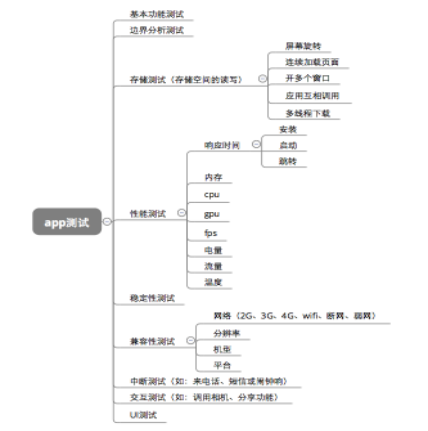
内容仅供学习参考,如有侵权联系删除
先通过京东非自营的店铺名拿到的公司名,再通过公司名称去其他平台拿到联系方式(代码省略)
from aioscrapy.spiders import Spider
from aioscrapy.http import Request, FormRequest
import ddddocr
import re
import random
from loguru import logger
class JingDongSpider(Spider):
name = 'products:jd'
custom_settings = {
'CONCURRENT_REQUESTS': 4,
# 'DOWNLOAD_DELAY': 0.5,
'DOWNLOAD_TIMEOUT': 10,
'RETRY_TIMES': 5,
'HTTPERROR_ALLOWED_CODES': [503],
'COOKIES_ENABLED': False,
'DUPEFILTER_CLASS': 'aioscrapy.dupefilters.redis.RFPDupeFilter', # 过滤方法
# 'LOG_LEVEL': 'DEBUG'
}
ocr = ddddocr.DdddOcr(show_ad=False, use_gpu=True)
async def start_requests(self):
yield Request(
url=f"https://mall.jd.com/index-11111111.html?from=pc",
method='GET',
dont_filter=False,
# fingerprint=str(i),
# meta={"shop_id": str(i)},
priority=500)
async def parse(self, response):
"""店铺首页"""
title = response.xpath('//title/text()').get() or ''
shop_id = str(response.meta['shop_id'])
if '您所访问的页面不存在' in str(title) or len(response.text) < 25000:
logger.info(f"{shop_id}")
return
logger.info(title.strip())
product_list = self.get_product_items(response)
urls = re.findall(r"//\w+\.jd\.com/view_search-\d+-\d+-\d+-\d+-\d+-\d+\.html", response.text)
yield Request(
url=f"https://mall.jd.com/sys/vc/createVerifyCode.html?random={random.random()}",
method='GET',
callback=self.parse_img_code,
dont_filter=True,
meta={
"data": {"product_url": 'https:' + urls[0] if urls else '',
"categorys": self.get_category(response),
"product_list": product_list,
# "shop_url": response.url,
"shop_id": shop_id}
},
priority=500)
async def parse_img_code(self, response):
"""验证码"""
code = self.ocr.classification(response.body)
cookie = dict(response.cookies.items())
shop_id = response.meta["data"]["shop_id"]
if not code or not cookie:
return
yield FormRequest(
url=f'https://mall.jd.com/showLicence-{shop_id}.html',
method='POST',
formdata={"verifyCode": str(code)},
cookies=cookie,
meta={"data": response.meta["data"]},
callback=self.parse_shop_detail,
dont_filter=True,
priority=400)
async def parse_shop_detail(self, response):
""" 解析店铺详情
"""
company = response.xpath(
'//*[contains(.,"企业名称:")]/following-sibling::span[position()=1]/text()').get() or ''
shop_name = response.xpath(
'//*[contains(.,"店铺名称:")]/following-sibling::span[position()=1]//text()').get() or ''
shop_url = response.xpath('//*[contains(.,"店铺网址:")]/following-sibling::span[position()=1]//text()').get()
# legal_person = response.xpath( '//*[contains(.,"法定代表人姓名:")]/following-sibling::span[position()=1]//text()').get()
# business_scope = response.xpath( '//*[contains(.,"营业执照经营范围:")]/following-sibling::span[position()=1]//text()').get()
license = response.xpath('//img[@class="qualification-img"]/@src').get() or ''
if not company or '测试' in shop_name or '测试' in company:
if not company:
logger.info(f"无公司: {response.url}")
else:
logger.info(f" {shop_name} => {company}")
return
else:
logger.info(company)
data = response.meta['data']
data['company'] = company
data['shop_name'] = shop_name
items = dict(company=company,
shop_name=shop_name,
shop_url='https:' + shop_url if shop_url else response.url,
product_url=data['product_url'],
shop_id=data['shop_id'],
push_kafka_status=0,
license='https:' + license if license else '',
)
if len(data['product_list']) < 1:
if data['product_url']:
yield Request(
url=data['product_url'],
method='GET',
meta={"data": data},
callback=self.parse_product,
dont_filter=True,
priority=300)
else:
logger.warning(f"获取不到产品链接:{response.url}")
items.pop('product_url')
yield items
else:
product_list = []
for item in data['product_list']:
item['entityId'] = company
product_list.append(item)
yield dict(
source='jd.com',
ocid='',
entityId=company,
product=product_list,
)
items['push_kafka_status'] = 1
yield items
async def parse_product(self, response):
"""解析产品页"""
data = response.meta['data']
shop_name = data['shop_name']
company = data['company']
categorys = data['categorys']
product_list = self.get_product_items(response, shop_name, company, categorys, data['product_url'])
if product_list:
yield dict(
source='jd.com',
ocid='',
entityId=company,
product=product_list,
)
logger.info(f"成功: {company} => {data['shop_id']}")
yield dict(
company=company,
shop_id=data['shop_id'],
push_kafka_status=1,
)
else:
logger.error(f"{response.url} => {data['shop_id']}")
def get_product_items(self, response, shop_name='', company='', categorys='', shop_url='') -> list:
ul = response.xpath('//li[@class="jSubObject"] | //li[@class="jSubObject gl-item"] | //div[@class="jItem"]')
product_list = []
for li in ul[:10]:
title = li.xpath('.//div[@class="jDesc"]/a/@title').get() or ''
# price = li.xpath('.//span[@class="jdNum"]/text()').get()
img = str(li.xpath('.//div[@class="jPic"]//img/@src').get() or '').replace('s350x350', '')
if not title and not img:
continue
if img:
img = re.sub(r"/n[23456789]/", "/n1/", img)
img = 'https:' + img
item_i = {}
item_i["entityId"] = company
item_i["productPic"] = img.replace('s350x350', '')
item_i["productName"] = title # 产品名称
item_i["productCategory"] = "" # 产品分类
item_i["productKeyword"] = "" # 产品关键词
item_i["productPrice"] = "" # 产品价格
item_i["mainProducts"] = categorys # 主营产品
item_i["listingPlatform"] = "京东"
item_i["productShopName"] = shop_name # 产品所属店铺名
item_i["dataLink"] = shop_url or response.url # 店铺链接
product_list.append(item_i)
return product_list
@staticmethod
def get_category(response) -> str:
categorys = response.xpath(
'//ul[@class="menu-list"]/li[@class="menu"]/a/text() | //div[@class="abs"]//div[@class="ins abs hdur_2"]/a/text()').getall()
category = []
for i in categorys:
if '首页' in i or '全部' in i or '所有' in i or '问题' in i or '指导' in i or '售后' in i or '撰文' in i:
continue
category.append(i)
return ','.join(category)
if __name__ == '__main__':
JingDongSpider.start()
最后的数据

本内容仅限用于学习参考,不得用于商业目的。如有版权问题,请联系我们删除,谢谢!
欢迎一起学习讨论Q540513871