双机高可用方法目前分为两种:
1)Nginx+keepalived 双机主从模式:即前端使用两台服务器,一台主服务器和一台热备服务器,正常情况下,主服务器绑定一个公网虚拟IP,提供负载均衡服务,热备服务器处于空闲状态;当主服务器发生故障时,热备服务器接管主服务器的公网虚拟IP,提供负载均衡服务;但是热备服务器在主机器不出现故障的时候,永远处于浪费状态,对于服务器不多的网站,该方案不经济实惠。
2)Nginx+keepalived 双机主主模式:即前端使用两台负载均衡服务器,互为主备,且都处于活动状态,同时各自绑定一个公网虚拟IP,提供负载均衡服务;正常情况下访问不同的虚拟IP,将会访问其所在master上的nginx;当其中一台发生故障时,另一台接管发生故障服务器的公网虚拟IP(这时由非故障机器一台负担两个不同VIP所有的请求)。这种方案,经济实惠,非常适合于当前架构环境。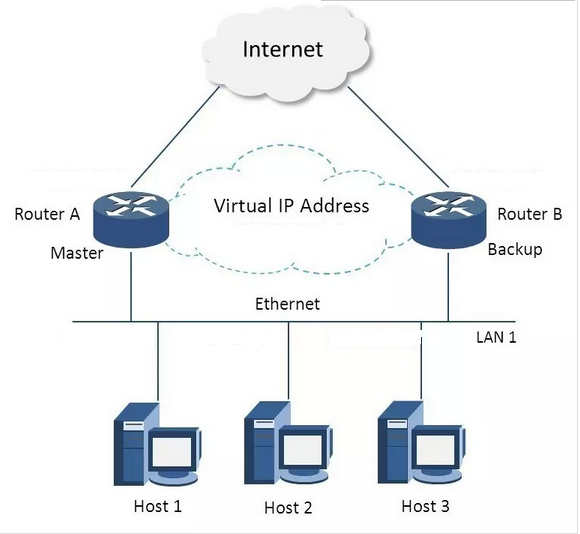
我这里选择双主模式
模拟环境:
虚拟机 10.0.0.128 与 10.0.0.129
10.0.0.129:安装 nginx + keepalived 主/备
10.0.0.128:安装 nginx + keepalived 备/主
双虚拟IP(VIP — virtual IP):10.0.0.100(对应129的master) 与10.0.0.101 (对应128的master)
第一步:安装keepalived-2.2.8
1、基础依赖包安装
yum install gcc
yum -y install openssl-devel #我的centos8缺少这个,只要执行这句命令即可
yum -y install libnl libnl-devel
yum -y install libnfnetlink-devel
yum -y install net-tools
yum -y install vim2、安装包下载、解压编译和安装
官网下载keepalived安装包:
Keepalived for Linux
将keepalived-2.2.8.tar.gz安装包上传到服务器上的某个目录下,此处为/usr/local/src目录下
进入安装目录下并解压安装包:
cd /usr/mysoft/
tar -zxvf keepalived-2.2.8.tar.gz进入解压目录
生成makefile文件:
./configure安装执行:
make && make install完成后会在以下路径生成:
/usr/local/etc/keepalived/keepalived.conf /usr/local/etc/sysconfig/keepalived /usr/local/sbin/keepalived
3 、初始化及启动
将配置文件放到默认路径下:
mkdir /etc/keepalivedcp /usr/mysoft/keepalived-2.2.8/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/将keepalived启动脚本(源码目录下),放到/etc/init.d/目录下:
cp /usr/mysoft/keepalived-2.2.8/keepalived/etc/init.d/keepalived /etc/rc.d/init.d/将keepalived启动脚本变量引用文件放到/etc/sysconfig/目录下:
cp /usr/mysoft/keepalived-2.2.8/keepalived/etc/sysconfig/keepalived /etc/sysconfig/将keepalived主程序加入到环境变量/usr/sbin/目录下:
cp /usr/local/sbin/keepalived /usr/sbin/
启动keepalived:
service keepalived start #如果启动不了,可以尝试重启centos8
附注:
service keepalived stop #停止服务
service keepalived status #查看服务状态4 、配置文件修改
停止keepalived服务,修改keepalived.conf配置文件(第3步中的/etc/keepalived/keepalived.conf)并重新启动keepalived服务加载配置文件。
128服务器keepalived配置如下
! Configuration File for keepalived
global_defs {
notification_email { #指定keepalived在发生事件时(比如切换)发送通知邮件的邮箱
acassen@qq.com ##设置报警邮件地址,可以设置多个,每行一个。 需开启本机的sendmail服务
}
notification_email_from Alexandre.Cassen@firewall.loc #keepalived在发生诸如切换操作时需要发送email通知地址
smtp_server 127.0.0.1 #keepalived在发生诸如切换操作时需要发送email通知地址
smtp_connect_timeout 30 #keepalived在发生诸如切换操作时需要发送email通知地址
router_id LVS_DEVEL #keepalived在发生诸如切换操作时需要发送email通知地址
vrrp_skip_check_adv_addr # 默认是不跳过检查。检查收到的 VRRP 通告中的所有地址可能会比较耗时,设置此命令的意思是,如果通告与接收的上一个通告来自相同的master 路由器,则不执行检查 ( 跳过检查 )
vrrp_strict # 严格遵守 VRRP 协议。
vrrp_garp_interval 0 # 在一个接口发送的两个免费 ARP 之间的延迟。可以精确到毫秒级。默认是 0
vrrp_gna_interval 0 # 在一个网卡上每组 na 消息之间的延迟时间,默认为 0
}
#检测nginx服务是否在运行。有很多方式,比如进程,用脚本检测等等
vrrp_script chk_nginx_port{
script "/opt/chk_nginx.sh" #这里通过脚本监测
interval 2 #脚本执行间隔,每2s检测一次
weight -5 #脚本结果导致的优先级变更,检测失败(脚本返回非0)则优先级 -5
fall 2 #检测连续2次失败才算确定是真失败。会用weight减少优先级(1-255之间)
rise 1 #检测1次成功就算成功。但不修改优先级
}
# 设置 keepalived 实例的相关信息,VI_1为VRRP实例名称
vrrp_instance VI_1 {
#指定keepalived的角色,MASTER表示此主机是主服务器,BACKUP表示此主机是备用服务器。注意这里的state指定instance(Initial)的初始状态,就是说在配置好后,这台服务器的初始状态就是这里指定的,但这里指定的不算,还是得要通过竞选通过优先级来确定。如果这里设置为MASTER,但如若他的优先级不及另外一台,那么这台在发送通告时,会发送自己的优先级,另外一台发现优先级不如自己的高,那么他会就回抢占为MASTER
state BACKUP
#指定HA监测网络的接口。实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的,默认为eth0,我这里是ens33
interface ens33
#指定HA监测网络的接口。实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的
virtual_router_id 51
#定义优先级,数字越大,优先级越高,在同一个vrrp_instance下,MASTER的优先级必须大于BACKUP的优先级
priority 90
#设定MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒
advert_int 1
#设定MASTER与BACKUP负载均衡器之间同步检查的时间间隔,单位是秒
authentication {
auth_type PASS #设置vrrp验证类型,主要有PASS和AH两种
auth_pass 1111 #设置vrrp验证密码,在同一个vrrp_instance下,MASTER与BACKUP必须使用相同的密码才能正常通信
}
virtual_ipaddress { #VRRP HA 虚拟地址 如果有多个VIP,继续换行填写
10.0.0.100
}
#执行监控的服务。注意这个设置不能紧挨着写在vrrp_script配置块的后面(实验中碰过的坑),否则nginx监控失效!!
track_script{
chk_nginx_port #引用VRRP脚本,即在 vrrp_script 部分指定的名字。定期运行它们来改变优先级,并最终引发主备切换。
}
}
#虚拟IP 10.0.0.101的配置
vrrp_instance VI_2 {
state MASTER
interface ens33
virtual_router_id 52 #注意这里与VI_1的配置要不一样
priority 100 #注意这里作为了master 优先级要高
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.101 #101虚拟IP配置
}
track_script{
chk_nginx_port
}
}
129服务器keepalived配置
129服务器keepalived配置与128相似,不同之处是VI_1 与 VI_2主从关系的变化,
global_defs {
notification_email {
921405797@qq.com
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_nginx_port{
script "/opt/chk_nginx.sh"
interval 2
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER #这里作为master
interface ens33
virtual_router_id 51 #注意配置要与128的VI_1一致
priority 100 #这里作为master 优先级高
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.100 # 虚拟IP配置
}
track_script{
chk_nginx_port
}
}
vrrp_instance VI_2 {
state BACKUP #这里作为backup
interface ens33
virtual_router_id 52 #注意配置要与128的VI_2一致
priority 90 #这里作为backup 优先级低
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.101 # 虚拟IP配置
}
track_script{
chk_nginx_port
}
}让keepalived监控Nginx的状态
1)经过前面的配置,如果master主服务器的keepalived停止服务,backup从服务器会自动接管VIP对外服务;
一旦主服务器的keepalived恢复,会重新接管VIP。 但这并不是我们需要的,我们需要的是当Nginx停止服务的时候能够自动切换。
2)keepalived支持配置监控脚本,我们可以通过脚本监控Nginx的状态,如果状态不正常则进行一系列的操作,最终仍不能恢复Nginx则杀掉keepalived,使得从服务器能够接管服务。
如何监控Nginx的状态:
最简单的做法是监控Nginx进程,更靠谱的做法是检查NginX端口,最靠谱的做法是检查多个url能否获取到页面。
注意,这里要提示一下keepalived.conf中vrrp_script配置区的script一般有2种写法:
1)通过脚本执行的返回结果,改变优先级,keepalived继续发送通告消息,backup比较优先级再决定。这是直接监控Nginx进程的方式。
2)脚本里面检测到异常,直接关闭keepalived进程,backup机器接收不到advertisement会抢占IP。这是检查Nginx端口的方式。
上文script配置部分,”killall -0 nginx”属于第1种情况,”/opt/chk_nginx.sh” 属于第2种情况。
个人更倾向于通过shell脚本判断,但有异常时exit 1,正常退出exit 0,然后keepalived根据动态调整的 vrrp_instance 优先级选举决定是否抢占VIP:
如果脚本执行结果为0,并且weight配置的值大于0,则优先级相应的增加
如果脚本执行结果非0,并且weight配置的值小于0,则优先级相应的减少
其他情况,原本配置的优先级不变,即配置文件中priority对应的值。
提示:
优先级不会不断的提高或者降低,可以编写多个检测脚本并为每个检测脚本设置不同的weight(在配置中列出就行)
不管提高优先级还是降低优先级,最终优先级的范围在[1,254],不会出现优先级小于等于0或者优先级大于等于255的情况
在MASTER节点的 vrrp_instance 中配置 nopreempt ,当它异常恢复后,即使它 prio 更高也不会抢占,这样可以避免正常情况下做无谓的切换,以上可以做到利用脚本检测业务进程的状态,并动态调整优先级从而实现主备切换。
另外:在默认的keepalive.conf里面还有 virtual_server,real_server,这样的配置,我们这用不到,它是为lvs准备的。。。
如何尝试恢复服务
由于keepalived只检测本机和他机keepalived是否正常并实现VIP的漂移,而如果本机nginx出现故障不会则不会漂移VIP。
所以编写脚本来判断本机nginx是否正常,如果发现NginX不正常,重启之。等待3秒再次校验,仍然失败则不再尝试,关闭keepalived,其他主机此时会接管VIP;
根据上述策略写出监控脚本。此脚本必须在keepalived服务运行的前提下才有效!如果在keepalived服务先关闭的情况下,那么nginx服务关闭后就不能实现自启动了。
该脚本检测ngnix的运行状态,并在nginx进程不存在时尝试重新启动ngnix,如果启动失败则停止keepalived,准备让其它机器接管。
监控脚本如下脚本名称chk_nginx.sh,并放到opt目录下(master和backup都要有这个监控脚本):
#!/bin/bash
counter=$(ps -C nginx --no-heading|wc -l)
echo "$counter"
if [ "${counter}" = "0" ]; then
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
sleep 2
counter=$(ps -C nginx --no-heading|wc -l)
if [ "${counter}" = "0" ]; then
/etc/init.d/keepalived stop
fi
fi为脚本文件设置权限
chmod 755 chk_nginx.sh此架构需考虑的问题:
1)由于采用双master模式,访问不同的VIP会进入各自的对应的master,访问该master对应的VIP。如10.0.0.100地址会访问129的nginx,如10.0.0.101地址会访问128的nginx,
2)如果其中一个keepalived挂了,则当前keepalived的VIP转移到对应的slave上,例如:128宕机,129作为128的backup会接管其VIP10.0.0.101,当访问101时会访问到对应129的nginx。
3)如果master上的nginx服务挂了,则nginx会自动重启,重启失败后会自动关闭keepalived,这样vip资源也会转移到backup上。
4)检测后端服务器的健康状态
5)master和backup两边都开启nginx服务,无论master还是backup,当其中的一个keepalived服务停止后,vip都会漂移到keepalived服务还在的节点上;
如果要想使nginx服务挂了,vip也漂移到另一个节点,则必须用脚本或者在配置文件里面用shell命令来控制。(nginx服务宕停后会自动启动,启动失败后会强制关闭keepalived,从而致使vip资源漂移到另一台机器上)
最后验证
不同场景下访问不同VIP地址,将会解析到哪个nginx:关闭主服务器上的keepalived或nginx,vip都会自动飘到backup服务器上
1. 启动 keepalived 之前,咱们先使用命令 ip a , 查看 10.0.0.128和 10.0.0.129这两台服务器的 IP 情况
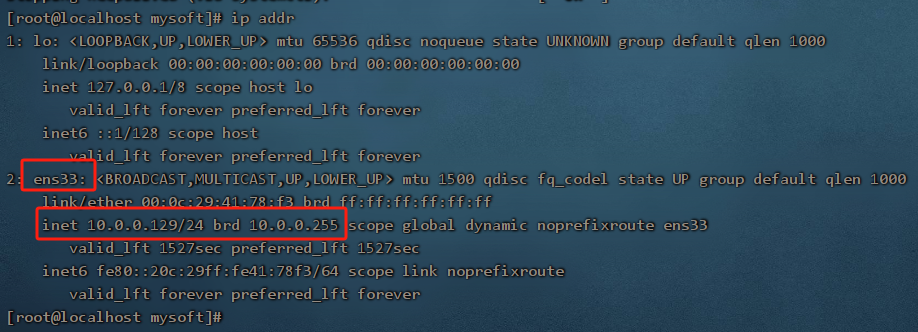
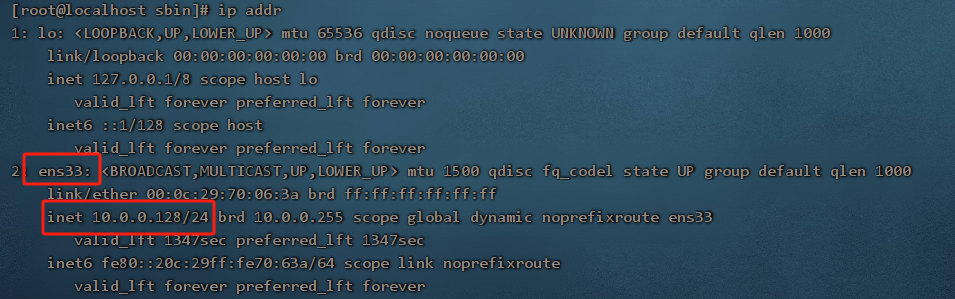 2. 分别启动两台服务器的 keepalived
2. 分别启动两台服务器的 keepalived
看到VIP 10.0.0.100和10.0.0.101已经分别被129和128服务器接管了,
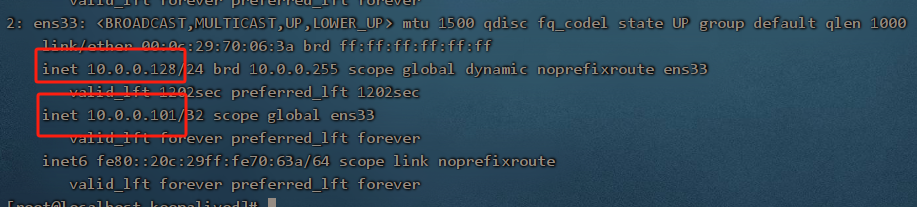
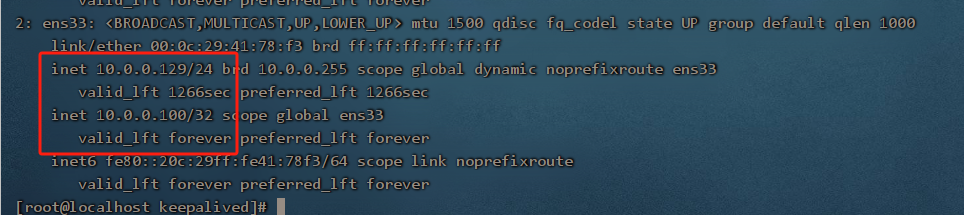
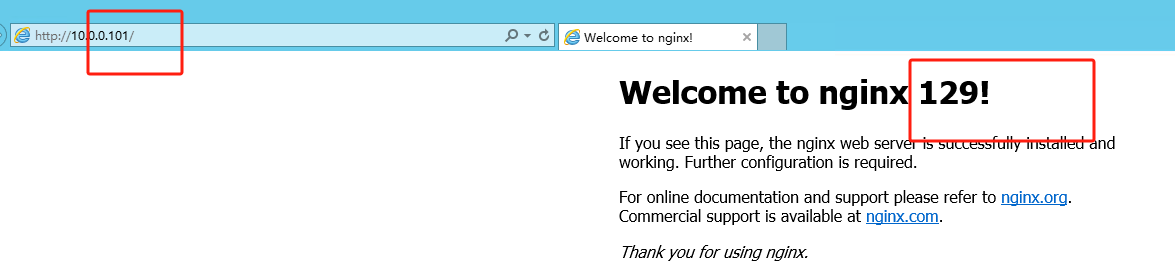
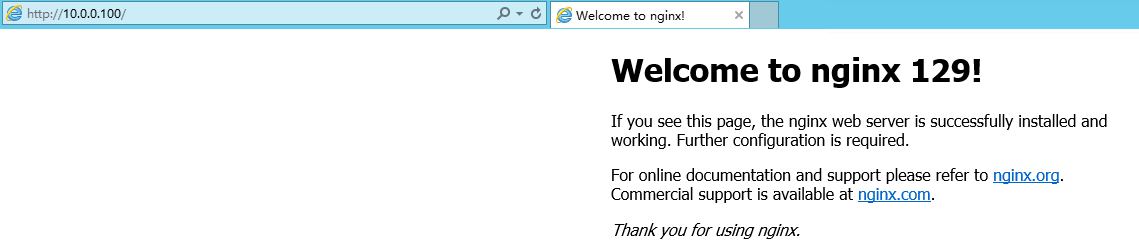
此时通过http://10.0.0.100与http://10.0.0.101都将访问到129和128的nginx,验证问题1
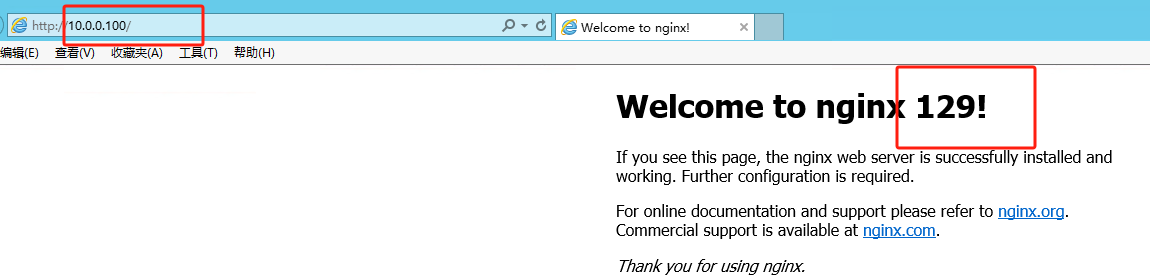
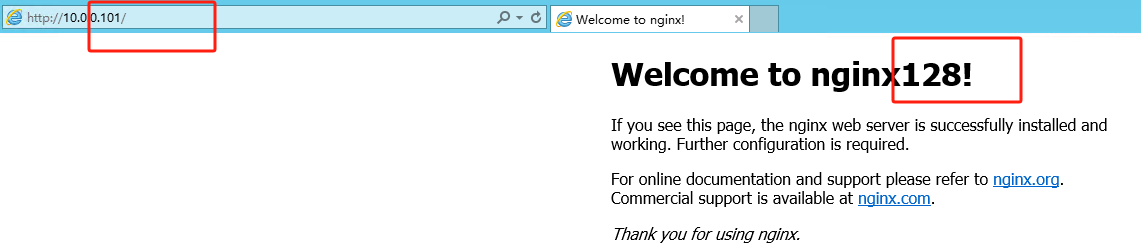
2. 停止128服务器的keepalived
看到因为128宕机,VIP 10.0.0.100和10.0.0.101已经都被129服务器接管了,验证问题2
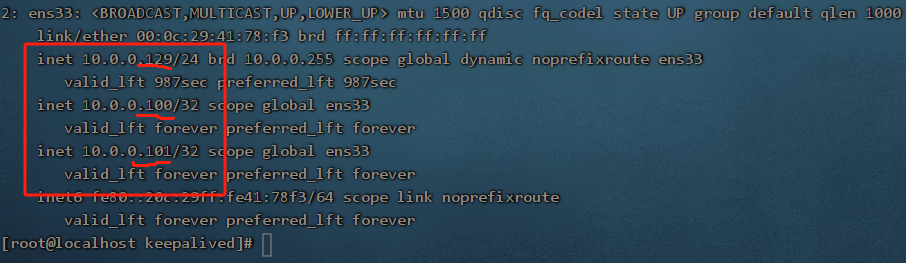
此时通过http://10.0.0.101 也访问到了129的nginx,100也能正常访问到129.