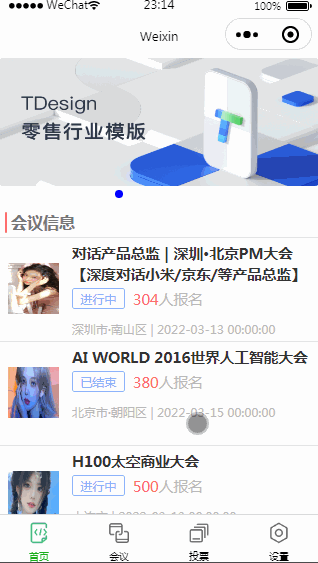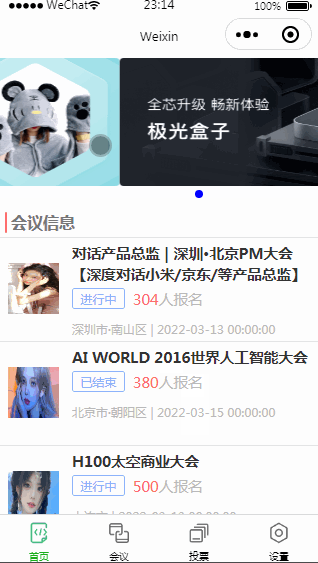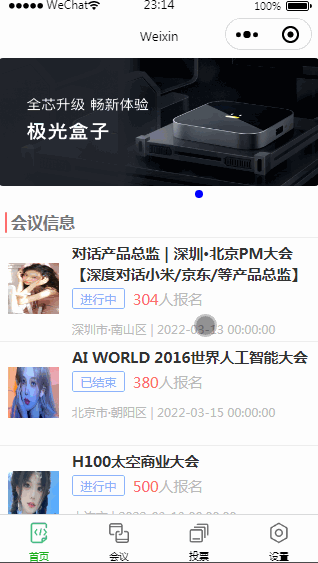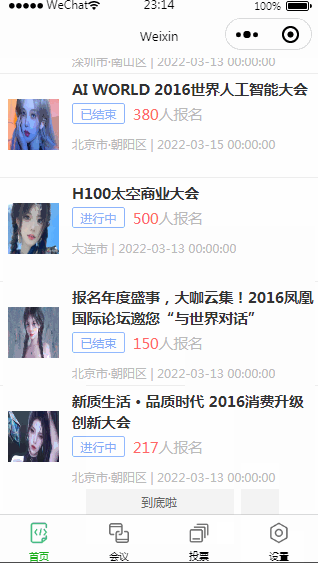
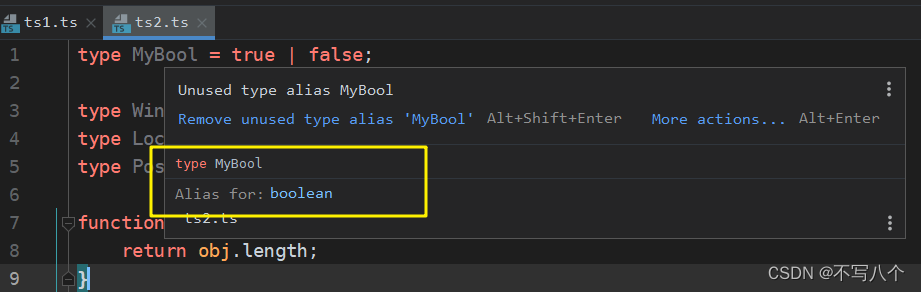
以下是一个使用CPR库和Python编写的爬虫程序,用于爬取。此程序使用了proxy的代码。
import requests
from cpr import CPR
def get_proxy():
url = "https://www.duoip.cn/get_proxy"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
def download_audio(audio_url, proxy=None):
if proxy:
cpr_options = {
"proxy": f"{proxy.split(':')[0]}:{proxy.split(':')[1]}" if proxy else None,
"proxy_auth": None,
"proxy_type": "http" if proxy else None,
}
else:
cpr_options = {"proxy": None, "proxy_auth": None, "proxy_type": None}
cpr = CPR(cpr_options)
with cpr.download(audio_url) as audio_file:
audio_content = audio_file.read()
return audio_content
def main():
audio_url = "https://www.tianya.cn/audio/123456789" # 请替换为目标音频的实际链接
proxy = get_proxy()
audio_content = download_audio(audio_url, proxy)
with open("output.mp3", "wb") as output_file:
output_file.write(audio_content)
if __name__ == "__main__":
main()
这个程序首先获取一个代理IP,然后使用CPR库下载音频。注意将audio_url替换为目标音频的实际链接。运行程序后,音频将保存为output.mp3。




![相同的树[简单]](https://img-blog.csdnimg.cn/837ec5c97d7448538ac26558947e20c7.png)