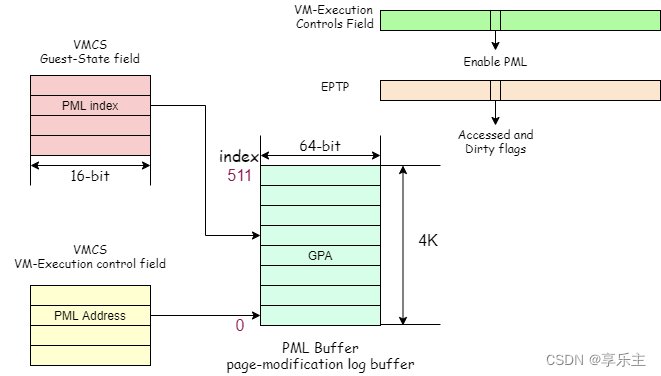
Dirty-Ring基于Intel PML(page-modification log buffer)实现,我们首先介绍PML工作流程,其框架如下: Intel VT-x提供的VMCS(virtual machine control structure)中,有三个地方与PML特性相关:
Extended-Page-Table Pointer: EPTP字段中的bits[6],控制当物理CPU访问内存页后,硬件是否将对应的accessed and dirty flags 置位,PML需要开启。
VM-execution control fields: 控制区域中的Secondary Processor-Based VM-Execution Controls子字段的bits[17]控制位用于控制是否开启PML,PML需要开启。Control Field for Page-Modification Logging存放一段4K物理内存的地址,这段内存是就是PML的buffer,其内容是vCPU访问的物理内存页地址(GPA), 每条地址64bit,一共512条,因此其大小为512 * 64bit = 4K:
Guest State area: Guest状态字段中的PML index子字段,用于指示物理CPU将下一次访问的内存地址记录到PML buffer的哪一条,一旦设置好,CPU填写了一条PML entry后,硬件会自动将PML index加1。
使能PML的整个流程是,开启EPTP的页表标脏功能,开启VM-execution control fields的PML开关,为每个CPU的PML buffer分配4K内存,将内存地址填入VM-execution control fields的地址字段,最后设置将CPU填写PML buffer的起始位置写入PML index,执行VMLAUNCH指令进入guest模式。
kvm_cpu_exec
/* 执行vCPU线程,陷入内核 */
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
/* 从内核exit到用户态空间 */
switch (run->exit_reason) {
/* 根据exit_reason做对应处理 */
case KVM_EXIT_IO:
......
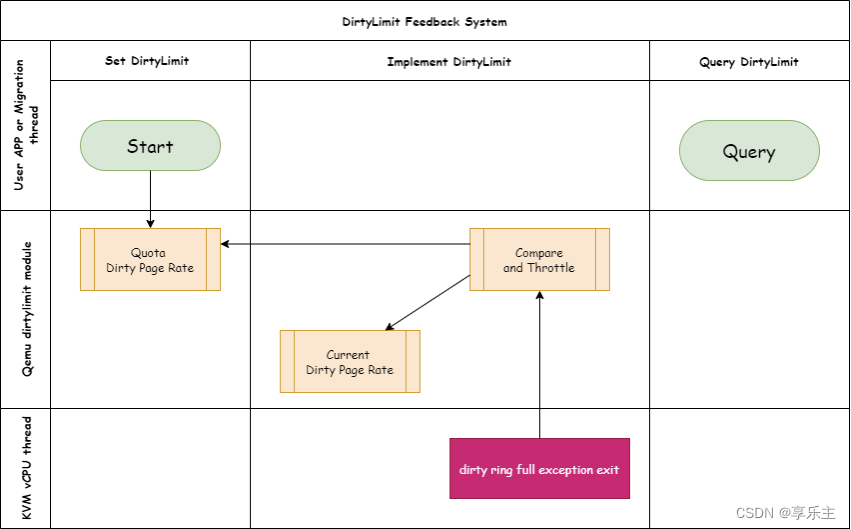
/* 如果退出是由于Dirty-Ring满了,做对应的处理
* 这里QEMU的主要工作就是清空Dirty-Ring,让内核可以继续填写
*/
case KVM_EXIT_DIRTY_RING_FULL:
/*
* We shouldn't continue if the dirty ring of this vcpu is
* still full. Got kicked by KVM_RESET_DIRTY_RINGS.
*/
trace_kvm_dirty_ring_full(cpu->cpu_index);
qemu_mutex_lock_iothread();
/*
* We throttle vCPU by making it sleep once it exit from kernel
* due to dirty ring full. In the dirtylimit scenario, reaping
* all vCPUs after a single vCPU dirty ring get full result in
* the miss of sleep, so just reap the ring-fulled vCPU.
*/
if (dirtylimit_in_service()) {
/* 当dirty-limit开启时,仅清空对应vCPU的Dirty-Ring
* 这样可以保证每个vCPU满了之后都会走到该路径,保证其接受惩罚
* 如果某个vCPU满了,但是这里我们把所有vCPU的Dirty-Ring都清空的话
* 就会导致有些脏页速率较大的vCPU永远接收不到惩罚 */
kvm_dirty_ring_reap(kvm_state, cpu);
} else {
kvm_dirty_ring_reap(kvm_state, NULL);
}
qemu_mutex_unlock_iothread();
/* 调用睡眠函数,实施最终的惩罚 */
dirtylimit_vcpu_execute(cpu);
ret = 0;
break;
......
QEMU 8.1.50 monitor - type 'help' for more information
(qemu) migrate_set_capability
auto-converge background-snapshot block
compress dirty-bitmaps dirty-limit
events late-block-activate multifd
pause-before-switchover postcopy-blocktime postcopy-preempt
postcopy-ram rdma-pin-all release-ram
return-path switchover-ack validate-uuid
x-colo x-ignore-shared xbzrle
zero-blocks zero-copy-send
(qemu) migrate_set_capability dirty-limit on
(qemu) migrate -d tcp:192.168.31.155:9000
/* 查看迁移使用的capability,可以看到dirty-imit被开启 */
(qemu) info migrate_capabilities
xbzrle: off
rdma-pin-all: off
auto-converge: off
zero-blocks: off
compress: off
events: off
postcopy-ram: off
x-colo: off
release-ram: off
block: off
return-path: off
pause-before-switchover: off
multifd: off
dirty-bitmaps: off
postcopy-blocktime: off
late-block-activate: off
x-ignore-shared: off
validate-uuid: off
background-snapshot: off
zero-copy-send: off
postcopy-preempt: off
switchover-ack: off
dirty-limit: on
/* 查看迁移过程中的实时数据,dirty-limit会在迁移迭代的第三轮开启 */
(qemu) info migrate
globals:
store-global-state: on
only-migratable: off
send-configuration: on
send-section-footer: on
decompress-error-check: on
clear-bitmap-shift: 18
Migration status: active
total time: 3433 ms
expected downtime: 300 ms
setup: 33 ms
transferred ram: 23936 kbytes
throughput: 26.16 mbps
remaining ram: 1438576 kbytes
total ram: 4195080 kbytes
duplicate: 684655 pages
skipped: 0 pages
normal: 4471 pages
normal bytes: 17884 kbytes
dirty sync count: 1
page size: 4 kbytes
multifd bytes: 0 kbytes
pages-per-second: 363313
precopy ram: 23936 kbytes
/* 再次查看迁移信息,dirty-limit有相关信息输出 */
(qemu) info migrate
globals:
store-global-state: on
only-migratable: off
send-configuration: on
send-section-footer: on
decompress-error-check: on
clear-bitmap-shift: 18
Migration status: active
total time: 372685 ms
expected downtime: 63130 ms
setup: 19 ms
transferred ram: 3598269 kbytes
throughput: 99.79 mbps
remaining ram: 386204 kbytes
total ram: 4195080 kbytes
duplicate: 822808 pages
skipped: 0 pages
normal: 895998 pages
normal bytes: 3583992 kbytes
dirty sync count: 5
page size: 4 kbytes
multifd bytes: 0 kbytes
pages-per-second: 3039
dirty pages rate: 2015 pages
precopy ram: 3598269 kbytes
dirty-limit throttle time: 23272722 us
dirty-limit ring full time: 235078 us
前置条件 一、本文章讨论的成员变量 public static final String aa "aa";public static final Integer bb 1;public static final Students cc new Students();public static String aa1 "aa";public static Integer bb1 1;public static String bb2…