文章目录
- 引言
- 一、基本概念
- 1.1 总体
- 1.2 样本
- 1.3 统计量
- 1.4 顺序统计量
- 写在最后
引言
以前学概率论的时候,不知道后面的数理统计是什么,所以简称都把后面的省略掉了。现在接触的学科知识多了,慢慢就对数理统计有了直观印象。
尤其是第一次参加数模比赛的时候,各种统计方法,不知如何下手。不过利用像 Spss 这样的软件,只要把数据导进来,点点就能实现复杂统计处理。但是我还是心里发虚,因为不知道如何解释这些软件统计出来的结果。看着出来的各种 p 值,Sig. 等等,只会照猫画虎学网上说怎么怎么样。
扯远了,不过对这一章我还是很有学习欲望的,希望能顺利掌握考试所需要的知识点,同时也为以后打下一个统计学基础。
一、基本概念
1.1 总体
我们经常需要研究某类特定对象的某一特征,如全国的粮食产量、青少年的身高、体重等指标。所研究对象的某项指标的全体称为总体,记为 X X X ,其中构成总体的每个元素称为个体。
从本质上来说,总体即一个随机变量。
1.2 样本
对于总体数量太多,如全国商品的价格波动、某个企业生产的所有照明灯的寿命,对每个个体进行研究会花费大量人力物力,所以我们往往只研究一定数量的具有代表性的个体的特征,来大致反映总体的特征。
从总体中随机抽取若干个个体构成的几何,称为总体的一个样本。
设总体为 X X X ,从总体 X X X 中取出含 n n n 个个体的样本( X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn), n n n 称为样本的容量,若样本( X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn)满足:
- X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn相互独立;
- 样本 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn 中每个个体与总体 X X X 分布相同,
称( X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn)为来自总体 X X X 的简单随机样本。设 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn 为样本的一组抽样取值,称其为样本( X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn)的一组观察值。
1.3 统计量
设 X X X 为总体,( X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn)为来自总体 X X X 的简单随机样本,以样本( X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn)为变量所构造的不含任何参数的函数称为统计量。其本质是随机变量。
如 ( X 1 + X 2 ) / 2 , X 1 2 + X 2 2 + X 3 2 (X_1+X_2)/2,X_1^2+X_2^2+X_3^2 (X1+X2)/2,X12+X22+X32 等等都不含参数,故都是统计量;以下为一些常见的统计量:
- 样本均值 X ‾ = 1 n ∑ i = 1 n X i ; \overline{X}=\frac{1}{n}\sum_{i=1}^nX_i; X=n1i=1∑nXi;
- 样本的 k ( k = 1 , 2 , ⋯ ) k(k=1,2,\cdots) k(k=1,2,⋯) 阶原点矩 A k = 1 n ∑ i = 1 n X i k ; A_k=\frac{1}{n}\sum_{i=1}^nX_i^k; Ak=n1i=1∑nXik;
- 样本的 k ( k = 1 , 2 , ⋯ ) k(k=1,2,\cdots) k(k=1,2,⋯) 阶中心矩 B k = 1 n ∑ i = 1 n ( X i − X ‾ ) k ; B_k=\frac{1}{n}\sum_{i=1}^n(X_i-\overline{X})^k; Bk=n1i=1∑n(Xi−X)k;
- 样本方差 S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 = 1 n − 1 B 2 , S^2=\frac{1}{n-1}\sum_{i=1}^n(X_i-\overline{X})^2=\frac{1}{n-1}B_2, S2=n−11i=1∑n(Xi−X)2=n−11B2, 其中 S S S 称为样本均方差。
设 X X X 为总体,且 ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) (X1,X2,⋯,Xn) 为来自总体 X X X 的简单随机样本,且 E ( X ) = μ , D ( X ) = σ 2 E(X)=\mu,D(X)=\sigma^2 E(X)=μ,D(X)=σ2 ,则 E ( X ‾ ) = μ , D ( X ‾ ) = σ 2 n , E ( S 2 ) = σ 2 . E(\overline{X})=\mu,D(\overline{X})=\frac{\sigma^2}{n},E(S^2)=\sigma^2. E(X)=μ,D(X)=nσ2,E(S2)=σ2. 咱可以简单证明一下。
对 E ( X ‾ ) = μ E(\overline{X})=\mu E(X)=μ ,即样本均值的期望为总体的期望,证明如下: E ( X ‾ ) = 1 n ∑ i = 1 n E ( X i ) = n μ n = μ . E(\overline{X})=\frac{1}{n}\sum_{i=1}^nE(X_i)=\frac{n\mu}{n}=\mu. E(X)=n1i=1∑nE(Xi)=nnμ=μ. 主要是利用了独立变量 E ( X 1 + X 2 + ⋯ + X n ) = E ( X 1 ) + ⋯ + E ( X n ) E(X_1+X_2+\cdots+X_n)=E(X_1)+\cdots+E(X_n) E(X1+X2+⋯+Xn)=E(X1)+⋯+E(Xn) 。
对 D ( X ‾ ) = σ 2 n D(\overline{X})=\frac{\sigma^2}{n} D(X)=nσ2 ,即样本均值的方差为总体方差的均值,证明如下: D ( X ‾ ) = D ( 1 n ( X 1 + X 2 + ⋯ + X n ) ) = 1 n 2 ∑ i = 1 n D ( X i ) = n σ 2 n 2 = σ 2 n . D(\overline{X})=D(\frac{1}{n}(X_1+X_2+\cdots+X_n))=\frac{1}{n^2}\sum_{i=1}^nD(X_i)=\frac{n\sigma^2}{n^2}=\frac{\sigma^2}{n}. D(X)=D(n1(X1+X2+⋯+Xn))=n21i=1∑nD(Xi)=n2nσ2=nσ2. 同样也只是利用独立变量方差加和的性质。
对 E ( S 2 ) = σ 2 E(S^2)=\sigma^2 E(S2)=σ2 ,即样本方差的期望为总体的方差,证明如下:
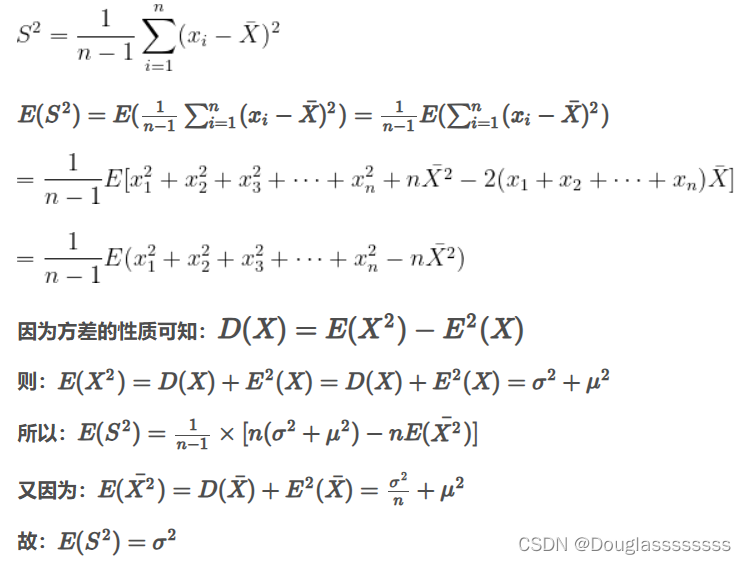
1.4 顺序统计量
设 X X X 为总体,且 ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) (X1,X2,⋯,Xn) 为来自总体 X X X 的简单随机样本,将 ( X 1 , X 2 , ⋯ , X n ) (X_1,X_2,\cdots,X_n) (X1,X2,⋯,Xn) 按照样本观察值大小进行排序,称为顺序统计量。
称 min ( X 1 , X 2 , ⋯ , X n ) \min{(X_1,X_2,\cdots,X_n)} min(X1,X2,⋯,Xn) 为最小统计量, max ( X 1 , X 2 , ⋯ , X n ) \max{(X_1,X_2,\cdots,X_n)} max(X1,X2,⋯,Xn) 为最大顺序统计量。
写在最后
基本概念就到这里,下一篇我们来看看三个重要的抽样分布。