一、指针数组与数组指针
1.指针数组VS数组指针
(1)指针数组:实质是一个数组,因为这个数组中传参的内容全部是指针变量。
(2)数组指针:实质是一个指针,这个指针指向一个数组
2.分析指针数组与数组指针的表达式
注意点:符号的优先级有什么作用?其实是决定当2个符号一起作用的时候决定哪一个符号先运算,哪一个符号后运算。
【】,. ,->这几个优先级比较高
(1)int *p[5];
核心:p
第一个结合:p[5]---》【数组的(【】)优先级比指针(*)高】
第二个结合:*p[5]---》整一个指针数组
因为p先跟【】组合所以是数组,在跟*结合所以是指针,合起来就是指针数组【先结合起来的放在后面】
数组有5个元素大,数组中的元素都是指针,指针指向的元素类型是int类型的,整个符号是一个指针数组。
(2)int (*p)[5]
核心:p---》p是一个指针
第一个结合:(*p)【】--》数组指针
p先和*结合,所以是指针,在和【】结合,所以是数组指针【先结合起来的放在后面】
指针指向一个数组,数组有5个元素,数组中存的元素是int类型,是一个数组
(3)Int *(p[5])
核心:p
第一个结合:p[5]--->数组
第二个结合:* (p[5])---》是指针数组
因为p先跟【】组合所以是数组,在跟*结合所以是指针,合起来就是指针数组【先结合起来的放在后面】
数组有5个元素大,数组中的元素都是指针,指针指向的元素类型是int类型的,整个符号是一个指针数组。
(4)总结
(1)一般规律,Int *p(p是一个指针)
int p[5](p是一个数组)
(2)我们在定义一个符号时,关键在于:首先搞清楚你定义的符号是谁
第一步:找核心;
第二步:看谁和核心最近,谁根核心结合;
第三步:以后继续向外结合
(3)如果核心与*结合,表示核心是指针;如果核心和【】结合,表示核心是数组;如果核心和()结合,表示核心是函数
(4)用一般规律
3.总结
1.优先级和结合性是分析符号意义的关键
2.学会逐层剥离的方法
找到核心后从内向外层进行结合,结合之后可以把已经结合的部分当成一个整体,再去和整体外部的继续进行结合
二、函数指针与typedef
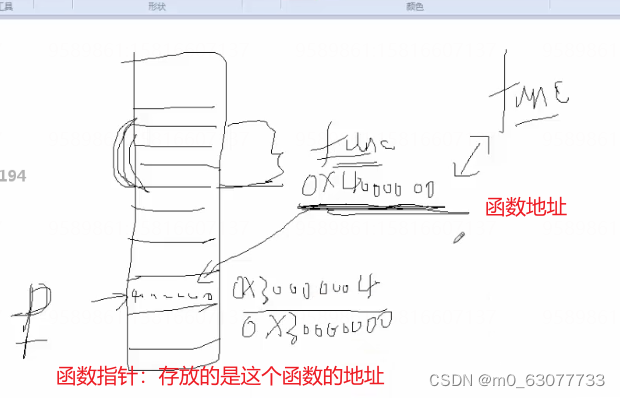
1.函数指针的实质(还是指针变量-->存放函数地址)
(1)函数指针的实质还是指针,还是指针变量,本身占4字节(在32位系统中,所有的指针都是4字节)
(2)函数指针,数组指针,普通指针之间并没有本质区别,区别在于指针指向的大小是什么东西
(3)函数的实质是一段代码,这一段代码在内存中是连续分布的(一个函数的大括号括起来的所有语言将来编译出来生成的可执行程序是连续的),所以对应函数来说很关键的就是函数中的第一句代码的地址,这个地址就是所谓的函数地址,在c语言中用函数名这个符号来表示。
(4)结合函数的实质,函数指针其实就是一个普通变量,这个普通变量的类型是函数指针变量类,它的值就是某一个函数的地址(页就是它的函数这个符号在编译器中对应的值)
2.函数指针的书写和分析方法
(1)C语言本身是强类型语言(每一个变量都有自己的变量类型),编译器可以帮我们做严格的类型检查
(2)所有的指针变量类型其实本质都是一样的,但是为什么在c语言中要去区分他们,写法不一样呢(比如int类型指针就写int *p;数组指针就写int (*p)[5],函数指针就写的更复杂)
(3)假设我们有个函数是:
void func(void),
对应的函数指针;void (*p)(void)
类型是void (*)(void)
(4)函数名和数组名最大的区别就是:函数名做右值时加不加&效果和意义都是一样的;
pFunc = func1;//左边是一个函数指针变量,右边是一个函数名
pFunc = &func1;//&func1和func1做右值一模一样但是数组名做右值时加不加&意义就不一样。
void func1(void) {
printf("test");
}
void main(){
void (*pFunc)(void);//变量名是:pFunc
//类型是:void (*) (void)
pFunc = func1;//左边是一个函数指针变量,右边是一个函数名
pFunc = &func1;//&func1和func1做右值一模一样
func1();//用函数指针来解调用函数
}(5)写一个复杂的函数指针的实例:比如函数是strcpy函数
char *strcpy(char *dest, const char *src);
对应的函数指针是:char* (*pFunc)(char *dest,const char *src)
//直接使用函数指针调用strcpy
char a[5] = { 0 };
//char *strcpy(char *dest, const char *src);--->函数原型
char* (*pFunc)(char*, const char*);//变量名为:pFunc
pFunc = strcpy;
pFunc(a, "abc");
printf("a=%s\n", a);
3.typedef关键字的用法
(1)typedef是C语言中一个关键字,作用是用来定义(或者叫重命名类型)
(2)c语言中类型一共有2种:
第一种是编译器定义的原生类型(基础数据类型)
第二种是用户自定义类型,不是语言自带是程序员自己定义的
(3)typedef是将自定义类型进行重命名
(4)注意点:
typedef是给类型重命名,也就是说typedef加工出来都是类型,不是变量。
//这句话重命名了一种类型,这个新类型叫pType,类型是:char* (*)(char*, const char*)
typedef char* (*pType)(char*, const char*);
//函数指针数组
typedef char* (*pType[1])(char*, const char*);
void main(){
char* (*p1)(char*, const char*);
char* (*p2)(char*, const char*);
pType p3;//等价于char* (*p3)(char*, const char*);
pType p4;
}三、函数指针实战
1.用函数指针调用执行函数
(1)最简单的函数指针来调用函数的示例上面已经讲解
(2)用函数指针指向不同的函数来实现同一个调用指向不同的结果
(3)比如C++和java等面向对象的语言,就会知道面向对象三大特征有一个多态。多态就是同一个指向实际结果不一样,跟我们这里看到的现象其实是一样的。
#include<stdio.h>
#include <string.h>
//定义了一共类型pFun,这个函数指针类型指向一种特点参数列表和返回值的函数
typedef int (*pFun)(int, int);
int add(int a, int b){
return a + b;
}
int sub(int a, int b) {
return a - b;
}
int multiply(int a, int b) {
return a * b;
}
int divide(int a, int b) {
return a / b;
}
void main(){
pFun p1 = NULL;//函数指针
char c = 0;
printf("请输入操作数据类型:");
scanf("%c", &c);
switch (c) {
case '+':
p1 = add;
break;
case '-':
p1 = sub;
break;
case '*':
p1 = multiply;
break;
case '/':
p1 = divide;
break;
default:
p1 = NULL;
break;
}
int a, b;
printf("请输入2位数字");
scanf("%d %d", &a, &b);
int result = 0;
result=p1(a, b);
printf("a=%d,b=%d,c=%d", a, b, c);
}刚才调试可以得到很多信息:
(1)当程序出现段错误的时候,第一步先定位段错误。定位的方法就是在可疑加打印消息,从而锁定导致段错误的语句,然后集中分析这句话为什么会错误
(2)Linux中命令行默认是行缓冲的,意思是当我们程序printf输出的时候,LInux不会一个字一个字的输出我们的内容。而是将其缓冲起来放在缓冲区等一行准备完再一次性把一行全部输出(为了效率)。Linux判断一行有没有完的依据就是换行符'\n'
(window中换行符是\r\n
Linux中的换行符是\n
ios中的换行符是\r)
也就是说你printf再多,最后没有遇到\n(或者中断程序,或者缓冲区满)都不会输出而会不断缓冲,这时候你是看不到内容输出。因此,再每一个printf打印语句(尤其是用来做调试的printf)后面一定要加\n,否则可能导致几点:
(3)关于再linux命令行下用scanf写交互性代码的问题,想说以下几点:
1.我们用户再输入内容时结尾都会用\n结尾,但是程序中scanf的时候都不会去接收最后的\n,导致这个回车保存再标志输入中。下一次再scanf时就会被拿出来,就是导致你真正想拿的那个数反而没有机会拿,导致错误。
printf("请输入a=%d b=%d\n",a,b);
do{
scanf("%c",&c);//将上面的换行符读取走
}while((c=='\n') || (c=='\r));
2.结构体内嵌函数指针实现分层

总结:
(1)本节和上节实际完成同一个任务,但是采用了不同的程序架构
(2)对于简单问题来说,上节的不分层反而容易理解,反而简单,本节的分层代码不好理解,看起来有点把简单问题复杂化。原因在于我们这个问题本身确实是简单问题,而简单问题应该简单处理。我们为什么还要这样做?
(3)分层之后上层为下层提供服务,上层写的代码是为了在下层中被调用
(4)上层注重注重业务逻辑,与我们最终的目标相直接关联,而没有具体干活的函数。
(5)下层注重实际干活的函数,注重为上层填充变量,并且将变量传递给上层中的函数(其实就是调用上层提供的接口函数)来完成任务。
cal.c
#include<stdio.h>
#include"framwork.h"
int main(){
int ret=0;
struct cal_t myCal;
myCal.a=12;
myCal.b=3;
myCal.p=div;
ret=calculator(&myCal);
printf("ret=%d",ret);
return 0;
}framwork.c
#include<framwork.h>
int add(int a, int b){
return a + b;
}
int sub(int a, int b) {
return a - b;
}
int multiply(int a, int b) {
return a * b;
}
int divide(int a, int b) {
return a / b;
}
//计算器函数
int calculator(const struct cal_t *p){//这里我们使用的是结构体指针
//表示将结构体中的值赋值给变量
return p->p(p->a,p->b);
}
framwork.h
#ifndef __CAL_H__
#define __CAL__H__
//定义了一共类型pFun,这个函数指针类型指向一种特点参数列表和返回值的函数
typedef int (*pFun)(int, int);
//结构体是用来做计算器,计算器工作时需要的原材料
struct cal_t{
int a;
int b;
pFunc p;
}
//函数原型声明
void calculator(const struct cal_t *p);四、在论typedef
1.c语言的2种类型:内建类型与用户自定义类型
(1)内建类型ADT,自定义类型UDT
2.typedef定义类型而不是变量
(1)类型是一个数据模块,变量是一个实在的数据。类型是不占内存,而变量是占内存的
(2)面向对象的语言中:类型就是类class,变量就是对象
3.typedef VS #define的区别
宏定义 (define) 和 typedef 的区别 | 编程指北
typedef 旧的 新的
#define 新的 旧的
typedef char *pChar;//表示将char*重命名为pChar
#define pChar char*;4.typedef和结构体
(1)结构体在使用时都是先定义结构体,然后再使用结构体去定义变量
(2)C语言规定,结构体类型使用时必须使用 【struct 结构体类型名 结构体变量名;】这样来定义
//结构体类型的定义
struct student {
char name[20];
int age;
};
//定义了一个结构体类型,这个类型有2个名字
//第一个名字:struct student
//第二个名字:student_t
typedef struct student {
char name[20];
int age;
}student_t;
//两个名字一样也可以
//第一个名字:struct student
//第二个名字:student
typedef struct student {
char name[20];
int age;
}student;
int main(){
struct student s1;//struct stduent是类型,s1是变量
s1.age = 12;
student_t s2;
student s3;
//student s2;//不能这样定义一个结构体变量
return 0;
}(3)使用typedef一次定义2个类型,分别是结构体变量类型和结构变量指针
结构体指针类型:struct teacher * pTeacher
//我们一次定义了两个类型
//第一个是结构体类型,有2个名字:struct teacher teacher
//第二个是结构体指针类型,有2个名字:struct teacher* pTeacher
typedef struct teacher {
char name[23];
int age;
int mager;
}teacher,*pTeacher;
teacher t1;
t1.age = 23;
pTeacher p1 = &t1;
printf("teacher age=%d\n", p1->age);
5.typedef与const
(1)typedef int* PINT:永远只能修改变量的值,不能修改变量本身
(2)typedef const int *CPINT:可以修改变量本身,但是不能修改变量的值
1.typedef int* PINT;const PINT p2;相当于int *const p2;【不能修改p2的值】
typedef int* PINT;//将int * 重命名为PINT
//注意区分
//const int *p和int *const p是不同的
//【const int *p】:表示p指向的变量是不可以变
//【int *const p】:表示p本身不可以改变
int a = 23;
int b = 11;
PINT p1 = &a;
//本来翻译过来是这样的:const int *p2 【指向的值不能改变】
//但是测试说明:p2所指向的值是可以改变的
const PINT p2= &a;
*p2 = 33;
printf("*p2=%d",* p2);
p2 = &b;//此处报错,p2本身不能被修改2.typedef int* PINT;cPINT const p2;相当于int *const p2;【不能修改p2的值】
typedef int* PINT;//将int * 重命名为PINT
//注意区分
//const int *p和int *const p是不同的
//【const int *p】:表示p指向的变量是不可以变
int a = 23;
int b = 11;
PINT p1 = &a;
//本来翻译过来是这样的:const int *p2 【指向的值不能改变】
//但是测试说明:p2所指向的值是可以改变的
PINT const p2= &a;
*p2 = 33;
printf("*p2=%d",* p2);
p2 = &b;//此处报错,p2本身不能被修改
如果确实想要得到const int *p【可以修改p本身】,这种效果,只能使用typedef const int *CPINT;CPINT p1;
//此时等价于
// int *cosnt p;【表示p本身不能改变】
typedef const int* CPINT;
int a = 12;
int b = 23;
CPINT p = &a;
*p = 22;//报错,此时不能修改p所指向的值
p = &b;6.使用typedef的意义
(1)简化类型的描述
char *(*)(char *,char *); typedef char *(*pFun)(char *,char *)
(2)很多编程体系下,人们倾向于不适应int,double等C语言内建类型,因为这些类型本身和平台是相关的(比如int再16位机器上是16位的,再32位机器上就是32位),所以很多程序使用自定义的中间类型再做缓冲。
用size_t来替代int
typedef int size_t;
(3)STM32库中全部使用了自定义类型
五、二重指针
1.二重指针与普通一重指针的区别
(1)从本质上来说,二重指针和一重指针本质都是指针变量,指针变量的本质就是变量
(2)一重指针变量和二重指针变量本身都占4字节内存空间
char** p1;//二重指针
char* p2;//一重指针
printf("sizeof(p1)=%d", sizeof(p1));//4
printf("sizeof(p2)=%d", sizeof(p2));//42.二重指针的本质
(1)二重指针本质也是指针变量,和一重指针的差别就是他指向的变量类型必须是一个一重指针。二重指针其实也是一种数据类型,编译器再编译时会根据二重指针的数据类型来做静态类型检查,一旦发现允许是数据类型不匹配编译器就会报错。
(2)一重指针完全可以做二重指针做的事情。

3.二重指针的用法
(1)二重指针指向一重指针的地址
char** p1;//二重指针
char* p2;//一重指针
p1 = &p2;//p2本身是char *类型的,再取地址变成 char **类型的和p相同(2)二重指针指向指针数组
int* p1[2];
int* p2;
int** p3;
//p1 = p2;//报错
//p1是指针数组名,本质是数组名,数组名做右值表示数值首元素首地址
//数组的元素就是int*类型,所以p1做右值就表示一个int *类型
//变量的地址,所以p1就是一个int类型的变量的指针
//所以他指向一个二重指针int **;
p3 = p1;(1)实践编程中二重指针用的比较少,大部分时候就是和指针数组纠结起来。
(2)实际编程中有时候在函数传参时为了通过函数内部改变外部的一个指针变量,会传这个指针变量的地址(也就是二重指针)进去。
void func(int** p) {
*p = (int*)0x123456;
}
int main(){
int a = 4;
int* p = &a;//此时p指向a
printf("p=%p\n", p);
func(&p);//此时在func内部将p指向了其他地方
printf("p=%p\n", p);
*p = 23;//此时p指向0x123456,但是这个地址是不允许访问的,所以出现段错误
}4.二重指针与数组指针
(1)二重指针,数组指针,结构体指针,一重指针,普通变量的本质都是相同的,都是变量
(2)所有的指针变量的本质都是相同的,都是4字节。都是用来指向别的东西的,不同类型的指针变量只是可以指向的(编译器允许你指向的)变量类型不同。
(3)二重指针就是:指针数组指针
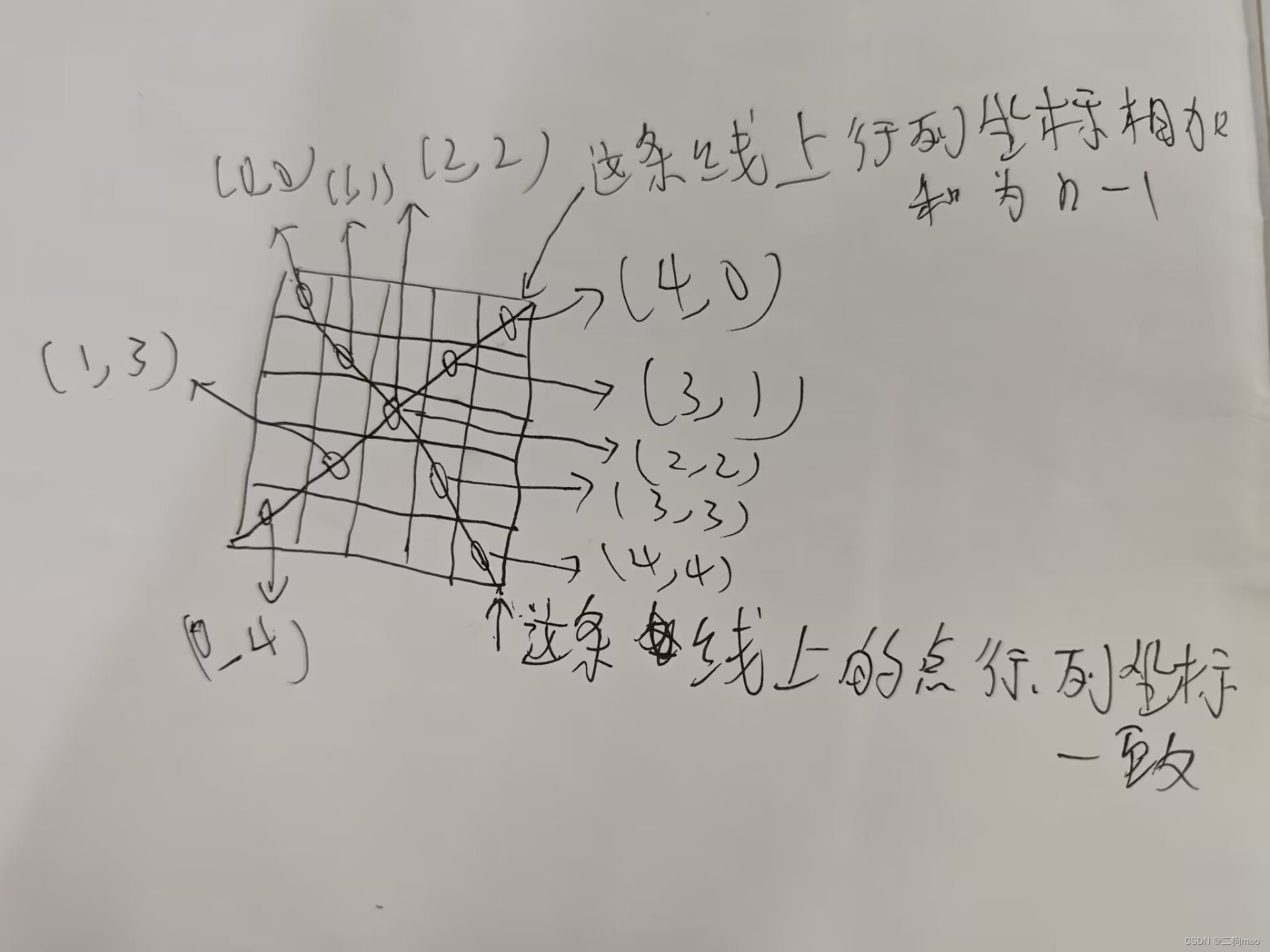
六、二维数组
1.二维数组的内映像

(1)一维数组在内存中的连续分布的多个内存单元组成的,而二维数组在内存中也是连续分布的多个内存单元组成的
(2)从内存角度来看,一维数组和二维数组没有本质区别

2.二维数组的维数

3.二维数组的下标式访问和指针式访问

4.二维数组的应用和更多维数组

七、二维数组的运算和指针
1.指针指向二维数组的数组名
(1)二维数组的数组名表示二维数组的第一位数组中首元素(也就是第二维的数组)的首地址
(2)二维数组的数组名a等同于&a[0],这个和一维数组的符号含义是相符的
(3)用数组指针来指向二维数组的数组名类型是匹配的
int a[2][3] = { {1,2,3},{4,5,6} };
//int* p1 = a;//报错---类型不匹配
//int** p2 = a;//报错---类型不匹配
int(*p3)[3] ;//类型匹配
p3 = a; //数组指针,指针指向一个数组,数组有2个int类型元素
//a是二维数组的数组名,作为右值表示二维数组第一维的数组
//的首先元素的首地址,等同于&a[0]
printf("a[0][1]=%d\n", *(*(p3 + 0) + 1));
printf("a[1][1]=%d\n", *(*(p3 + 1) + 1));2.指针指向二维数组的第一维
(1)用int *p来指向二位数组的第一维a[i]
//指针指向二维数组的第一维
int a[2][5] = { {1,2,3,8,9},{4,5,6,10,11} };
//&a[0]:表示第一维的地址
//int* p4 = &a[0];//报错
int* p4 = a[0];//a[0]表示二维数组的第一维的第一个元素,相当于是
//第二维的整体数组的数组名。数组名又表示数组元素
//首地址,因此a[0]等同于&a[0][0]
//等价于
int* p5 = &a[0][0];
printf("a[0][4]=%d", *(p5 + 4));
//a[1]等价于&a[1][0]
int* p6 = a[1];//此时指向第一维的第二个元素
printf("a[1][3]=%d", *(p6 + 3));3.指针指向二维数组的第二维
(1)二维数组的第二维元素其实就是普通变量了(a[1][1]其实就是int类型的7),已经不能用指针类型和它相互赋值
(2)除非int *p=&a[i][j],类似于指针指向二维数组的第一维