Pandas 简介
Pandas 库是机器学习四个基础库之一, 它有着强大的数据分析能力和处理工具。它支持数据增、删、改、查;支持时间序列分析功能;支持灵活处理缺失数据;具有丰富的数据处理函数;具有快速、灵活、富有表现力的数据结构:DataFrame 数据框和 Series 系列。
官方文档:API reference — pandas 2.1.1 documentation
Pandas 读取与存储数据
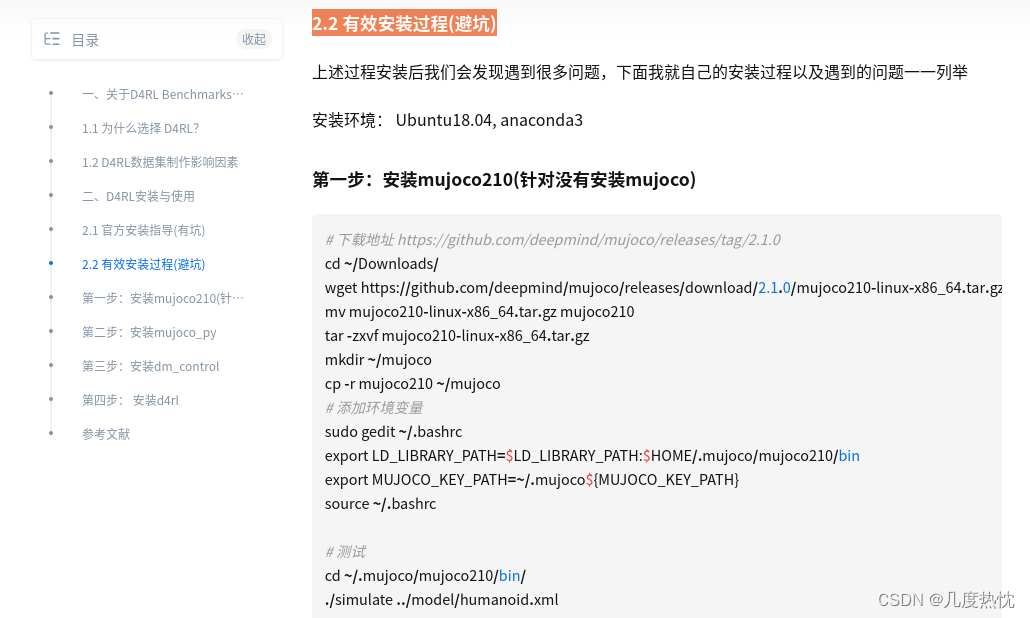
1、csv文件读取
read_csv(filepath_or_buffer, sep=',', header='infer', names=None, index_col=None, dtype=None, engine=None, nrows=None)
| 参数名称 | 说明 |
|---|---|
| filepath | 接收 string。代表文件路径。无默认。 |
| sep | 接收 string。代表分隔符。read_csv 默认为' , ',read_table 默认为制表符 '[Tab]'。 |
| header | 接收 int 或 sequence。表示将某行数据作为列名。默认为 infer,表示自动识别。 |
| names | 接收 array。表示列名。默认为 None。 |
| index_col | 接收 int、sequence 或 False。表示索引列的位置,取值为 sequence 则代表多重索引。默认为 None。 |
| dtype | 接收 dict。代表写入的数据类型(key:列名,values:数据格式)。默认为 None。 |
| engine | 接收 C 或者 Python。代表数据解析引擎。默认为 C。 |
- sep 参数是指定文本的分隔符,如果分隔符指定错误,在读取数据的时候,每一行数据将连城一片。
- header 参数是用来指定列名,如果是 None 则会添加一个默认的列名。
- encoding 代表文件的编码格式,常用的编码有 utf-8、utf-16、gbk、gb18030、big5 等。如果编码指定错误,数据将无法读取,Ipython 解释器会报解析错误。
import numpy as np
import pandas as pd
df = []
df = pd.read_csv(file, dtype='str') # 所有数据转为字符串
df = df.replace(np.nan, '') # 空数据转为空字符串
print(df)2、excel文件读取
pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None, dtype=None)
| 参数名称 | 说明 |
|---|---|
| io | 接收 string。代表文件路径。无默认。 |
| sheet_name | 接收 string 或 int。代表 excel 表内数据的分表位置。默认为0。 |
| header | 接收 int 或 sequence。表示将某行数据作为列名。默认为 infer,表示自动识别。 |
| names | 接收 int、sequence 或 False。表示索引列的位置,取值为 sequence 则代表多重索引。默认为 None。 |
| index_col | 接收 int、sequence 或 False。表示索引列的位置,取值为 sequence 则代表多重索引。默认为 None。 |
| dtype | 接收 dict。代表写入的数据类型(列名为 key,数据格式为 values)。默认为 None。 |
import pandas as pd
import numpy as np
df = []
ws = pd.ExcelFile(file)
sheets = ws.sheet_names
print(sheets)
for sheet in sheets:
tem_df = pd.read_excel(file, sheet_name=sheet, dtype='str')
tem_df = tem_df.replace(np.nan, '')
if len(df) == 0:
df = tem_df
else:
df = pd.concat([df, tem_df])
print(df)3、储存数据
dict数据存储
result = {
'A': [1.0,2.2,3,4],
'B': [7,8,9,0],
'C': [1,2,3,4],
'D': [3,5,7,9]
}
df = pd.DataFrame.from_dict(result)
# 输出csv
df.to_csv(out_file_csv, index=False)
# 输出excel
df.to_excel(out_file_excel, index=False)多维数据存储
result = [[1.0,2.2,3,4],[1,2,3,4],[7,8,9,0],[3,5,7,9]]
columns_result = ['A', 'B', 'C', 'D']
df = pd.DataFrame(result, columns=columns_result)
# 输出csv
df.to_csv(out_file_csv, index=False)
# 输出excel
df.to_excel(out_file_excel, index=False)excel存储限制,单sheet页只能存100万条数据
result = [[1.0,2.2,3,4],[1,2,3,4],[7,8,9,0],[3,5,7,9]]
columns_result = ['A', 'B', 'C', 'D']
# 输出excel
writer = pd.ExcelWriter(out_file)
result_df = pd.DataFrame(result, columns=columns_result)
page_size = 500000
page_num = math.ceil(len(result_df) / page_size)
for i in range(page_num):
s_idx = i * page_size
e_idx = (i + 1) * page_size if (i + 1) * page_size < len(result_df) else len(result_df)
tmp_df = result_df[s_idx:e_idx]
tmp_df.to_excel(writer, sheet_name="Sheet{}".format(i + 1), index=False)
writer._save()Pandas增删改查操作
1、访问数据框中的元素
- 对某一列的某几行访问:访问 DataFrame 中的某一列的某几行时,单独一列的 DataFrame 可以视为一个 Series,而访问一个 Series 和访问一个一维的 ndarray 基本相同。
- 对多列数据访问:访问 DataFrame 多列数据可以将多个列索引名称视为一个列表,同时访问 DataFrame 多列数据中的多行数据和访问单列数据的多行数据方法基本相同。
- 对某几行访问:head 和 tail 函数可以得到多行数据,但是用这两种方法得到的数据都是从开始或末尾获取的连续数据。默认参数为访问五行。
import pandas as pd
d = [[1.0,2.2,3,4],[1,2,3,4],[7,8,9,0],[3,5,7,9]]
df = pd.DataFrame(d, columns=['A', 'B', 'C', 'D'])
print(df)
print(df['A']) # 单列数据访问
print(df[['A', 'C']]) # 多列数据访问
print(df.head(3)) # 访问前三行数据
print(df.tail(3)) # 访问后三行数据
print(df[0:4]) # 访问前三行数据
print(df[:-4]) # 访问后三行数据loc、iloc 方法
DataFrame.loc[行索引名称,列索引名称],如果传入的不是索引名称,那么切片操作将无法执行。
DataFrame.iloc[行索引位置,列索引位置],如果传入的不是索引位置,那么切片操作将无法执行。
loc 方法的代码灵活多变,代码的可读性更高;iloc 方法的代码简洁,但可读性不高。
使用 loc、iloc 方法访问查看 DataFrame 中的数据:
- 使用 loc、iloc 方法实现多列切片,其原理是将多列的列名或者位置作为一个列表或者数据传入。
- 使用 loc、iloc 方法可以取出 DataFrame 中的任意数据。
- 在使用 loc 方法的时候内部传入的行索引名称如果为一个区间,则前后均为闭区间。其内部还可以传入表达式,结果会返回满足表达式的所有值。
- 在使用 loc 方法的时候内部传入的行索引位置或列索引位置为区间时,则为前闭后开区间。
- 使用 loc 方法能够实现所有单层索引切片操作。
# 按照行列顺序进行数据访问
print(df.iloc[0, 0]) # 取出第一行第一列的数据
print(df.iloc[0:3, 0]) # 取出前三行第一列的数据
print(df.iloc[:, 0]) # 取出第一列的数据
print(df.iloc[0, :]) # 取出第一行的数据
print(df.iloc[1:3, 1:3])
# 按照行列名称进行数据访问
print(df.loc['a', 'A']) # a行,A列
print(df.loc['a':'c', 'A']) # a到c行,A列
print(df.loc[:, 'A']) # 访问第A列的元素
print(df.loc['a', :]) # 访问第a行的元素
print(df.loc[['b','c'], ['B', 'C']])
# 注意如下方式返回值的区别
print(df.iloc[:, 0]) # 返回的是 Series
print(df.iloc[:, 0:1]) # 返回的是 DataFrame
print(type(df.iloc[:, 0]))
print(type(df.iloc[:, 0:1]))
df.iloc[:, 0:1]循环查询,使用 iterrows() 方法循环遍历行
import pandas as pd
# 创建数据帧
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 使用 iterrows() 方法遍历行
for index, row in df.iterrows():
print(index, row['A'], row['B'])2、修改数据框中的元素
更改 DataFrame 中的数据,原理是将这部分数据提取出来,重新赋值为新的数据。需要注意的是,数据更改直接针对 DataFrame 原数据更改,操作无法撤销。所以在做出更改前最好对数据进行备份。
DataFrame.loc[行索引名称,行索引名称] = new_value
d = [[1.0,2.2,3,4],[1,2,3,4],[7,8,9,0],[3,5,7,9]]
df = pd.DataFrame(d, columns=['A', 'B', 'C', 'D'])
print(df)
df.loc['a', 'A'] = 101 # 对某个元素进行修改
df.loc[:, 'B'] = 0.25 # 对某一列进行修改
df.loc[:, 'C'] = [1, 2, 3, 4] # 将某一列元素改成不同的值
print(df)3、删除数据框中的元素
使用 drop 方法删除 Series 的元素或 DataFrame 的某一行(列)。
DataFrame.drop(labels=None, axis=0, levels=None, inplace=False)
| 参数名称 | 说明 |
|---|---|
| labels | 接收 string 或 array。代表删除的行或列的标签。无默认。 |
| axis | 接收0或1。代表操作的轴向。默认为0。 |
| levels | 接收 int 或者索引名。代表标签所在级别。默认为 None。 |
| inplace | 接收 boolean。代表操作是否对原数据生效。默认为 False。 |
d = [[1.0,2.2,3,4],[1,2,3,4],[7,8,9,0],[3,5,7,9]]
df = pd.DataFrame(d, index=['a', 'b', 'c', 'd'], columns=['A', 'B', 'C', 'D'])
print(df)
print(df.drop('D', axis=1, inplace=False)) # 删除数据框的列元素
print(df.drop(['a', 'c'], axis=0)) # 删除数据框的行元素Pandas转换与处理时间序列数据
1、将字符串转换为日期类型
# 将各种日期字符串转换成日期格式
import pandas as pd
data = ['12Feb23', '20201225', '2022/12/25', '2018.7.12']
columns = ['日期']
df = pd.DataFrame(data = data, columns = columns)
df['转换后'] = pd.to_datetime(df['日期'])
print(df)
2、日期类型转时间戳
import pandas as pd
data = {'date': ['2022-10-29', '2022-10-30', '2022-10-31'], 'value': [1, 2, 3]}
df = pd.DataFrame(data)
# 先将日期列转换成datetime格式
df['date'] = pd.to_datetime(df['date'])
# 再将datetime格式转换成timestamp
df['timestamp'] = df['date'].apply(lambda x: int(x.timestamp()))
print(df)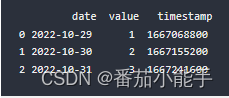
3、使用dt对象获取datetime数据类型的特定信息
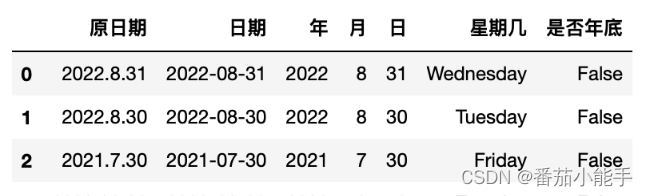
# dt 对象的使用
import pandas as pd
df = pd.read_excel('datetime.xlsx')
df['日期'] = pd.to_datetime(df['原日期'])
df['年'] = df['日期'].dt.year
df['月'] = df['日期'].dt.month
df['日'] = df['日期'].dt.day
df['星期几'] = df['日期'].dt.day_name()
df['是否年底'] = df['日期'].dt.is_year_end