- 论文名:Going depper with convolutions
- 论文下载地址:https://github.com/jixiuy/paper
- 引言第一段:背景+成绩
- 1*1的卷积在channel上升维和降维,channel融合,计算方法上等价于FNN
- GAP(全局平均池化):每个cov都利用相同维度的平均池化层进行处理,图片都进行用标量来代替特征,类似Flatten的作用,结果可以提升1-2个点
- Related work如果是老手可读可不读,如果是新生,帮助你快速进入领域的背景知识
- 用有特定值的卷积核对图像进行处理的核叫过滤核 filter core
- 总结回顾之前的问题,然后讲我是怎么解决的
- Inception的概念:
Inception块由四条并行路径组成。前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息。中间的两条路径在输入上执行1×1卷积,以减少通道数,从而降低模型的复杂性。第四条路径使用3×3最大汇聚层,然后使用1×1卷积层来改变通道数。这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。《动手学深度学习》
- 有些工作只是理论上有用,不能应用到现实生活
- 像谷歌的一些论文比较难懂,开始没读懂可以撂在那,之后他会解释
- 在论文里对引用论文的解释要到位
- depth:神经网络的堆叠层数。width:神经网络:节点数量;卷积:卷积核的数量。
- 没有必要读论文里一些不相关的内容,可以用到了再回过头来看。
- 解决小数据集容易过拟合,大数据集获取代价大:移除全连接用稀疏连接
- 神经网络(密集)
- 卷积神经网络(稀疏)
- 如果不对称不能够并行运算
- LeNet: 第一层卷积的feature map送入第二层卷积的时候,随机的送feature map而不是全部送。计算上不高效。
- AelxNet:全部送入下一层,更快的并行计算
- NAS:自动构建神经网络的工具
- Inception四条路分别提取不同尺度的信息,通过Padding来保证输出尺寸相同,在通道维度上拼接。每条路是密集的,4条路整体式稀疏的,因为和传统的一条路的形式不一致。
- stride减少的是空间维度,channel减少的是通道维度
- Stage可以方便的进行网路的缩放,每相同Stage中空间维度不变,不同Stage中空间维度可变,所以在每个相邻Stage中间需要用池化进行空间维度的变化,通道数比较随意,空间维度不能随意。
- GoogleNet网络结构:patch size指的是卷积核的尺寸

- Inception网络结构:

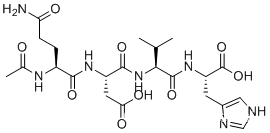
- 卷积大小计算公式:对于输入大小为 (H, W) 的图像或特征图,卷积核大小为 (K, K),步幅为 S,填充大小为 P,则输出大小为:
( ⌊ H + 2 P − K S ⌋ + 1 ) × ( ⌊ W + 2 P − K S ⌋ + 1 ) \left( \left\lfloor \frac{{H + 2P - K}}{{S}} \right\rfloor + 1 \right) \times \left( \left\lfloor \frac{{W + 2P - K}}{{S}} \right\rfloor + 1 \right) (⌊SH+2P−K⌋+1)×(⌊SW+2P−K⌋+1) - 防止梯度弥散,设置auxiliary classifiers (辅助分类器),网络结构和顶层的输出一样,分别得到loss1,loss2,loss3。loss=loss1+loss2+0.3loss3(系数不是论文里的),这样在反向传播的时候不至于每个梯度都为0,从不同角度看物体。下图黄色部分,详见论文。

- 训练细节第二遍不看
- 分类结果:(小trick、刷表)
- 为了获得更高的精度,GoogleNet采取了一些小Trick,同时利用7个版本的GoogleNet,预测的时候用了集成学习的方法。
- 对于一张图片取4个不同的尺寸,每个尺寸分别取左中右部子图,对于子图分别取四个角和中心,再镜像一下。435*2=144。从144个角度都预测然后取平均结果。