如果我们查看汇编代码的话,可以发现,经过优化的for-range循环的汇编代码和普通for的结构相同。也就是说,使用for-range的控制结构最终也会被Go语言编译器换成普通的for循环。
现象提出
现象1:循环永动机
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr) // [1 2 3 1 2 3]
}
现象2:神奇的指针
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
// 3
// 3
// 3
正确的做法是使用&arr[i]替代&v,原因我们后面会讲解。
现象3:遍历清空数组
当我们想在Go语言中清空一个切片或者哈希表的时候,一般会使用以下方法将切片中的元素置为0
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}
这样清空是非常消耗性能的,所以在编译的时候,编译器会直接优化成使用runtime.memclrNoHeapPointers来清空切片中的数据。
现象4:随机遍历
当我们用for-range遍历哈希表的时候,得到的顺序是不相同的。
for-range循环遍历
从编译器的视角来看,就是将ORANGE 类型的节点转换成OFOR节点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G9lqF3l0-1671804211571)(D:\A\图片\板书\for-range.excalidraw.png)]
然后我们来看一看for-range的遍历
数组和切片
数组和切片和遍历通常情况下会有4种可能性:
- 遍历数组和切片清空元素的情况
for range a {},不关心索引和值for i := range a {},只关心索引for i, elem := range a{},关心索引和值
第一种情况
也就是我们的现象3的解决。
Go会使用runtime.memclrNoHeapPointers或者runtime.memclrHasPointers清除目标数组内存空间中的全部数据
第二种情况
如果我们不关心索引和值的话,那么代码大概会被编译器转换成这个样子:
for range a {}为例子
ha := a // 这里不是a了,是拷贝给了ha
hv1 := 0 // hv1代表循环变量
hn := len(ha) // 我的遍历长度已经给你计算完毕了
v1 := hv1 // v1代表索引的值
for ; hv1 < hn; hv1++ {
...
}
第三种情况
for i := range a{}为例子
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 = hv1
...
}
第四种情况
for i, j := range a{}为例子
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1 // 表示索引
v2 := nil // 表示值
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 = hv1, tmp
...
}
所以解释现象1:
我们可以看到对于所有的range循环,Go会在编译期间将长度提前计算好,所以循环次数是已经固定的,不会无限制增加。
解释现象2:
我们可以看到表示值的变量v2会在每一次迭代被重新赋值而覆盖,覆盖到最后就都是一个结果了。因此要得到正确的结果,我们不应该获取range返回的变量地址&v2,而是直接获取&arr[i]
哈希表
该图片来自面向信仰编程
这个代码是for key, val := range hash {}展开的结果:
ha := a
hit := hiter(n.Type)
th := hit.Type
mapiterinit(typename(t), ha, &hit)
for ; hit.key != nil; mapiternext(&hit) {
key := *hit.key
val := *hit.val
}
编译器会根据range返回值的数量在循环体中插入需要的赋值语句。
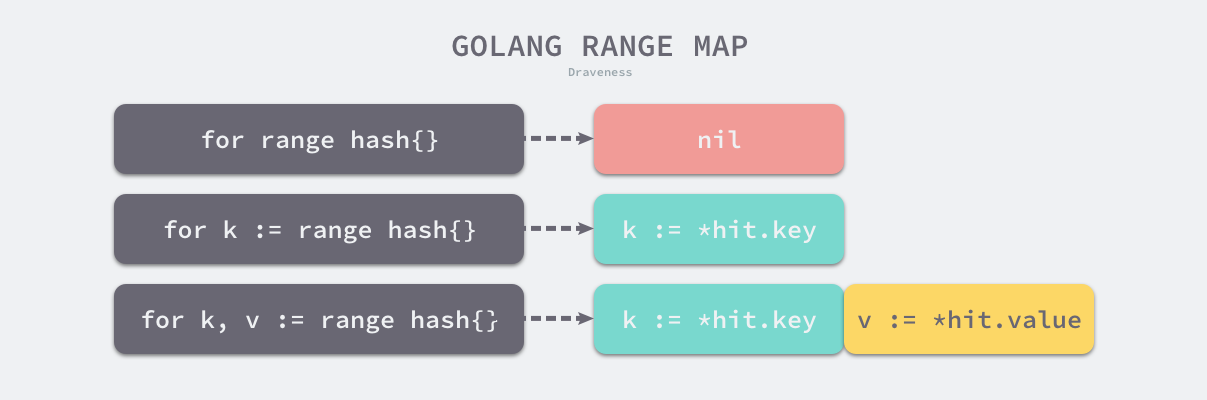
在遍历的时候,Go会通过runtime.fastrand生成一个随机数,这样我们第一个遍历桶的起始位置每次都是不一样的,这就解释了现象4。
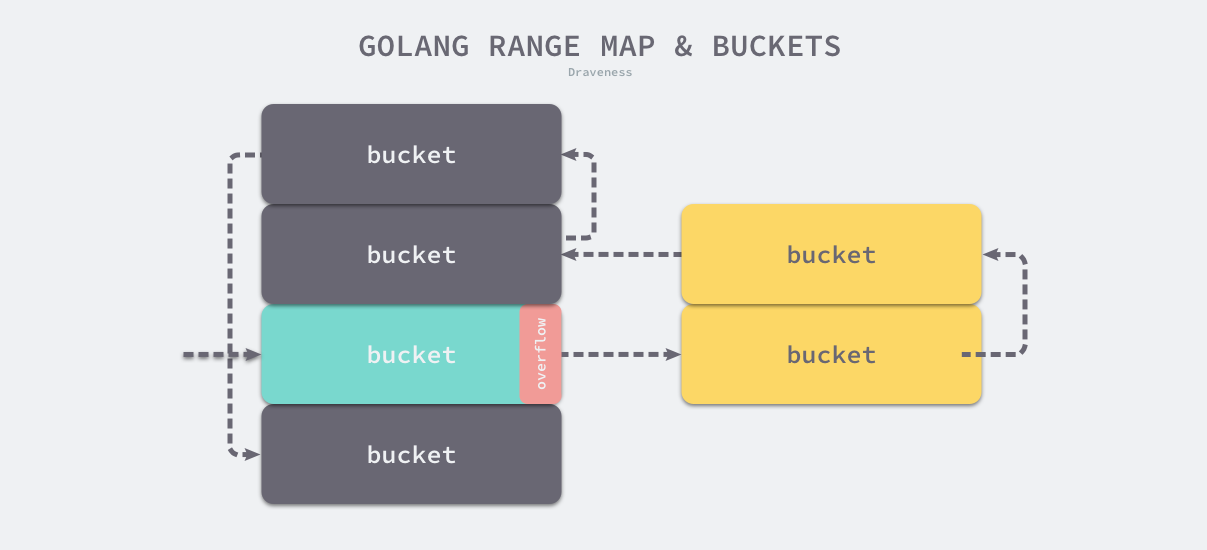
简单总结一下哈希表遍历的顺序,首先会选出一个绿色的正常桶开始遍历,随后遍历所有黄色的溢出桶,最后依次按照索引顺序遍历哈希表中其他的桶,直到所有的桶都被遍历完成。
字符串
具体过程和遍历数组和切片差不多
Channel
使用 range 遍历 Channel 也是比较常见的做法,一个形如 for v := range ch {} 的语句最终会被转换成如下的格式:
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
...
}
这里的代码可能与编译器生成的稍微有一些出入,但是结构和效果是完全相同的。该循环会使用 <-ch 从管道中取出等待处理的值,这个操作会调用 runtime.chanrecv2 并阻塞当前的协程,当 runtime.chanrecv2 返回时会根据布尔值 hb 判断当前的值是否存在:
- 如果不存在当前值,意味着当前的管道已经被关闭;
- 如果存在当前值,会为
v1赋值并清除hv1变量中的数据,然后重新陷入阻塞等待新数据;


![[机缘参悟-95] :不同人生、社会问题的本质](https://img-blog.csdnimg.cn/img_convert/85631530ea018ce54650f42cdc126b41.jpeg)