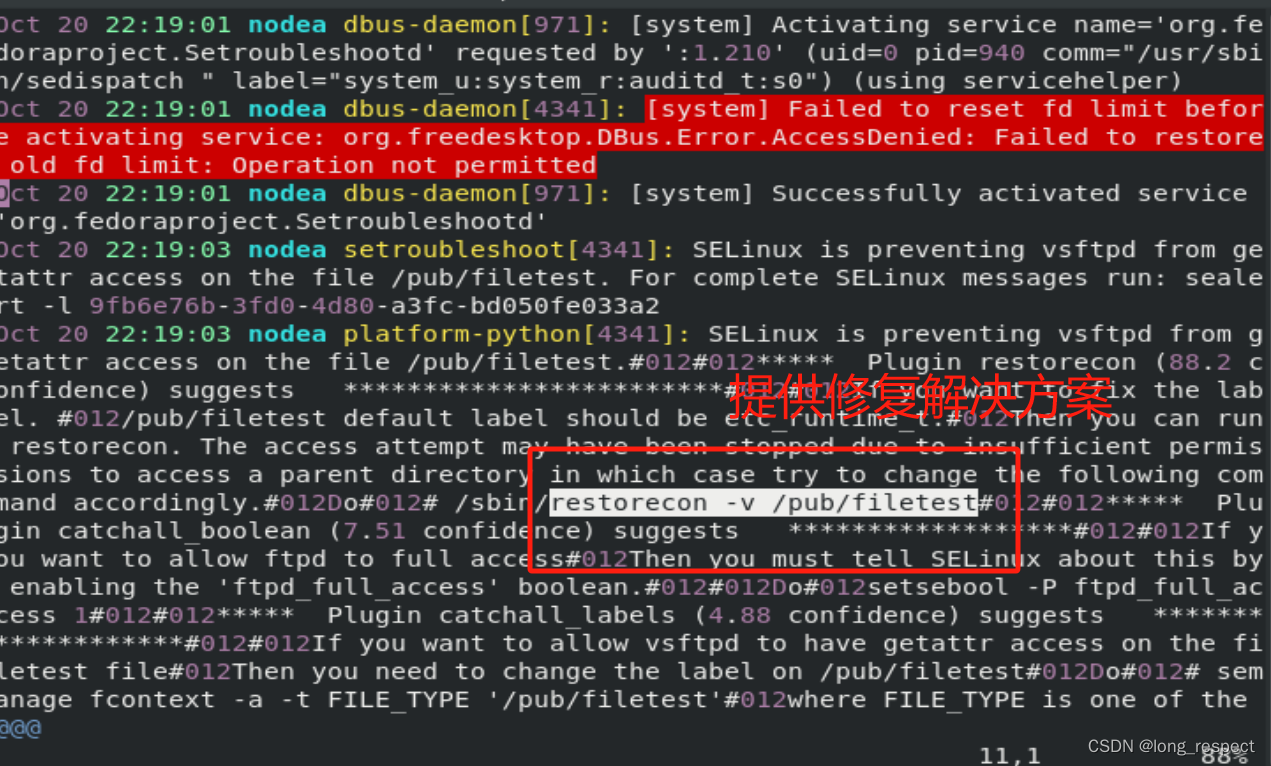
这是一个通过 Python mitmproxy 库 实现获取某个微信公众号下全部文章数据的解决方案。首先需要创建一个 Python 虚拟环境,并进入虚拟环境下:
$ python -m venv venv
$ venv/Scripts/activate
我们需要使用 mitmproxy 库 来建立一个网络代理,以实现监控微信公众号请求的需求。通过下面的命令安装 mitmproxy 库 到虚拟环境:
$ pip install mitmproxy
然后在项目的根目录下创建一个 mitmproxy 插件 文件,这个插件的核心逻辑在 HTTP 事件钩子 - 收到完整的响应 时,判断是否微信公众号的文章数据相关请求和响应,如果是就取出我们需要的数据,并写入文件中。插件的完整代码如下:
import json
from mitmproxy import ctx, http
class Agency:
def __init__(self):
self.filter_host = 'mp.weixin.qq.com'
self.filter_path_list = ['/mp/getappmsgext', '/mp/appmsg_comment', '/cgi-bin/appmsg']
self.article_data = {}
def request(self, flow: http.HTTPFlow):
""" HTTP 事件钩子 - 发出完整的请求 """
pass
def response(self, flow: http.HTTPFlow):
""" HTTP 事件钩子 - 收到完整的响应 """
if flow.request.host == self.filter_host:
path = flow.request.path.split('?')[0]
if path in self.filter_path_list:
if path == '/mp/getappmsgext':
response_json = json.loads(flow.response.text)
if 'appmsgstat' in response_json:
appmsgstat = response_json['appmsgstat']
self.article_data['read_num'] = int(appmsgstat['read_num']) # 阅读数
self.article_data['like_num'] = int(appmsgstat['like_num']) # 在看数
self.article_data['old_like_num'] = int(appmsgstat['old_like_num']) # 点赞数
elif path == '/mp/appmsg_comment':
response_json = json.loads(flow.response.text)
if 'elected_comment_total_cnt' in response_json:
comment_total = response_json['elected_comment_total_cnt']
self.article_data['elected_comment_total_cnt'] = int(comment_total) # 评论数
elif path == '/cgi-bin/appmsg':
response_json = json.loads(flow.response.text)
if 'app_msg_list' in response_json:
app_msg_list = response_json['app_msg_list']
for app_msg in app_msg_list:
title = app_msg['title'] # 标题
digest = app_msg['digest'] # 概要
link = app_msg['link'] # 链接
msg = {'title': title, 'digest': digest, 'link': link}
with open('article_list.log', 'a+', encoding='utf-8') as file:
file.write(f'{json.dumps(msg, ensure_ascii=False)}\n')
if len(self.article_data) == 4:
with open('article_detail.log', 'w+', encoding='utf-8') as file:
file.write(f'{json.dumps(self.article_data, ensure_ascii=False)}')
self.article_data = {}
addons = [Agency()]
我们监控的三个接口中,/cgi-bin/appmsg 是微信公众平台 web 后台中,用户编辑文章时,插入其他公众号文章的超链接时,调用的分页查询接口。用于获取当前公众号下的全部文章的基本信息(包括文章的标题、概要和链接):

另外两个 /mp/getappmsgext 和 /mp/appmsg_comment 则是微信 PC 客户端中,用户点击微信公众号文章链接后,客户端打开新窗口时调用的查询接口。用于获取具体某个公众号文章的详细信息(包括文章的阅读数、点赞数、在看数和评论数):

生成的 article_list.log 文件(公众号下全部文章基本信息)是追加写入的。而 article_detail.log 文件(具体某个文章的详细数据)是覆盖写入的。这个区别需要注意下。
启动和配置代理
在虚拟环境里,执行下面的命令启动代理:
$ mitmdump -p 23457 -s agency.py
然后打开系统管理页面,选择代理,手动配置成 23457 并开启、保存配置:

安装证书文件
执行这一步的前提是,前面的步骤都顺利完成!
因为微信公众号的请求是 HTTPS 的模式,所以现在还需要访问 http://mitm.it/ 地址,下载证书文件:

下载完成后,直接打开证书文件,系统会引导你完成安装流程,完成安装后,可以在系统中查看到证书已经安装成功:

获取公众号文章
最后就可以验收结果了,我们打开微信公众号平台的后台页面,创建并编辑一个新文章,选择超链接,然后搜索你要获取的公众号名称,分页查询的视图就出来了:

我们只需要通过某些方式一直点击下一页,就可以把全部文章的标题、概要、链接都获取到,不过要注意控制请求/点击的频率,不然会触发服务器的安全机制。
接下来通过脚本读取 article_list.log 文件中的每一条 JSON 数据,取出里面的文章链接,复制到微信 PC 客户端的聊天窗口里,再点击打开:

当文章窗口里的图文内容完全加载完成后,就会生成 article_detail.log 文件。