Apache Kafka 是一种分布式数据存储,用于实时处理流数据,它由 Apache Software Foundation 开发,使用 Java 和 Scala 编写,Apache Kafka 用于构建实时流式数据管道和适应数据流的应用程序,特别适用于企业级应用程序和关键任务应用程序,它是最受欢迎的数据流平台之一,被数千家公司用于高性能数据管道、流分析和数据集成。
Apache Kafka 将消息传递、存储和流处理结合在一个地方,允许用户设置高性能和强大的数据流,用于实时收集、处理和流式传输数据。
在本教程中,我们将在 Rocky Linux 服务器上安装 Apache Kafka,并学习 Kafka 作为消息代理的基本用法,通过 Kafka 插件流式传输数据。
先决条件
要学习本教程,您需要满足以下要求:
- Rocky Linux 服务器,您可以使用 Rocky Linux v8 或 v9。
- 具有 sudo root 权限的非 root 用户。
安装 Java OpenJDK
Apache Kafka 是一个基于 Java 的应用程序,要安装 Kafka,您将首先在您的系统上安装 Java,在撰写本文时,最新版本的 Apache Kafka 至少需要 Java OpenJDK v11。
在第一步中,您将从官方的 Rocky Linux 存储库安装 Java OpenJDK 11。
运行下面的 dnf 命令将 Java OpenJDK 11 安装到您的 Rocky Linux 系统。
sudo dnf install java-11-openjdk
当提示确认安装时,输入y并按ENTER继续。

安装 Java 后,使用以下命令验证 Java 版本,您将看到Java OpenJDK 11安装在您的 Rocky Linux 系统上。
java version

现在已经安装了 Java,接下来您将开始安装 Apache Kafka。
下载 Apache Kafka
Apache Kafka 为包括 Linux/Unix 在内的多种操作系统提供多种二进制包,在此步骤中,您将为 Kafka 创建一个新的专用系统用户,下载 Kafka 二进制包,并配置 Apache Kafka 安装。
运行以下命令创建一个名为kafka的新系统用户。这将为 Kafka 创建一个新的系统用户,默认主目录为“/opt/kafka”,该目录将用作 Kafka 安装目录。
sudo useradd -r -d /opt/kafka -s /usr/sbin/nologin kafka
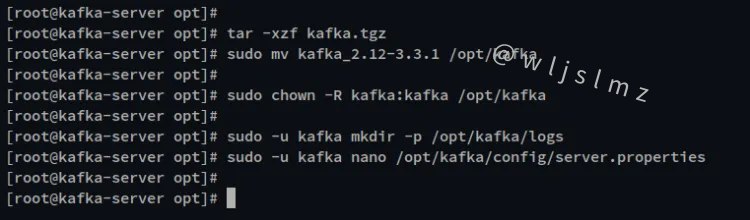
现在将您的工作目录移动到“/opt”。然后,通过下面的 curl 命令下载 Apache Kafka 二进制包。您现在将看到文件kafka.tar.gz。
cd /opt
sudo curl -fsSLo kafka.tgz https://downloads.apache.org/kafka/3.3.1/kafka_2.12-3.3.1.tgz

通过 tar 命令提取文件“kafka.tar.gz”,并将提取的目录重命名为*“/opt/kafka* ”。
tar -xzf kafka.tgz
sudo mv kafka_2.12-3.3.1 /opt/kafka
接下来,通过下面的 chmod 命令 将“/opt/kafka”目录的所有权更改为“ kafka ”用户。
sudo chown -R kafka:kafka /opt/kafka
之后,为 Apache Kafka 创建一个新的日志目录。然后,通过 nano 编辑器编辑默认配置“server.properties”。
sudo -u kafka mkdir -p /opt/kafka/logs
sudo -u kafka nano /opt/kafka/config/server.properties
Kafka 日志目录将用于存储 Apache Kafka 日志,您必须在 Kakfka 配置 sertver.properties 上定义日志目录。
取消注释“log.dirs”选项并将值更改为/opt/kafka/logs。
# Apache Kafka 的日志配置
log.dirs=/opt/kafka/logs
完成后保存文件并退出编辑器。
您现在已经完成了 Apache Kafka 的基本安装和配置。接下来,您将设置并运行 Apache Kafka 作为系统服务。
将 Kafka 作为 Systemd 服务运行
Apache Kafka 软件包包括另一个应用程序 Zookeeper,用于集中服务和维护 Kafka 控制器选择、主题配置以及 Apache Kafka 集群的 ACL(访问控制列表)。
要运行 Apache Kafka,您必须先在您的系统上运行 Zookeeper。在此步骤中,您将为 Zookeeper 和 Apache Kafka 创建一个新的 systemd 服务文件。这两项服务也将在同一用户kafka下运行。
使用以下命令 为 Zookeeper /etc/systemd/system/zookeeper.service 创建一个新的服务文件。
sudo nano /etc/systemd/system/zookeeper.service
将配置添加到文件中。
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
完成后保存文件并退出编辑器。
接下来,使用以下命令 为 Apache Kafka /etc/systemd/system/kafka.service创建一个新的服务文件。*
sudo nano /etc/systemd/system/kafka.service
将以下配置添加到文件中。您可以在[Unit]部分看到,Kafka 服务需要先运行zookeeper.service,并且它始终在zookeeper.service之后运行。
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties > /opt/kafka/logs/start-kafka.log 2>&1'
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
完成后保存文件并退出编辑器。

接下来,运行以下 systemctl 命令以重新加载 systemd 管理器并应用新服务。
sudo systemctl daemon-reload
现在使用以下命令启动 zookeeper 和 kafka 服务。
sudo systemctl start zookeeper
sudo systemctl start kafka
通过下面的 systemctl 命令使 kafka 和 zookeeper 服务在系统启动时自动运行。
sudo systemctl enable zookeeper
sudo systemctl enable kafka
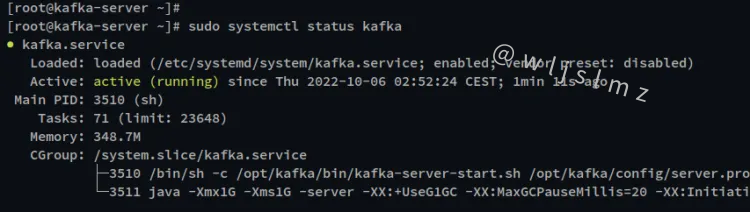
最后,使用以下命令验证 zookeeper 和 kafka 服务。
sudo systemctl status zookeeper
sudo systemctl status kafka
在下面的输出中,您可以看到 zookeeper 服务的当前状态正在运行并且它也已启用。

下面是 kafka 服务状态,它正在运行并且服务已启用。
现在您已经完成了 Apache Kafka 安装并且它现在已经启动并正在运行。接下来,您将学习 Apache Kafka 作为生成消息的消息代理的基本用法,还将学习如何使用 Kafka 插件实时流式传输数据。
使用Kafka Console Producer和Consumer的基本操作
在开始之前,将用于此示例的所有命令均由“/opt/kafka/bin”目录中可用的 Kafka 包提供。
在此步骤中,您将学习如何创建和列出 Kafka 主题、启动生产者并插入数据、通过消费者脚本流式传输数据,最后,您将通过删除 Kafka 主题来清理您的环境。
运行以下命令创建一个新的 Kafka 主题。您将使用脚本“ kafka-topics.sh ”创建一个名为“ TestTopic ”的新主题,其中包含一个复制和分区。
sudo -u kafka /opt/kafka/bin/kafka-topics.sh \
--create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic TestTopic
现在运行以下命令来验证 Kafka 上的主题列表。您应该看到“ TestTopic ”已在您的 Kafka 服务器上创建。
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092

接下来,要生成消息,您可以使用脚本kafka-console-producser.sh,然后将数据插入将被处理的内容中。
运行以下命令启动 Kafka Console Producer 并将主题指定为TestTopic。
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TestTopic --from-beginning
获得 Kafka Console Producer 后,输入将要处理的任何消息。
接下来,打开一个新的终端会话并登录到服务器。然后通过脚本kafka-conosle-consumer.sh打开 Kafka Console Consumer 。
运行以下命令启动 kafka 控制台消费者并将主题指定为TestTopic。
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TestTopic --from-beginning
在下面的屏幕截图中,您可以看到来自 Kafka 控制台生产者的所有消息都被处理到消费者控制台。您还可以在 Console Producer 上键入其他消息,消息将自动处理并显示在 Console Consumer 屏幕上。
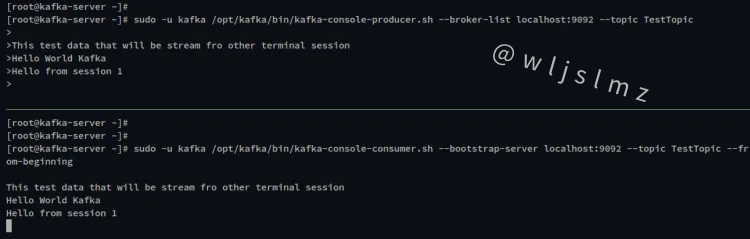
现在按 Ctrl+c 退出 Kafka Console Producer 和 Kafka Console Consumer。
要清理您的 Kafka 环境,您可以通过以下命令 删除和移除TestTopic.
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic TestTopic
使用 Kafka Connect 插件流式传输数据
Apache Kafka 提供了多个插件,可用于从多个源流式传输数据。默认情况下,附加的 Kafka 库插件在*“/opt/kafka/libs* ”目录中可用,您必须通过配置文件*“/opt/kafka/config/connect-standalone.properties* ”启用 kafka 插件。在这种情况下,对于 Kafka 独立模式。
运行以下命令编辑 Kafka 配置文件“ /opt/kafka/config/connect-standalone.properties ”。
sudo -u kafka nano /opt/kafka/config/connect-standalone.properties
取消注释“plugin.path”行并将值更改为插件的库目录“ /opt/kakfa/libs ”。
plugin.path=/opt/kafka/libs
完成后保存文件并退出编辑器。
接下来,运行以下命令创建一个新文件“ /opt/kafka/test.txt ”,该文件将用作 Kafka 流的数据源。
sudo -u kafka echo -e "Test message from file\nTest using Kafka connect from file" > /opt/kafka/test.txt
现在运行以下命令,使用配置文件connect-file-source.properties和connect-file-sink.properties在独立模式下启动 Kafka Consumer。
此命令和配置是 Kafka 数据流的默认示例,其中包含您刚刚创建的源文件test.txt,此示例还将自动创建一个新主题“connect-test”,您可以通过 Kafka 控制台消费者访问该主题。
cd /opt/kafka
sudo -u kafka /opt/kafka/bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
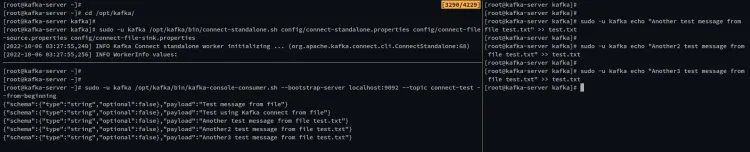
现在,打开另一个终端会话并运行以下命令以启动 Kafka 控制台消费者。此外,将主题指定为“connect-test”。您将看到来自文件“ test.txt ”的消息。
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
现在您可以更新文件test.txt,新消息将在 Kafka 控制台消费者上自动处理和流式传输。
运行以下命令以使用新消息 更新文件test.txt.
sudo -u kafka echo "Another test message from file test.txt" >> test.txt
在以下输出中,您可以看到当文件test.txt发生更改时,Kafka 会自动处理新消息。您现在已经完成了 Kafka connect 插件的基本用法,通过文件流式传输消息。
结论
通过本指南,您了解了如何在 Rocky Linux 系统上安装 Apache Kafka,您还了解了用于生成和处理消息的 Kafka Producer Console 以及用于接收消息的 Kafka Consumer 的基本用法,最后,您还学习了如何启用 Kafka 插件并使用 Kafka Connect 插件从文件实时流式传输消息。
![[附源码]java毕业设计基于学生信息管理系统](https://img-blog.csdnimg.cn/35e84dc086914025a51641038857d45f.png)
及结构体长度及占用空间的一些特性说明和测试](https://img-blog.csdnimg.cn/c58c0b8685fc4747aab6b85993271712.png)