Java多线程编程案例
- 1. 单例模式
- 1.1 代码的简单实现
- 1.2 懒汉模式的线程安全代码
- 2. 阻塞队列
- 2.1 阻塞队列的概念
- 2.2 使用库中的BlockingDeque
- 2.3 模拟实现阻塞队列
- 2.4 生产者消费者模型
- 3. 定时器
- 3.1 概念
- 3.2 使用库的定时器 - Timer类
- 3.3 模拟实现定时器
- 4. 线程池
- 4.1 概念
- 4.2 使用库中的线程池
- 4.3 线程池模拟实现
1. 单例模式
1.1 代码的简单实现
- 应用场景: 一个项目中, 该对象只能创建一个
饿汉模式 – 迫切, 程序启动, 类加载之后, 立即创建出实例
代码示例
class SingletonHungryMode { // 不加以任何限制就是线程安全的
private static SingletonHungryMode instance = new SingletonHungryMode(); // 直接new
public static SingletonHungryMode getInstance() {
return instance;
}
// 添加限制, 让外部无法 new 出对象
private SingletonHungryMode() {
}
}
优点:
- 编写代码简单
缺点:
- 一开始就需要加载对象, 会降低程序的启动速率, 一开始不需要用到该对象的时候, 就会体验感下降
懒汉模式 - 正在需要用到实例的时候才创建对象
class SingletonLazyMode {
private static SingletonLazyMode instance = null; // 不是直接new
// 这个版本不是线程安全的
public static SingletonLazyMode getInstance() {
if (instance == null) {
instance = new SingletonLazyMode();
}
return instance;
}
// 添加限制, 让外部无法 new 出对象
private SingletonLazyMode() {
}
}
优点:
- 可以在需要的时候在new出实例对象, 可以提高程序界面的加载速度
Java的反射与单例模式的思考
我们都知道, Java提供了反射机制, 通过反射, 我们可以得到类的所有信息, 可以得到private修饰的构造函数, 就可以new 多个对象, 这样单例模式中private修饰;
那么我们通过private修饰构造方法设计的单例模式是不是就存在问题呢? 是的! 使用反射, 确实可以在当前单例模式中, 创建出多个实例;
反射是属于 “非常规” 的编程手段, 正常开发的时候, 不应该使用/慎用; 滥用反射, 会带来极大的风险, 会让代码变的抽象, 难以维护!
Java 中也有实现单例模式而不怕反射的
1.2 懒汉模式的线程安全代码
懒汉模式下线程不安全的原因

解决方案 1)
// 版本2 加锁保证, 但是存在频繁加锁的问题 -- 效率低
public static SingletonLazyMode getInstance() {
synchronized (locker) {
if (instance == null) {
instance = new SingletonLazyMode();
}
}
return instance;
}
- 加锁就保证了线程安全了
- 效率分析
- 加锁是一个成本比较高的操作, 教唆可能会引起阻塞
- 加锁的基本原则, 应该是, 非必要, 不加锁, 不能无脑加锁, 如果无脑加锁, 就会导致程序执行效率受到影响。
- 上述代码除了要保证创建对象的时候需要保证 if语句是原子, 剩下的时候条件都为 false, 所以此时的加锁就很重
解决方案 2)
// 版本3 双重判断, 避免无脑加锁 -- 效率高
public static SingletonLazyMode getInstance() {
if (instance == null) { // 条件判断是否需要加锁
synchronized (locker) {
if (instance == null) { // 条件判断是否需要创建新的对象
instance = new SingletonLazyMode();
}
}
}
return instance;
}
- 这样基本可以保证线程安全了
- 但是还存在一个特别的情况, 内存可见性的问题!!!
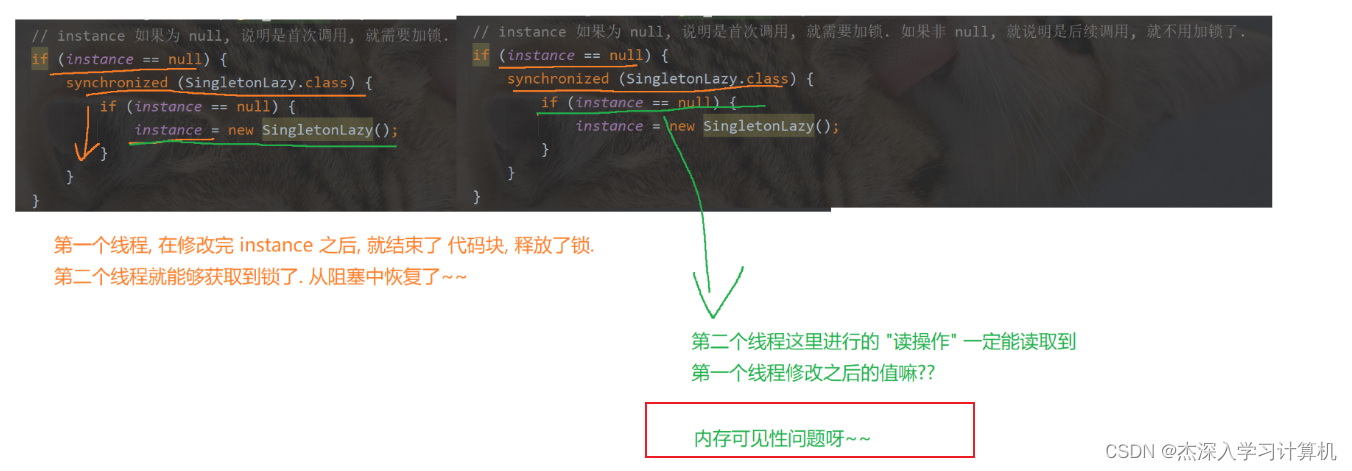
- volatile 还有一个功能, 避免指令的重排序的问题
- 指令重排序也是编译器优化一种首单
- 保证原有的逻辑不变的前提下, 对代码执行顺序进行调整, 调整之后的执行效率提高。
- 如果是单线程, 这样的重排序, 一般没事
- 如果是多线程, 就可能出现问题了
| 指令重排序可能出现的问题 |
- 对于Instance = new SingletonLazy()指令步骤
- 给对象创建出内存空间, 得到内存地址
- 在空间上调用构造方法, 对对象进行初始化
- 把内存地址, 赋值给 Instance 引用
- 此处就可能涉及到指令重排序
- 1 2 3 -> 132
- 如果是单个线程, 此时无所谓, 但是多线程就不一定了

- 给Instance加上 volatile 之后, 此时针对 Instance 进行的赋值操作, 就不会产生上述的指令重排序了, 必然按照 1 2 3 顺序执行!
解决方案 3) – 最终版本
private static volatile SingletonLazyMode instance = null; // 不是直接new
// 版本3 双重判断, 避免无脑加锁 -- 效率高
public static SingletonLazyMode getInstance() {
if (instance == null) { // 条件判断是否需要加锁
synchronized (locker) {
if (instance == null) { // 条件判断是否需要创建新的对象
instance = new SingletonLazyMode();
}
}
}
return instance;
}
// 添加限制, 让外部无法 new 出对象
private SingletonLazyMode() {
}
- Java中实现单例模式的三个关键点
- 加锁
- 双重if
- volatile
2. 阻塞队列
2.1 阻塞队列的概念
- 阻塞队列, 带有阻塞功能
- 当队列满的时候, 继续入队列, 就会出现阻塞, 阻塞到其它线程从队列中取走元素为止
- 当队列空的时候, 继续出队列, 也会出现阻塞, 阻塞到其它线程往队列中添加元素为止
2.2 使用库中的BlockingDeque
- 两个关键的方法
- put 入队列 – 具有阻塞功能
- take 出队列 – 具有阻塞功能
【使用示例】
public static void main(String[] args) throws InterruptedException {
BlockingDeque<String> queue = new LinkedBlockingDeque<>(10);
// put 入队列, take 出队列 -- 这两个方法有阻塞的功能
queue.put("Hello BlockingDeque");
String elem = queue.take();
System.out.println(elem);
elem = queue.take();
System.out.println(elem);
// offer 入队列, poll 出队列 -- 这两个方法没有阻塞的功能
// queue.offer("test");
// System.out.println(queue.poll());
// System.out.println(queue.poll());
}
2.3 模拟实现阻塞队列
public class MyBlockingDeque {
// 使用一个 String 类型的数组来保存元素. 假设这里只存 String.
private String[] strings;
// 指向队列的头部
private int head;
// 指向队列的尾部的下一个元素. 总的来说, 队列中有效元素的范围 [head, tail)
// 当 head 和 tail 相等(重合), 相当于空的队列.
private int tail;
// 使用 size 来表示元素个数.
private int size;
private final static int DEFAULT_CAPACITY = 1000;
// 加锁对象
private Object locker;
public MyBlockingDeque() {
this(DEFAULT_CAPACITY);
}
public MyBlockingDeque(int capacity) {
strings = new String[capacity];
head = tail = size = 0;
locker = new Object();
}
public void put(String str) throws InterruptedException {
synchronized (locker) {
// if (isFull()) {
while (isFull()) { // 循环判断, 保证醒来的时候队列不满了
// 队列满, 进行wait等待
locker.wait();
// return;
}
strings[tail] = str;
++tail;
if (tail >= strings.length) {
tail = 0;
}
++size;
locker.notify(); // 生产完, 唤醒消费消费者进行消费
}
}
public String take() throws InterruptedException {
synchronized (locker) {
while (isEmpty()) {
locker.wait(); // 等待生产者生产
// return null;
}
String str = strings[head];
++head;
if (head >= strings.length) {
head = 0;
}
--size;
locker.notify();
return str;
}
}
private boolean isFull() {
return size == strings.length;
}
private boolean isEmpty() {
return size == 0;
}
}
- wait方法的注意事项
- wait方法醒来的时候, 条件不一定就绪了
- 被notify唤醒的时候, 一定要用循环条件来判断条件是否成立, 这样才能保证醒来的时候, 条件已经就绪了
2.4 生产者消费者模型
生产者消费者模型的优势
-
解耦合
- 解耦合就是 “降低模块之间的耦合”
- 通过一个 “交易场所” 来时保证
- 例如可以通过阻塞队列
- 有了这个中间交易场所, 对于生产者来说, 只需要关注生产, 生产出来的任务一股脑放进这个交易场所中即可; 如果交易场所满了, 就会告知生产者, 生产者就会阻塞等待消费者行消费
- 对于消费者来说, 只需要一股脑从交易场所中取出任务即可了, 当没有任务的时候, 交易场所会告知消费者, 消费者就会进行阻塞等待生产者生产任务
- 所以这样, 如果消费者出问题了, 也不会影响到生产者, 相反也是一样的, 最多也就是阻塞等待而已; 这样就实现了解耦合操作
- 这个交易场所也可以加入更多的消费者来消费, 更多的生产者来生成, 他们之间都是互相不受影响的
-
削峰填谷
- 如果生产者生成能力大于消费者消费能力, 当生产者把交易场所填满的时候就会阻塞等待消费者消费 – 这样就使得生产者和消费者步调一致了
| 生产者消费者示例 |
public static void main(String[] args) {
BlockingDeque<Integer> queue = new LinkedBlockingDeque<>(100);
Thread consumer = new Thread(() -> {
while (true) {
try {
Integer task = queue.take();
System.out.println("消费:" + task);
// Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread producer = new Thread(() -> {
int count = 0;
while (true) {
try {
Thread.sleep(1000);
queue.put(count);
System.out.println("生产: " + count);
++count;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
consumer.start();
producer.start();
}
3. 定时器
3.1 概念
- 定时器就相当于一个闹钟, 在未来某个时间去做某件事, 起到提醒的作用
3.2 使用库的定时器 - Timer类
- 标准库中提供了一个 Timer 类, Timer 类的核心方法为 schedule
- schedule 包含两个参数, 第一个参数指定即将要执行的任务代码, 第二参数指定多长时间后执行 (单位为毫秒);
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("Hello 3");
}
}, 3000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("Hello 2");
}
}, 2000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("Hello 1");
}
}, 1000);
System.out.println("程序开始运行!");
}
- Timer 内部, 有自己的线程
- 为了保证随时可以处理新安排的任务, 这个线程会持续执行, 并且这个线程还是个前台线程
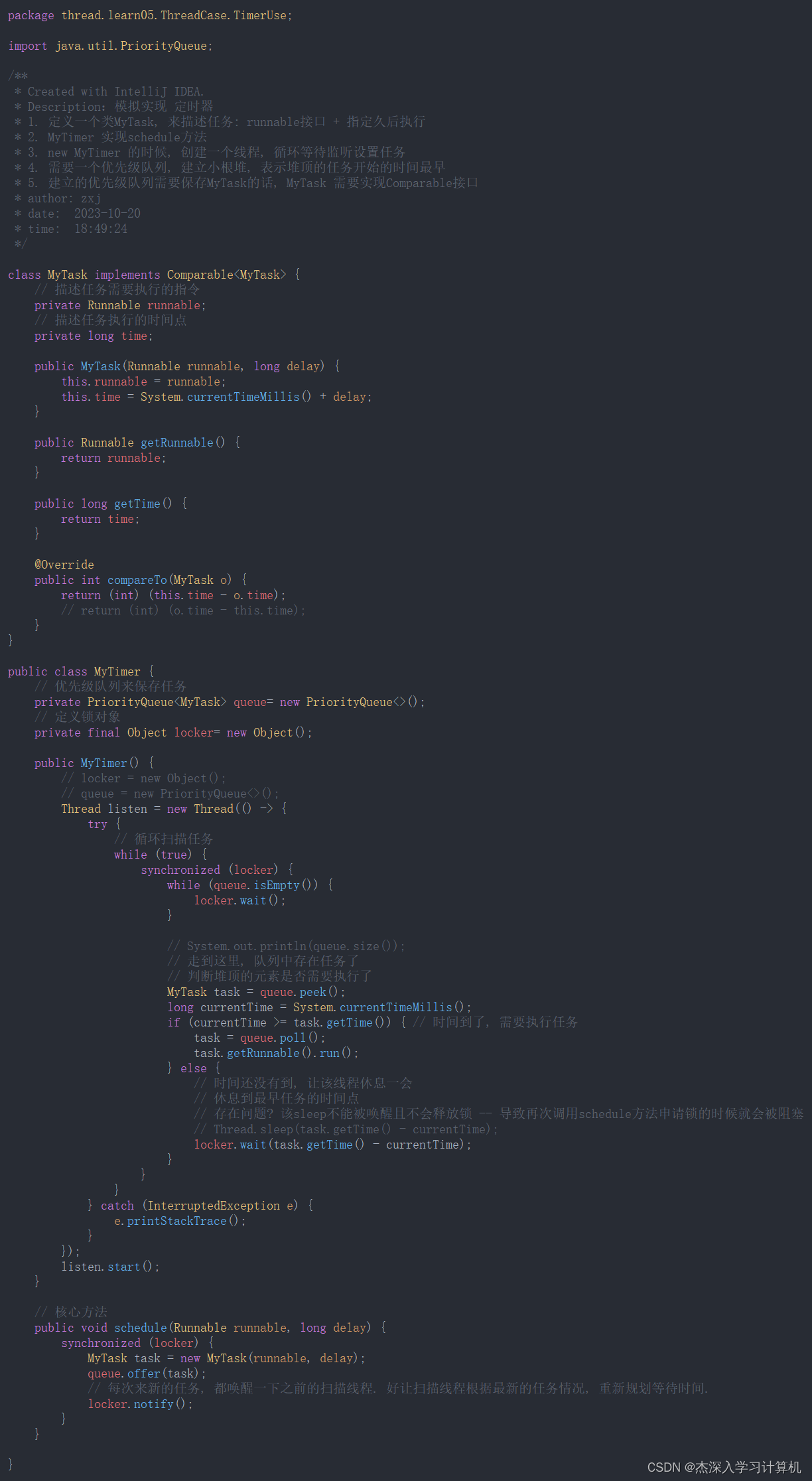
3.3 模拟实现定时器

4. 线程池
4.1 概念
-
池的作用: 就是提高效率的
- 有 线程池
- 内存池
- 进程池
- 常量池
- …
-
线程池的作用
- 如果我们需要频繁的创建销毁线程, 此时创建销毁线程的成本, 就不能忽视了, 因此就可以使用线程池
- 提前创建好一波线程, 后续需要使用下层, 就直接从池子里拿一个一个即可
- 当线程不在使用, 就放回池子里面
- 这样就可以避免频繁的创建和销毁线程了
-
本来, 是需要创建线程/销毁线程; 现在, 是从池子里获取现成的线程, 并且把用完的线程归还到池子中
- 为啥, 从池子里取, 就比从系统这里创建线程更快更高效呢?
- 如果从系统这里创建线程, 需要调用系统 API, 进一步的由操作系统内核完成线程的创建过程 (内核是给所有进程提供服务的) – 这不可控
- 如果从线程池里面获取现成, 上述的内核中进行的操作, 都提前做好了, 现在的取线程的过程, 纯粹的由用户代码完成(纯用户态) 这是可控的
- 为啥, 从池子里取, 就比从系统这里创建线程更快更高效呢?
4.2 使用库中的线程池
工程模式
- 工厂使用来生产的, 所以工程模式是用来生产对象的
- 设计原因
-
一般创建对象, 都是通过new, 通过构造方法, 但是构造方法, 存在重大缺陷; 构造方法的名字固定是类名, 有的类, 需要有多种不同的构造方法, 但是构造方法的名字有固定, 就只能使用方法重载的方式来实现了, 当时这里存在一定的局限性!

-
此时工厂模式就可以解决上述的问题了
- 使用工厂模式, 不适用构造方法了, 使用普通的方法来构造对象, 这样的方法名就可以是任意的了
- 普通方法内部, 在new 对象 – 由于普通方法的目的是为了创建对象来, 这样的方法一般都是静态的

-
使用工程模式创建线程池
- 使用 Executors.newFixedThreadPool(10) 能够创建出固定包含 10 个线程的线程池
- 返回值类型为 ExecutorServer
- 通过ExecutorServer.submit 可以注册一个任务到线程池中
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(10);
for (int i = 0; i < 1000; i++) {
pool.submit(() -> {
System.out.println("Hello thread Pool");
});
}
}
- Executors 创建线程池的几种方式
- newFixedThreadPool: 创建固定线程数的线程池
- newCachedThreadPool: 创建线程数目动态增长的线程池
- newSingleThreadExecutor: 创建只包含当个线程的线程池
- newScheduleThreadPool: 设定延迟时间后执行命令, 后定期执行命令, 是进阶版的 Timer
- Executors 本质是ThreadPoolExecutor 类的封装
使用 Java原生的线程池构造方法来创建 (重点)

- 参数含义:
- int corePoolSize
- 核心线程数
- ThreadPoolExecutor 里面的线程个数, 并非是固定不变的, 会根据当前任务的情况动态发生变化(自适应)
- 至少得有这些线程, 哪怕线程里面的人物一点也没有
- int maximumPoolSize
- 最大线程数
- 最多不能超过这些线程, 哪怕线程池忙的冒烟了, 也不能比这个数目更多了
- int corePoolSize
上述两个参数, 做到了既能保证繁忙的时候高效处理任务, 又能保证空间的时候不会浪费资源
- long keepAliveTime, TimeUnit unit
- 前者表示的是数值; 后者是一个枚举变量, 里面定义时间的各种单位
这个两个参数, 说明了, 多余的线程, 空间闲时间超过指定的时间阈值, 就可以被销毁了!
- BlockingQueue<Runnable> workQueue
- 线程池内部有很多任务, 这些任务可以使用阻塞队列来管理
- 线程池可以内置阻塞队列, 也可以手动指定一个
- ThreadFactory threadFactory
- 工厂模式, 通过这个工厂类创建线程
- RejectedExecutionHandler handler
- 线程池考察的重点, 拒绝方式/拒绝策略
- 线程池, 有一个阻塞队列, 当阻塞队列满了之后, 继续添加任务, 应该如何应对
- 对应的处理动作如下
- ThreadPoolExecutor.AbortPolicy
- 直接抛出异常, 线程池直接不干活了
- ThreadPoolExecutor.CallerRunsPolicy
- 谁是添加这个新任务的线程, 谁就去执行这个任务
- ThreadPoolExecutor.DiscardOldestPolicy
- 丢弃最早的任务, 执行新的任务
- ThreadPoolExecutor.DiscardPolicy
- 直接把这个新的任务给丢弃了
- ThreadPoolExecutor.AbortPolicy
创建线程池方法的总结
上述都是创建线程池的手段, 具体用什么方法创建线程池, 主要看的是具体的应用场景
线程池中线程数量的思考
- 线程池中线程的数量主要是看线程工作的类型来决定的
- 主要应用类型所对应的线程数量
- “CPU密集型”
- 此时线程的工作全是运算
- 大部分工作都是在 CPU 上完成的, CPU 得给他安排核心去完成工作, 才可以有进展
- 如果 CPU 是 N 个核心, 当你线程数量也是 N 的时候, 理想情况 每个 核心 上一个线程
- 如果搞很多线程, 线程也是在排队等待, 不会有新的进展
- “IO密集型”
- 读写文件, 等待用户输入, 网络通信
- 涉及到大量的等待事件, 等待的过程中没有使用 CPU
- 这样的线程就算更多写, 也不会给CPU 造成太大的负担
- 比如 CPU 是 16 个核心, 写 32 个线程 – 由于是 IO 密集的, 这里的大部分线程都在等, 都不消耗 CPU, 反而 CPU 的占用情况还很低
- 读写文件, 等待用户输入, 网络通信
- “CPU密集型”
- 实际开发中, 一个线程往往是一部分工作是 CPU 密集的, 一部分工作是 IO 密集的; 此时, 一个线程, 几成是在 CPU 上运行, 几成实在等待IO, 说不好; 这里更好的做法, 是通过实验的方法, 来找到合适的线程数!
- 性能测试, 尝试不同的线程数目, 尝试过程中, 找打性能和系统资源开销比较均衡的数值
4.3 线程池模拟实现
public class MyThreadPool {
BlockingDeque<Runnable> queue = new LinkedBlockingDeque<>(10);
// 通过这个方法, 来把任务添加到线程池中.
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
// n 表示线程池里有几个线程.
// 创建了一个固定数量的线程池.
public MyThreadPool(int n) {
for (int i = 0; i < n; i++) {
Thread t = new Thread(() -> {
while (true) {
try {
// 取出任务, 并执行~~
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}
}