作者:贺弘 谦言 临在
导言
图像分割(Image Segmentation)是指对图片进行像素级的分类,根据分类粒度的不同可以分为语义分割(Semantic Segmentation)、实例分割(Instance Segmentation)、全景分割(Panoptic Segmentation)三类。图像分割是计算机视觉中的主要研究方向之一,在医学图像分析、自动驾驶、视频监控、增强现实、图像压缩等领域有重要的应用价值。我们在EasyCV框架中对这三类分割SOTA算法进行了集成,并提供了相关模型权重。通过EasyCV可以轻松预测图像的分割谱以及训练定制化的分割模型。本文主要介绍如何使用EasyCV实现实例分割、全景分割和语义分割,及相关算法思想。
使用EasyCV预测分割图
EasyCV提供了在coco数据集上训练的实例分割模型和全景分割模型以及在ADE20K上训练的语义分割模型,参考EasyCV quick start(https://github.com/alibaba/EasyCV/blob/master/docs/source/quick_start.md)完成依赖环境的配置后,可以直接使用这些模型完成对图像的分割谱预测,相关模型链接在reference中给出。
实例分割预测
由于该示例中的mask2fromer算法使用了Deformable attention (在DETR系列算法中使用该算子可以有效提升算法收敛速度和计算效率),需要额外对该算子进行编译
cd thirdparty/deformable_attention
python setup.py build install
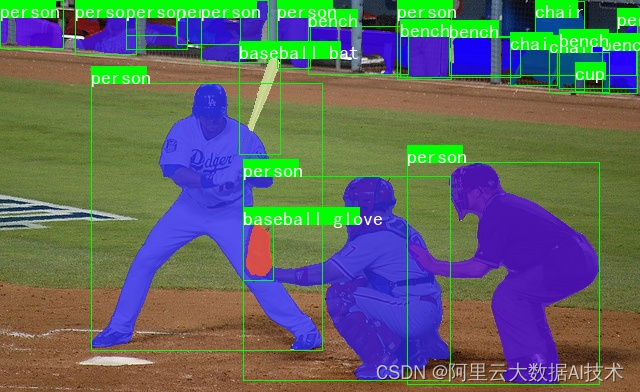
通过Mask2formerPredictor预测图像实例分割图
import cv2
from easycv.predictors.segmentation import Mask2formerPredictor
predictor = Mask2formerPredictor(model_path='mask2former_instance_export.pth',task_mode='instance')
img = cv2.imread('000000123213.jpg')
predict_out = predictor(['000000123213.jpg'])
instance_img = predictor.show_instance(img, **predict_out[0])
cv2.imwrite('instance_out.jpg',instance_img)
输出结果如下图:

全景分割预测
通过Mask2formerPredictor预测图像全景分割图
import cv2
from easycv.predictors.segmentation import Mask2formerPredictor
predictor = Mask2formerPredictor(model_path='mask2former_pan_export.pth',task_mode='panoptic')
img = cv2.imread('000000123213.jpg')
predict_out = predictor(['000000123213.jpg'])
pan_img = predictor.show_panoptic(img, **predict_out[0])
cv2.imwrite('pan_out.jpg',pan_img)
输出结果如下图:


语义分割预测
通过Mask2formerPredictor预测图像语义分割图
import cv2
from easycv.predictors.segmentation import Mask2formerPredictor
predictor = Mask2formerPredictor(model_path='mask2former_semantic_export.pth',task_mode='semantic')
img = cv2.imread('000000123213.jpg')
predict_out = predictor(['000000123213.jpg'])
semantic_img = predictor.show_panoptic(img, **predict_out[0])
cv2.imwrite('semantic_out.jpg',semantic_img)


示例图片来源:cocodataset
在阿里云机器学习平台PAI上使用Mask2Former模型
PAI-DSW(Data Science Workshop)是阿里云机器学习平台PAI开发的云上IDE,面向各类开发者,提供了交互式的编程环境。在DSW Gallery中(链接),提供了各种Notebook示例,方便用户轻松上手DSW,搭建各种机器学习应用。我们也在DSW Gallery中上架了Mask2Former进行图像分割的Sample Notebook(见下图),欢迎大家体验!

Mask2Former算法解读
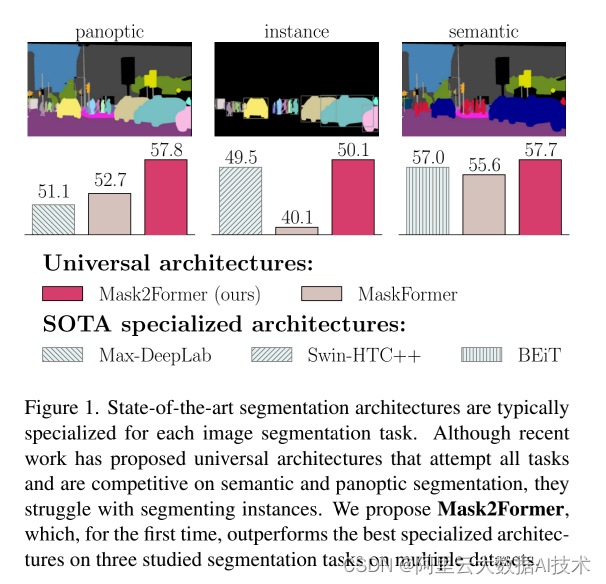
上述例子中采用的模型是基于Mask2former实现的,Mask2former是一个统一的分割架构,能够同时进行语义分割、实例分割以及全景分割,并且取得SOTA的结果,在COCO数据集上全景分割精度57.8 PQ,实例分割精度达50.1 AP,在ADE20K数据集上语义分割精度达57.7 mIoU。
核心思想
Mask2Former采用mask classification的形式来进行分割,即通过模型去预测一组二值mask再组合成最终的分割图。每个二值mask可以代表类别或实例,就可以实现语义分割、实例分割等不同的分割任务。
在mask classsification任务中,一个比较核心的问题是如何去找到一个好的形式学习二值Mask。如先前的工作 Mask R-CNN通过bounding boxes来限制特征区域,在区域内预测各自的分割谱。这种方式也导致Mask R-CNN只能进行实例分割。Mask2Former参考DETR的方式,通过一组固定数量的特征向量(object query)去表示二值Mask,通过Transformer Decoder进行解码去预测这一组Mask。(ps:关于DETR的解读可以参考:基于EasyCV复现DETR和DAB-DETR,Object Query的正确打开方式)
在DETR系列的算法中,有一个比较重要的缺陷是在Transformer Decoder中的cross attention中会对全局的特征进行处理,导致模型很难关注到真正想要关注的区域,会降低模型的收敛速度和最终的算法精度。对于这个问题Mask2former提出了Transformer Decoder with mask attention,每个Transformer Decoder block 会去预测一个attention mask并以0.5为阈值进行二值化,然后将这个attentino mask作为下一个block的输入,让attention模块计算时只关注在mask的前景部分。
模型结构
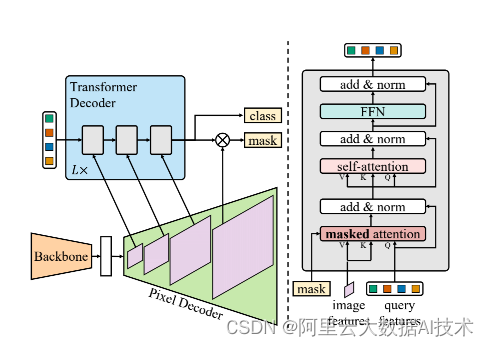
Mask2Former由三个部分组成:
- Backbone(ResNet、Swin Transformer)从图片中抽取低分辨率特征
- Pixel Decoder 从低分辩率特征中逐步进行上采样解码,获得从低分辨率到高分辨率的特征金字塔,循环的作为Transformer Decoder中V、K的输入。通过多尺度的特征来保证模型对不同尺度的目标的预测精度。
其中一层的Trasformer代码如下所示(ps:为了进一步加速模型的收敛速度,在Pixel Decoder中采用了Deformable attention模块):
class MSDeformAttnTransformerEncoderLayer(nn.Module):
def __init__(self,
d_model=256,
d_ffn=1024,
dropout=0.1,
activation='relu',
n_levels=4,
n_heads=8,
n_points=4):
super().__init__()
# self attention
self.self_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
self.dropout1 = nn.Dropout(dropout)
self.norm1 = nn.LayerNorm(d_model)
# ffn
self.linear1 = nn.Linear(d_model, d_ffn)
self.activation = _get_activation_fn(activation)
self.dropout2 = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ffn, d_model)
self.dropout3 = nn.Dropout(dropout)
self.norm2 = nn.LayerNorm(d_model)
@staticmethod
def with_pos_embed(tensor, pos):
return tensor if pos is None else tensor + pos
def forward_ffn(self, src):
src2 = self.linear2(self.dropout2(self.activation(self.linear1(src))))
src = src + self.dropout3(src2)
src = self.norm2(src)
return src
def forward(self,
src,
pos,
reference_points,
spatial_shapes,
level_start_index,
padding_mask=None):
# self attention
src2 = self.self_attn(
self.with_pos_embed(src, pos), reference_points, src,
spatial_shapes, level_start_index, padding_mask)
src = src + self.dropout1(src2)
src = self.norm1(src)
# ffn
src = self.forward_ffn(src)
return src
- Transformer Decoder with mask attention 通过Object query和Pixel Decoder中得到的Multi-scale feature去逐层去refine二值mask图,得到最终的结果。
其中核心的mask cross attention,会将前一层的预测的mask作为MultiheadAttention的atten_mask输入,以此来将注意力的计算限制在这个query关注的前景中。具体实现代码如下:
class CrossAttentionLayer(nn.Module):
def __init__(self,
d_model,
nhead,
dropout=0.0,
activation='relu',
normalize_before=False):
super().__init__()
self.multihead_attn = nn.MultiheadAttention(
d_model, nhead, dropout=dropout)
self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
self._reset_parameters()
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
tgt,
memory,
memory_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.multihead_attn(
query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory,
attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout(tgt2)
tgt = self.norm(tgt)
return tgt
def forward_pre(self,
tgt,
memory,
memory_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm(tgt)
tgt2 = self.multihead_attn(
query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory,
attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout(tgt2)
return tgt
def forward(self,
tgt,
memory,
memory_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, memory_mask,
memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, memory_mask,
memory_key_padding_mask, pos, query_pos)
Tricks
1.efficient multi-scale strategy
在pixel decoder中会解码得到尺度为原图1/32、1/16、1/8的特征金字塔依次作为对应transformer decoder block的K、V的输入。参照deformable detr的做法,对每个输入都加上了sinusoidal positional embedding和learnable scale-level embedding。按分辨率从低到高的循序依次输入,并循环L次。
2.PointRend
通过PointRend的方式来节省训练过程中的内存消耗,主要体现在两个部分a.在使用匈牙利算法匹配预测mask和真值标签时,通过均匀采样的K个点集代替完整的mask图来计算match cost b.在计算损失时按照importance sampling策略采样的K个点集代替完整的mask图来计算loss(ps实验证明基于pointreind方式来计算损失能够有效提升模型精度)
3.Optimization improvements
- 更换了self-attention和cross-attention的顺序。self-attention->cross-attention变成cross-attention->self-attention。
- 让query变成可学习的参数。让query进行监督学习可以起到类似region proposal的作用。通过实验可以证明可学习的query可以产生mask proposal。
- 去掉了transformer deocder中的dropout操作。通过实验发现这个操作会降低精度。
复现精度
实例分割及全景分割在COCO上的复现精度,实验在单机8卡A100环境下进行(ps :关于实例分割复现精度问题在官方repo issue 46中有提及)
| Model | PQ | Box mAP | Mask mAP | memory | train_time |
|---|---|---|---|---|---|
| mask2former_r50_instance_official | 43.7 | ||||
| mask2former_r50_8xb2_epoch50_instance | 46.09 | 43.26 | 13G | 3day2h | |
| mask2former_r50_panoptic_official | 51.9 | 41.7 | |||
| mask2former_r50_8xb2_epoch50_panoptic | 51.64 | 44.81 | 41.88 | 13G | 3day4h |
语义分割在ADE20K数据集上进行复现
| Model | mIoU | train memory | train_time |
|---|---|---|---|
| mask2former_r50_semantic_official | 47.2 | ||
| mask2former_r50_8xb2_e127_samantic | 47.03 | 5.6G | 15h35m |
使用EasyCV训练分割模型
对于特定场景的分割,可以使用EasyCV框架和相应数据训练定制化的分割模型。这里以实例分割为例子,介绍训练流程。
一、数据准备
目前EasyCV支持COCO形式的数据格式,我们提供了示例COCO数据用于快速走通流程。
wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/data/small_coco_demo/small_coco_demo.tar.gz && tar -zxf small_coco_demo.tar.gz
mkdir -p data/ && mv small_coco_demo data/coco
二、模型训练
在EasyCV的config文件夹下,我们提供了mask2former的数据处理和模型训练及验证的配置文件(configs/segmentation/mask2former/mask2former_r50_8xb2_e50_instance.py),根据需要修改预测的类别、数据路径。
执行训练命令,如下所示:
#单机八卡
python -m torch.distributed.launch --nproc_per_node=8 --master_port 11111 tools/train.py \
configs/segmentation/mask2former/mask2former_r50_8xb2_e50_instance.py \
--launcher pytorch \
--work_dir experiments/mask2former_instance \
--fp16
模型导出,将config文件保存到模型中,以便在predictor中得到模型和数据处理的配置,导出后的模型就可直接用于分割图的预测。
python tools/export.py configs/segmentation/mask2former/mask2former_r50_8xb2_e50_instance.py epoch_50.pth mask2former_instance_export.pth
Reference
实例分割模型:http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/modelzoo/segmentation/mask2former_r50_instance/mask2former_instance_export.pth
全景分割模型:http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/modelzoo/segmentation/mask2former_r50_panoptic/mask2former_pan_export.pth
语义分割模型:http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/modelzoo/segmentation/mask2former_r50_semantic/mask2former_semantic_export.pth
EasyCV往期分享
EasyCV开源地址:https://github.com/alibaba/EasyCV
EasyCV DataHub 提供多领域视觉数据集下载,助力模型生产 https://zhuanlan.zhihu.com/p/572593950
EasyCV带你复现更好更快的自监督算法-FastConvMAE https://zhuanlan.zhihu.com/p/566988235
基于EasyCV复现DETR和DAB-DETR,Object Query的正确打开方式 https://zhuanlan.zhihu.com/p/543129581
基于EasyCV复现ViTDet:单层特征超越FPN https://zhuanlan.zhihu.com/p/528733299
MAE自监督算法介绍和基于EasyCV的复现 https://zhuanlan.zhihu.com/p/515859470
EasyCV开源|开箱即用的视觉自监督+Transformer算法库 https://zhuanlan.zhihu.com/p/50521999
END
EasyCV会持续进行SOTA论文复现进行系列的工作介绍,欢迎大家关注和使用,欢迎大家各种维度的反馈和改进建议以及技术讨论,同时我们十分欢迎和期待对开源社区建设感兴趣的同行一起参与共建。









![[附源码]java毕业设计家乡旅游文化推广系统](https://img-blog.csdnimg.cn/26bba2f4e8f2470a934eea1029731bf2.png)