事务系统保证了系统的数据一致性,确保事务更新的原子性或是不同事务之间的数据隔离性等在多线程并发环境下所必不可少的ACID特性。而在今天快速变化的商业环境下,诸如物流和供应链,金融风控和欺诈检测等场景都需要图分析系统提供对数据动态更新和新鲜度的更高要求。因此,在图分析系统中支持事务机制至关重要。本文将介绍三篇相关论文Livegraph,Teseo与Sortledton。



背景介绍
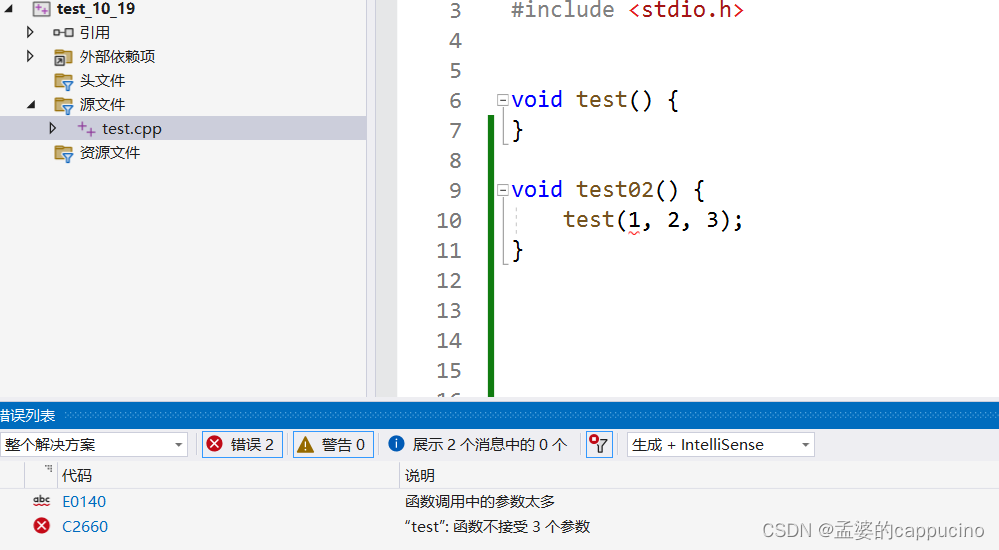
图分析系统通常存储下图的拓扑结构以及必要的属性,并支持在存储图上高效执行各类图算法,例如单源最短路(Single source shortest path,SSSP)和PageRank(PR)算法。在大多数原生的图存储系统中,拓扑结构通常采用下图所示的两种方法:1.稀疏矩阵行压缩(compressed sparse row,CSR),2.邻接表。
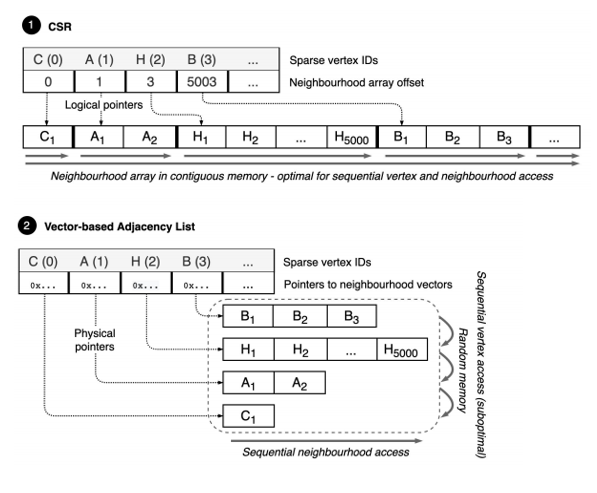
CSR通过将所有顶点的所有邻域共同存储连续的内存位置,形成一个紧凑的结构,支持快速的读取,但需要承担高额的修改代价。邻接表的各个顶点邻域分别存储,读取上由于邻域不存储在一起需要若干次指针查找会逊色于CSR结构。
事务方面,目前的主流系统都采取的多版本并发控制(multiple version concurrency control,MVCC)来实现。MVCC的主要思想是存储数据的多个版本,记录这些版本创建和无效的时间戳。而各个事务可以根据自己的时间戳读取自己需要的版本数据,以此避免读写冲突。根据不同时间戳限制可以轻松实现读已提交、快照隔离等不同隔离等级,并可以引入经典的两阶段锁策略实现可串行化隔离等级。
本文介绍的三篇论文旨在将图分析与事务两种操作结合在一个图存储系统中从而实现高效且支持并发的图分析操作。他们在事务方面皆采用了MVCC方案,并分别构建了自己的图存储数据结构。
设计思路
本部分将介绍三篇论文的数据结构的设计思路。
LiveGraph:
图分析的基本操作是大量的邻接表扫描,包含一次查找顶点邻域的seek和一次扫描邻域的scan两种操作。目前的主流图存储结构中,通常分为以neo4j为代表的链表形式、为了适应磁盘交换数据而设计的LSM-Tree(Log Structured Merge Tree)和B+Tree及上文描述过的CSR形式。这些结构在两类操作(seek和scan)上的效率各不相同。CSR以更新代价为代价达到最好的性能。

这之中,LiveGraph提出的新数据结构:事务型边日志(TEL)在连续TEL在连续内存上结合多版本,能够达到类似CSR的常数级seek并支持连续扫描邻域。下表也能够体现TEL相对于LSMT、B+Tree和链表的优势。

Teseo:
在LiveGraph的基础上,Teseo认为不仅要考虑某个点邻域的寻址与扫描问题,也要考虑扫描不同邻域时的时间消耗。Teseo总结图分析算法如下图,认为扫描所有邻域的图分析算法有两类:一是顺序扫描所有邻域,二是随机访问所有邻域。前者典型如PageRank,后者典型如SSSP。而类似LiveGraph这种邻接表的形式无法很好处理不同邻域的扫描。

Sortledton:
Sortledton设计了相关的实验,将同一个顶点的邻域存储在块大小超过256的链状块结构即可达到与存储在连续内存空间相近的效率。同时,Teseo中针对扫描所有顶点邻域的优化并不是必要的。最后,Sortledton总结了包括LiveGraph和Teseo在内的多个动态图分析结构,认为动态图结合事务系统需要提供三类操作:支持并发的事务操作,用于图分析的扫描操作和用于图模式匹配的快速交集(要求数据结构有序)操作。
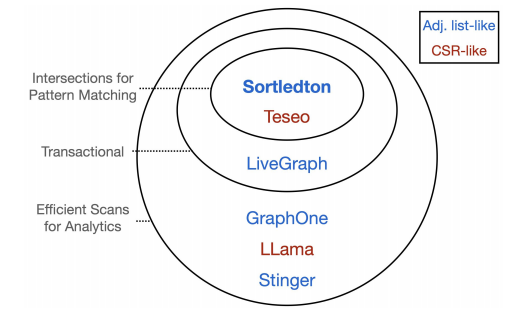
数据结构与事务机制
本部分介绍三篇论文具体的数据结构与事务机制设计。
LiveGraph
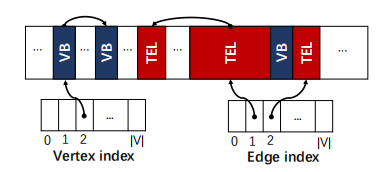
上图展示了LiveGraph数据结构的基本布局。LiveGraph基于属性图建模,每条边具有多种属性,并且有且仅有一个标签(Label)。点的相关信息都存储在Vertex Block(VB)里,而同一个点的同一类标签的出边都存放在一个TEL结构里。LiveGraph利用全局的点和边索引来快速定位需要操作的VB和TEL。
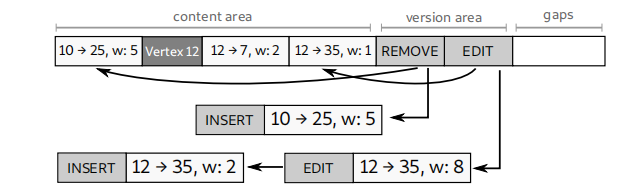
TEL内部的结构如下图所示,除了开头固定长度的元数据外,相关边与对应属性在一个倍增的动态扩容数组中分别从两头往中间增长。最新的数据被存储在最中间。这种布局保证了扫描一个邻域时是顺序访问内存的。此外,LiveGraph在基础数据结构中就实现了多版本存储:每个边在被删除或更新时,并不是直接在动态数组中删除该边及属性,而是修改该边的无效时间戳Invalidation TS,存储下这条边的历史数据。
为了支持这种多版本的存储,新边的插入操作不需要改变,但原有边的更新操作需要修改旧版本的无效时间戳。为了快速判断边操作是插入还是更新,LiveGraph在每个TEL的元数据出添加了一个Bloom filter加速判断。由于TEL的边是按照时间顺序存储的,因此单边查询可能需要scan整个TEL结构。

事务方面,LiveGraph实现了快照隔离。在全局有一个主线程管理事务,各个分线程执行事务,同时存在一个全局读时间戳GRE与写时间戳GWE。每个顶点拥有一个futex,在快照隔离下读写操作不互斥,事务的写操作在提交前不会被其他事务所读取,而写写操作则通过锁进行互斥。每个TEL额外维护一个最新提交时间CT与日志大小LS并在事务提交时更新,日志大小LS可以防止其他线程读取到未提交的数据。为了防止死锁,LiveGraph将超时的事务进行回滚,并使用批量提交的方法提高吞吐率。
具体而言,读写事务的操作分为以下三个阶段:
1.事务开启:事务读时间戳TRE设为GRE,写操作获取写锁后,更新私人版本。该私人版本由于日志大小LS未更新因此不会被读取。
2.事务持久化:事务提交前,交由主线程执行组提交。主线程令GWE+1。将日志同步到磁盘后。通知各线程执行提交。
3.事务提交:修改CT与LS。释放写锁。修改日志时间戳。组提交完成后,通知主线程令GRE+1,使事务可见。
Teseo
首先介绍Teseo使用的数据结构之一PMA。
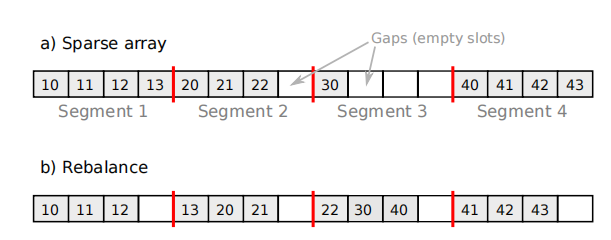
如上图所示,PMA是带有空隙的数组,将之分成若干segment。插入时优先插入segment中的空隙,若segment满时则联合周围若干segment执行rebalance,元素过多时可能执行数组的倍增。每次更新的最差效率为O(logN)^2,均匀分布的均摊效率是O(logN)。参数的设置可以保证rebalance段的填充率约为75%,而整体数组的填充率为50%。
Teseo的设计灵感从B+Tree出发。B+Tree的问题在于:B+tree的叶子较小(4KB),大度数的邻域scan将频繁跨越叶子。并且小度数的邻域scan将近似对数效率的点查找。因此Teseo提出了Fat-tree,如上图所示:1. 增大叶子大小至MB级别 2. 添加hash map作为secondary index加速点查找。
但简单地扩大叶子会提高更新的代价。因此Teseo将叶子的数据结构组织为稀疏数组。每个Segment具有一对fence key;叶子节点以min key为键,构建ART索引方便快速查找叶子。当稀疏数组需要expand时,执行split,保证叶子大小在X/2~X之间。删除时不执行rebalance,而是在必要时进行叶子间的merge。
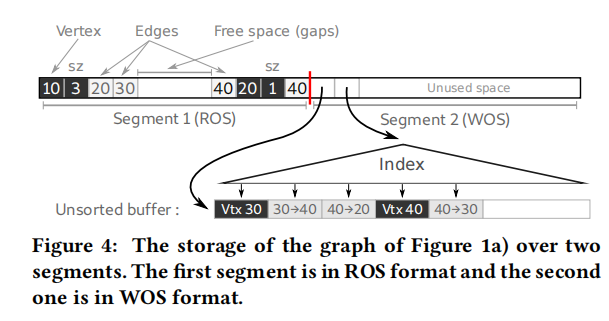
Teseo将segment分为读优化段ROS和写优化段WOS,如下图所示。初始段模式为ROS,在segment的两边存储数据。插入时需要挪动数据。为了防止更新偏斜的最差情况,段满时以延迟D执行rebalance。为此需要一个机制存储多余的数据:WOS段模式。WOS段模式利用段外的buffer和段内的索引存储数据,数据为<src,dst>,索引为ART tree。
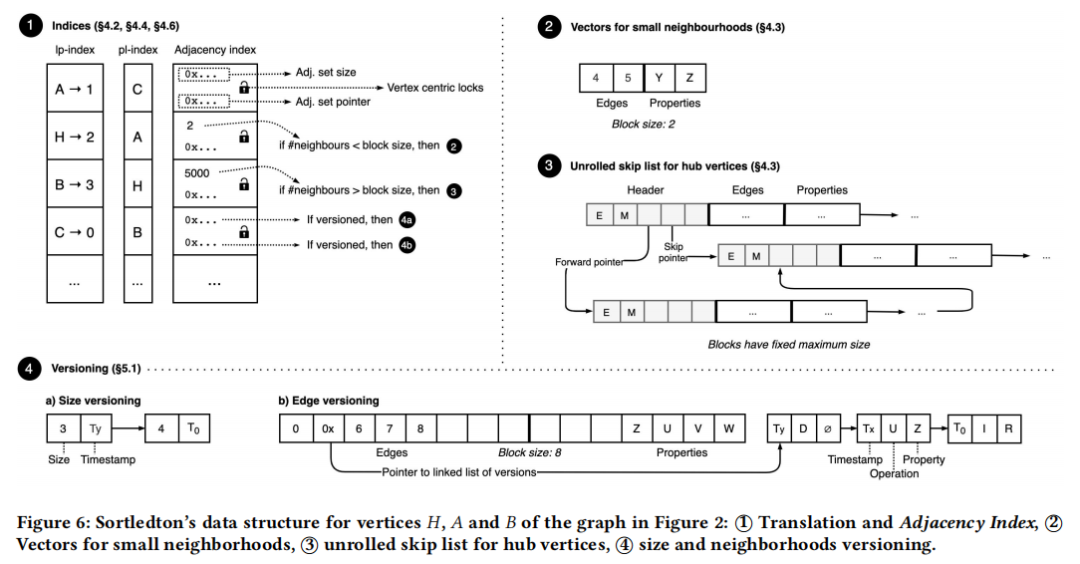
为了支持事务的并发,每个segment具有一个hybrid latch。携带一个版本标记的读写锁,读数据时乐观地可以选择不加读锁,而通过对比版本确保无人修改数据。为了防止死锁,Teseo的只读事务会获得传统的读锁存器。而读写事务的读操作则只能获取乐观模式的锁存器。由于Fat-Tree需要执行若干叶子中segment的rebalance,需要计算segment的长度。因此叶子节点还需要添加一个锁存器。二级索引使用的哈希表使用了无锁实现,同样可以保证线程安全。同时,在每个存储数组后面添加一个版本区域,以版本链的形式将数据的所有版本串联在一起,如下图所示。Teseo的事务执行逻辑基本与Hyper类似。
Sortledton
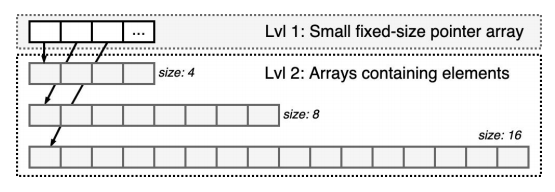
由于不需要优化所有邻域的访问模式,Sortledton采取邻接表的形式,以简化结构。如背景介绍中描述的,邻接表主要分为两个部分:点到边集的映射与某个点的邻边有序集。Sortledton的点边映射采用的两级数据如上图所示,第一级存储第二级数组的指针,每次扩容时新增一个大小翻倍的第二级数组。
而邻边有序集方面,根据设计思想一节中介绍的指导思想,不需要将邻边有序集都存储在连续物理内存,可以用块大小较大的链式块达到近似的处理速度。因此Sortledton选择松散链表,支持对数级别的查询更新的同时,维护边的有序性并避免类似B+ Tree的rebalance操作。
为了实现多版本存储,Sortledton在每个边维护的信息中加入一个版本链指针,并实现了一个传统的版本链维护。Sortledton的整体存储架构如下图所示,包括一个二级数组实现的动态索引,基于松散链表存储的每个点邻域与对应的版本链存储。

事务方面,Sortledton专注于优化具有已知读写集的读写事务和只读事务,认为这两种类型是图分析事务中最主要的事务。针对具有已知读写集的读写事务而言,事务的操作按照顺序主要分为:由于写集已知,因此可以先获取所有对应数据的锁,之后读取最新版本数据。最后获取commit时间戳,并在完成写操作后释放锁。而针对只读事务,则先获取read时间戳,并在需要读取数据时加读锁,读取数据后释放读锁。
实验
由于Sortledton的实验对比对象包括LiveGraph和Teseo,因此本文直接介绍Sortledton进行的实验。本实验采用的数据集是由LDBC数据生成器生成的图数据。
第一部分的测试比较插入的性能,对比的对象分别为Teseo,LiveGraph,GraphOne,Llama以及Stringer。插入的同时要求先查询该边是否存在。下图中存在巨大性能差异时主要由于存在性检测导致的:Teseo和Sortledton的边集有序,因此可以快速查询存在性;GraphOne不支持存在性查询。因此它们与另外三个系统存在较大的性能差异。
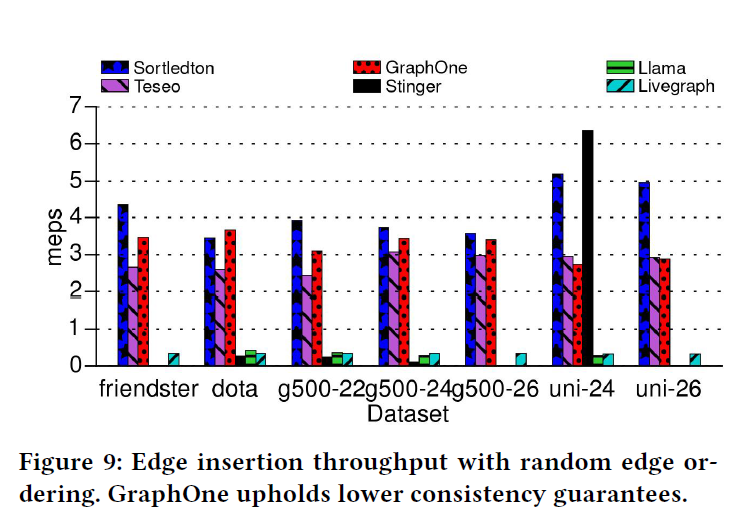
第二部分的实验是针对图算法的实验,主要比较的图算法包括局部集聚系数LCC、单源最短路SSSP、广度优先搜索BFS、弱连通分量WCC、基于标签传播的社区检测CDLP和PageRank。并且以CSR作为baseline。可以看出Teseo和Sortledton在各算法表现中较好,其中Sortledton更胜一筹。值得注意的是,LCC由于需要执行交集操作,只有维护有序集的Teseo和Sortledton才能在有效时间内执行。
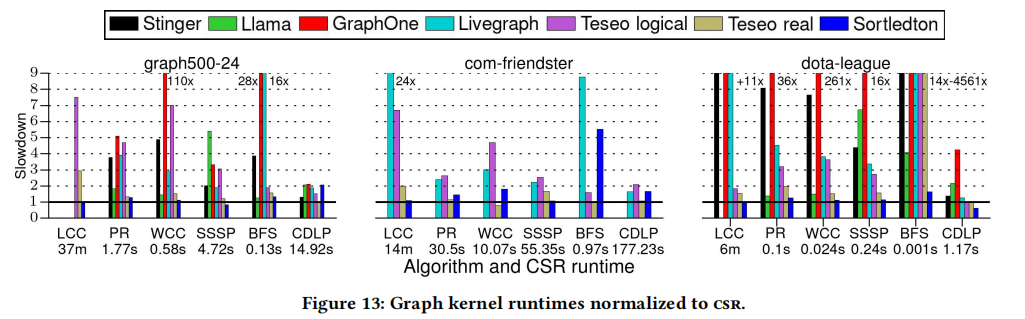
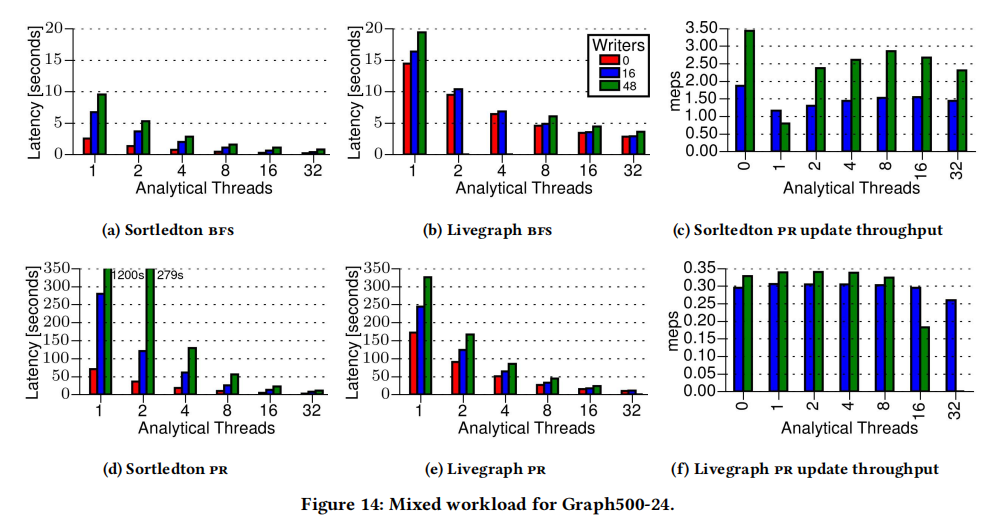
第三部分的实验是针对事务系统的实验,因此只有对支持事务的Teseo和LiveGraph系统的对比,其中Teseo由于在Sortledton进行实验期间存在bug,因此只有与LiveGraph的对比。可以看出,在线程数较少时,Sortledton的性比对LiveGraph有较大的优势,与第二部分的实验一致。但线程数较多时,两者在PR上的性能差距不大。这是因为LiveGraph的多版本是顺序存储的,而Sortledton需要遵循版本链,存在不连续的内存空间。
总结
本文介绍的三个系统在使用类CSR结构或邻接表的情况下,LiveGraph、Teseo、Sortledton有效的融合了事务系统和图分析系统,做到支持并发动态图分析。三篇论文为我们提供了设计针对图分析有效的数据结构,并设计了配套的事务系统的思路。


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
实验室开源产品图数据库gStore:
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore
![]()