数据处理
用户数据处理
用户数据一行
第一条数据是: 1::F::1::10::48067
- 首先,读取用户信息文件中的数据:
- 接下来把用户数据的字符串类型的数据转成数字类型,并存储到字典中,实现如下:
- 代码如下:
# 解压数据集
!unzip -o -q -d ~/work/ ~/data/data19736/ml-1m.zipimport numpy as np
def get_usr_info(path):
# 性别转换函数,M-0, F-1
def gender2num(gender):
return 1 if gender == 'F' else 0
# 打开文件,读取所有行到data中
with open(path, 'r') as f:
data = f.readlines()
# 建立用户信息的字典
use_info = {}
max_usr_id = 0
#按行索引数据
for item in data:
# 去除每一行中和数据无关的部分
item = item.strip().split("::")
usr_id = item[0]
# 将字符数据转成数字并保存在字典中
use_info[usr_id] = {'usr_id': int(usr_id),
'gender': gender2num(item[1]),
'age': int(item[2]),
'job': int(item[3])}
max_usr_id = max(max_usr_id, int(usr_id))
return use_info, max_usr_id
usr_file = "./work/ml-1m/users.dat"
usr_info, max_usr_id = get_usr_info(usr_file)
print("用户数量:", len(usr_info))
print("最大用户ID:", max_usr_id)
print("第1个用户的信息是:", usr_info['1'])电影数据处理

- 统计电影ID信息。
- 统计电影名字的单词,并给每个单词一个数字序号。
- 统计电影类别单词,并给每个单词一个数字序号。
- 保存电影数据到字典中,方便根据电影ID进行索引。
-
电影类别和电影名称定长填充,并保存所有电影数据到字典中
def get_movie_info(path):
# 打开文件,编码方式选择ISO-8859-1,读取所有数据到data中
with open(path, 'r', encoding="ISO-8859-1") as f:
data = f.readlines()
# 建立三个字典,分别用户存放电影所有信息,电影的名字信息、类别信息
movie_info, movie_titles, movie_cat = {}, {}, {}
# 对电影名字、类别中不同的单词计数
t_count, c_count = 1, 1
# 初始化电影名字和种类的列表
titles = []
cats = []
count_tit = {}
# 按行读取数据并处理
for item in data:
item = item.strip().split("::")
v_id = item[0]
v_title = item[1][:-7]
cats = item[2].split('|')
v_year = item[1][-5:-1]
titles = v_title.split()
# 统计电影名字的单词,并给每个单词一个序号,放在movie_titles中
for t in titles:
if t not in movie_titles:
movie_titles[t] = t_count
t_count += 1
# 统计电影类别单词,并给每个单词一个序号,放在movie_cat中
for cat in cats:
if cat not in movie_cat:
movie_cat[cat] = c_count
c_count += 1
# 补0使电影名称对应的列表长度为15
v_tit = [movie_titles[k] for k in titles]
while len(v_tit)<15:
v_tit.append(0)
# 补0使电影种类对应的列表长度为6
v_cat = [movie_cat[k] for k in cats]
while len(v_cat)<6:
v_cat.append(0)
# 保存电影数据到movie_info中
movie_info[v_id] = {'mov_id': int(v_id),
'title': v_tit,
'category': v_cat,
'years': int(v_year)}
return movie_info, movie_cat, movie_titles
movie_info_path = "./work/ml-1m/movies.dat"
movie_info, movie_cat, movie_titles = get_movie_info(movie_info_path)
print("电影数量:", len(movie_info))
ID = 1
print("原始的电影ID为 {} 的数据是:".format(ID), data[ID-1])
print("电影ID为 {} 的转换后数据是:".format(ID), movie_info[str(ID)])
print("电影种类对应序号:'Animation':{} 'Children's':{} 'Comedy':{}".format(movie_cat['Animation'],
movie_cat["Children's"],
movie_cat['Comedy']))
print("电影名称对应序号:'The':{} 'Story':{} ".format(movie_titles['The'], movie_titles['Story']))评分数据处理
评分数据格式为UserID::MovieID::Rating::Timestamp,如下图。
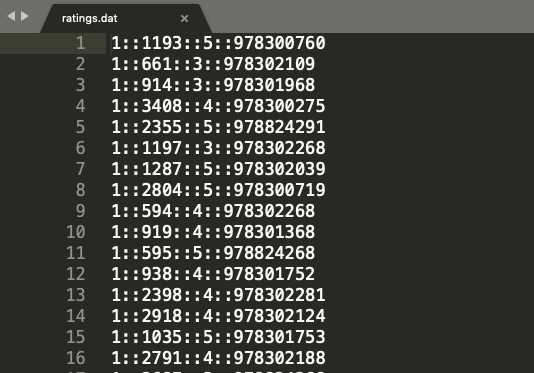
将数据直接存到字典中。
def get_rating_info(path):
# 打开文件,读取所有行到data中
with open(path, 'r') as f:
data = f.readlines()
# 创建一个字典
rating_info = {}
for item in data:
item = item.strip().split("::")
# 处理每行数据,分别得到用户ID,电影ID,和评分
usr_id,movie_id,score = item[0],item[1],item[2]
if usr_id not in rating_info.keys():
rating_info[usr_id] = {movie_id:float(score)}
else:
rating_info[usr_id][movie_id] = float(score)
return rating_info
# 获得评分数据
#rating_path = "./work/ml-1m/ratings.dat"
rating_info = get_rating_info(rating_path)
print("ID为1的用户一共评价了{}个电影".format(len(rating_info['1'])))海报图像读取