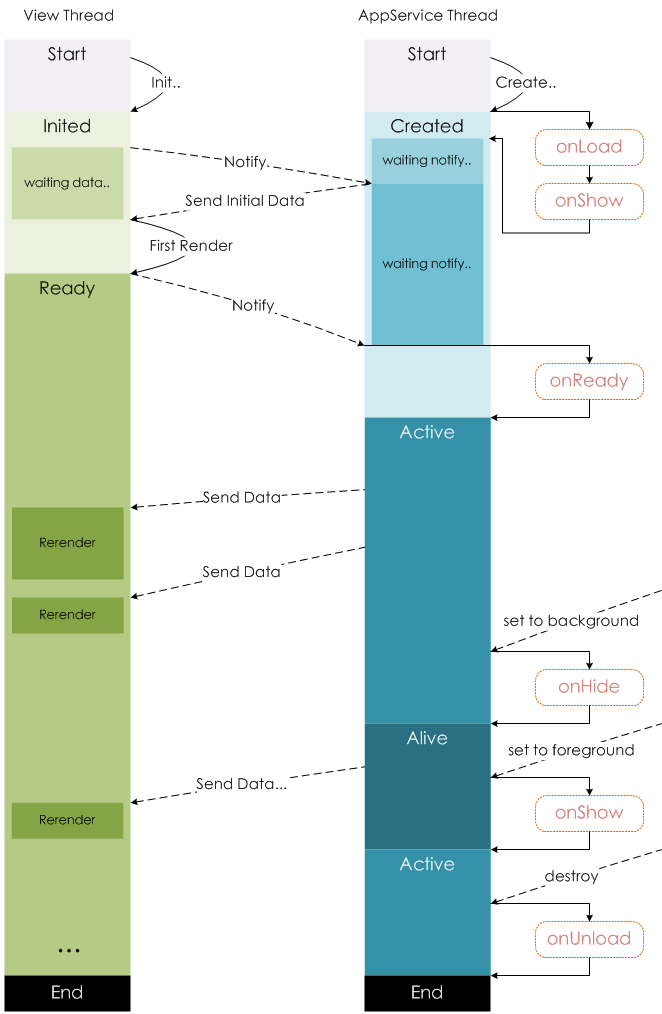
CLIP和改进工作
CLIP 改进方向
语义分割
Lseg、GroupViT
目标检测
ViLD、GLIP v1/v2
视频理解
VideoCLIP、CLIP4clip、ActionCLIP
图像生成
VQGAN-CLIP、CLIPasso、CLIP-Draw
多模态下游任务
VL Downstream
其他
prompt enginering(CoOp等)
depthCLIP、pointCLIP(点云)、audioCLIP(音频)
CLIP:Learning Transferable Visual Models From Natural Language Supervision(2021)
数据集4个亿
预训练阶段
论文标题中有一个重要的点——自然语言监督。这说明 CLIP 是涉及文字和图片的多模态领域的工作,它从文本中得到监督信号,引导视觉分类的任务。
其实,预训练网络的输入是文字与图片的配对,文本为‘a photo of a
将文字和图片分别通过一个encoder,得到embeddings。这里的text encoder就是 Transformer;而img encoder既可以是 Resnet,也可以是 VIT,作者对这两种结构都进行了考察。

分别得到了 N 个图片和 N 个文本的embeddings。接下来,我们需要对它们进行对比学习(contrastive learning)。对比学习需要一些正样本和负样本。在这里,配对的句子和文本就是一对正样本(也就是对角线上的);反之,不配对的就是负样本(对角线之外的)。预训练网络的目标,就是最大化正样本对的余弦相似度,并最小化负样本的余弦相似度。
这种无监督的训练方式需要大量的数据。后面我们会提到,OpenAI 专门收集了四亿个样本对的巨无霸数据集。真是有钱任性啊。
推理过程
接下来是 zero-shot 的推理过程。给定一张图片,如何利用预训练好的CLIP做分类?这里作者很巧妙地设置了一道“多项选择”。具体来说,我给网络一堆分类标签,比如cat, dog, bird,利用文本编码器得到embeddings。然后分别计算这些标签与图片的余弦相似度;最终相似度最高的标签即是预测的分类结果(或者设置阈值,大于就输出)。
作者提到,相比于单纯地给定分类标签,给定一个句子的分类效果更好:预训练时模型看到的大多是句子,如果在推理时突然变成单词,效果肯定会下降。作者还说,还专门讨论了prompt engineering。

局限性
作者在第六章介绍了 CLIP 的局限性。
首先,虽然 CLIP 在 Imagenet 上与 Resnet 50 打成平手。但后者远远不是 state-of-art model。CLIP 离表现最好的模型还差了十几点精度。尽管大规模训练能够极大地促进模型精度,但作者预估,要媲美现今表现最好的模型,计算量至少要扩大 1000 倍。
另一个问题在于,如果做推理的数据真的和训练数据差得非常远 (out of distribution),那么 CLIP 的泛化效果会很差。作者举了个例子,在MNIST数据集上(1-9手写数字图片),CLIP 只达到了88%的准确度,还不如一个作用在像素点上的逻辑回归。虽然 4 亿数据集很大,但是很有可能没有包含这种不常见的手写数字的图片。这就引起了一些疑虑:CLIP 的强大有多大程度上取决于这个高质量、大规模的数据集。
还有一点,CLIP 在推理阶段,需要我们手动地设置“多项选择题”。作者设想,如果能够让网络自动生成文本来描述图片就好了(后面有人做了)。另外作者还提到了数据利用效率不高的问题。
Lseg:Language-driven Semantic Segmentation
用的是有监督,存在标注的分割图
细节:
LSeg 整个文本编码器就是 CLIP 的文本编码器的模型和权重,并且训练、推理全程中都是冻结的;
LSeg 的图像编码器可以是任何网络(CNN/ViT),需要进行训练;
Spatial Regularization Blocks 是本文提出的一个模块,为了在计算完像素级图文相似度后有一些可学习的参数来理解计算结果,是由一些卷积和逐深度卷积组成;

GroupVIiT:GroupViT: Semantic Segmentation Emerges from Text Supervision
LSeg 虽然能够实现 zero-shot 的语义分割,但是训练方式并不是对比学习,没有将文本作为监督信号,因此还是需要有监督的分割图标注进行训练。而且由于语义分割的标注非常麻烦,因此分割领域的数据集都不大,LSeg 用的 7 个数据集加起来可能也就一二十万个样本。如何像 CLIP 一样,利用到文本来进行自监督训练呢?GroupViT 就是语义分割领域像 CLIP 一样使用文本来自监督训练的代表工作之一。GroupViT 通过文本自监督的对比学习来进行语义分割的训练,在推理阶段,可以实现 zero-shot 的推理。
如标题所说,GroupViT 的核心思想是利用了深度学习之前无监督分割的 grouping 思想。当时的做法大概是在确定某个中心点之后,不断向外发散,将接近的点都分到一个 group 中,最终发散完毕,得到分割结果。在 GroupViT 中的 grouping 是将 ViT 中的图像块 token进行分配,分配到不同的语义类别 token 上。

模型框架与训练过程
下面来看一下 GroupViT 具体是怎样进行训练的。模型框架和训练过程如下图所示。送入Transformer 的除了图像块 token s i 1 \mathbf{s}_i^1 si1(尺寸 N × D N\times D N×D) ,还有可学习的 group token g i 1 \mathbf{g}_i^1 gi1(尺寸 M 1 × D M_1×D M1×D ,有点像object query) 。这里的 group tokens 就相当于分类任务中的 cls token,由于分类任务一张图像只需要一个全图的特征,因此只用一个 token 即可,而语义分割中一张图需要多个特征,因此是多个 group tokens。
64个group是希望有多的聚类中心,之后会在block里合并,之前一个是代表整个图片
(随机初始化的还是聚类出来的?)
经过六层 Transformer Layers 的学习之后,通过 Grouping Block 来完成 grouping ,将图像块 token 分配到各个 group token 上,合并成为更大的、更具有高层语义信息的 group。Grouping token 的做法如图 7 右侧所示,与自注意力机制类似,就是计算图像块 token 与 grouping token 的相似度分配到最大的上面。
这里为了克服 argmax 的不可导性,使用了 gumbel softmax。
合并完成后得到 、
s
i
2
\mathbf{s}_i^2
si2(尺寸
M
1
×
D
M_1\times D
M1×D)。然后再添加新的 Group tokens
g
i
2
\mathbf{g}_i^2
gi2(尺寸为
M
2
×
D
M_2\times D
M2×D),重复上述过程:经过 3 层 Transformer Layers 的学习之后,在经过再一次的 grouping block 分配之后,得到
s
i
3
\mathbf{s}_i^3
si3(尺寸
M
2
×
D
M_2\times D
M2×D) 。
这里就要用语义编码器提取的语义特征来监督了,但是不同于分类任务只有一个图像特征,这里有
M
2
M_2
M2 个图像特征(8*384),怎么计算其与文本特征的相似度呢?
这里作者用了最简单的办法,直接平均池化,得到一个 D D D 维的图像特征 z I \mathbf{z}^I zI,与文本特征 z T \mathbf{z}^T zT计算对比损失。
这个模型只有8个group,最多分8类,再多就不行了
limitation:没有多尺度信息只用了encoder
其他细节:
除了与图形配对的文本本身,还将文本中的名词提取出来,按照类似 CLIP 中的方法生成 prompt (如 “A photo of a {tree}.”),与某个图像特征计算对比损失,见原文 Figure 3;

推理过程
然后来看一下 GroupViT 是如何进行 zero-shot 推理的。如图 8 所示,GroupViT 实现 zero-shot 推理的方式与 CLIP 十分相似,先通过图像编码器得到 M 2 M_2 M2 个图像特征,然后将它们分别与给定类别 prompt 提取的文本特征计算相似度,取最大值。但是这样实现 zero-shot 一个很明显的缺点是能检测到的图像中的类别个数最多只能是 M 2 M_2 M2 个。
其他细节:
对于语义分割中的背景类,GroupViT 在推理时是这样处理的:推理过程怎么考虑背景类?为了提高前景类的分割阈值设了一个阈值,相似度超过0.9(取最大)才算那个类,都没有就算背景,对于类别数少的好用,类别多,相似度比较低,前景背景相似度差不了多少,阈值设的很低会出现错误分类的问题
可视化结果
GroupViT 中不同阶段不同 group token 对应的注意力区域可视化结果如图 9 所示。可以看到,在第一阶段,每个 token 都注意到一些语义明确的区域,如眼睛、四肢,并且,都是些相对较小的区域;在第二阶段,每个 token 注意到的语义区域则相对较大,如脸、身体。这正符合了作者想要的 group 分组合并的效果。

- GroupViT 是第一个实现 zero-shot 语义分割的工作;
- GroupViT 相较于其他自监督语义分割方法提升显著

但是,PASCAL VOC 在有监督上的水准已经在 90+ 了,因此还是有很大的提升空间。
后续验证
作者认为CLIP分割做的挺好,分类分错了,验证是不是分类错误导致上限低,作者把mask和GTmask对比,直接把iou最大的lable拿过来当作标签,这样和有监督的性能差不多了,分割做的很好
原因是**clip只能学到语义信息很强的东西,**学不到模糊的,背景之类的,学不到背景类
解决方案:根据类别设阈值,改成可学习的阈值,改zeroshot推理过程,训练的时候加上约束融入背景类之中
目标检测
ViLD:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
训练时间非常长,写作方法:上来给个图,问问题,引出研究动机
本文要做的开放词表目标检测的例子如下图所示。在下图中,紫色的是基础类(Base categories),粉色的是新类(Novel categories)。ViLD 想要做到的事情是:在训练时只需要训练基础类,然后通过知识蒸馏从 CLIP 模型中学习,从而在推理时能够检测新类。
当前目标检测标注类别很有限只能测有限类别,能不能在现有数据集之上,模型检测新的类别

模型结构与训练目标
ViLD 的模型结构与训练目标如下图所示。第一阶段没画,ViLD 方法的研究重点在二阶段检测器的第二阶段,即得到proposal之后的阶段。

(a) 是一个常规的二阶段检测器的分类头(mask rcnn),直接计算交叉熵损失。
(b)是 ViLD-text 模型,它将分类器替换为了固定的语义类别文本 embedding 和可学习的背景 embedding,再计算图像文本特征相似度,来计算交叉熵损失。文本 embedding 就是将根据数据集中基础类生成的 prompt 提取到的特征。需要添加一个单独的背景 embedding 的原因是,训练时只有基础类,而其他不在基础类的物体则需要全部归为背景类,用一个可学习的背景 embedding 表示,在训练时一起更新。Projection 层的引入是为了统一图像文本特征的尺寸。
在 ViLD-text 模型中,通过文本 embedding 将图像特征和文本特征联系到了一起,模型结构已经支持文本查询的 zero-shot 检测,但是由于模型还不了解基础类之外的其他语义内容,因此直接做 zero-shot 的效果不会很好。如何巧妙地引入CLIP呢(拓展到CN)?
(c) 是 ViLD-image,它将 CLIP 模型的图像编码器作为教师模型,希望这边输出的M个region embedding和CLIP尽可能一致(知识蒸馏)
为了加速模型训练,在训练 ViLD-image 时先用 CLIP 模型提取好图像区域特征,保存在硬盘中,在训练时直接从硬盘读取即可(Clip权重锁住)。
考虑到 CLIP 模型提取的图像特征与文本关联紧密,ViLD-image 模型通过知识蒸馏来学习预训练的CLIP中的开放世界的图像特征提取能力。由于监督信号来自 CLIP,而非人工标注,因此 ViLD-image 不再受到特定类别的限制,而是对于任何的语义区域都可以由 CLIP 抽取图像特征,检测器来学习。因此模型的 open-vocabulary 能力得到增强。
算的是L1 LOSS
弊端:为什么M个pre-computed proposals?主要是为了让训练更加快速,ab的N个proposal是可以随时变的
(d)是将 ViLD-text 和 ViLD-image 模型合并起来,得到完整 ViLD 模型,同时进行训练,训练目标已经在上面两点介绍过。
Loss算的是cross entropy loss和l1 los
模型训练与推理完整框架
图的上半部分是模型训练过程及目标函数,已经介绍过,不再赘述。图 14 的下半部分是 ViLD 进行 zero-shot 推理时的过程,将**任意类别(基础类+新类)**通过 prompt 生成文本并提取特征,与检测器提取的图像区域特征计算相似度,取最大值为该检测框的预测类别。

GLIP:Grounded Language-Image Pre-training
定位任务(给一段句子定位物体)与图像检测任务非常类似,都是去图中找目标物体的位置。GLIP 模型统一了目标检测(object detection)和定位(grounding)两个任务,构建了一个统一的训练框架,从而将两个任务的数据集都利用起来。再配合伪标签的技术来扩增数据,使得训练的数据量达到了前所未有的规模。在训练完成之后,直接以 zero-shot 的方式在 COCO 数据集上进行测试,达到了 49.8 AP。
GLIP 进行 zero-shot 测试的结果如图所示,不管是给定几个类别(如 person、pistol、apple等)还是给定一段话(如 ‘there are some holes on the road’)作为文本编码器的输入,GLIP 模型都能从图像中找到对应物体的位置。

detection 和 grouding 任务的目标函数都是由两部分损失组成,即分类损失和定位损失。定位损失不必多说,直接去计算与标注中的 GT 框的距离即可。而对于分类损失,则有所不同。
对于 detection 任务来说,分类的标签是一个类别单词,在计算分类损失时,每个区域框特征与分类头计算得到 logits,输出 logits 经过 nms 筛选之后,与 GT 计算交叉熵损失即可。
对于 grounding 任务来说,标签是一个句子,不是用分类头,而是通过文本编码器得到文本特征,计算文本特征与区域框特征的相似度,得到匹配分数。
作者提出,只要判断一下两个任务中什么时候是 positive match,什么时候是 negative match,就能将两个任务统一起来了。
数据
既然统一了 detection 和 grounding 两个任务,最直接的一个利好就是两边的数据集都可以拿来训练这个统一的框架。这些数据集都是有标注的,规模还不够大,想要进一步获得更大量的数据,必须像 CLIP 那样借助无标注的图像文本对数据。但是,目标检测任务的训练必须要 GT 框,单独的图文对数据没法直接用。作者这里使用了 self-training 中伪标签的方式,使用 O365 和 GoldG 上训练好的 GLIP-T© 去在图文对数据 Cap4M/ Cap24M 上生成伪标签,直接当做 GT 框给 GLIP-T/L 进行训练。
生成的伪标签肯定有错误,但是实验表明,经过扩充大量伪标签数据训练得到的 GLIP-L 模型仍然会有性能提高。
模型结构
GLIP 模型结构及训练目标如图 18 所示,模型是以有监督的方式进行训练,计算得到文本特征和图像特征的相似度之后,直接与 GT 计算对齐损失(alignment loss)即可,定位损失(Localization loss)也是直接与GT 框计算。
模型中间的融合层(fusion)是为了增加图像编码器和文本编码器之间的特征交互,使得最终的图像-文本联合特征空间训练得更好。

GLIPv2: Unifying Localization and Vision-Language Understanding
GLIP 的进一步拓展工作 GLIPv2 融合了更多定位相关的任务(如检测、实例分割)和更多的多模态相关的任务(如问答、字幕生成)。

CoOp: Learning to Prompt for Vision-Language Models[IJCV 2022]
prompt改成可学习的向量
Context Optimization (CoOp)
作者提出了两种 CoOp 的实现方式:
(1) Unified Context. 所有类别使用相同的 context words,prompt 形式为

其中, [ V ] m [V]_m [V]m 即为可学习的 context word, M M M 为超参, [ C L A S S ] [CLASS] [CLASS] 为类别单词对应的 word embed. 当然,除了将 [ C L A S S ] [CLASS] [CLASS] 放在最后,也可以将它放在中间

这种形式更加灵活,因为模型可以自由学习是否需要后半部分的 context words,如果不需要的话可以提前学习出 termination signal such as full stop,不过这种 prompt 形式在实验中总体效果不如前一种
(2) Class-Specific Context (CSC). 每个类别使用不同的 context words. 作者发现 CSC 特别适合于一些细粒度分类任务 (e.g. StanfordCars, Flowers102 and FGVCAircraft)

Conditional prompt learning for vision-language models[CVPR 2022]
Introduction
本文是对 CoOp 的改进之作,作者发现 CoOp 中学习到的 context vectors 对同一数据集中的 unseen classes 泛化性不强(原文就这么写的),这说明 CoOp 对训练时使用的 base classes 过拟合了。为了解决上述问题,作者提出 Conditional Context Optimization (CoCoOp),在 CoOp 的基础上进一步学习一个轻量网络用于为每个图像生成 input-conditional token (vector),这样得到的动态 prompts 能够融合每个样本的特征,因此对 class shift 更鲁棒。
实验表明 CoCoOp 对 unseen classes 的泛化性更强,cross-dataset transfer 和 domain generalization 的性能也更强。

CoCoOp: Conditional Context Optimization

作者认为 instance-conditional context 能比 CoOp 中的 unified context 更好地泛化到 unseen (new)classes (it shifts the focus away from a specific set of classes—for reducing overfitting—to each input instance, and hence to the entire task. they are optimized to characterize each instance (more robust to class shift) rather than to serve only for some specific classes)
具体来说,作者引入了 Meta-Net
h
θ
h_\theta
hθ (two-layer bottleneck structure: Linear-ReLU-Linear, with the hidden layer reducing the input dimension by
16
×
16×
16×.),context token 为
v
m
(
x
)
=
v
m
+
π
v_m(x) = v_m + π
vm(x)=vm+π,其中
v
m
v_m
vm为 CoOp 中的 context vector,
π
=
h
θ
(
x
)
\pi=h_\theta(x)
π=hθ(x)
( x ) (x) (x) 为抽取出的图像的 conditional token (vector)
Limitations
(1) training efficiency. CoCoOp is slow to train and would consume a significant amount of GPU memory if the batch size is set larger than one.
(2) generalization ability. on 7 out of the 11 datasets (see Table 1), CoCoOp’s performance in unseen classes still lags behind CLIP’s.
CLIP 改进工作_actionclip模型改进_连理o的博客-CSDN博客
CoCoOp 其实是介于 CoOp 和 CLIP 之间的一个方法。CoOp 的设计初衷用于将 CLIP 先验快速 adapt 到下游任务上,其提升了 accuracy 的同时也牺牲了 generalization,所以 CoOp “专” 而 “精”;而 CLIP 从头到尾都是在追求generalization,所以 CLIP 在所有数据集上的效果都还不错,但不够 “精”,即 “广” 而 “糙”。而 CoCoOp 则介于它们之间,那么问题拿来:我们什么时候才需要 CoCoOp 呢?或者说 CoCoOp 的应用场景真的广吗?举个例子,如果说我想完成某个下游任务我就直接用 CoOp,如果我想同时完成很多下游任务那么我就选 CLIP。这样看,CoCoOp 的 motivation 并不是很强
[CVPR 2023] MaPLe: Multi-modal Prompt Learning
Introduction

作者认为单模态 prompt 不足以充分适应多模态预训练模型的表征空间,为此作者提出 Multi-modal Prompt Learning (MaPLe) 来同时对两个模态进行 prompt learning,从而进一步增强模型在下游任务上的多模态对齐能力
MaPLe模型:

deep Language Prompting. 作者在 text encoder 的前 J J J 层都各引入了 b b b 个 learnable tokens { P i ∈ R d l } i = 1 b \{P^i\in\R^{d_l}\}_{i=1}^b {Pi∈Rdl}i=1b 作为 language context prompts (i.e., deep prompting,VPT deep的也可以试试,这种好像是VPTshallow)


其中, P j , W j P_j,W_j Pj,Wj分别为 j j j 层 L j \mathcal L_j Lj输出的 prompt 和 word embed, P 0 P_0 P0 初始化为 pretrained CLIP word embeddings of the template ‘a photo of a ’,其余层的 prompt 从正态分布随机初始化
Deep Vision Prompting. vision context prompts { P ~ i ∈ R d v } i = 1 b \{\tilde P^i\in\R^{d_v}\}_{i=1}^b {P~i∈Rdv}i=1b由 language context prompts 通过 coupling function F : F : R d l → R d v \mathcal F:\R^{d_l}\rightarrow\R^{d_v} F:Rdl→Rdv(i.e., a linear layer) 得到

其中, c j , E j , P ~ j c_j,E_j,\tilde P_j cj,Ej,P~j 分别为 j j j 层 V j \mathcal V_j Vj 输出的 [ C L S ] [CLS] [CLS],image embed 和 prompt
CLIP Adapter
本文通过在 CLIP 的text encoder、img encoder中插入 adapter 模块,对比 CoOp 实现了更优的微调性能。
Method
CLIP Adapter的架构及其与其他方式的对比如图 所示。一张图片经过 CNN / ViT 得到视觉特征 f f f,即图中彩色的 embedding 条。
(a)朴素的分类器是直接学习一个分类器矩阵权重
W
W
W
(b)CLIP 是人工设计一些 prompt,与类别名一起构建文本,并通过文本编码器提取出文本特征,多个类别的文本特征组成矩阵
W
W
W
(c)CoOp 也是通过学习 prompt token 构造文本,得到文本特征,组成矩阵
W
W
W
(d)最下方的 CLIP-Adapter 则是通过在文本塔和视觉塔中插入一个可学习的 adapter,并将其得到特征与原特征残差相加,得到最终的输出特征。

主要结果和 CoOp 差不多,稍高一点。
TIP-Adapter
Tip-Adapter 是 Training-free CLIP-Adapter 的简写,顾名思义,Tip-Adapter 可以做到在不学习任何参数的条件下,将 CLIP 适配到 few-shot 分类任务。Tip-Adapter 通过构建 key-value cache model 来将 few shot 样本的知识结合进来,再加上 CLIP 本身的图文相似度计算能力,完成下游分类任务。无需任何参数更新的 Tip-Adapter 就达到了与当时微调 SOTA 接近的性能。而 Tip-Adapter 再加上参数微调的版本 Tip-Adapter-F 则能取得更高的性能。

Method
定一个训练好的 CLIP 模型和 N-way K-shot(N 个类,每类 K 个样本) 的 few-shot 分类任务训练集,目标是同时利用 CLIP 的图文相似度计算能力和 NK 个样本的特定知识来创建一个 N 类的分类器。Tip-Adapter 的方法框架如图所示。
few shot训练集中有 NK 张图像,经过 CLIP 视觉编码器,得到视觉特征 F t r a i n ∈ R N K × C \bf{F}{train}\in\mathbb{R}^{NK\times C} Ftrain∈RNK×C ,其中 C 是视觉特征的维度。对 N 个类别取 OneHot 标签,得到 ∗ L t r a i n ∈ R N K × N *\bf{L}{train}\in\mathbb{R}^{NK\times N} ∗Ltrain∈RNK×N 。将 F t r a i n \bf{F}{train} Ftrain 作为 keys,将 ∗ L t r a i n *\bf{L}{train} ∗Ltrain 作为 values,我们就能够构建出 key-value cache model 了,这个 cache model 中包含了 few shot 训练集中的全部知识,与预训练的 CLIP 结合,进行下游分类任务。这个过程中没有任何的参数训练。
在测试时,给定一张测试图片,先用 CLIP 的视觉编码器得到其特征
f
t
e
s
t
∈
R
1
×
C
f_{test}\in\mathbb{R}^{1\times C}
ftest∈R1×C ,分别经过 cache model 和 clip classifier,将得到的 logits 进行加权融合,得到最终的 logits,用于图像分类。最终的 logits 的计算公式为:
logits
=
α
⋅
exp
(
−
β
(
1
−
f
t
e
s
t
F
t
r
a
i
n
T
)
L
t
r
a
i
n
+
f
t
e
s
t
W
c
T
\text{logits}=\alpha\cdot\text{exp}(-\beta(1-f_{test}F_{train}^T)L_{train}+f_{test}W_c^T
logits=α⋅exp(−β(1−ftestFtrainT)Ltrain+ftestWcT
其中 α \alpha α是权重系数, W c W_c Wc 是 CLIP 预训练的分类器(即 CLIP 原文中进行 zero-shot 分类的方式), exp ( − β ( 1 − f t e s t F t r a i n T ) L t r a i n \text{exp}(-\beta(1-f_{test}F_{train}^T)L_{train} exp(−β(1−ftestFtrainT)Ltrain 则是 cache model 的工作方式。其中 ( 1 − f t e s t F t r a i n T ) (1-f_{test}F_{train}^T) (1−ftestFtrainT) 相当于计算测试图像的特征与 few shot 训练集各个图像特征的欧氏距离,取指数保证值全正, β \beta β用于调制分布的锐度。这个过程相当于在 cache model 中检索出最相似的 value。
总结
cache model 的思路类似于 proto(原型) 的方法,在很多 few shot、meta learning 的方法(如 MAML、matching network 等)中早已经出现,Tip-Adapter 将其用于 CLIP few shot learning 中,再借鉴 CLIP-Adapter 中残差连接的方式,将 key-value cache model 中的 few-shot 样本知识与预训练 CLIP 中图文相似度计算的能力综合起来,取得了 CLIP few shot 微调的 SOTA 性能。
ref:
CLIP改进工作串讲(上)_Adenialzz的博客-CSDN博客
CLIP 论文逐段精读【论文精读】_哔哩哔哩_bilibili
CLIP 改进工作串讲(上)【论文精读·42】_哔哩哔哩_bilibili
CLIP微调方式_Adenialzz的博客-CSDN博客