目录
前言
一、Google的四类黄金指标
二、RED方法
三、USE方法
RED方法 vs USE方法
四、监控指标
WEB服务监控
MySQL数据库监控
QPS
TPS
最大连接数
缓存监控
总结
前言
众所周知,业界各种大中型软件系统在生产运行时,总会有一些手段来进行保驾护航。Metric 机制作为一个非常重要的监控手段,与日志系统,告警系统,APM 等,共同守护业务系统运行安全。没有“运行时监控机制”的软件系统都是不合格的系统,是根本没有资格上到生产环境上去的,因为掌握不了软件系统的运行状况,就像一个瞎子开着汽车上路了,是极其危险的。Metric 机制承担着收集软件系统各种监控指标的职责,提供的各个监控指标能够帮助运维人员进行系统运行状态的研判,配合告警系统及时进行预警,在出现异常情况的时候,给日志分析团队指明“问题查找”的方向。总之,Metric 的重要程度非常高,可以认为是不可或缺的非功能性需求。
一、Google的四类黄金指标
Four Golden Signals是Google针对分布式监控进行的经验总结,将需要重点关注的监控数据分为四类:
- 延迟(Latency):此类指标聚焦于请求所需要花费的时间的指标纬度。一般通过关注成功请求相应的延迟和失败请求相应的延迟的区别,过长的延迟会导致事件响应的时间推后,同时也会使得用户的体验变差,此类指标对于衡量和改善终端用户体验一般有重要的作用,同时延迟很多时候也是性能变差的一个重要外在显示,对于早期发现和定位性能问题也有一定的作用。
- 流量(Traffic): 此类指标聚焦于系统所需要承受的用户或者交易的量级相关的指标纬度。比如基于Web的HTTP应用服务此类指标可能表现为TPS或者QPS。通过监控此类实施的用户交互和流量相关的指标数据,能够对于系统所承受的压力负载状况有一个更好地把握,同时对于所能能够承受的压力峰值也能有一个更为清晰的判断。
- 错误(Errors): 此类指聚焦于系统错误相关的指标纬度。错误是任何系统都需要关注的内容,它不但能衡量系统的质量状况,同时也是后续事件管理需要开始的信号。错误一般分为显示错误和隐式错误两类,显示错误可能会直接体现为HTTP 500的错误返回,这类错误一般直接在诸如Nginx这样的应用服务器的日志中就能进行抓取和确认,而隐式错误则往往跟具体的业务应用相关,虽然返回了HTTP 200的正常值,但是有可能在业务上仍然是失败的,这类错误则一般需要根据具体情况在系统中埋点来实现。
- 饱和度(Saturation): 此类指标聚焦于系统资源使用率的饱和状况的指标纬度。这类指标一般回答的是“某类会影响系统的资源离饱和(100%或者已经会影响到系统动作的程度)还有多远”的问题。因为一旦这些关键的资源达到饱和状态,整体系统性能就会出现明显下降,是监控系统中需要注意的指标类型。
这四类指标是Google SRE的经验积累,所观测的指标对于系统的可靠性非常重要,是监控系统创建时的有益参考。
二、RED方法
RED是Weave Cloud所提供的方法,这种方法完全以Google的4类黄金指标为基础,以应用请求相关的R(Rate:请求速率)、E(Error:请求错误)和D(Duration:请求耗时)三种关键指标为中心所创建监控体系的方法,被成为RED方法,对于云原生应用或者为微服务架构下的应用有很好地借鉴作用。
RED方法定义了微服务架构中所需要定义的三种指标:
- 请求速率(Request) Rate:每秒服务所需要处理请求数量
- 请求错误(Request) Errors: 每秒失败的请求数量
- 请求耗时(Request) Duration: 每个请求所消耗的时间
三、USE方法
USE方法的全称是Utilization Saturation and Errors Method,相较于RED方法,USE方法从资源使用率(Utilization)、资源饱和度(Saturation)和错误等指标纬度进行监控和分析,在帮助用户进行系统性能分析、资源瓶颈识别等方面有较好的效果。具体指标说明如下所示:
- 资源使用率:系统资源诸如CPU、内存、网络、磁盘IO等相关的使用率信息,某项资源长时间较高使用率通常是系统性能瓶颈的标志。
- 资源饱和度:资源一旦达到饱和程度将会显著影响系统性能,资源饱和度指标主要包括各种影响系统性能的指标信息。
- 错误:错误相关的指标统计信息。
RED方法 vs USE方法
可以看到使用RED方法或者USE方法都可以对服务进行监控,具体选择可根据如下特点进行:
- RED方法:主要适用于单纯关注与请求相关的指标数据
- USE方法:可以提供资源使用率和饱和度的指标信息,对于系统性能监控和性能瓶颈分析可以起到很好的作用。
四、辅助手段
除了在生产和测试环境中被动的等待和确认系统状况,还可以通过更为主动的方式进行持续的学习从而构建更加可靠的系统,而这些离不开一些主动的辅助手段,比如:
- 混沌工程(Chaos Engineering): 更准确地来说,混沌工程是作为团队持续实验中的一项最佳实践而进行,这项最佳实践的目的就是为了更好地了解系统,尤其是系统的脆弱性,通过主动的向服务中诸如错误或者混乱状况,可以更好地观察系统在这种情形之下的表现。
- 游戏日(Game Days): 混沌工程是为了帮助我们更好地了解系统,而游戏日则是为了更好地了解系统相关的人员如何协同作业。 游戏日实际上就是灾难或者故障的演习,通过游戏日则能更好地检验团队对于故障或者事件相应的弹性能力。而且通过游戏日的实践可以进行持续的改进。
- 合成监控(Synthetic Monitoring): 合成监控的重点在于通过创建模拟的用户和用户行为来确认系统的运行状况,这是一种更加主动的方法,使得测试不再过度依赖于最终用户的使用,可以事先更好地对于可能出现的各种问题进行验证和结果确认,从而创建更好的系统。
五、监控指标
一些组件或者服务还有独特的指标,这些指标也是需要你特殊关注的。比如,数据库主从延迟数据、消息队列的堆积情况、缓存的命中率等等。
| 组件 | 延迟 | 通信量 | 错误 | 饱和度 | 其他 |
|---|---|---|---|---|---|
| WEB服务 | 响应时间 | 请求量 | 4** 5**请求量 业务错误 | tomcat线程池的 任务堆积数, 活跃线程数 | |
| MySQL数据库 | 响应时间 慢SQL | 每秒执行操作数 QPS | 请求超时 错误数量 | 连接数 | 主从延迟 CPU 内存 |
| 缓存 | 响应时间 慢请求 | 请求量 OPS每秒操作数 | 请求超时 错误数量 | 连接数 | BigKey, 命中率 缓存已用容量 |
| 消息队列 | 响应时间 | 请求量 | 请求超时 错误数量 | 消息堆积 | |
| JVM | GC时间 | GC频率 | 内存区域大小 | ||
| 依赖的服务 | 响应时间 | 请求量 | 请求超时 错误数量 |
WEB服务监控
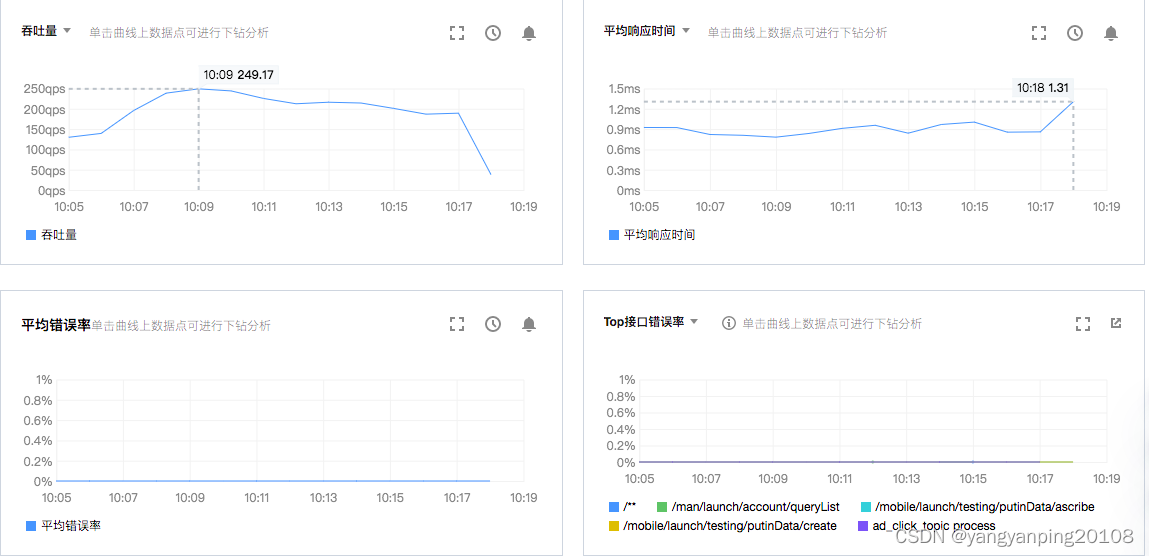
MySQL数据库监控
QPS
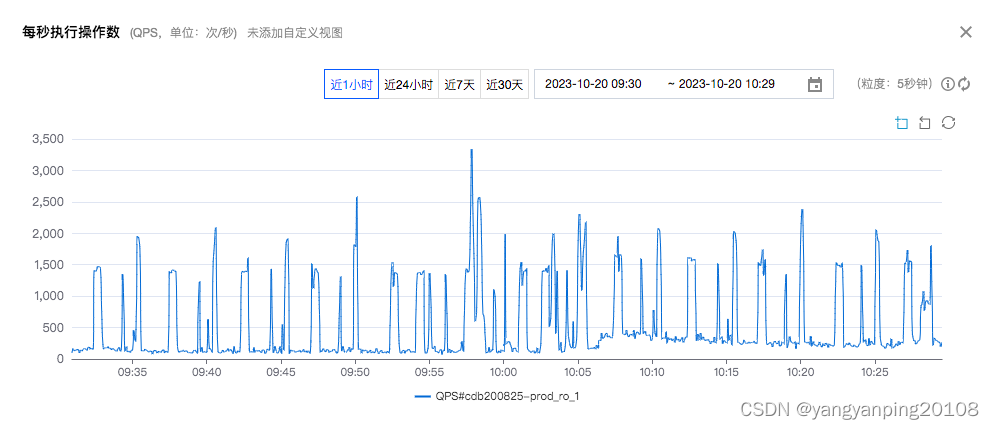
TPS
最大连接数
缓存监控

六、如何采集数据指标
说到监控指标的采集,我们一般会依据采集数据源的不同,选用不同的采集方式,总结起来,大概有以下几种类型:
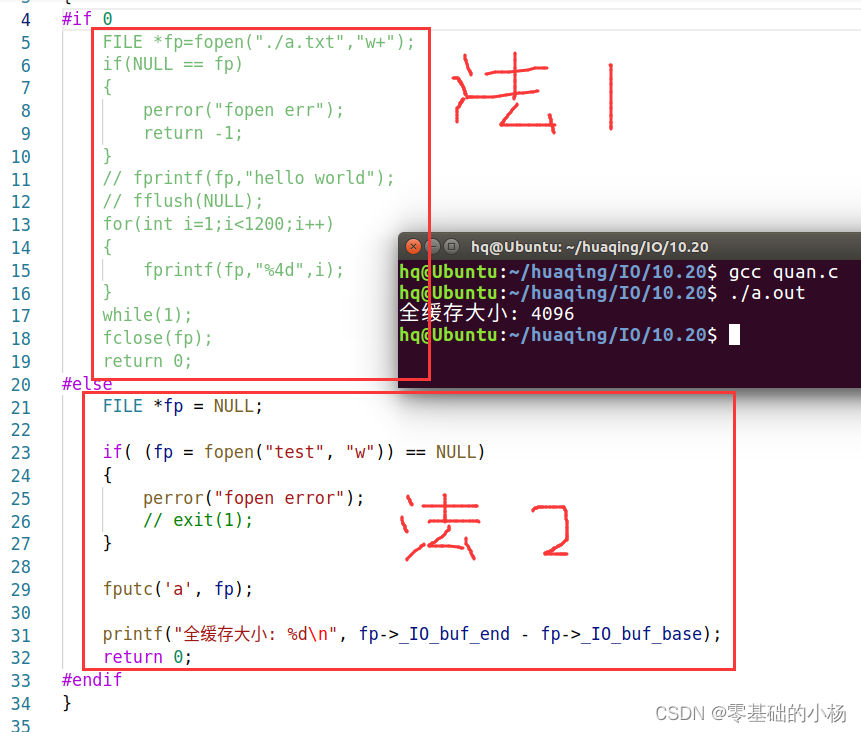
首先,Agent 是一种比较常见的,采集数据指标的方式。
我们通过在数据源的服务器上,部署自研或者开源的 Agent,来收集数据,发送给监控系统,实现数据的采集。在采集数据源上的信息时,Agent 会依据数据源上,提供的一些接口获取数据,我给你举两个典型的例子。
比如,你要从 Redis 服务器上,获取它的性能数据,那么,你就可以在 Agent 中,连接这个 Redis 服务器,并且发送一个 stats 命令,获取服务器的统计信息。然后,你就可以从返回的信息中,挑选重要的监控指标,发送给监控服务器,形成Redis 服务的监控报表。你也可以从这些统计信息中,看出当前 Redis 服务器,是否存在潜在的问题。
redis-cli --stat【连续统计】
连续统计可能是实时监控 Redis 实例的鲜为人知但非常有用的功能之一,要启用此功能,请使用redis-cli --stat。
redis-cli --stat 默认每秒输出一条新行,其中包含有用信息和每个采集点的请求次数差异。使用此命令可以轻松了解内存使用情况、客户端连接计数以及有关已连接 Redis 数据库的各种其他统计信息。
可以使用-i修改采样频率,默认值为1秒,如下面这个命令代表每2s采集一次数据:
yangyanpingdeMacBook-Air:bin yangyanping$ redis-cli --stat -i 2
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
1 1.02M 1 0 1 (+0) 4
1 1.02M 1 0 2 (+1) 4
1 1.02M 1 0 3 (+1) 4
1 1.02M 1 0 4 (+1) 4
1 1.02M 1 0 5 (+1) 4
1 1.02M 1 0 6 (+1) 4
1 1.02M 1 0 7 (+1) 4
1 1.02M 1 0 8 (+1) 4
1 1.02M 1 0 9 (+1) 4
1 1.02M 1 0 10 (+1) 4
1 1.02M 1 0 11 (+1) 4
1 1.02M 1 0 12 (+1) 4
^C
yangyanpingdeMacBook-Air:bin yangyanping$ redis-cli --bigkeys【统计大key】
这个命令用作键空间分析器,它扫描数据集中的大键,但也提供有关数据集所包含的数据类型的信息。
yangyanpingdeMacBook-Air:bin yangyanping$ redis-cli --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '"test"' with 4 bytes
-------- summary -------
Sampled 1 keys in the keyspace!
Total key length in bytes is 4 (avg len 4.00)
Biggest string found '"test"' has 4 bytes
1 strings with 4 bytes (100.00% of keys, avg size 4.00)
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
yangyanpingdeMacBook-Air:bin yangyanping$七、监控数据的处理和存储
在采集到监控数据之后,你就可以对它们进行处理和存储了,在此之前,我们一般会先用消息队列来承接数据,主要的作用是削峰填谷,防止写入过多的监控数据,让监控服务产生影响。
与此同时,我们一般会部署两个队列处理程序,来消费消息队列中的数据。一个处理程序接收到数据后,把数据写入到 Elasticsearch,然后通过 Kibana 展示数据,这份数据主要是用来做原始数据的查询;另一个处理程序是一些流式处理的中间件,比如,Spark、Storm。它们从消息队列里,接收数据后会做一些处理,这些处理包括:
- 解析数据格式,尤其是日志格式。从里面提取诸如请求量、响应时间、请求 URL 等数据;
- 对数据做一些聚合运算。 比如,针对 Tomcat 访问日志,可以计算同一个 URL 一段时间之内的请求量、响应时间分位值、非 200 请求量的大小等等。
- 将数据存储在时间序列数据库中。这类数据库的特点是,可以对带有时间标签的数据,做更有效的存储,而我们的监控数据恰恰带有时间标签,并且按照时间递增,非常适合存储在时间序列数据库中。目前业界比较常用的时序数据库有 InfluxDB、OpenTSDB、Graphite,各大厂的选择均有不同,你可以选择一种熟悉的来使用。
- 最后, 你就可以通过 Grafana 来连接时序数据库,将监控数据绘制成报表,呈现给开发和运维的同学了。
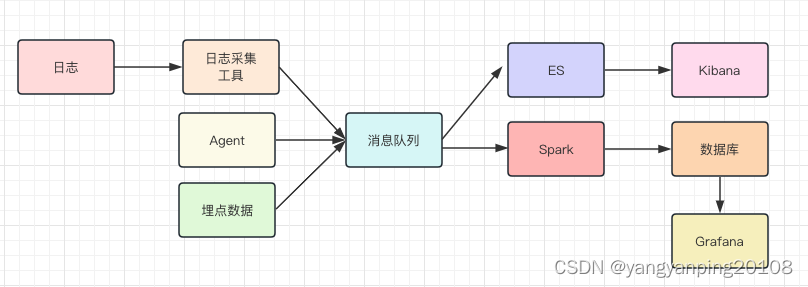
至此,你和你的团队,也就完成了垂直电商系统,服务端监控系统搭建的全过程。这里我想再多说一点,我们从不同的数据源中采集了很多的指标,最终在监控系统中一般会形成以下几个报表,你在实际的工作中可以参考借鉴:
1. 访问趋势报表。这类报表接入的是 Web 服务器,和应用服务器的访问日志,展示了服务整体的访问量、响应时间情况、错误数量、带宽等信息。它主要反映的是,服务的整体运行情况,帮助你来发现问题。
2. 性能报表。 这类报表对接的是资源和依赖服务的埋点数据,展示了被埋点资源的访问量和响应时间情况。它反映了资源的整体运行情况,当你从访问趋势报表发现问题后,可以先从性能报表中,找到究竟是哪一个资源或者服务出现了问题。
3. 资源报表。 这类报表主要对接的是,使用 Agent 采集的,资源的运行情况数据。当你从性能报表中,发现某一个资源出现了问题,那么就可以进一步从这个报表中,发现资源究竟出现了什么问题,是连接数异常增高,还是缓存命中率下降。这样可以进一步帮你分析问题的根源,找到解决问题的方案