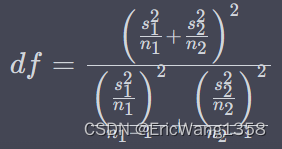基本原理
决策树的基本原理是将数据分成不同的子集,使每个子集尽可能纯净。
这意味着子集中的数据属于同一类别或具有相似的属性。
为了做到这一点,决策树会选择一个特征,并根据该特征将数据分成两个子集。
它会选择那个特征,该特征在划分后的子集中具有最好的纯度,通常使用一种叫做“信息增益”的指标来衡量。
公式解释
信息熵(Entropy)
信息熵是衡量数据纯度的指标。对于一个数据集,信息熵的计算公式如下:
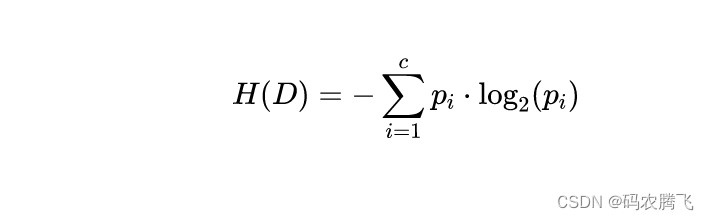
其中,是数据集的信息熵,是类别的数量,是数据集中属于第
个类别的样本所占的比例。信息熵越低,数据集越纯净。
信息增益(Information Gain)
信息增益用于选择最佳的特征进行数据分割。对于一个特征
,信息增益的计算公式如下:
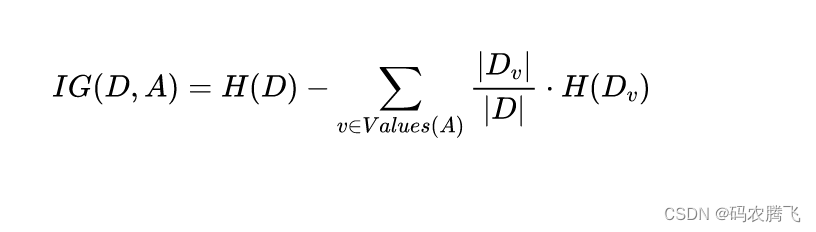
其中,是特征的信息增益,是数据集的信息熵,是特征的可能取值,是特征取值为时的子集,表示数据集
的大小。
Python示例
现在,让我们使用Python来绘制一个简单的决策树示例,以更好地理解它的工作原理。我们将使用scikit-learn库来创建和可视化决策树模型。