规的conda、pip安装,过程非常简单高效。以前大致瞅见过 mim库,估计是可以自动检测软硬件环境以匹配合适的库进行安装,命令可能是模仿的 pip,这个库一般来说可以避免使用,所以这里未考虑使用mim库。
官网安装教程如下,网址:https://mmdetection.readthedocs.io/zh_CN/latest/get_started.html
下面是本文推荐的安装教程。
二、环境安装
1、下载mmdetection框架的所有文件,可以:
git clone https://github.com/open-mmlab/mmdetection.git
也可以直接去官网:https://github.com/open-mmlab/mmdetection 下载压缩包
我下载的是3.1.0版本的压缩包

2、创建运行需要的虚拟环境
很常规的操作,不熟悉的需要时间理解摸索一下,
①一般涉及到使用的操作系统,Linux或windows,这里用的是Linux下的Ubuntu 16.04。
②然后是显卡驱动软件,深度学习要用显卡计算一般得有,显卡驱动的版本一般有12基本够用,显卡驱动软件版本就是nvidia-smi右上角的cuda version,表示环境中cudatoolkit可以安装的最高版本号。(之前有段时间以为需要单独安装CUDA,实际发现只需要安装显卡驱动软件 + 虚拟环境安装cudatoolkit 就可以跑深度学习代码)
③然后就是常规的虚拟环境创建,安装相关库。
假设创建一个名称为mmlab的虚拟环境
conda create -n mmlab python=3.8 -y
激活进入虚拟环境
conda activate mmlab
安装pytorch等深度学习库,我的显卡驱动软件是12.2的版本,我选择装CUDA11.3版本的pytorch,其他具体命令可去pytorch官网查询,我的是
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
这时可以验证一下pytorch库是否可以调用显卡,进入python环境
import torch
torch.cuda.is_available()
True
输出True则说明可正常调用显卡
接着是安装 mmengine
pip install mmengine
然后是mmcv,官网给了一个版本推荐:

我是根据这个推荐尝试了的,但是发现后面会报错,无法导入mmdet,而且提示我mmcv版本不对,所以不能完全按照教程来。后面我看了一下可能是装的mmdetection是3.x版本的,而教程里是2.X版本的教程。
我安装能用的是:
pip install mmcv==2.0.0rc4
这条命令的安装时间很长,估计有半小时以上
装完之后,可以进入python命令行测试一下
import mmdet
如果可以正常导入的话,说明库之间的调用是没问题的
最后就是进入mmdetection进行编译
cd mmdetection-main
pip install -v -e .
运行完就会提示安装成功。
上述就是我装环境的过程,完全没有使用mim,而且安装起来也不复杂,我提供的这个版本也是验证了可以使用的。总共没几条命令,特别简单,就是要花点时间。
三、训练自己的数据集
1、数据集准备
mmdetection要求数据集的格式是coco形式的,即训练、测试图片+两个各自的json文件,具体格式自行查询coco数据集制作或介绍的内容
2、网络配置
以前配置网络感觉过程还挺复杂的,在一些文件里 加数据集路径+数据集类别名等,现在不用这么复杂了,可以自己写一个配置文件覆盖掉提供的文件,基于自己提供的信息去训练网络。
①我一般在configs文件夹下创建一个专门用来跑自己想跑的算法的文件夹,假设为test_task
②把要跑的算法拷贝test_task,假设是fcos.py
③把_base_要求的文件也拷进来,可能会改内容。在test_task文件夹下创建一个_base_文件夹,放coco_detection.py , schedule_1x.py , default_runtime.py 代码,注意在fcos.py里修改相对路径
④自己写一个配置文件,比如fcos_base.py,用来给fcos.py继承,注意配置文件fcos_base.py的内容必须是fcos.py出现了的变量,仅是覆盖掉之前的配置,示例fcos_base.py内容主要如下:
""" 表示继承自fcos.py"""
_base_ = './fcos.py'
"""更改 model 中的 num_classes 以匹配数据集中的类别数,
本地加载预训练模型加checkpoint参数,建议绝对路径"""
model = dict(
backbone =dict(init_cfg=dict(checkpoint='./resnet50.pth')),
bbox_head=dict(num_classes=1)
)
"""修改数据集相关配置,dataroot建议数据集的绝对路径,metainfo给出数据集的类别,训练集和验证集的ann_file写自己的数据集路径和名称,batch_size也可以设置"""
data_root = 'data/balloon/'
metainfo = {
'classes': ('balloon', )
}
train_dataloader = dict(
batch_size=1,
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='train/annotation_coco.json',
data_prefix=dict(img='train/')))
val_dataloader = dict(
dataset=dict(
data_root=data_root,
metainfo=metainfo,
ann_file='val/annotation_coco.json',
data_prefix=dict(img='val/')))
test_dataloader = val_dataloader
# 修改评价指标相关配置
val_evaluator = dict(ann_file=data_root + 'val/annotation_coco.json')
test_evaluator = val_evaluator
所以基本上用着一个配置文件就可以完成个性化的训练任务,不需要去改那么多的参数和文件了
训练命令:
python tools/train.py configs/test_task/fcos_base.py
这样就可以开始训练了。
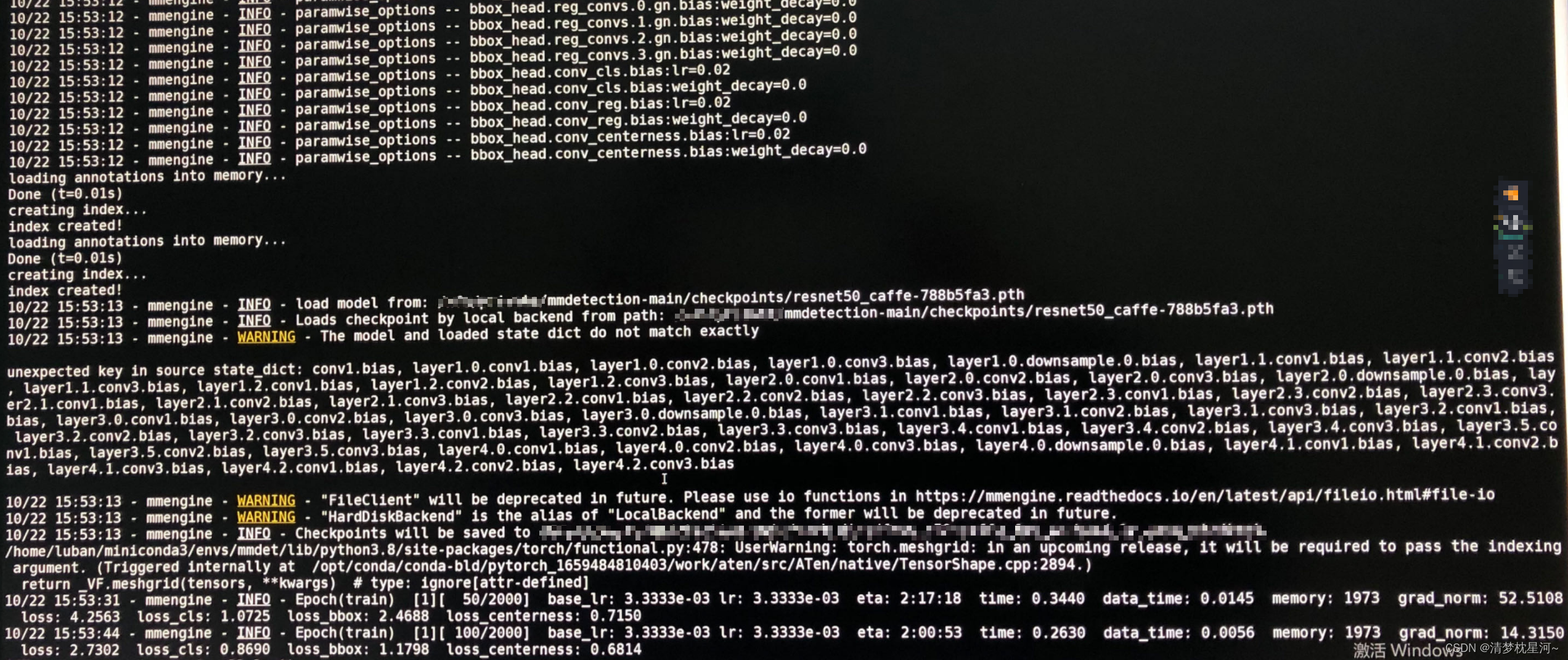
我的训练界面: