目录
1. Introduction 简介
2. Data preparation 数据准备
2.1 Load data 加载数据
2.2 Check for null and missing values 检查空值和缺失值
2.3 Normalization 规范化
2.4 Reshape 重塑
2.5 Label encoding 标签编码
2.6 Split training and valdiation set 拆分训练集和验证集
3. CNN 卷积神经网路
3.1 Define the model 定义模型
3.2 Set the optimizer and annealer 设置优化器和退火器
3.3 Data augmentation 数据增强
4. Evaluate the model 评估模型
4.1 Training and validation curves 训练和验证曲线
4.2 Confusion matrix 混淆矩阵
这篇文章来自Kaggle手写识别项目,通过CNN卷积神经网络实现的当时获得了0.997的准确度,分数排名前6%。原文链接:Introduction to CNN Keras - 0.997 (top 6%) | Kaggle
1. Introduction 简介
This is a 5 layers Sequential Convolutional Neural Network for digits recognition trained on MNIST dataset. I choosed to build it with keras API (Tensorflow backend) which is very intuitive. Firstly, I will prepare the data (handwritten digits images) then i will focus on the CNN modeling and evaluation.
这是一个 5 层顺序卷积神经网络,用于在 MNIST 数据集上训练的数字识别。选择使用非常直观的keras API(Tensorflow后端)构建。首先,将准备数据(手写数字图像),然后将专注于CNN建模和评估。
I achieved 99.671% of accuracy with this CNN trained in 2h30 on a single CPU (i5 2500k). For those who have a >= 3.0 GPU capabilites (from GTX 650 - to recent GPUs), you can use tensorflow-gpu with keras. Computation will be much much faster !!!
作者在单个 CPU(i5 2500k)上用2小时30分训练的这个CNN 实现了99.671%的准确率。对于那些拥有>=3.0 GPU 功能(从 GTX 650 - 到最近的 GPU)的用户,您可以将 tensorflow-gpu 与 keras 一起使用。计算速度将!!!快得多
For computational reasons, i set the number of steps (epochs) to 2, if you want to achieve 99+% of accuracy set it to 30.
出于计算原因,作者将步数(epochs)设置为 2,如果要达到 99+% 的精度,请将其设置为 30。我在后面设置为了30.
This Notebook follows three main parts:
下面分成三个部分:
- The data preparation 数据准备
- The CNN modeling and evaluation CNN建模和评估
- The results prediction and submission 结果预测和提交
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import itertools
from keras.utils.np_utils import to_categorical # convert to one-hot-encoding
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
#from keras.optimizers import RMSprop
from tensorflow.keras.optimizers import RMSprop
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ReduceLROnPlateau
np.random.seed(2)2. Data preparation 数据准备
2.1 Load data 加载数据
#加载数据
train = pd.read_csv("../input/train.csv")
test = pd.read_csv("../input/test.csv")
Y_train = train["label"]
#删除label列
X_train = train.drop(labels = ["label"],axis = 1)
#释放空间(我觉得不删也行)
del train
g = sns.countplot(Y_train)
Y_train.value_counts()1 4684
7 4401
3 4351
9 4188
2 4177
6 4137
0 4132
4 4072
8 4063
5 3795
Name: label, dtype: int64
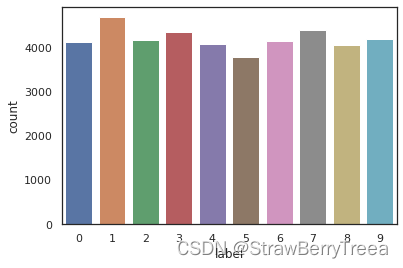
We have similar counts for the 10 digits.
对 10 个数字计数。
2.2 Check for null and missing values 检查空值和缺失值
#检查数据
X_train.isnull().any().describe()
count 784
unique 1
top False
freq 784
dtype: object
test.isnull().any().describe()count 784
unique 1
top False
freq 784
dtype: object
I check for corrupted images (missing values inside).
我检查损坏的图像(内部缺少值)。
There is no missing values in the train and test dataset. So we can safely go ahead.
训练数据集和测试数据集中没有缺失值。因此,我们可以放心地继续前进。
2.3 Normalization 规范化
We perform a grayscale normalization to reduce the effect of illumination's differences.
我们执行灰度归一化以减少照明差异的影响。
Moreover the CNN converg faster on [0..1] data than on [0..255].
此外,CNN在[0..1]数据上的收敛速度比在[0..255]上收敛得更快。
#标准化数据
X_train = X_train / 255.0
test = test / 255.02.4 Reshape 重塑
#把三维都修改为统一像素 (height = 28px, width = 28px , canal = 1)
X_train = X_train.values.reshape(-1,28,28,1)
test = test.values.reshape(-1,28,28,1)Train and test images (28px x 28px) has been stock into pandas.Dataframe as 1D vectors of 784 values. We reshape all data to 28x28x1 3D matrices.
训练和测试图像(28px x 28px)已被储存到panda中。数据帧作为 784 个值的一维向量。我们将所有数据重塑为 28x28x1 的3D 矩阵。
Keras requires an extra dimension in the end which correspond to channels. MNIST images are gray scaled so it use only one channel. For RGB images, there is 3 channels, we would have reshaped 784px vectors to 28x28x3 3D matrices.
Keras 最终需要一个额外的维度,它对应于通道。MNIST 图像是灰度缩放的,因此它只使用一个通道。对于 RGB 图像,有 3 个通道,我们将 784px 矢量重塑为 28x28x3 3D 矩阵。
2.5 Label encoding 标签编码
#把标签都转化为独热码 (ex : 2 -> [0,0,1,0,0,0,0,0,0,0])
Y_train = to_categorical(Y_train, num_classes = 10)Labels are 10 digits numbers from 0 to 9. We need to encode these lables to one hot vectors (ex : 2 -> [0,0,1,0,0,0,0,0,0,0]).
标签是从 0 到 9 的 10 位数字。我们需要将这些标签编码为一个独热向量(例如:2 -> [0,0,1,0,0,0,0,0,0,0,0,0])。
2.6 Split training and valdiation set 拆分训练集和验证集
#设置随机种子
random_seed = 2
#拆分训练集和验证集
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size = 0.1, random_state=random_seed)I choosed to split the train set in two parts : a small fraction (10%) became the validation set which the model is evaluated and the rest (90%) is used to train the model.
我选择将训练集分成两部分:一小部分(10%)成为评估模型的验证集,其余部分(90%)用于训练模型。
Since we have 42 000 training images of balanced labels (see 2.1 Load data), a random split of the train set doesn't cause some labels to be over represented in the validation set. Be carefull with some unbalanced dataset a simple random split could cause inaccurate evaluation during the validation.
由于我们有 42,000 张平衡标签的训练图像(参见 2.1 加载数据),因此训练集的随机拆分不会导致某些标签在验证集中过度表示。请注意,对于某些不平衡的数据集,简单的随机拆分可能会导致验证期间的评估不准确。
To avoid that, you could use stratify = True option in train_test_split function (Only for >=0.17 sklearn versions).
为了避免这种情况,你可以在train_test_split函数中使用 stratify = True 选项(仅适用于 >=0.17 sklearn 版本)。
We can get a better sense for one of these examples by visualising the image and looking at the label.
我们可以通过可视化图像并查看标签来更好地了解其中一个示例。
#样例
g = plt.imshow(X_train[0][:,:,0])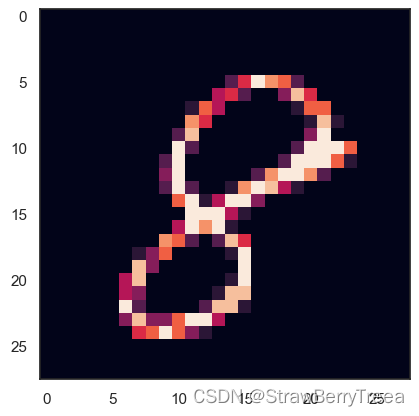
3. CNN 卷积神经网路
3.1 Define the model 定义模型
I used the Keras Sequential API, where you have just to add one layer at a time, starting from the input.
我使用了 Keras Sequential API,从输入开始,一次只需添加一个层。
The first is the convolutional (Conv2D) layer. It is like a set of learnable filters. I choosed to set 32 filters for the two firsts conv2D layers and 64 filters for the two last ones. Each filter transforms a part of the image (defined by the kernel size) using the kernel filter. The kernel filter matrix is applied on the whole image. Filters can be seen as a transformation of the image.
第一个是卷积(Conv2D)层。它就像一组可学习的过滤器。我选择为前两个 conv2D 层设置 32 个过滤器,为最后两个层设置 64 个过滤器。每个筛选器使用内核筛选器转换映像的一部分(由内核大小定义)。内核筛选器矩阵应用于整个映像。滤镜可以看作是图像的转换。
The CNN can isolate features that are useful everywhere from these transformed images (feature maps).
CNN可以从这些转换后的图像(特征图)中分离出在任何地方都有用的特征。
The second important layer in CNN is the pooling (MaxPool2D) layer. This layer simply acts as a downsampling filter. It looks at the 2 neighboring pixels and picks the maximal value. These are used to reduce computational cost, and to some extent also reduce overfitting. We have to choose the pooling size (i.e the area size pooled each time) more the pooling dimension is high, more the downsampling is important.
CNN中的第二个重要层是池化(MaxPool2D)层。该层仅充当下采样滤波器。它查看 2 个相邻像素并选择最大值。这些用于降低计算成本,并在一定程度上减少过拟合。我们必须选择池化大小(即每次池化的区域大小),池化维度越高,下采样就越重要。
Combining convolutional and pooling layers, CNN are able to combine local features and learn more global features of the image.
结合卷积层和池化层,CNN能够结合局部特征并学习图像的更多全局特征。
Dropout is a regularization method, where a proportion of nodes in the layer are randomly ignored (setting their wieghts to zero) for each training sample. This drops randomly a propotion of the network and forces the network to learn features in a distributed way. This technique also improves generalization and reduces the overfitting.
Dropout 是一种正则化方法,其中每个训练样本都会随机忽略层中一定比例的节点(将其宽度设置为零)。这会随机丢弃网络的一个分支,并强制网络以分布式方式学习特征。这种技术还可以改善泛化并减少过度拟合。
'relu' is the rectifier (activation function max(0,x). The rectifier activation function is used to add non linearity to the network.
“relu”是整流函数(激活函数max(0,x)。整流函数激活功能用于向网络添加非线性。
The Flatten layer is use to convert the final feature maps into a one single 1D vector. This flattening step is needed so that you can make use of fully connected layers after some convolutional/maxpool layers. It combines all the found local features of the previous convolutional layers.
展平层用于将最终特征图转换为单个 1D 矢量。需要这个展平步骤,以便您可以在一些卷积/最大池层之后使用全连接层。它结合了先前卷积层的所有发现的局部特征。
In the end i used the features in two fully-connected (Dense) layers which is just artificial an neural networks (ANN) classifier. In the last layer(Dense(10,activation="softmax")) the net outputs distribution of probability of each class.
最后,我在两个全连接(密集)层中使用了这些特征,这只是人工神经网络(ANN)分类器。在最后一层(Dense(10,激活=“softmax”)),净输出每个类的概率分布。
# Set the CNN model 设置CNN模型 # my CNN architechture is In -> [[Conv2D->relu]*2 -> MaxPool2D -> Dropout]*2 -> Flatten -> Dense -> Dropout -> Out 一共是5层
model = Sequential()
#设置卷积层参数
model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same',
activation ='relu', input_shape = (28,28,1)))
model.add(Conv2D(filters = 32, kernel_size = (5,5),padding = 'Same',
activation ='relu'))
#设置池化层参数
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same',
activation ='relu'))
model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same',
activation ='relu'))
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))
model.add(Dropout(0.25))
#设置全连接层参数
model.add(Flatten())
model.add(Dense(256, activation = "relu"))
model.add(Dropout(0.5))
model.add(Dense(10, activation = "softmax"))3.2 Set the optimizer and annealer 设置优化器和退火器
Once our layers are added to the model, we need to set up a score function, a loss function and an optimisation algorithm.
将图层添加到模型后,我们需要设置评分函数、损失函数和优化算法。
We define the loss function to measure how poorly our model performs on images with known labels. It is the error rate between the oberved labels and the predicted ones. We use a specific form for categorical classifications (>2 classes) called the "categorical_crossentropy".
我们定义了损失函数来衡量我们的模型在具有已知标签的图像上的表现有多差。它是标签和预测标签之间的错误率。我们使用一种特定的分类形式(>2 类),称为“categorical_crossentropy”。
The most important function is the optimizer. This function will iteratively improve parameters (filters kernel values, weights and bias of neurons ...) in order to minimise the loss.
最重要的函数是优化器。该函数将迭代改进参数(过滤内核值,神经元的权重和偏差......),以最大程度地减少损失。
I choosed RMSprop (with default values), it is a very effective optimizer. The RMSProp update adjusts the Adagrad method in a very simple way in an attempt to reduce its aggressive, monotonically decreasing learning rate. We could also have used Stochastic Gradient Descent ('sgd') optimizer, but it is slower than RMSprop.
我选择了 RMSprop(带有默认值),它是一个非常有效的优化器。RMSProp 更新以一种非常简单的方式调整了 Adagrad 方法,试图降低其激进的、单调递减的学习率。 我们也可以使用随机梯度下降('sgd')优化器,但它比RMSprop慢。
The metric function "accuracy" is used is to evaluate the performance our model. This metric function is similar to the loss function, except that the results from the metric evaluation are not used when training the model (only for evaluation).
度量函数“准确性”用于评估我们的模型的性能。 此指标函数类似于损失函数,不同之处在于在训练模型时不使用指标评估的结果(仅用于评估)。
#设置优化器
optimizer = RMSprop(learning_rate=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
#编译模型
model.compile(optimizer = optimizer , loss = "categorical_crossentropy", metrics=["accuracy"])正在上传…重新上传取消正在上传…重新上传取消
In order to make the optimizer converge faster and closest to the global minimum of the loss function, i used an annealing method of the learning rate (LR).
为了使优化器收敛得更快,最接近损失函数的全局最小值,我使用了学习率(LR)的退火方法。
The LR is the step by which the optimizer walks through the 'loss landscape'. The higher LR, the bigger are the steps and the quicker is the convergence. However the sampling is very poor with an high LR and the optimizer could probably fall into a local minima.
LR 是优化器遍历“损失情况”的步骤。LR 越高,步长越大,收敛越快。然而,在高LR下,采样非常差,优化器可能会陷入局部最小值。
Its better to have a decreasing learning rate during the training to reach efficiently the global minimum of the loss function.
最好在训练期间降低学习率,以有效地达到损失函数的全局最小值。
To keep the advantage of the fast computation time with a high LR, i decreased the LR dynamically every X steps (epochs) depending if it is necessary (when accuracy is not improved).
为了保持高LR快速计算时间的优势,我每隔X步(epoch)动态降低LR,具体取决于是否有必要(当精度没有提高时)。
With the ReduceLROnPlateau function from Keras.callbacks, i choose to reduce the LR by half if the accuracy is not improved after 3 epochs.
使用 Keras.callback 的 ReduceLROnPlateau 函数,如果 3 个 epoch 后精度没有提高,我选择将 LR 减少一半。
#设置学习率
learning_rate_reduction = ReduceLROnPlateau(monitor='val_acc',
patience=3,
verbose=1,
factor=0.5,
min_lr=0.00001)
epochs = 30 #迭代次数设置为30
batch_size = 863.3 Data augmentation 数据增强
In order to avoid overfitting problem, we need to expand artificially our handwritten digit dataset. We can make your existing dataset even larger. The idea is to alter the training data with small transformations to reproduce the variations occuring when someone is writing a digit.
为了避免过度拟合问题,我们需要人为地扩展我们的手写数字数据集。我们可以使您现有的数据集更大。这个想法是通过小的转换来改变训练数据,以重现有人写数字时发生的变化。
For example, the number is not centered The scale is not the same (some who write with big/small numbers) The image is rotated...
例如,数字不居中 比例不一样(有些用大/小数字写) 图像被旋转...
Approaches that alter the training data in ways that change the array representation while keeping the label the same are known as data augmentation techniques. Some popular augmentations people use are grayscales, horizontal flips, vertical flips, random crops, color jitters, translations, rotations, and much more.
以改变数组表示形式同时保持标签相同的方式改变训练数据的方法称为数据增强技术。人们使用的一些流行的增强功能包括灰度、水平翻转、垂直翻转、随机裁剪、颜色抖动、平移、旋转等等。
By applying just a couple of these transformations to our training data, we can easily double or triple the number of training examples and create a very robust model.
通过对训练数据仅应用其中几个转换,我们可以轻松地将训练样本的数量增加一倍或三倍,并创建一个非常健壮的模型。
The improvement is important :
改进很重要:
- Without data augmentation i obtained an accuracy of 98.114%
- 在没有数据增强的情况下,我获得了 98.114% 的准确率
- With data augmentation i achieved 99.67% of accuracy
- 通过数据增强,我实现了 99.67% 的准确率
这部分是没有数据增强的代码
# Without data augmentation i obtained an accuracy of 0.98114
# history = model.fit(X_train, Y_train, batch_size = batch_size, epochs = epochs,
# validation_data = (X_val, Y_val), verbose = 2)
# With data augmentation to prevent overfitting (accuracy 0.99286)
#数据增强
datagen = ImageDataGenerator(
featurewise_center=False, #设置输入均值为0
samplewise_center=False,
featurewise_std_normalization=False, #标准化
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=10, #随机旋转图像
zoom_range = 0.1,
width_shift_range=0.1, #随机水平移动图像
height_shift_range=0.1, #随机垂直移动图像
horizontal_flip=False, #随机翻转图像
vertical_flip=False)
datagen.fit(X_train)For the data augmentation, i choosed to :
对于数据增强,我选择:
- Randomly rotate some training images by 10 degrees
- 将一些训练图像随机旋转 10 度
- Randomly Zoom by 10% some training images
- 随机缩放 10% 一些训练图像
- Randomly shift images horizontally by 10% of the width
- 将图像水平随机移动宽度的 10%
- Randomly shift images vertically by 10% of the height
- 将图像垂直随机移动高度的 10%
I did not apply a vertical_flip nor horizontal_flip since it could have lead to misclassify symetrical numbers such as 6 and 9.
我没有应用vertical_flip也没有应用horizontal_flip因为它可能导致错误分类对称数字,例如 6 和 9。
Once our model is ready, we fit the training dataset .
一旦我们的模型准备就绪,我们拟合训练数据集。
#拟合模型
history = model.fit(datagen.flow(X_train,Y_train, batch_size=batch_size),
epochs = epochs, validation_data = (X_val,Y_val),
verbose = 2, steps_per_epoch=X_train.shape[0] // batch_size
, callbacks=[learning_rate_reduction])#运行结果
Epoch 1/30
439/439 - 83s - loss: 0.4110 - accuracy: 0.8662 - val_loss: 0.0679 - val_accuracy: 0.9783
Epoch 2/30
439/439 - 81s - loss: 0.1266 - accuracy: 0.9629 - val_loss: 0.0442 - val_accuracy: 0.9867
Epoch 3/30
439/439 - 81s - loss: 0.0959 - accuracy: 0.9715 - val_loss: 0.0399 - val_accuracy: 0.9874
Epoch 4/30
439/439 - 81s - loss: 0.0823 - accuracy: 0.9760 - val_loss: 0.0349 - val_accuracy: 0.9905
Epoch 5/30
439/439 - 81s - loss: 0.0739 - accuracy: 0.9788 - val_loss: 0.0310 - val_accuracy: 0.9921
Epoch 6/30
439/439 - 81s - loss: 0.0657 - accuracy: 0.9815 - val_loss: 0.0320 - val_accuracy: 0.9919
Epoch 7/30
439/439 - 81s - loss: 0.0633 - accuracy: 0.9819 - val_loss: 0.0245 - val_accuracy: 0.9929
Epoch 8/30
439/439 - 81s - loss: 0.0624 - accuracy: 0.9819 - val_loss: 0.0227 - val_accuracy: 0.9926
Epoch 10/30
439/439 - 80s - loss: 0.0591 - accuracy: 0.9830 - val_loss: 0.0218 - val_accuracy: 0.9940
Epoch 11/30
439/439 - 80s - loss: 0.0610 - accuracy: 0.9835 - val_loss: 0.0286 - val_accuracy: 0.9907
Epoch 12/30
439/439 - 80s - loss: 0.0573 - accuracy: 0.9835 - val_loss: 0.0271 - val_accuracy: 0.9914
Epoch 13/30
439/439 - 79s - loss: 0.0623 - accuracy: 0.9827 - val_loss: 0.0256 - val_accuracy: 0.9924
Epoch 14/30
439/439 - 81s - loss: 0.0609 - accuracy: 0.9841 - val_loss: 0.0351 - val_accuracy: 0.9902
Epoch 15/30
439/439 - 80s - loss: 0.0617 - accuracy: 0.9839 - val_loss: 0.0194 - val_accuracy: 0.9936
Epoch 16/30
439/439 - 80s - loss: 0.0620 - accuracy: 0.9826 - val_loss: 0.0252 - val_accuracy: 0.9929
Epoch 17/30
439/439 - 80s - loss: 0.0639 - accuracy: 0.9829 - val_loss: 0.0636 - val_accuracy: 0.9824
Epoch 18/30
439/439 - 80s - loss: 0.0650 - accuracy: 0.9833 - val_loss: 0.0292 - val_accuracy: 0.9917
Epoch 19/30
439/439 - 81s - loss: 0.0699 - accuracy: 0.9818 - val_loss: 0.0327 - val_accuracy: 0.9914
Epoch 20/30
439/439 - 80s - loss: 0.0646 - accuracy: 0.9831 - val_loss: 0.0340 - val_accuracy: 0.9917
Epoch 21/30
439/439 - 81s - loss: 0.0699 - accuracy: 0.9830 - val_loss: 0.0295 - val_accuracy: 0.9945
Epoch 22/30
439/439 - 81s - loss: 0.0667 - accuracy: 0.9827 - val_loss: 0.0389 - val_accuracy: 0.9921
Epoch 23/30
439/439 - 80s - loss: 0.0692 - accuracy: 0.9833 - val_loss: 0.0269 - val_accuracy: 0.9926
Epoch 24/30
439/439 - 80s - loss: 0.0683 - accuracy: 0.9826 - val_loss: 0.0394 - val_accuracy: 0.9883
Epoch 25/30
439/439 - 80s - loss: 0.0721 - accuracy: 0.9820 - val_loss: 0.0432 - val_accuracy: 0.9921
Epoch 26/30
439/439 - 81s - loss: 0.0746 - accuracy: 0.9826 - val_loss: 0.0315 - val_accuracy: 0.9921
Epoch 27/30
439/439 - 81s - loss: 0.0689 - accuracy: 0.9824 - val_loss: 0.0310 - val_accuracy: 0.9938
Epoch 28/30
439/439 - 80s - loss: 0.0778 - accuracy: 0.9812 - val_loss: 0.0292 - val_accuracy: 0.9921
Epoch 29/30
439/439 - 81s - loss: 0.0789 - accuracy: 0.9808 - val_loss: 0.0318 - val_accuracy: 0.9917
Epoch 30/30
439/439 - 80s - loss: 0.0767 - accuracy: 0.9812 - val_loss: 0.0257 - val_accuracy: 0.99174. Evaluate the model 评估模型
4.1 Training and validation curves 训练和验证曲线
#画数据验证图
fig, ax = plt.subplots(2,1)
ax[0].plot(history.history['loss'], color='b', label="Training loss")
ax[0].plot(history.history['val_loss'], color='r', label="validation loss",axes =ax[0])
legend = ax[0].legend(loc='best', shadow=True)
ax[1].plot(history.history['accuracy'], color='b', label="Training accuracy")
ax[1].plot(history.history['val_accuracy'], color='r',label="Validation accuracy")
legend = ax[1].legend(loc='best', shadow=True)
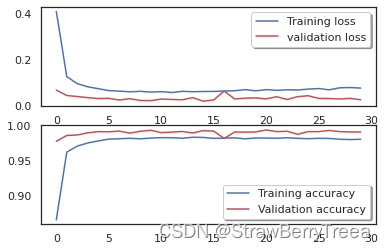
The code below is for plotting loss and accuracy curves for training and validation. Since, i set epochs = 2 on this notebook . I'll show you the training and validation curves i obtained from the model i build with 30 epochs (2h30)
下面的代码用于绘制损失和准确性曲线以进行训练和验证。因为,我在这个笔记本上设置了纪元 = 2. 我将向您展示我从我构建的具有 30 个 epoch (2h30) 的模型中获得的训练和验证曲线
(我是按照30 epoch 运行的)
正在上传…重新上传取消
The model reaches almost 99% (98.7+%) accuracy on the validation dataset after 2 epochs. The validation accuracy is greater than the training accuracy almost evry time during the training. That means that our model dosen't not overfit the training set.
该模型在 2 个 epoch 后在验证数据集上的准确率几乎达到 99% (98.7+%)。在训练过程中,验证精度几乎大于训练精度。这意味着我们的模型不会过度拟合训练集。
Our model is very well trained !!!
我们的模型训练有素!!!
正在上传…重新上传取消
4.2 Confusion matrix 混淆矩阵
Confusion matrix can be very helpfull to see your model drawbacks.
混淆矩阵对于查看模型缺点非常有帮助。
I plot the confusion matrix of the validation results.
我绘制了验证结果的混淆矩阵。
#混淆矩阵
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')#预测验证数据集中的值
Y_pred = model.predict(X_val)
#将预测转换为独热向量
Y_pred_classes = np.argmax(Y_pred,axis = 1)
#将验证值转换为独热向量
Y_true = np.argmax(Y_val,axis = 1)
#计算混淆矩阵
confusion_mtx = confusion_matrix(Y_true, Y_pred_classes)
#绘制混淆矩阵
plot_confusion_matrix(confusion_mtx, classes = range(10)) 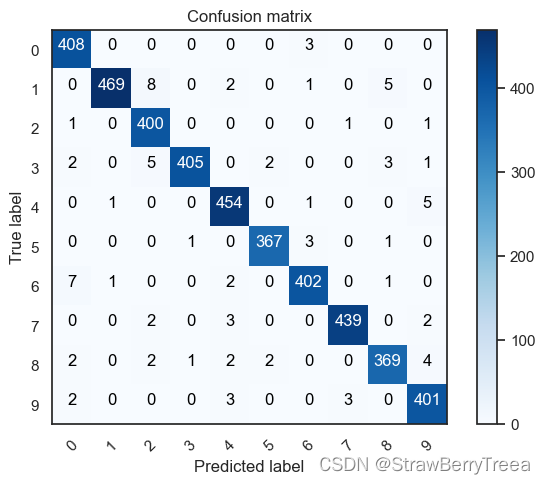
Here we can see that our CNN performs very well on all digits with few errors considering the size of the validation set (4 200 images).
在这里,我们可以看到我们的CNN在所有数字上都表现非常好,考虑到验证集的大小(4 200张图像),几乎没有错误。
However, it seems that our CNN has some little troubles with the 4 digits, hey are misclassified as 9. Sometime it is very difficult to catch the difference between 4 and 9 when curves are smooth.
但是,似乎我们的CNN在4位数字上有一些小麻烦,嘿被错误地归类为9。有时,当曲线平滑时,很难捕捉 4 和 9 之间的差异。
Let's investigate for errors.
让我们调查错误。
I want to see the most important errors . For that purpose i need to get the difference between the probabilities of real value and the predicted ones in the results.
我想看看最重要的错误。为此,我需要获得结果中实际值概率与预测概率之间的差异。
#展示错误结果
#预测和真实之间的差异
errors = (Y_pred_classes - Y_true != 0)
Y_pred_classes_errors = Y_pred_classes[errors]
Y_pred_errors = Y_pred[errors]
Y_true_errors = Y_true[errors]
X_val_errors = X_val[errors]
def display_errors(errors_index,img_errors,pred_errors, obs_errors):
""" This function shows 6 images with their predicted and real labels"""
n = 0
nrows = 2
ncols = 3
fig, ax = plt.subplots(nrows,ncols,sharex=True,sharey=True)
for row in range(nrows):
for col in range(ncols):
error = errors_index[n]
ax[row,col].imshow((img_errors[error]).reshape((28,28)))
ax[row,col].set_title("Predicted label :{}\nTrue label :{}".format(pred_errors[error],obs_errors[error]))
n += 1#错误预测数字的概率
Y_pred_errors_prob = np.max(Y_pred_errors,axis = 1)
#误差集中真实值的预测概率
true_prob_errors = np.diagonal(np.take(Y_pred_errors, Y_true_errors, axis=1))
#预测标签和真实标签的概率之间的差异
delta_pred_true_errors = Y_pred_errors_prob - true_prob_errors
#增量概率错误的排序列表
sorted_dela_errors = np.argsort(delta_pred_true_errors)
#错的最离谱的6个
most_important_errors = sorted_dela_errors[-6:]
#展示这6个错误
display_errors(most_important_errors, X_val_errors, Y_pred_classes_errors, Y_true_errors)
The most important errors are also the most intrigous.
最重要的错误也是最棘手的。
For those six case, the model is not ridiculous. Some of these errors can also be made by humans, especially for one the 9 that is very close to a 4. The last 9 is also very misleading, it seems for me that is a 0.
对于这六种情况,这个模型并不荒谬。其中一些错误也可能由人类制造,特别是对于非常接近 4 的 9。最后 9 个也非常具有误导性,在我看来这是一个 0。
#预测结果
results = model.predict(test)
#输出结果
results = np.argmax(results,axis = 1)
results = pd.Series(results,name="Label")
#提交结果
submission = pd.concat([pd.Series(range(1,28001),name = "ImageId"),results],axis = 1)
submission.to_csv("cnn_mnist_datagen.csv",index=False)最后保存模型,输出模型参数
model.save('my_model')
model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 28, 28, 32) 832 _________________________________________________________________ conv2d_1 (Conv2D) (None, 28, 28, 32) 25632 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 14, 14, 32) 0 _________________________________________________________________ dropout (Dropout) (None, 14, 14, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 14, 14, 64) 18496 _________________________________________________________________ conv2d_3 (Conv2D) (None, 14, 14, 64) 36928 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 7, 7, 64) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 7, 7, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 3136) 0 _________________________________________________________________ dense (Dense) (None, 256) 803072 _________________________________________________________________ dropout_2 (Dropout) (None, 256) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 2570 ================================================================= Total params: 887,530 Trainable params: 887,530 Non-trainable params: 0 _________________________________________________________________




![[机缘参悟-95] :不同人生、社会问题的本质](https://img-blog.csdnimg.cn/img_convert/85631530ea018ce54650f42cdc126b41.jpeg)