目录
1 自从 Alexnet 之后,对视频理解的研究就从这种手工特征慢慢转移到卷积神经网络了。
编辑
1.1Deep video——深度学习时代,使用卷积神经网络去处理视频理解问题的最早期的工作之一
1.2如何把卷积神经网络,从图片识别应用到视频识别
1.1.1baseline—— single frame
1.1.2尝试变体1—— late Fusion
1.1.3尝试变体2—— early Fusion
1.1.4尝试变体2—— slow Fusion
1.1.5这几种变体效果差别不大,而且即使大数据集上预训练了效果还是不好——新尝试:多分辨率的卷积神经网络的结构
1.1.6本文贡献
2 two stream双流网络及其变体
2.1研究动机
2.2双流网络如何处理时间信息
2.3双流网络的变体总结
2.3.1 LSTM 这个方向,提升有限
1、具体怎么使用LSTM
2、实验表明
2.3.2 early Fusion 这个方向
1、本文回答了三个问题:如何spatial fusion、如何temporal fusion、在哪一层做fusion
2、 如何spatial fusion
3、 在哪一层做fusion
4、 如何temporal fusion
5、分别回答完这三个问题之后,作者就提出了最后的总体框架
6、模型怎么做推理的?
6、结果
7、贡献
2.3.3如何处理更长时间的这个视频问题——TSN
1、贡献
(TDD 如何更好地利用光流)
2、研究动机
3、temporal segment的思想
3、好用的技巧
cross modality Pre training
模型正则化的技巧
2个数据增强
4、效果
(DVOF和TLE 给TSN加入全局编码)
总结
大家好,前两期我们讲了视频理解领域里的两篇经典的论文,一个是双流网络,第一个是 I3D 网络,所以说对视频理解这个问题有了个基本的了解。

那今天我们就从 2014 年开始,一直到最近 2021 年的工作,我们一起来总结一下,做一个串讲。上图这篇论文其实是我们组两年前写的一篇综述论文,当时是为了我们要在 CVPR 2020 年举办的一个视频理解的 tutorial 而准备的一些讲义和资料,结果越写越长,就写成一篇综述论文了。我们这篇综述里大概提及了超过 200 篇在视频领域里的论文,除了没有 video Transformer,基本是包含了之前用 deep learning 去做 video action recognition 的大部分工作。
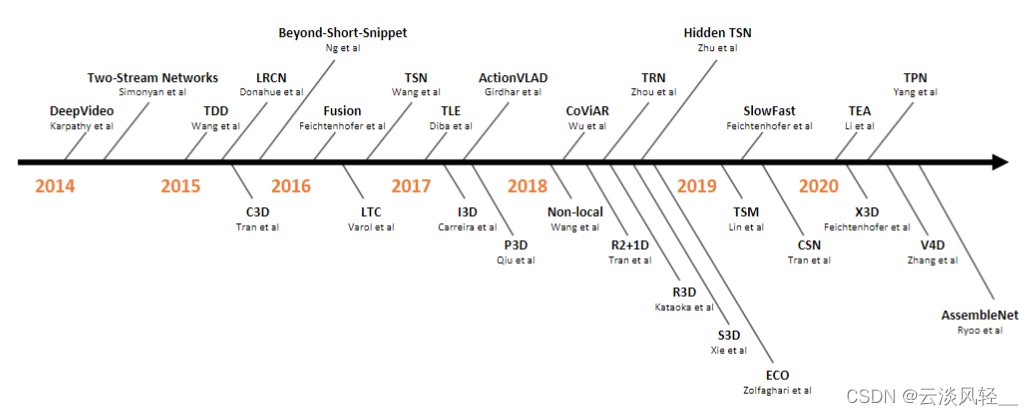
今天这期视频,其实我也是想仿照之前图 3 里这种时间线上的结构,从最开始的用卷积神经网络做Deep video 这个工作,然后到双流网络以及双流网络的这些大部分的变体(TDD、LRCN、Beyond-Short-Snippet、Fusion、TSN、TLE),还有 3D 网络以及 3D 网络的这些变体(I3D、P3D、Non-local、R2+1D、R3D、S3D、ECO),以及讨论一下最新的基于 video Transformer 的工作。
那鉴于本期内容比较多,我们就直奔主题,大概我会分四个部分来讲。
第一部分就是自从 Alexnet 之后,对视频理解的研究就从这种手工特征慢慢转移到卷积神经网络了。在这一部分里,我们只讲一篇论文,就是 CVPR 14 的 deep video 那篇论文。
接下来在第二部分和第三部分,我们会分别讲双流网络及其变体,还有 3D 卷积神经网络以及它的变体,这两个部分涉及的工作比较多,所以会讲很久。
然后到第四部分,自从 vision Transformer 出现以后,视频理解领域里是如何把 image Transformer 延伸到 video Transformer 上。其实这里面它用的很多方法都是直接从 2 或者 3 里面来的,尤其是借鉴了很多在 3D 卷积神经网络里使用的技巧,所以说第四部分讲的也会比较快。
1 自从 Alexnet 之后,对视频理解的研究就从这种手工特征慢慢转移到卷积神经网络了。

1.1Deep video——深度学习时代,使用卷积神经网络去处理视频理解问题的最早期的工作之一
那首先我们来看一下 CVPR 14 的这篇 Deep video 的论文,题目非常直截了当,上来就是说大规模的视频分类理解用卷积神经网络来做。其实在这篇论文之前,也有一些工作是用神经网络来做的,有卷积神经网络,也有用LSTM,但是那些工作都是在 Alex net 出现之前,一般使用的数据集都比较小,或者说网络也比较浅。而 deep video 这篇论文是在 Alex net 出现之后,是在深度学习时代使用了超大规模的数据集,而且使用了比较深的这种卷积神经网络去做的。所以说算是深度学习时代使用卷积神经网络去处理视频理解问题的最早期的工作之一。
作者团队来自于 Google research 和Stanford,一作就是之前我们也提过好几次的 Andrej capacity, 14 年的时候他还是 Stanford 的一个博士生,这片工作是他在 Google 实习的时候完成的一篇论文。然而就在短短的七八年之后, Andrej 就已经带领特斯拉的团队把辅助无人驾驶做得这么好了。接下来几位作者都来自于 Google research,这个团队其实为视频理解领域做出了很大的贡献,不光是这篇论文里提出的 Sports one million 这个数据集,他们在两年之后又推出了一个更大的 YouTube eight million 的数据集,还有最近为了 action detection 提出的 Ava 数据集,全都是这个团队做的。最后就是我们耳熟能详的李飞飞老师,在 image net 数据集取得了如此巨大的成功之后,又来建立一个如此大规模的视频数据集,也是很大程度上推动了视频理解领域的发展。
1.2如何把卷积神经网络,从图片识别应用到视频识别
那论文本身其实它的方法是比较直接的想法,其实就是说如何把卷积神经网络从图片识别里面应用到视频识别里面,那视频跟图片唯一的不同就是它多了一个时间轴,就是说它有更多的这个视频帧,而不是单个的图片了。
那所以很自然就有几个变体是需要尝试的,比如说这里列出来的后三种变体,那我们一个一个来过。
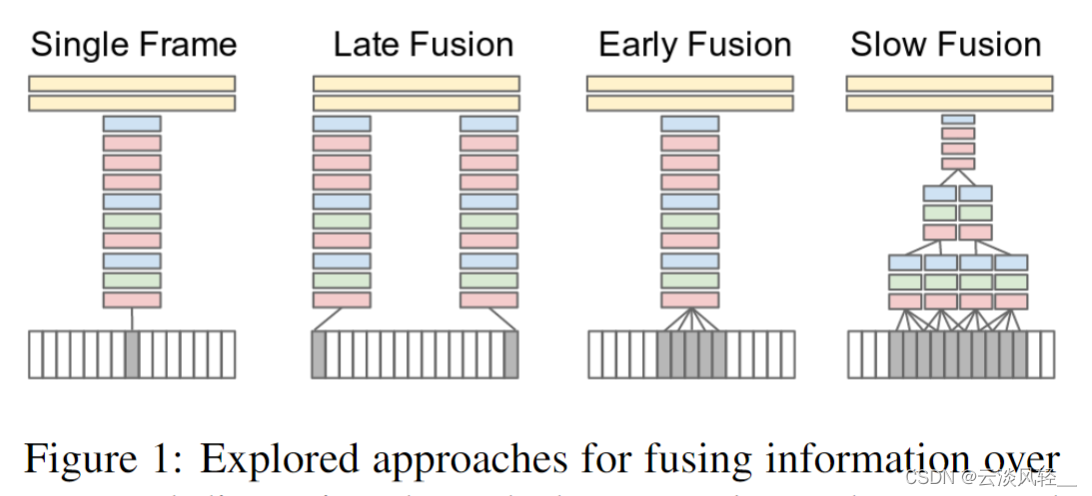
1.1.1baseline—— single frame
首先论文里说的这个 single frame 的方式就是单帧的方式,它其实就是一个图片分类的任务,在一个视频里任选一帧,然后把这一帧通过一个CNN,最后通过两层FC,然后得到一个分类结果。那这个其实就相当于是一个baseline,就是它完全没有时间信息,也完全没有视频信息在里面,然后作者就开始做各种尝试了。
1.1.2尝试变体1—— late Fusion
首先第一个比较好做的尝试就是 late Fusion,我们在讲双流网络的时候也讲过,之所以叫它late,是因为它是在网络输出层面做的一些结合。那这幅图里就是说,比如说我有一个视频,我去随机的选几帧,然后每一帧都是单独的通过一个卷积神经网络,这两个神经网络是全值共享的。然后把得到的这两个特征合并一下,通过这个 FC 层最后做一下输出。这样虽然从做法上还是单帧进入一个卷积神经网络去得到一个特征,还是比较像图片分类的,但是毕竟因为后面把这个特征合并起来了,所以说稍微有一些这个时序上的信息在里面,
1.1.3尝试变体2—— early Fusion
那做完了 late Fusion 自然对应的就会有这种 early Fusion,那作者这里采用的是非常 early 的做法,也就是在输入层面就做了这种融合。具体的做法就是把 5 个视频帧在 RGB 那个 channel 上直接合起来,那这样呢,原来一张图片,RGB 有三个channel,现在五个图片,所以就是有 15 个channel,那也就意味着网络结构要进行一定的改变了,尤其是第一层,那你这个第一个卷积层接受的这个输入的通道数就要用原来的 3 变成 15 了,但之后的网络都跟之前保持不变。这种 early Fusion 的做法就能在网络的刚开始就能从输入的层面去感受到这种时序上的改变,希望能学到一些全局的运动或者时间信息。
1.1.4尝试变体2—— slow Fusion
那最后既然你做过 late Fusion,又做过 early Fusion,那其实另外一个更直接的变体就是说为什么不把这两个合起来做。于是作者这里也尝试了一下,他管这个叫 slow Fusion,意思就是说你这个 late Fusion 合并的太晚了,这个 early Fusion 又合并的太早了。如果能在这个网络学习的过程中,就在这个特征层面再去做一些合并了,那就再好不过了。具体的做法就是每次先选一个有十个视频帧的一个小的视频段,然后每四个视频帧就通过一个卷积神经网络去抽取一些特征,这些刚开始的层也都是全值共享的,那在抽出最开始的这些特征之后,由最开始的 4 个输入片段,我们又把它慢慢合并成两个输入片段,然后再做一些卷积操作去学习更深层的特征,最后再把这个特征给FC,然后去做最后的分类。这个意思就是说整个网络从头到尾其实都是对这个视频的整体在进行学习,那按道理来说结果应该是最好的,而事实上它结果也是最好的。
1.1.5这几种变体效果差别不大,而且即使大数据集上预训练了效果还是不好——新尝试:多分辨率的卷积神经网络的结构
但作者没有想到的是,其实这几种方法差别都不大,而且更没有想到的是,即使是在 100 万个视频上去做了预训练之后,在 UCF 101 那个小数据集上去做迁移学习的时候,竟然效果还比不上之前的手工特征,这个就非常诡异了。
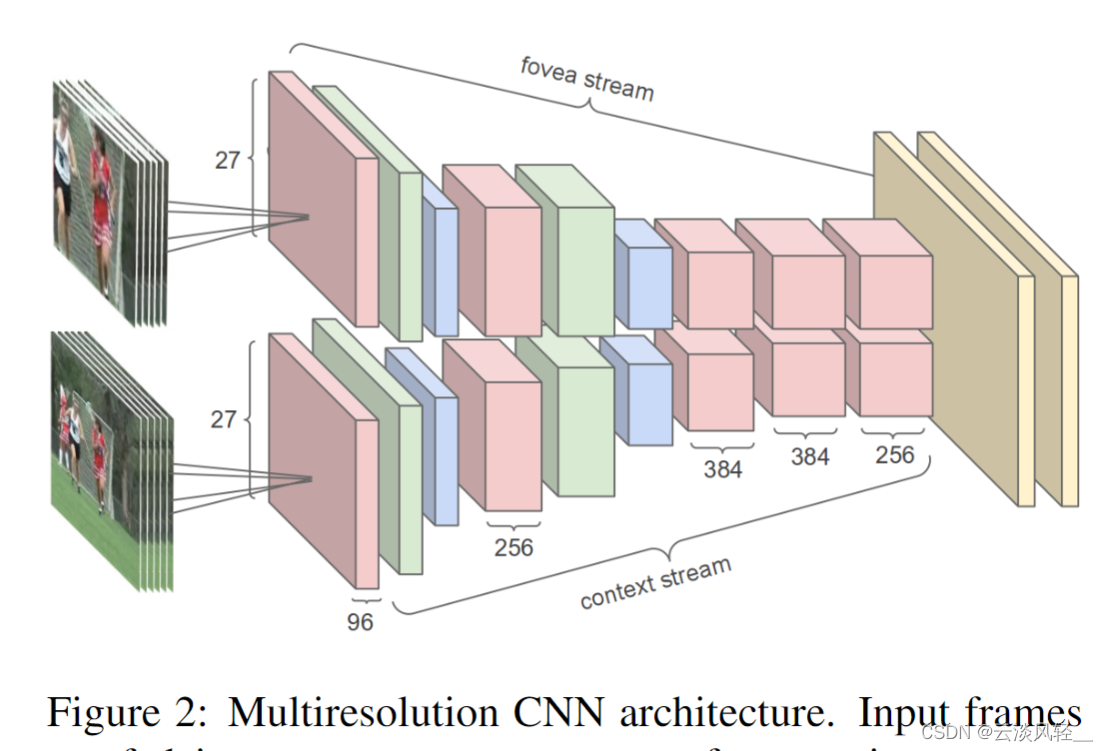
所以作者又开始尝试另外一条路。那另外一种尝试就是作者这里在图 2 里画的这种多分辨率的卷积神经网络的结构,作者一看用这个 2D 卷积神经网络去学这个时序特征确实很难,不好学,那我就先不学了,我把图像那边使用卷积神经网络一些好用的 trick 搬过来,看能不能在视频领域里也工作得很好,也就他这里想尝试的这种多分辨率卷积神经网络。
简单的来说,作者就是把输入分成了两个部分,一个是原图,另外一个就是从原图的正中间抠出来一部分,变成上面的这个输入。因为不论是对图片还是对视频来说,一般最有用的或者说物体都会出现在这个图片的正中间,所以它就把上面的这一分支叫做 FOVEA stream,下面的这一分支叫做 context stream 。
FOVEA其实就指的是人眼视网模拟最中心的一个叫中央凹的东西,它是对外界变化最敏感的一个区域,而 context 指的就是图片的这个整体的信息,作者就是想通过这个操作既能学到这个图片里最有用的中间的那些信息,又能学习到这个图片整体的一个理解,看看这样能不能提升对视频的理解。
其实这个架构也可以理解成是一种双流结构,因为它也有两个网络,但是这两个网络是全值共享的。
然后这种架构也可以理解成早期对于注意力的一种使用方式,它强制性的想让这个网络去更加关注图片中心的区域
那总之一顿操作下来,虽然这个多分辨率卷积神经网络有一定的提升,比如说跟这个单帧的这个 baseline 比,这个单帧加上这个多尺度之后,这个效果还是有一定提升的,但是这个提升相对来说是比较小的。
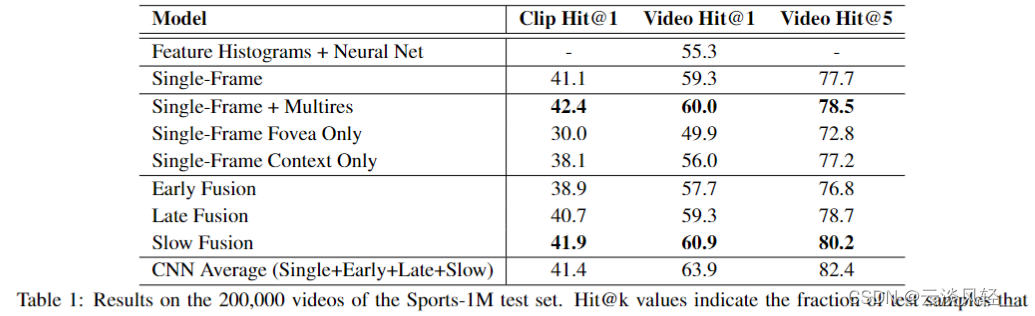
然后我们再来看一下这个单帧的 baseline 加上这几种时间信息上的合并之后,会有什么样的表现。
- 我们可以发现 early Fusion 确实做得太 early 了,所以说它的效果还不如用这个 single frame 的baseline,
- 然后 late Fusion 也不如baseline,
- 只有最后的这个 slow Fusion 经过了一顿复杂的操作之后,才勉强比这个 single frame 的 baseline 高了一点点,而且这个还是在他们提出的这个 Sports one million 这个数据集上的结果,
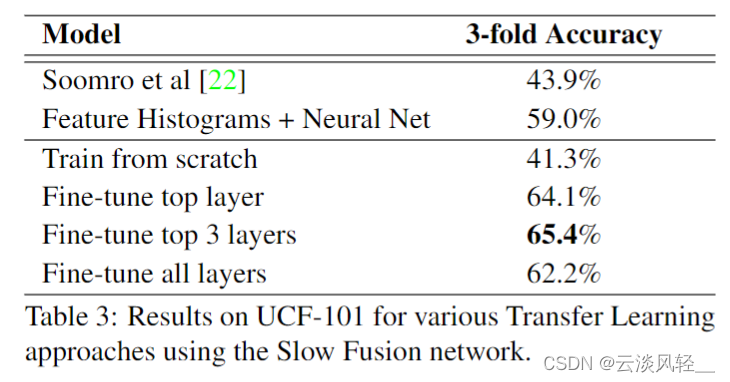
那如果我们换一个数据集,就是换到 14 年当时大家广为接受的 UCF 101 数据集上,我们可以看到作者这里最好的变体也只有 65 点儿 4 的这个准确度。
而事实上我们之前在双流网络那篇论文里也讲到过,当时最好的手工特征的方法就已经能达到 87 的这个准确度了。也就意味着说,当你使用了这么多预训练的数据,而且又使用了这么大规模的一个网络之后,最后这个迁移学习的结果竟然还不如一个手工特征的结果,而且是远远不如。
1.1.6本文贡献
所以说引发了大家很多的思考,为什么深度学习在图片分类、图片检测、分割那边都工作的这么好,但是在视频领域里怎么就碰壁了?但这篇文章的意义其实是不在于它的效果的,它不仅提出了当时最大的这个视频理解的数据集,而且把你能想到的这种最直接的方式全都试了一遍,给后续的工作做了一个很好的铺垫,这才有了后面几年深度学习在视频领域里的飞速的发展。
所以到 1819 年的时候,这个视频理解或者说这个动作识别已经是 CV 领域排名前五前六的一个关键词了,是一个非常主流的视觉任务。
2 two stream双流网络及其变体
2.1研究动机
那说完了 deep video,接下来我们就来讲一下双流网络,因为我们刚才在 deep video 这篇论文里也看到了, 2D 这个网络,在当时还是不能很好的去学习这种时序信息的,而视频理解和这个图像理解最关键的区别就在于它多了一个时间轴,所以如何去更好地处理这个时间信息,可能才会带来更大的提升。
所以接下来大家就想了很多的方法,双流网络是其中一个,它就利用了光流这个特征去帮助网络学习。当然了也有很多人尝试想用 LSTM 去做这个视频理解,另外大家就想用这种 3D 卷积神经网络,因为本身视频它就是一个 3D 的输入,所以你用 3D 的网络去应对听起来就更合理。然后其实还有很多别的操作了,比如说基于轨迹的一些方法,基于 ranking function 的一些方法,还有基于 shift 移位这种操作。总之在 2014 年之后的这五六年里,视频动作识别还是发展的相当不错的。
2.2双流网络如何处理时间信息
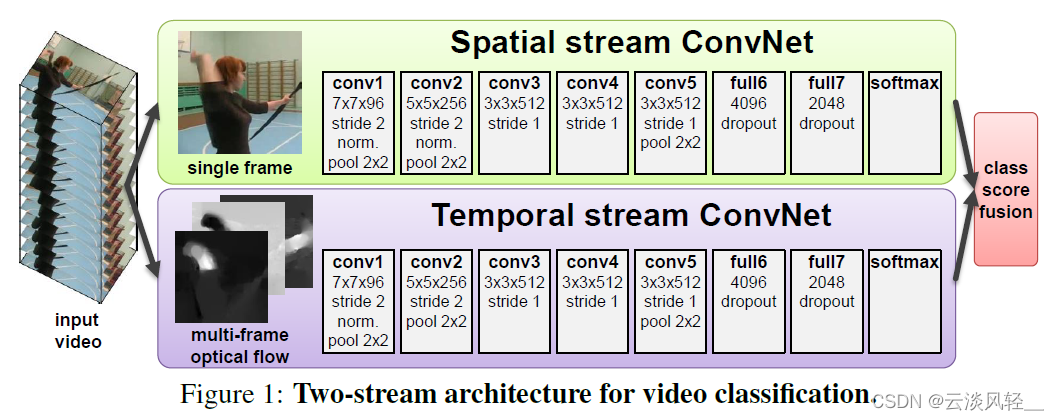
那首先我们来回顾一下双流网络,双流网络我们在之前的视频里已经讲到过了,所以这里我们就直接跳到 图1。双流网络的主要意义就是说当你用一个卷积神经网络无法去很好地处理这个时序信息的时候,你只需要在下面再加一个卷积神经网络去专门处理这个时序信息就好了。比如说像这里从这个原始视频中去抽取对应的这个光流图像,那这个光流图像里就涵盖了很多的这个物体移动的信息,以及这个视频的这时序信息。
那最后上面的这个空间流网络其实就是在学一个从 RGB 图像到最后的这个分类的映射,而下面的这个时间流网络就是学一个从光流图像到最后的分类的这么一个映射,这两个卷积神经网络都不用去学习这种时序信息了,他只需要去学习这种对应的映射就可以了,一下就把问题给简化了,而且两个网络各司其职,谁也不干扰谁,相对而言优化起来就轻松许多。
2.3双流网络的变体总结
所以别看是仅仅加上了下面这一支这个时间流的网络,但是大幅度地提高了这个性能,那一旦双离网络证明了它的这个成功,那迅速就有很多工作跟进了。我们其实单从这个图里就能看到有几个比较容易能想到的想法,
- 比如说首先你最后这个合并,这个 Fusion 是坐在最后面的,你是在已经经过 Softmax 之后才做合并,所以也叫 late Fusion,那自然而然的肯定就会有人问,那你能不能做 early Fusion?那 early Fusion 的效果会不会比 late Fusion 好?因为按道理来说,如果你能在前面这些层之间去做这种空间和时间流的特征交互,应该是比你在最后做一个简单这种加权平均效果要好的。所以说怎么去做 early Fusion 算是一个研究方向。
- 第二个更直接的就是这里面明显就是一个 Alex net 的变体。那接下来大家已经有了 exception net VGG net rest net 以及更深的其他网络,那很显然对于深度学习时代来说,那越深的网络一般效果是越好的。那尝试更深的网络对于视频动作识别来说也是一个研究方向。但是是因为普遍来说视频这些数据集都比较小,所以说如何在小数据集上去训练大模型是一个难点,如何更好的去控制这个过拟合是个很难的问题。
- 那第三个方向就是说当你把一个图片通过一个卷积神经网络,最后得到一个特征,双流网络直接就是把这个特征拿来就去做分类。同样的道理,对于这个时间流网络来说,也是把这个特征抽取来之后直接就去做分类。而事实上我们知道我们有一类非常成熟的模型叫做 RNN 或者LSTM,他们是专门用来处理这种时序信息的。其实很多人一直都觉得 LSTM 应该是处理视频理解的一个非常好的工具,如果你先能在每一帧上用这个卷积神经网络去抽特征,然后你再抽出来的这个特征之上再去加一个 LSTM 层,去把它们之间的这些时序信息模拟起来,那你最后得到的特征应该会更强,所以这也就是第三个可以做的研究方向。
- 那第四个我们可以探索,就是说不论你是用单张图片还是用这个光流图像,这光流图像这里面是 10 个视频帧得到的,它都非常的短,因为对于一个帧率为 25 或者 30 的视频来说,即使是 10 帧也才对应不到 0. 5 秒的时间,是非常非常短的。但是一般一个动作或者一般一个事件,它的这个持续时间都是两三秒甚至更长,那我们如何去做这种长时间的这种视频理解?很显然不论是单帧还是光流都不能给我们有效的答案,
所以说分别针对这几个研究方向,也就分别推出了不同的工作。接下来我就针对每一个方向去讲一个代表工作。
2.3.1 LSTM 这个方向,提升有限
那首先我们提到的就是这篇 CVPR 15 的论文叫 beyond short snippets deep network for video classification,题目的意思就是说我不想再做这种特别短的这种视频。理解了题目里的 short snippet 其实就是指那种两三秒或者甚至还不到两三秒的小的视频段。
作者团队其实我们可以看到跟之前 deep video 的那个作者团队还是差不多的,还是来自于 Google 这个组,只不过一作换了另外一个实习生。
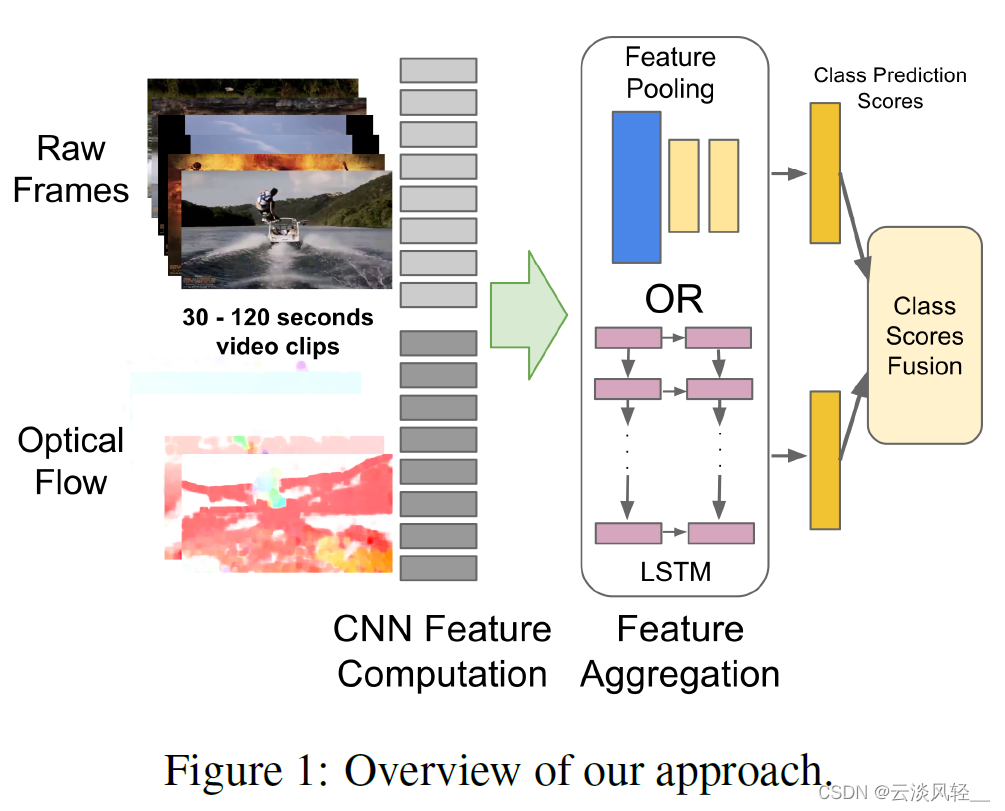
他这篇论文的主要方法其实都画在这个图一里了,就是说如果你按照双流网络的那种思想去做,这个原始图像只有一帧或者几帧,这个光流图也就只有十帧,那它能处理的视频其实是非常短的。
那如果这时候我们有特别多的这个视频帧,那该怎么处理?
1、那其实一般来讲,对于所有的这些视频帧,我们肯定都是先用一种方法去抽它的特征,比如说原始的手工特征,那就是我们抽一个 sift 的特征,那对于现在深度学习时代,我们就拿一个卷积神经网络去抽一个特征,
2、关键就是说在抽到这些特征之后,我们该如何去做这个 pooling 这个操作,我们当然可以简单的做一个 Max pooling 或者 average pooling。那这篇论文里做了非常详尽的这个探索,它还做了conv pulling,它还像 deep video 那篇论文一样做了 late pulling、slow pulling、local pooling。最后的结论其实也是都差不多,就是这个conv pooling 表现最好。
3、然后他们又尝试了一下用 LSTM 去做这种特征的融合,那按道理来说, LCM 能够掌握这种时间上的变化,应该是一个更好的特征融合的方式。但是其实一会儿我们看结果,它的提升也非常有限,
1、具体怎么使用LSTM
那具体怎么使用STM,其实就在他们的这个图 4 里有写,那这个 c 在这里就代表着最后这个卷积神经网络抽出来的那个特征,意思就是说每一个视频帧它其实都对应了一个卷积神经网络,然后去抽取到这个 c 这个特征,当这里这个卷 d 神经网络肯定都是权值共享的,而不是说有很多单独训练的网络。
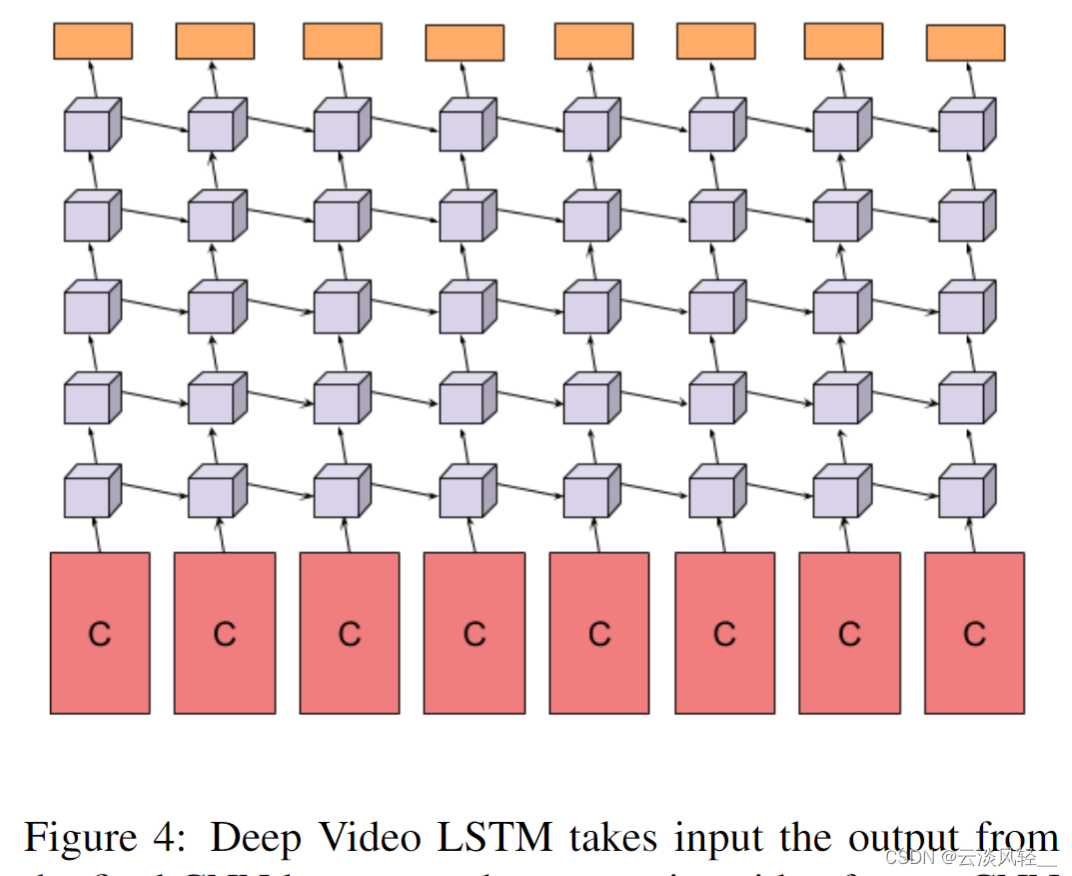
那当你达到这些特征以后,其实这些特征在时序上是有顺序的,所以你才想到要用一个 LstM 去做这种特征的融合。
那接下来作者这里就用了 5 层 LstM 网络去处理之前这些抽取出来的这个视频特征,最后这个橘黄色部分就代表 Softmax 操作,就直接做分类。
所以说这个改动相对于双流网络来说是非常直接的,前面的操作通通都没有改变,只是在最后一个卷积层之后,不是简单的做一层 FC 操作直接做分类,而是把所有的这些特征通过一些 LSTM 层去做一些时序上的处理和融合,最后再做这个分类。
2、实验表明
作者这里先是在 Sports one million 数据集上做了一下实验,它就对比了一下之前的这个最好的结果,比如说单帧或者 slow Fusion,那 slow Fusion 其实就是 deep video 的结果了。然后他们论文里提出来就是这个 conv pulling 和使用LSTM。我们首先可以看到,在使用这个视频帧数上,这个 conf pulling 和 LSTM 都能使用非常多非常多的这个帧,意思就是说他能看到非常长的这个视频,最后的结果也比之前的这两种方法好了许多。
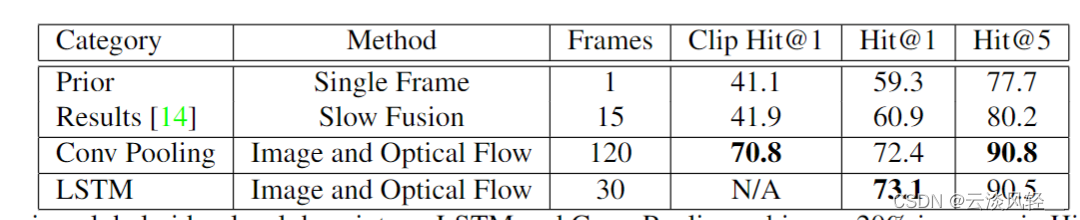
当然了,这里这么大的提升也不光是使用了 count pulling 或者LSTM,主要还是因为使用了这个光流,而且看到了更多的这个视频帧,如果你仅仅地去对比这个 count pooling 和 LCM 来看,其实它们的差距基本没有多大,也就是说 LSTM 没有想象中的那么有用。
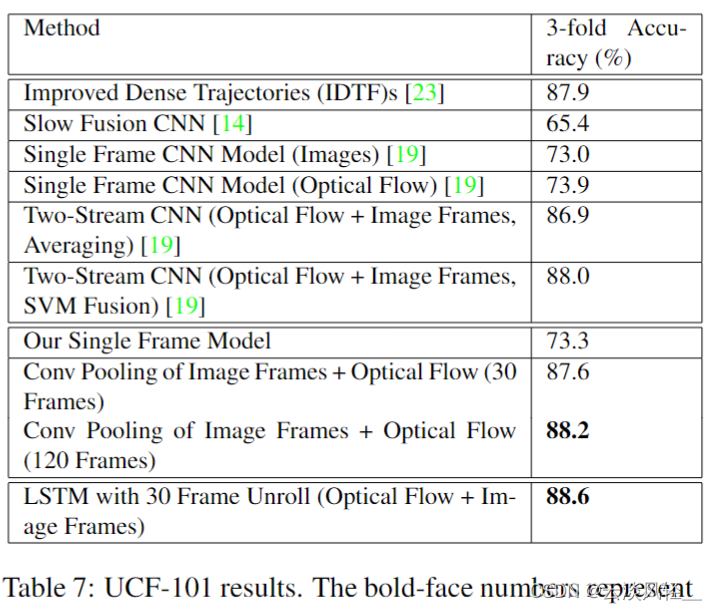
那如果我们再来看一下 UCF 101 上的结果,那之前传统的手工特征方式最好能达到 88 的这个准确度,然后 deep video 就只有 65. 4,因为它没有很好地利用这个时序的信息,然后双流网络一上,立马这个效果就不一样了,直接就88,跟之前最好的手工特征打平手了。
然后这篇论文是完全在双流网络的基础上在做的,所以说它的效果肯定是要比双流网络更好才行。而事实上,我们这里可以看到,当使用 120 帧的 com pulling 的时候,也只有 88. 2 的准确度,只比 88 高了一点点。然后使用了 STM 之后用了 30 帧,也只有 88. 6 的效果,只比 88 好了一点点。所以说在短视频上,比如说像 UCF 101 这种只有六七秒的视频上, LSTM 所带来的提升是非常有限。当然这个在我看来其实也是比较好理解的,因为我一直觉得像LSTM 这种操作,它学的是一个更 high level,更有语义信息的一个特征。给 LSTM 的这个输入必须有一定的变化, LCM 才能起到它应有的作用,它才能学到这个时间上的这个改变。但如果你的视频比较短,只有五六秒六七秒的话,你这个语义信息可能根本就没有改变。你从这个视频里去抽了很多帧出来,然后再把这些帧通过这个卷积神经网络去抽到这个更有语义信息的特征之后,这些特征其实可能都差不多,都代表了差不多的意思。
那你把这样的特征传给一个 LSTM 网络,就相当于你把很多一模一样的东西给了LSTM,那你指望 LSTM 能学到什么呢?它其实什么也学不到。这这也就是我觉得为什么在短视频上 l s t m 不能发挥它威力的原因。如果在长视频上,或者说变化比较剧烈的视频理解上,LSTM 还是有用武之地的。那说完了 LSTM 这个方向,接下来就该说 early Fusion 这个方向了。
2.3.2 early Fusion 这个方向
这篇是 CVPR 16 的一篇论文,叫做 Convolutional Two-Stream Network Fusion for Video Action Recognition,它其实就把双流网络题目给颠倒了一下,双流网络叫做 toolstream collusional network,它叫 convertional toolstream network,其实关键词只有一个,就是这个Fusion。这篇文章非常细致地讲了一下到底如何去做这种合并,就是说当你有了这个时间流,又有了这个空间流之后,你如何去在这个两个流之间去做这种early Fusion?
1、本文回答了三个问题:如何spatial fusion、如何temporal fusion、在哪一层做fusion

- 它这个图一里其实只画了他们论文中的一部分,就是如何去做这种空间上的Fusion。比如说现在都有两个这个特征图,那如何把特征图上的这两个对应的点去做这种合并?那这个在论文中叫 special Fusion,
- 那作者还讨论了一些 temporal Fusion 的方法。
- 然后在你决定了去做这种 Fusion 之后,那到底在网络的哪一层去做这种 Fusion 也是非常关键
所以说作者就从这三个方向分别回答了这几个问题,从而最后得到了一个非常好的一个 early Fusion 的网络结构,能够比之前直接做 late Fusion 的这种双流网络效果也好不少。
那接下来看作者团队,一作这个 Christopher 在做完这篇工作之后就一发不可收拾,在视频领域里出了很多代表性的工作,比如说之后的 slow fast X3D,直接就把 3 d c nn 做到了极致,让大家不得不去转向 video Transformer 了。然后 video Transformer 里他也做了 MVIT 以及 MVITV two。
我们今天接下来至少还要讲到它另外两篇代表性的工作,那二座 Excel 是 Christopher 的老师,那他们跟最后的三座 AZ 也有很多的合作,那双流网络其实就出自于 AZ 之手,所以估计他们就想了想,那既然双流网络里是这么做 late Fusion 的,那我们要不要研究一下 early Fusion?于是乎就有了这篇论文。
2、 如何spatial fusion
那首先我们就来简单的看一下什么是这个 spatial Fusion。那作者在这里解释说,当你有这个时间流和空间流有两个网络之后,我们如何能保证这个时间流和空间流的这个特征图在同样的这个位置上,它们产生的这个通道 response 是差不多能联系起来的,因为这样才算是一个 early Fusion,就是在特征图层面还去做这种合并
那作者这里就做了几个简单的尝试:
- 比如说这里他说这个 Max Fusion,那对于 a 和 b 两个不同的这个特征图来说,在同样的这个位置上,我们只取它的这个最大值作为合并之后的这个值,这个就叫 Max Fusion。
- 那如果我们不想二选一,我们想尽可能地把这些信息都保留下来,我们也可以有很多别的方式。比如说最简单的就是这种 concatenation Fusion,直接把两个特征图合并起来就完了。
- 或者说我们也可以做一下这个cov fusion,就是先把这两个特征图堆叠起来,然后再对它做一层这个卷积操作。
- 当然更简单的,我们可以在这个两个特征图上对应的位置上直接做一个加法,
- 那最后最复杂的一种形式就是直接做一个这个biLinear Fusion,那就是说给定两个特征图之后,我们在这两个特征图上去做一个这个 outer product,做完所有乘积之后再在所有维度上做一次这个加权平均,那这种方法明显它的计算复杂度就比之前几种方法要高很多了。
而事实上我们最后也可以看到表现最好的其实就是 cov fusion 就可以了。
然后说完了 spatial Fusion,就是说在这个空间维度上我们已经知道如何处理这两个网络这个特征图了。
3、 在哪一层做fusion
那接下来的问题就是说我们到底应该在网络的哪个部分去做这个合并呢?到底是偏前面一些的层,比如说conv一、conv二还是偏后面一些的层?conv四、conv五,甚至是最后的这个分类层,这个 F C 6、 F C 7 。作者这里就做了大量的消重实验,最后作者就得出来了两种比较好的这个方式,它就列在这个图 2 里。
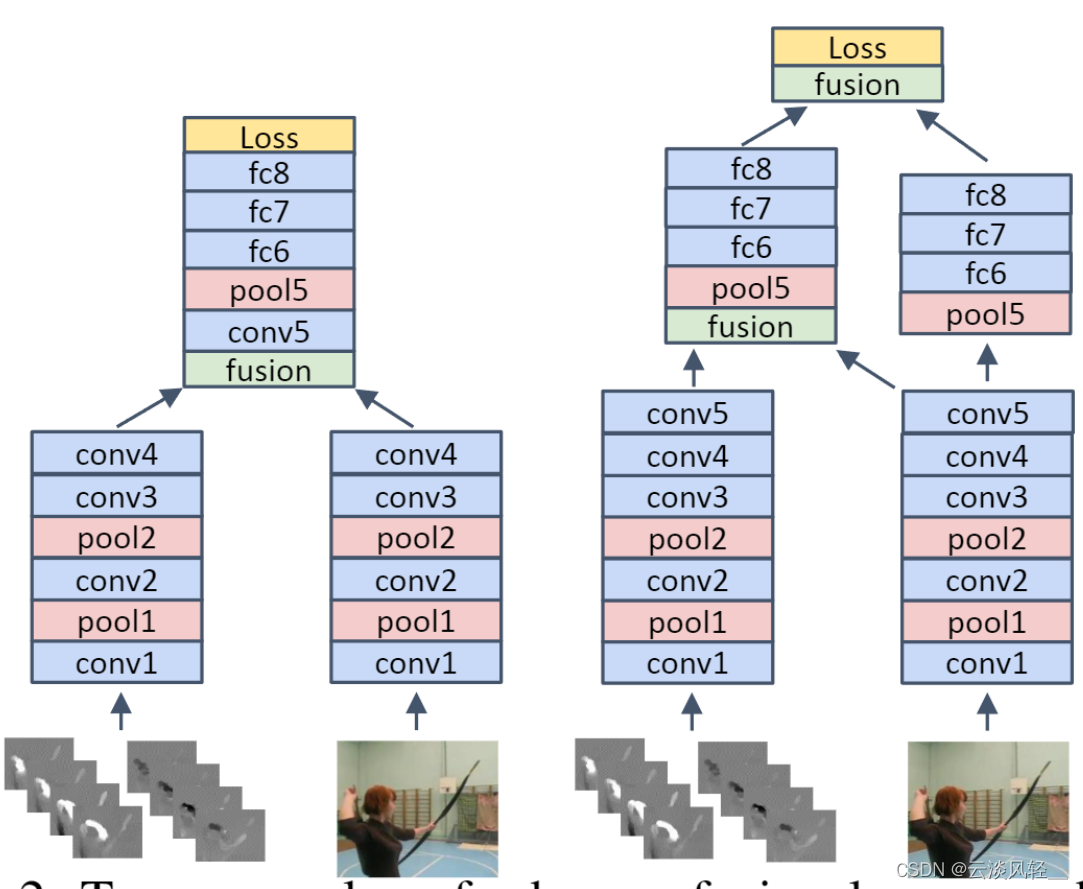
第一种就是空间流和这个时间流先分别做,然后在做完了 COnv 4 这层操作之后,把它们进行一次Fusion,然后 Fusion 完之后就从两个网络变成一个网络了,这其实也就是传统意义上的 early Fusion,就是在模型的中间就已经二合一了,所以最后的输出只有一个。
那另外一个表现更好的方式就是说我先这个两个网络分别做,然后再做到conv五这一层以后,我把空间流上的这个conv五的特征拿过来和这个时间流的特征做一次合并,然后这里出一个这个 special temporal 的特征,就它既有空间信息还又有时间信息,所以这个特征应该是比较好的。
但是我这个空间流也没有完全抛弃,我在它之后继续做这个pool 5、f c 6、f c 7、f c 8 就是保持了这个空间流的这个完整性,然后在最后的这个 FC 8 层我们再做一次合并。
这个可以简单地理解为就是说我们在之前的这个特征层,就是在还没有学到那么 high level 的这个语义特征之前,我们先合并一下去帮助这个时间流去进行学习。然后等到最后 FC 8 就是已经特别高的这个语义含义之后,我们再去做一次这个合并,也就是 late Fusion,从而得到最后的这个分类结果。
这两种方法效果都不错,那说完了 special Fusion,又说完了应该在哪儿做这种Fusion,
4、 如何temporal fusion
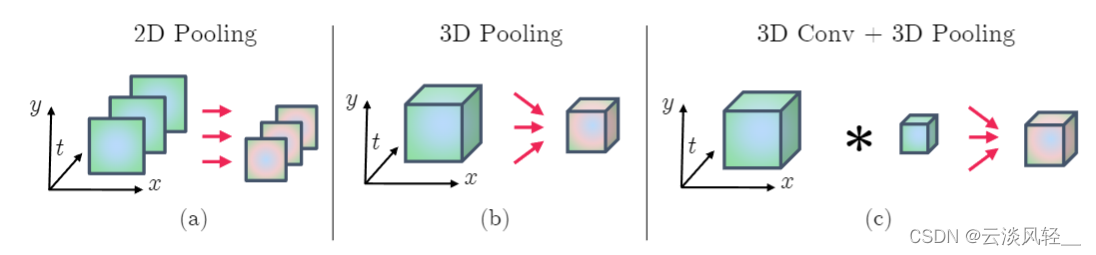
那最后就是讨论一下如何去做这种 temporal Fusion。就是说当你有很多这个视频帧,然后你每一帧都去抽了这个特征之后,我如何在这个时间轴这个维度上把它们合并起来,或者做一些交互去得到最后的特征。那作者在这篇论文里就尝试了两种方式,一种叫做 three d pulling,一种是先做一下 three d calm,再做一下 three d pulling。
5、分别回答完这三个问题之后,作者就提出了最后的总体框架
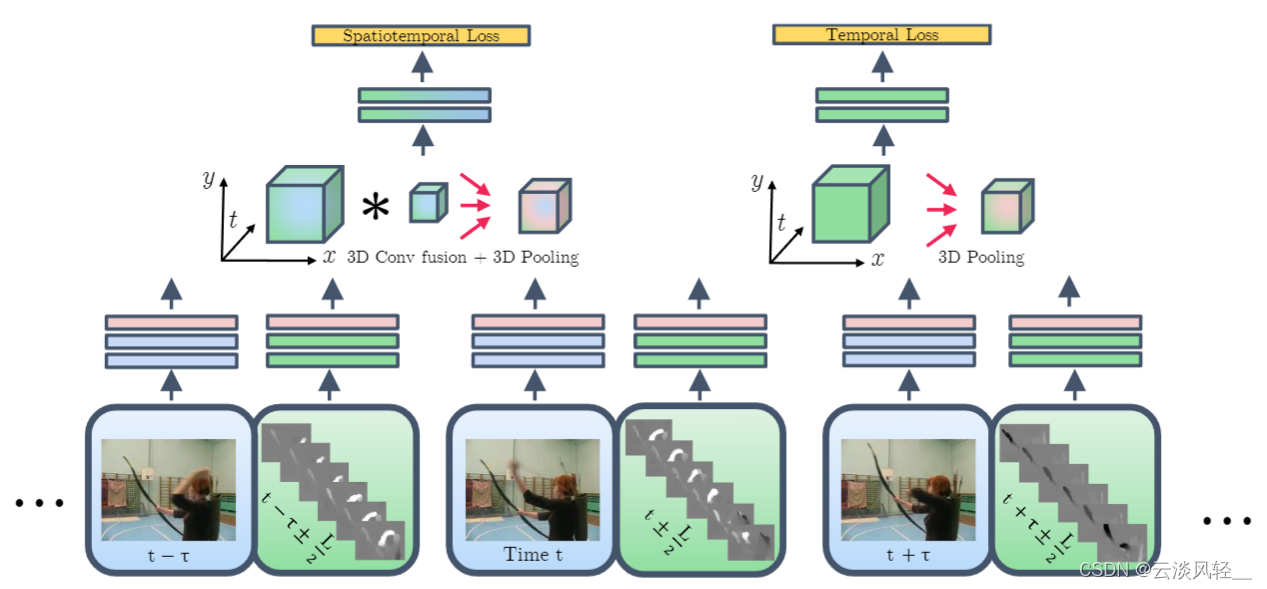 那在作者分别回答完这三个问题之后,作者就提出了最后的这个总体框架,那从最底下来看,这就是 RGB 的输入,这就是光流的输入,然后就是下一帧的 RGB 输入,下一帧的光流输入。总之蓝色就代表的是空间流,绿色就代表的是时间流。然后针对每个图像或者说光流图像,我先分别用这两个网络去抽它的特征,那一旦抽取好特征之后,我就按照刚才第二个问题里说的,我再conv 5 那一层,我就先对这个时间流和这个空间流做一次 early Fusion,那这里面因为同时牵扯到空间信息和时间信息,所以我们想让它交互的更好一些的。那这里面我们就采用了这种先做一个 3D covfusion,再做一个 3D pulling 的结构,然后在两个特征融合,而且pool完之后就可以把它变成一个 FC 层,最后出来一个结果,然后去算一个 spatiotempral temporal 的损失函数。
那在作者分别回答完这三个问题之后,作者就提出了最后的这个总体框架,那从最底下来看,这就是 RGB 的输入,这就是光流的输入,然后就是下一帧的 RGB 输入,下一帧的光流输入。总之蓝色就代表的是空间流,绿色就代表的是时间流。然后针对每个图像或者说光流图像,我先分别用这两个网络去抽它的特征,那一旦抽取好特征之后,我就按照刚才第二个问题里说的,我再conv 5 那一层,我就先对这个时间流和这个空间流做一次 early Fusion,那这里面因为同时牵扯到空间信息和时间信息,所以我们想让它交互的更好一些的。那这里面我们就采用了这种先做一个 3D covfusion,再做一个 3D pulling 的结构,然后在两个特征融合,而且pool完之后就可以把它变成一个 FC 层,最后出来一个结果,然后去算一个 spatiotempral temporal 的损失函数。
之所以是 spatiotempral,因为你这里时间和空间的信息都有,他学的是一个 spatiotempral的特征,
然后因为时间流特别关键,我们之前也知道做视频就是要在这个时间上做更多的处理,所以说作者这里又把时间流单独拿出来去做一次简单的铺令,然后再接 FC 层,最后专门做一个针对时间上的损失函数。
那这也就意味着我们这个模型是有两个分支的,一个是做这种时空学习 spatiotempral branch,还有一个是专门做这种时间学习一个 temporal 的branch,那在训练的时候也用了两个目标函数,也就是这里说的这个 special temporal loss 和这个 temporal loss,
6、模型怎么做推理的?
那这个模型在做推理的时候是怎么做推理的?那因为你这个网络现在有两个分支,这两个分支最后都会有一个分类头,那到底应该用哪个?其实在文章中就跟在图 2 里画的一样,或者说跟之前的双流网络一样,它也是做了一个 late Fusion,就是把这两个最后的这个分类结果加权平均一下,这是我们最后的预测结果了。
6、结果
那说完了文章的整体架构,那我们就直接来看一下最后的结果,那在表 5 里,作者就展示了一下他们的方法,在 USF 101 和 H M D B 51 上的结果。这里作者首先是尝试了一下使用这个更深的网络会带来多大的提升, 就把这个双流网络简单的自己复现了一下,但是他把空间流和时间流的这个网络 backbone 全都换成 VGG 16 了,那这个显然是比双流网络之前用的网络结构要深一些的,所以说它得到的效果也好一些。比如说在 UCF 上,它的这个提升非常大,从这个 88 直接就提升到 91. 7 了,但是在 H M B 51 这个数据集上,其实就是 59. 4 和 58. 7 是差不多的水平,还略微有所下降。
这个其实在我们马上要讲的这个 Tempo segment network,就 TSN 这篇论文里也有提到,就是说当一个数据集特别小,但是你要用特别深的网络去训练的时候,就容易遇到这种过拟合的问题,所以说不见得你用更深的网络就能得到更好的结果,但总之至少在 UCF 101 这个数据集上,就是当你有一万多个视频的时候可能就比较够了,这时候你能从 88 直接提升到 91. 7,这个提升还是非常明显的。
那如果我们从作者自己复现的这个 baseline 出发,然后把这个 late Fusion 换成 early Fusion 之后,我们可以看到其实提升也还好,就是从 91. 7 直接提升到了 92. 5,但是在 HMD 51 上它的提升就非常的明显了,直接从五十八点几就提升到 65. 4 了,这个效果还是非常厉害的。
所以说明这种 early Fusion 的方式可能算是一种变相的对网络的约束,让模型在早期的训练中就能从时间流和空间流这两肢网络中去互相学习,互相弥补,所以说在一定程度上可能弥补了这个数据不足的问题。所以说能够让 early Fusion 比 late Fusion 学习的效果要好很多。
7、贡献
当然了,这篇文章的意义和贡献远远不仅于就是说作者尝试一下 early Fusion 和 late Fusion 到底谁好。它主要的贡献在我看来其实有两点,第一点就是它做了大量的这个消融实验,从这个 special Fusion 到 temporal Fusion,到底应该在哪里去做 Fusion 彻底的把这个网络结构研究了一番,所以给后面的研究工作带来了很好的这个见解,能让大家少走很多弯路。
那第二个贡献就是他尝试了这种 3D CUB 和 3D Pulling,增加了研究者对于使用这种 3 d c nn 的信心变相地向推动了这个 3 d c nn的发展,所以在不到一年之后, I3D 就出来了,从此就开始了 3D CN n霸占视频理解领域的这个局面,所以说这篇论文的影响还是非常深远。
那我们刚才在回顾双流网络的时候,也提到了几个可以改进的方向,刚才已经说完了LSTM,而且也说完了 early Fusion。
2.3.3如何处理更长时间的这个视频问题——TSN
1、贡献
那最后就是该说一下如何处理更长时间的这个视频问题了。接下来要说的这篇论文叫做TSN Temporal Segment Networks: 'Towards Good Practices for Deep Action Recognition——
TSN temporal segment networks,是一篇 ECCVE 6 的终稿论文。这篇论文在视频理解领域里的贡献完全不逊色于双流网络或者说 I3D 网络这些里程碑式的工作,它不仅通过一种特别简单的方式能够处理比较长的视频,而且效果特别好。而且它更大的贡献是确定了很多很好用的技巧,也就是它写进题目里的这些towards, good practice for deep action recognition,就是所谓的这些 good practices 好用的技巧。
这些技巧包括怎么去做这种数据增强啊,怎么去做模型的初始化,到底该怎么使用光流?到底使用哪个网络?到底该如何防止过拟合?这篇论文全都给出了非常好的答案,它里面的很多技巧沿用至今,作者团队其实基本上都来自于 CUHK 一作王立民老师当时已经去了 ETH 读博士后。
(TDD 如何更好地利用光流)
上次我们讲双流网络的一个跟进工作,就是如何更好地利用光流,然后去做这种轨迹上的这种光流堆叠,就是王老师的工作,叫TDD。接下来王老师还有 on Trim d net Artnet, T E a V 4D,以及去年 SCV 的TM,还有 MG Samper 一系列工作。所以说做视频理解的同学不妨多去关注一下王老师组的工作,他应该都会有所收获。
2、研究动机
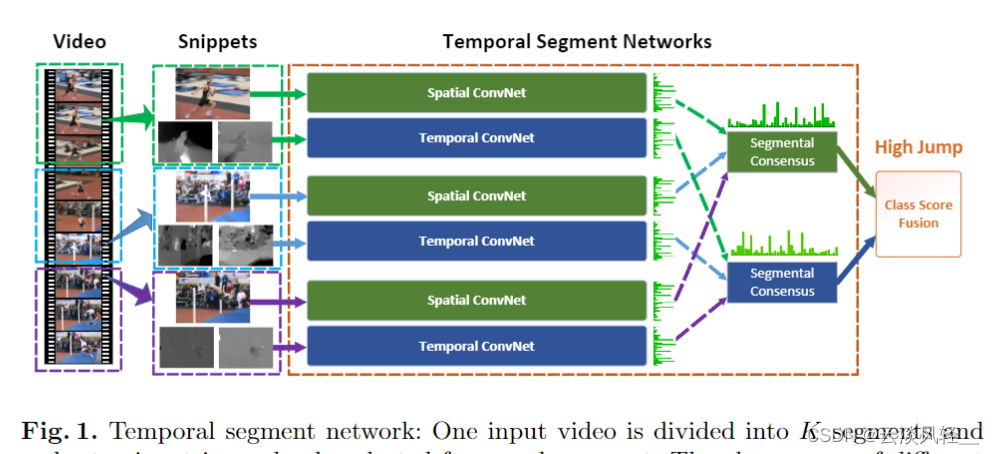
那 TSN 这篇论文到底讲的是什么意思?我们直接来看图一就可以了。这篇论文的研究动机就是说,如果你有一个原始的这个双流网络,你上面是一个视频帧,通过一个这个空间流,然后下面是几帧这个光流图像通过一个时间流,那你这个能覆盖的这个视频长度最多也就是 10 帧,也就是不到半秒的时间太短了,那我怎样才能去理解一个更长的一个完整的视频呢?
3、temporal segment的思想
那 TSN 这篇论文的想法就非常简单,那我把这个视频分成几段儿不就完了吗?
- 比如说我现在这个视频,我就把它切成三段儿,它这里出于这个画图简单,所以就分成了三段儿。
- 那我在每一段里去随机抽取一帧当做这个 RGB 图像,然后以这一帧为起点,再去选几帧,然后去算这个光流图像,
- 然后后面就按照这个双流网络的做法去做,最后就会出来两个Logis,
然后同样的道理,我再从第二段里去抽一帧,然后当做这个 RGB 图像,然后再去算一些光流,再通过一个双流网络。
当然这里所有的这个Spatial ConvNet全都是共享参数的,而这个 Temporal ConvNet也都是共享参数的。所以说其实你只有一组这个双流网络,然后再从这个第三道里做同样的操作,又会得到两个logics。
那 TSN 的想法就是说,如果你这个视频也不算太长,里面也就包含了一个事件或者一个动作的话,那即使抽出来的这些帧表面上看起来有些不一样,但它其实这个最高层的这个语义信息应该都描述的是一个东西。所以说我应该把这每一个段里,这个空间流出来的这个 Logis作为一个,这个 segmental consensus ,consensus 的意思就是达成共识,其实也就是做一下融合。这里面你也可以做加法,做乘法,做这个Max,也可以做 average 都可以,甚至你也可以用一个LSTM,总之就是去融合一下每个段出来的这个分类结果。
同样的道理,这个时间流出来的这个 Logis也要做一个这个 segmental consensus 也要达成一个共识,
那最后这个空间上的共识和这个时间上的共识做一个 late Fusion,一个加权平均就得到最后的这个预测了。
那举个简单的例子,如果我们现在做的是 UCF 101 这个数据集,也就是说一共有 101 个类的话,那其实这里的这个 Logis 其实就都是一乘以 101 的一个向量,那同样的道理,这里面的这个共识也是一个一乘 101 的向量。
我们可以看到 TSN 这个想法非常的简单,很多人可能觉得这太简单了,有可能神稿儿都不给过,但之前牧神在讲 Michael black 的那篇博文的时候,就是如何判断一个论文的新意度的时候。其实强调过简单不代表没有新意,反而如果你是一个既简单又工作得很好的方法,其实是最具有新意的。 TSN 这篇论文就完美的诠释了这个概念。而且这种给视频分段这种 Tempo segment 思想,不光是可以作用于这种短一点的视频,就是说这种已经裁剪好的 video clip 上,它也可以工作于就没有裁剪过的这种长视频上,也是可以的。因为即使你这个视频很长,我也可以把它打成更多的这个段落,而且每个段落里的含义也不一定需要一样。如果你不一样的话,那我后面这样就不做 average 就好了,我可以去做LSTM,去模拟这个时间的走势,也是可以的。
王老师之后另外一篇工作UntrimmedNets2017 其实就是用来去做这种没有裁剪过的长视频的视频分类任务,工作的也非常好。而且这篇论文做的是surprise,就是有监督的方式。 UntrimmedNets相当于是弱监督的方式。那其实 temporal segment 这个思想还可以作用于无监督的训练方式。
我们组去年的一个工作就是把 Tempo segment 思想融合到这个对比学习之中了。简单来说就是之前的工作往往是把一个视频里任意的两帧当做是正样的,把其他的所有帧都当做负样本。但这样的话,如果你这个视频比较长,你这个随机抽出来的两帧不一定是正样本,所以说我们就融合了 Tempo segment 思想。那在一个视频里,我们先把它分成段,从第一段、第二段、第三段里分别去抽出第一帧、第二帧、第三帧,我们把这三帧当作是第一个样本,然后我们再去这三个 segment 里任意的再去抽三针出来,那第二个抽出来的三针我们就当做是第二个样本,那第一个样本和第二个样本就可以理解成是一个正样本对。这样它成为正样本队的这个可能性就大很多,因为哪怕你这个视频很长,哪怕你每个 segment 里表示的这个语义都不一样,但是我的第一个样本也是从第一个 segment 到第二个 segment 到第三个segment,我第二个样本还是从第一个 segment 到第二个 segment 到第三个segment,它的基本走势是一样的,所以它俩成为正样本队的可能性是非常高的。
总之,别看 template segment 这个想法非常简单,但真的是非常的有效,我觉得它还能利用到更多的领域中去。
3、好用的技巧
另外我想简单提一下的就是文章题目里说的这些好用的技巧了,这个是在文章的这个 3. 2 节,也就是在这个网络训练部分,
cross modality Pre training
那他们使用的第一个技巧叫做这个 cross modality Pre training,它这里的 modelity 其实指的就是说图像和这个光流,因为图像和光流其实也算是挺不一样的输入了,所以也可以理解成是多模态。它这里的意思就是说你图像这边可以有 image net 这么大一个数据集去做这个预训练,所以你可以直接拿来做微调,效果应该不错。可是光流那边并没有一个很大的光流数据集去做这个预训练,那如果你只在这种小的视频数据集上从头训练的话,你光流的这个效果就可能不会太好。
那怎么样才能去做一个有效的预训练?作者这里就说,其实你把这个 Imagenet 预训练好的模型拿过来用给光流也是可以的,效果也非常好。
那但是这里问题就来了,你这个 Imagenet 预训练好的模型,你要接收的输入是 RGB 图像,而是 RGB 三个channel,而你这个光流的输入是 10 张光流图,每个光流图是两个channel,是 XY 上的分别的位移。所以说你一共有 20 个channel,那你这个预训练模型怎么把这个 3 个 channel 变成 20 个 channel 才能使用在光流上?
那作者这里其实就把这个网络的第一层,这是第一个卷积层的这个结构和参数改变了,它就把 Imagenet 那边预训练好的参数,刚开始的这个 RGB channel,就那三个 channel 的这个预训练好的参数先做了一下平均,那这样三个通道就变成一个通道了。然后你现在不是需要 20 个通道吗?那我直接就把这一个通道复制 20 遍就可以了。他们发现这种这个初始化的方式工作得非常好。后面我们也可以看到这个方式提了五六个点,提升是非常显著的,而事实上这种方式现在广泛被使用,那接下来的 I3D 它其实也就是这么去做inflation。
模型正则化的技巧
那第二个技巧就是作者这里谈到的这个模型正则化的技巧。那一上来作者就说 BN 怎么着了?那其实我们也讲过很多次,BN这个层真的是让人又爱又恨,用得好效果提升很好,用得不好就会问各种问题。
那在初期的视频理解领域,用 b n 就有一些困难,因为数据集太小,所以说虽然 BN 能够让这个训练加速,但是同样也带来了很严重的这个过拟合的问题,那怎么办?作者这里就提出了一个叫 partial BN 的做法,它本来的这个动机是说如果你这个 BN 层是可以微调的话,那因为数据集比较小,所以一调就会过拟合。我其实不想调你,我想把你全冻起来是最好的,不要动了。
但是如果你把所有的这个 BN 层全都冻住的话,你可能这个迁移学习的效果就不太好了,毕竟你之前那个数据集是图像数据集,而且跟这个视频数据集和这个视频动作分类差的还是比较远的,那之前 b n 估计出来的那些统计量可能就不太适用于这个动作识别,那怎么办?所以说作者提出的这个 partial b n 的意思就是说我们就把第一层的这个 BN 打开,后面的 BN 我们就全都冻住,也就它这里说的 freeze the mean and variance of all the BN layers except the first one。那这个意思就是说因为你的输入变了,所以说我第一层这个 BN 没办法,我必须也得学一学,这样我才能适应你这个新的输入,适应你这个新的数据集。但是除了这个输入层,再往后我就不想动了,因为如果再动就有这个过拟合的风险了。这个技巧后来也被广泛使用,虽然说现在视频里的数据集都变得很大了,可能暂时是不需要这种 partial BN 了,但是在微调的时候,或者在很多下游任务上还是会有很多情况,你需要使用 partial b n 的,一般工作的都不错。
2个数据增强
第三个好用的技巧就是数据增强了,因为为了防止过拟合,数据增强是一个必不可少的工具,那作者这里就提出了两个东西,一个叫 corner cropping,一个叫 scale gittering corner cropping 其实就是作者在训练的过程中发现,如果你去做这种 random cropping,这个 random Trello crop 经常就是在这个图像的正中间或者在中间附近,它很难去 corrupt 到这个图像的这种边边角角的地方。所以在这篇论文里,它就强制性地就在那些边角的地方去做裁剪。就像 Imagenet 之前做这个测试的时候,有的人用 one crop,有的人用 five crop, ten crop,那个 five crop 其实就是在左上、右上、左下、右下和中间选 5 个这个裁剪的位置。这里面作者就是把之前大家去做推理做测试的一个方法用到训练中来了,当成了一个数据增强的方式。
那第二个提出的数据增强方式,也就它这里说的这个 scale gitering,就是想通过改变图片的这个长宽比,去增加这个输入图片的多样性。作者这里的实现方式很高效,它就是先把这些视频帧全都这个 resize 到 256 乘340,然后它在这个图片上就学各种各样的做裁剪,但是它做裁剪的这个长宽都是从这个列表里去选的,意思就是说有些裁剪出来的图,比如说就是 256 乘192,有些就是 24 乘168,当然也有可能是 24 乘24,反正就是随机排列组合去,那这样图片的长宽比就变得非常多样性了,从而能提供更多的训练数据减少这种过拟合。
这两种数据增强的方式其实一直到现在还有很多论文也在使用,因为确实比较有效。
总之除了这几点好用的技巧之外, TSN 这篇论文里还有很多宝藏技巧,所以这也就是为什么作者把 good practice 都放到这个论文题目里了,因为真的是这篇论文最出彩的地方之一。那很多的消融实验我们就暂且跳过不看了,他提出这些技巧都非常有用,提点其实都很显著的。
4、效果
我们直接来看最后这个大表,来看一看 TSN 的效果跟之前的方法比到底有多好。
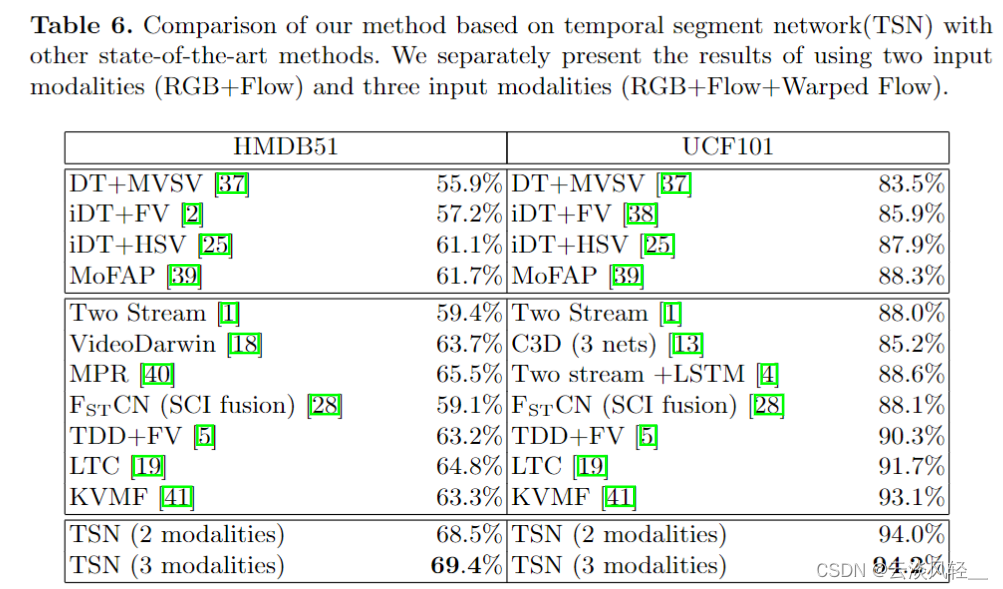 那作者在这里把之前手工特征的方式列到了这个表的上面,然后底下这片全都是用深度学习来做的,里面有一些我们其实已经讲过了,
那作者在这里把之前手工特征的方式列到了这个表的上面,然后底下这片全都是用深度学习来做的,里面有一些我们其实已经讲过了,
- 比如说这个Two Stream双流网络 59. 4 和 UCF 上 88 的这个准确度,
- 这个 video darwin 是用 ranking function 做的。这篇论文也非常有意思,只不过没有什么后续工作了。
- 然后像 C3D 其实就是 3D cnn 那边的一个早期的工作,很快就会在下一个部分就讲到,
但是我们也可以看到,这些早期的工作(C3D)即使用了三个卷积神经网络,它最后的结果也才 85. 2,既不能跟这种传统的手工特征比,也没法跟双流网络的这个性能去比,直到 I3D 的出现才改变了这种现状。
- 然后 tool stream 加LSTM,也就我们刚刚讲过的那个 beyond short snippet 那篇论文,但是提升了也不是很多,就是从 88 涨到了 88. 6,
- 然后 TDD 这篇论文就是王老师自己的工作,就是那篇把光流简单的堆叠变成利用轨迹去堆叠的方式,这个提升还是比较明显的,从 88 就到 90 了。
最后我们来看一下TSN, TSN 这里我们就看两个modalities就可以了,就是 RGB 和光流。至于三个 modelity 是因为他们用了另外一种这个光流的形式,这里我们就不细说了。这里我们看到就用两个modelity,这个 TSN 它在 HMDB 上就有 68. 5,比之前的方法都高。 UCF 上也有94,比之前的方法也是提升了不少。那 TSN 其实已经是把双流网络做得非常好了。
(DVOF和TLE 给TSN加入全局编码)
- 接下来还有一些后续工作,比如说我和蓝振忠就有一篇叫 DVOF 的论文,就是在 TSN 的基础上加加入了全局编码,比如说 facial Vector encoding 或者 VLAD encoding 这些编码方式,从而获得了更加全局的特征,然后在 UCF 101 上的效果也推到了 95 点多。
- 然后接下来在 CVPR 一期还有另外一篇论文叫TLE,也是用了非常类似的思想,只不过我们的不是端到端的,他们又把这个做成端到端了,而 TLE 的结果在 UCF 101 和 HMD V51 上也是非常的高, UCF 101 基本上已经到了将近 96 了
也就是在 2017 年I3D 这篇论文也出来了,所以说至此双流网络基本也就慢慢的淡出舞台了。而且因为有了 Kinetics 这个数据集,所以说 UCF 101 和 HMDB 51 也基本慢慢的淡出这个舞台了,所以说 TSN 是视频理解领域里不得不读的一片里程碑式的工作,不论你是做分类还是做动作检测,还是做其他任何的这个视频理解的任务,都不要错过TSN
总结
那在这个视频串讲的前半部分,我们主要就是在第一部分里讲了 deep video 这个工作,然后就是在第二部分里讲了这个双流网络以及双流网络的一些变体。
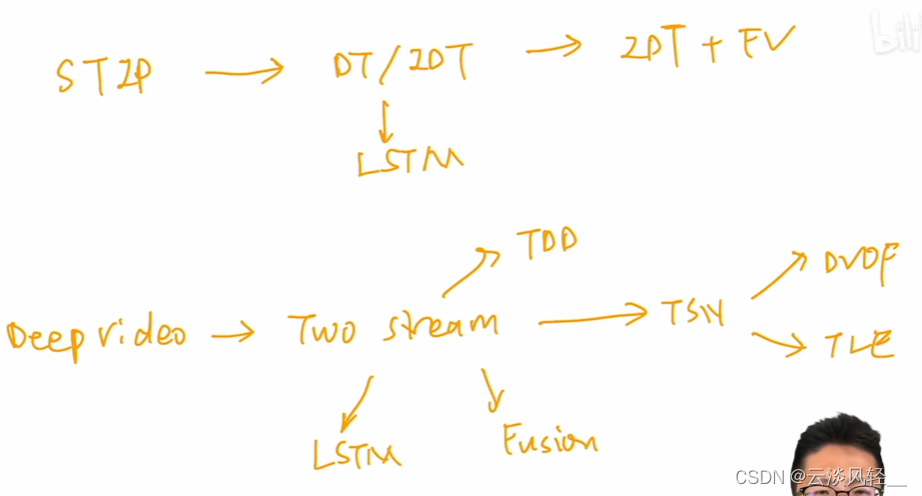
那具体的这个发展历程我们可以再过一遍。
首先就是在 2012 年有了 x net 之后,大家就想把这个卷积神经网络用到视觉的方方面面,所以说就有了这篇 CIPR14 的论文。 deep video 基本就是把卷积神经网络迁移到了视频理解这边,不过它的效果比较一般,经过一番研究,大家发现这个视频理解可能还是需要对时间或者对这个运动讯息有一些更好的了解。
所以说紧接着一个非常庞大的分支就出来了,就是这个双流网络,就是在你原来有一支网络的基础上,又加了一支时间流网络,这个时间流网络的输入是光流图像,这样的话,网络本身就不需要再去从原始的那个视频里去学习运动信息了,这些运动信息可以直接从光流而得到。所以说大大地简化了这个问题,而且效果也变得非常好。终于能跟手工的特征打成平手了。
那自从打成平手以后,后续的工作就越来越多了,比如说怎么去更好地利用光流,通过这种沿着轨迹去堆叠光流的方式,就有了 CVPR 15 的这篇 TDD 论文,
然后如何对这种时序进行更好的建模。所以大家自然而然的就想到了使用LSTM,也就是后来 C V P R E 5 的这个 beyond 说了 snippet 这篇论文,
然后因为双流网络它本身做的是一个 late Fusion,就是在网络最后把这个输出直接加权平均了一下。大家就想那如果你做 early Fusion 效果会不会更好?所以说在 CVPR 16 的时候就有了这篇 early Fusion 的论文。
最后为了加强对这种长视频的理解,在 ECCV16 就有了 TSN 这篇论文, TSN 就是把一个长视频打成很多的分段,然后每一分段都去算一个结果,然后把这些结果求一个共识,最后得到一个更稳健的输出。
接下来在 TSN 的基础上, RCVPR 一期就有两篇工作,想法都是把这种全局编码加到这个 TSN 里面,既学到一个更加全局的一个 video level 的特征。
DVOF 不是端到端的,而 TL e 是端到端的。
这个大概就是从 14 年到 17 年这个视频理解领域在双流这个方向上的一些发展。这个结果如果拿 UCF 101 来举例的话,也就是从 deep video 的 65 到 to stream 的这个88,然后到 TSN 的是94,一直到 TLE 的这个96,基本上就是把 UCF 101 刷爆了。
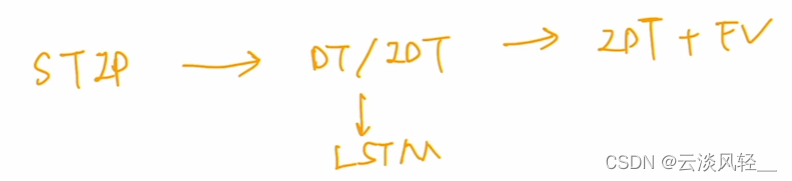
那我上面画的这张图其实都是一些传统的手工特征来做这个视频动作分类的,我之所以画这张图,其实是想对比一下传统的手工特征的发展历程和这个用深度学习做动作识别的发展历程。
其实我们可以看出来它的这个发展历程是非常相像。
手工特征那边儿是在图像方面, 2004 年先有了 STIP 的这个feature,然后就延伸到了视频领域,所以就有了这个 SIP 这个 feature special temporal interest point,那就跟 2012 年有了 Alex net,然后把它拓展到 deep video 一样。
紧接着因为这个视频需要更多的这个时序信息,所以手工特征就把光流加进来,而且把轨迹也加进来,就推出了这个 dance trajectory 和 improved dance trajectory 这两个工作,其实也就对应了这边的 toolstream 和 TDD 这两个工作,
然后你这抽出来的都是特征,所以说如果你想做更长时间的这种视频处理,或者你想对这个时序进行建模的话,那你都可以用LSTM。所以说手工特征那边也会先抽出特征,然后再用LSTM,然后深度学习这边也一样,就是在一个卷积神经网络之后,再加上这个LSTM,
那最后就是为了处理这种长视频,或者为了得到这种全局的信息,那手工特征那边也会把 IDT 这个特征跟这个 feature vacting coding 去做一个融合,从而去得到一个这种全局的 video level 的特征。那深度学习这边也就是把 feature back encoding 做到了整个这个框架之内,对应的其实就是 TSN DVOF TLE 这一系列工作,
所以我们可以看到其实不论这个工具怎么在改变,这个发展历程其实都是相似的。那在下一期我们会接着讲 3D 网络和 video Transformer,到时候我们可以再看一下这个 2D 网络、 3D 网络、双流网络、 video Transformer 所有的这些概念到底有哪些区别和联系。