time


import
import datetime
import time
Definition of time
- from 1970-01-01 00:00:00 UTC
Coordinated Universal Time
as the float format of ‘seconds’
For example

- use structured time lists
[ year,month,day,hours,minutes,seconds…]
表示从1970-01-01 00:00:00 UTC,开始到现在所经历的时间.

time.struct_time(tm_year=2018, tm_mon=1, tm_mday=31, tm_hour=1, tm_min=37,
tm_sec=36, tm_wday=2, tm_yday=31, tm_isdst=0)
Function of time
time.clock()
返回程序运行的整个时间段中中CPU运行的时间
def cpu_run():
start = time.clock()
for i in range(1000):
j = i * 2
for k in range(j):
t = k
print(t)
end = time.clock()
print('CPU excution takes: ',end - start, 'seconds')

python3.8就不再支持time.clock()了
If python > 3.8
用 time.perf_counter() 替换
def cpu_run():
start = time.perf_counter()
for i in range(1000):
j = i * 2
for k in range(j):
t = k
print(t)
end = time.perf_counter()
print('CPU excution takes: ',end - start, 'seconds')

time.sleep()
爬虫中常用,让程序暂停执行指定的秒数
time.sleep(2)
time.localtime()
用结构化的时间组,表示本地时间

time.ctime()
用字符串string表示时间

time.mktime()
将本地时间列表转化为浮点数的秒来表示

time.strftime()
将时间组时间转化为指定格式的String类

time.strptime
将String类时间转化为时间组格式

time.tzset()
更改本地时区
Applicaiton
用time来计算一下程序执行所耗时间
def run():
start = time.time()
for i in range(1000):
j = i * 2
for k in range(j):
t = k
print(t)
end = time.time()
print('This program excution takes: ',end - start, 'seconds')

Optimize
start = time.perf_counter()
for i in range(1000):
j = i * 2
for k in range(j):
t = k
print(t)
end = time.perf_counter()
print('CPU excution takes: ',end - start, 'seconds')
此段代码CPU执行时间大概5秒
那么问题来了:
CPU真的执行了这么长时间么?
会不会有什么东西是我没考虑进去的呢?
仔细看一下,这段程序主要内容就是两个for循环,for循环执行计算的时候CPU肯定是在运行的
那么print()函数打印期间这个时间段的CPU执行时间有没有算进去?
带着疑问,我们进行第三次测试,此次我们去掉print(),直接让CPU完成整个for循环的计算:
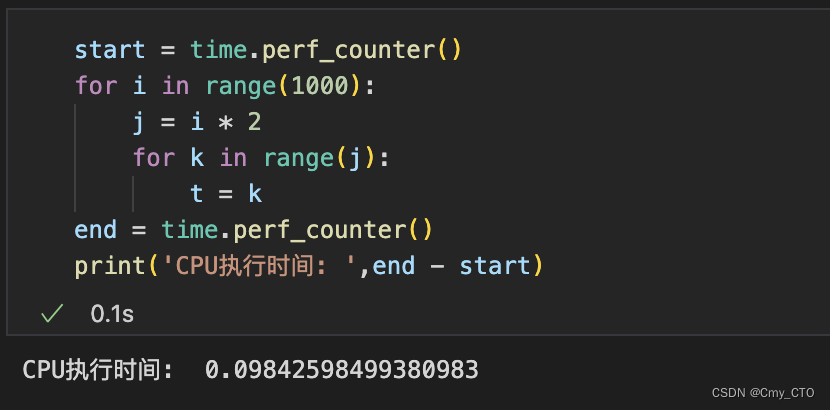
因为去掉了print(),所以只剩下了完整的for循环,CPU可以连续执行
不必一遍for循环一边print()来回切换
连续执行的CPU还是很快的~
所以 ,以后写代码时,要精简不必要的开销,譬如经常使用print()