系列文章目录
第一章 Python 机器学习入门之线性回归
第一章 Python 机器学习入门之梯度下降法
第一章 Python 机器学习入门之牛顿法
第二章 Python 机器学习入门之逻辑回归
番外 Python 机器学习入门之K近邻算法
番外 Python 机器学习入门之K-Means聚类算法
第三章 Python 机器学习入门之ID3决策树算法
ID3决策树算法
- 系列文章目录
- 前言
- 一、ID3决策树简介
- 1、定义
- 2、例子
- 3、原理
- 二、ID3决策树详解
- 1、前置条件
- 2、计算信息增益
- 三、优缺点
- 1、优点
- 2、缺点
前言
开始新的一章,这章主要介绍决策树(decision tree)算法,它是一种常用的分类和回归方法,同时在它的基础上还演化出了随机森林、XgBoost等算法;这篇文章说说最早的决策树算法ID3决策树。
一、ID3决策树简介
1、定义
百科定义:
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
没有找到单独给ID3决策树的定义,所以就先用下决策树的普遍定义;决策树简单来说就是我们经常在代码里面写的if…else if…esle if…这样的情况
2、例子
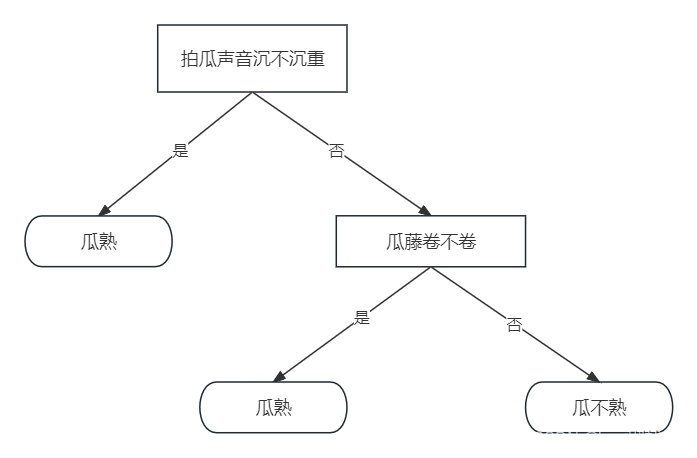
光说理论可能不太懂,我们举个例子看看,我们经常听到这瓜保熟吗这个梗,这是出自电视剧《征服》里面的一幕名场面,那我们就看看瓜熟不熟需要什么条件呢

本人爱吃西瓜,不太会选西瓜,就会这两三把式,让大家见笑了;首先我们可以根据拍打西瓜时候的声音沉不沉重,来看是不是熟瓜;如果是当当的清脆声那就是生瓜,如果声音沉重一般就是熟瓜;其次就看看瓜藤卷不卷,瓜藤卷到一定程度基本上就可以判定是熟瓜了;当然判断条件肯定不止这两个,其余条件有懂的朋友可以在下面评论让我学习学习哈
3、原理
从上面的例子中我们基本可以理解了决策树的原理,那我们现在就来说说ID3决策树,上面的例子提到了两个判断条件(瓜声和瓜藤),但是哪个放前面判断,哪个放后面判断呢?
这时候一位大佬昆兰使用信息论上的熵这个概念(该概念是由香农提出)进行思考,并在此基础上使用信息增益这个概念构建了决策树决策的过程
- 从根节点开始,计算所有可能的特征的信息增益,选择信息增益最大的特征作为节点的划分特征;
- 由该特征的不同取值建立子节点;
- 再对子节点递归1-2步,构建决策树;
- 直到没有特征可以选择或类别完全相同为止,得到最终的决策树
二、ID3决策树详解
1、前置条件
之前说到了熵和信息增益这两个概念,这块后面单独出一篇文章说下,我们当前只要需要明确两个概念,熵可以用来度量条件的不确定性,信息增益则是减少不确定的程度,所以我们每次优先挑选信息增益最大的特征确保接下来的特征分类结果更准确。
这里顺口提一句,由于该性质一般来说ID3决策树通常只用于分类,几乎不用于回归;网上资料中常提到决策树可用于回归和分类问题,那一般指的是C4.5算法和CART分类回归树,ID3可以说是不支持回归问题的。
2、计算信息增益
流程在上述原理中已经提过,这里就谈谈如何计算信息增益
- 假定样本集合D中第i类样本所占的比例为Pi,求它的信息熵
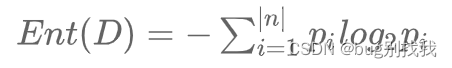
- 求离散特征a对数据集D的条件信息熵
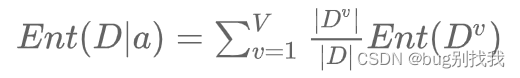
- 计算信息增益
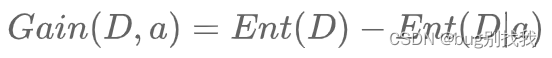
三、优缺点
1、优点
- 简单理解
- 处理分类问题
- 低计算复杂度
2、缺点
- 处理连续型特征困难
- 容易过拟合
- 处理缺失数据困难
- 对类别不平衡敏感
- 不支持剪枝