Robust Speech Recognition via Large-Scale Weak Supervision
- 前言
- Abstract
- 1. Introduction
- 2. Approach
- 2.1. Data Processing
- 2.2. Model
- 2.3. Multitask Format
- 2.4. Training Details
- 3. Experiments
- 3.1. Zero-shot Evaluation
- 3.2. Evaluation Metrics
- 3.3. English Speech Recognition
- 3.4. Multi-lingual Speech Recognition
- 3.5. Translation
- 3.6. Language Identification
- 4. Analysis and Ablations
- 4.1. Dataset Scaling
- 4.2. Model Scaling
- 4.3. Multitask and Multilingual Transfer
- 5. Related Work
- 6. Conclusion
- 阅读总结
前言
语音领域的又一力作,来自OpenAI团队,中稿于ICML 2023。本篇文章剑走偏锋,不同于当前火热的自监督预训练 ,而是采用大规模的弱监督预训练,特别适用于语音场景,这也为启发了广大的AI科研人员,做研究不能一股脑蹭热度,而是要根据特定的场景对症下药。
| Paper | https://proceedings.mlr.press/v202/radford23a/radford23a.pdf |
|---|---|
| Code | https://github.com/openai/whisper |
| From | ICML 2023 |
Abstract
本文探索了语音处理系统通过简单训练从而处理互联网大量音频转录的能力。作者在68万小时的多语言多任务的数据上进行预训练,得到的模型无需微调就可以和完全监督相竞争,接近人类的性能。
1. Introduction
Wav2Vec 2.0等无监督预训练工作推动了语音识别领域的进步,它们高效利用了无标注的大型数据集,规模甚至达到了一百万小时,远比监督数据集的1000小时多。这些方法在标准benchmark上微调达到了SOTA。
然而上面的方法基于无监督预训练,缺乏相应映射的解码器,需要微调才能执行语音识别等任务。微调过程的复杂性限制了这些模型的可用性,并且针对特定数据集的微调泛化性能不佳。语音识别系统的目标应该是在广泛的环境中即插即用,而不需要针对特定的部署对解码器进行微调。
现有的监督学习方法虽然在多个不同的数据集上跨域训练,表现更高的鲁棒性,但是监督数据集的规模限制了该方法的发展。
因此最近有工作努力创建更大的弱监督数据集,通过对质量和数量上的权衡来扩大数据集,从而显著提高模型的鲁棒性和泛化性。但是规模仍然难以和百万小时的无监督数据集相匹敌。
本文作者将弱监督数据集扩大到了68万小时,使用的方法称作Whisper,作者展示了其强大的泛化能力。此外,除了数据的规模。作者还将工作侧重语言的多样性和任务的多样性,并发现对于足够大的模型,多语言多任务训练会进一步提升模型的性能。
2. Approach
2.1. Data Processing
依赖sequence-to-sequence模型学习转录映射的能力,作者训练Whisper直接预测原始文本,无需任何标准化和预处理,简化了转录步骤。
作者从互联网上收集了大量不同环境的音频文本对数据,虽然提高了模型的鲁棒性,但是低质量的音频对训练没好处,因此作者对收集的数据采用了如下的过滤方法:
- 启发式方法过滤机器生成的字幕。
- 应用音频语言检测器,确保声音和字母是相同的语言(除了英语)。
- 训练时汇总数据错误率并排序,删除低质量的数据。
作者将音频切分为三十秒的片段进行训练。
2.2. Model
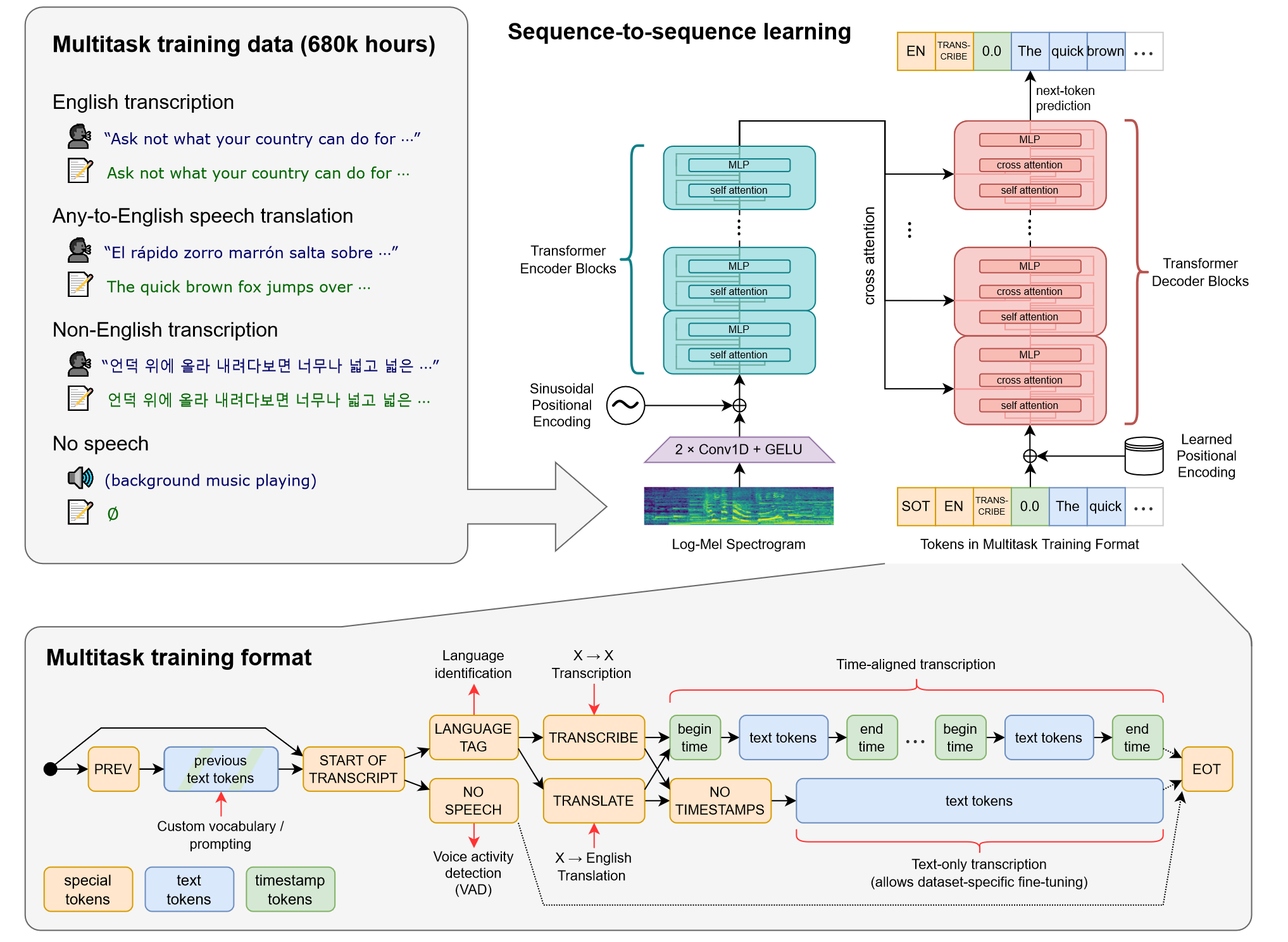
模型采用原始的Transformer,以证明性能的提升只受到监督数据规模的影响。所有的音频重采样到16000Hz,并且在25ms的窗口上以10ms的步幅计算80维通道的对数梅尔频谱图表示。此外,对输入也进行了特征归一化。为了减小计算的开销,编码器输入采用了两个宽度为3的卷积层和GELU激活函数,对输入进一步压缩,然后将正弦位置编码嵌入到输入中,再应用到编码器模块。解码器使用可学习的位置编码,并对输入的文本绑定特殊的标记。tokenizer采用了GPT-2的字节级BPE,并为多语言模型调整了词表。
这里很有意思的一点是为什么要对输入进行压缩,而不是直接采用50ms的窗口,因为当采用50ms的窗口时,有时候会超过人说话的频率,可能会导致精度降低。
2.3. Multitask Format
一个完整的语音处理系统还涉及其它组件,如语音活动检测,人物检测和逆文本归一化等。这些组件如果能够整合到一个模型中将大大简化相关工作。实际上,对于同一输入音频信号只需要进行相应的任务规范,就可以执行多个不同的任务。作者将特定的任务信息和语音信息指定为输入模型的序列。此外,还会有一定概率将之前语音片段添加到当前语音片段序列的上下文中,帮助模型学习通过上下文解决不明确的音频。
作者采用<|startoftranscript|>标记来指示预测的开始,整体流程如下:
- 首先判断是否有声音,执行语音活动检测。
- 接着预测语言类型,并给定相应token。
- 下一个token使用
<|transcribe|>或<|translate|>标记转录还是翻译任务,<|notimestamps|>指定是否用时间戳。 - 最后添加
<|EOT|>标记表明任务结束。
2.4. Training Details
作者训练了从39M到1550M一系列大小的模型,并且没有采用任何数据增强或者正则化。在初始开发的过程中,作者观察到Whisper倾向于转录看似合理但是错误的说话者的预测,这是因为许多字幕包含说话者的姓名,为了避免这种情况,作者对Whisper进行了不包含说话者数据的微调。
3. Experiments
3.1. Zero-shot Evaluation
Whisper的初衷就是无需微调就能在各种场景产生高质量结果。为了验证这个能力,作者在现有的语音数据集上来测试Whisper零样本性能。
3.2. Evaluation Metrics
语音领域通常根据单词错误率(WER)指标来评估系统。但是WER会惩罚输出和参考的所有差异,甚至不影响结果的格式差异。这对Whisper很不友好。为此,作者对输出进行文本标准化处理,尽量减少WER惩罚。
3.3. English Speech Recognition
虽然语音领域在2015年就达到了人类的水平(Deep Speech 2),并且当前的LibriSpeech又将当时SOTA WER下降了73%,但是在不同的场景下,仍然与人类有巨大的差距。
作者推测差距的原因在于测试集混淆了二者的训练方式。机器学习模型在分布内的数据集上进行训练后评估的,而人类是在分布外的泛化表现。而Whisper模型和人类的训练方式相同,都是在广泛多样的音频上训练,在零样本下评估。为了量化Whisper和人类之间的评估差异,作者测试了总体稳健性和有效稳健性,用于衡量分布内与分布外数据集之间预期性能的差异。结果如下图和下表所示:
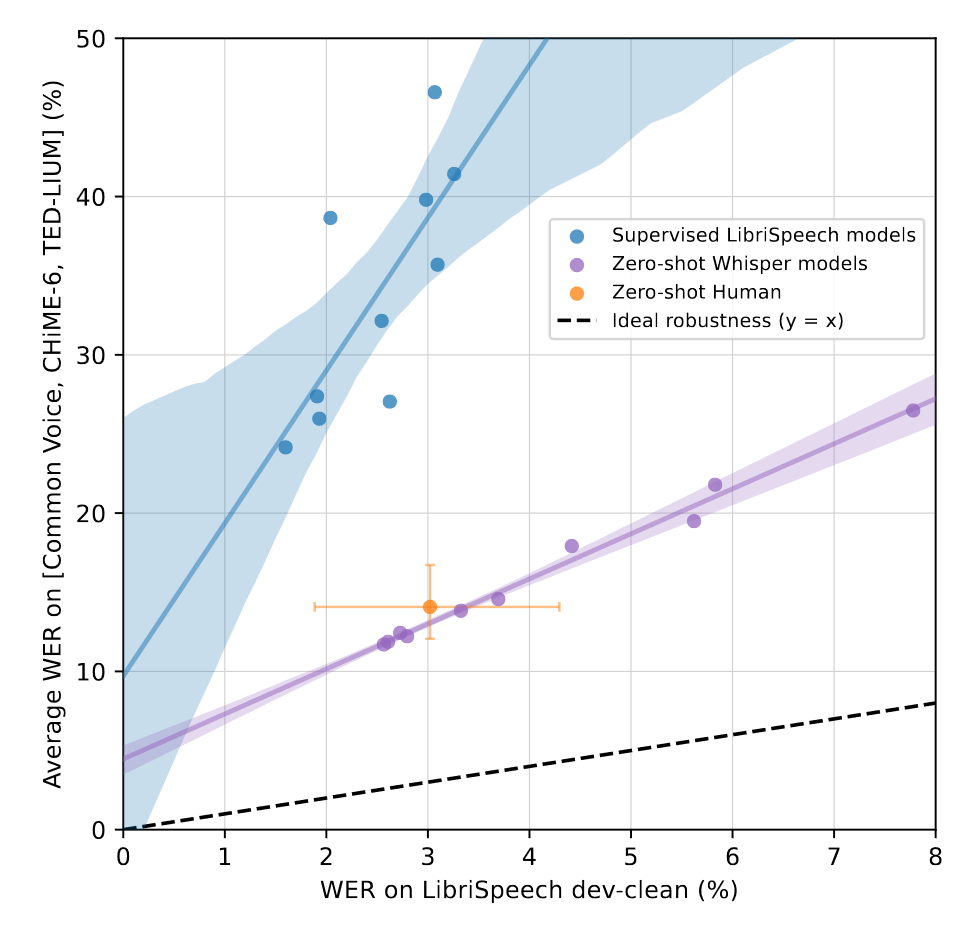

尽管Whisper在LibriSpeech上表现不显著,但是它与其它监督的LibriSpeech模型相比具有很好的鲁棒性,在其它数据集上远远优于所有基线模型,并且在其它数据集上也和人类的表现相匹配。为了进一步量化鲁棒性,上表展示了Whisper和其它模型在其它数据集上的表现,Whisper将误差下降了55.2%。这一发现强调了零样本和分布外评估的重要性,因为先前的模型虽然在单个数据集上表现好,但是泛化性能差,其能力被夸大了。
3.4. Multi-lingual Speech Recognition
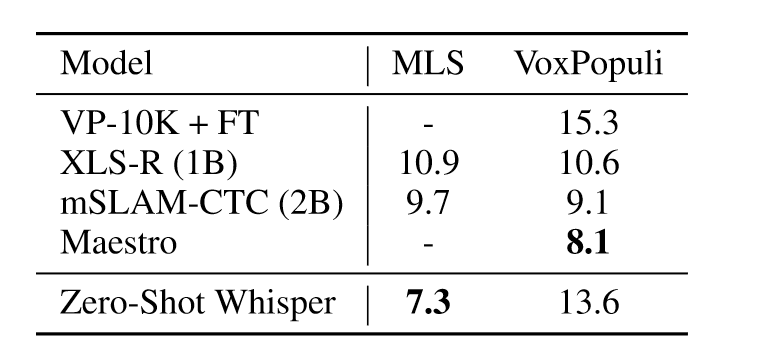
Whisper在多语言任务上的表现如上表所示,在MLS上展现出优越的性能,但是在VoxPopuli上性能不佳,可能原因是VoxPopuli数据集训练数据量是MLS的十倍,其它模型可以经过很好的微调从而提升性能。
为了更广泛研究Whisper的性能,作者报告了Fleurs数据集上的性能,研究不同语言训练数据量与零样本性能的关系:
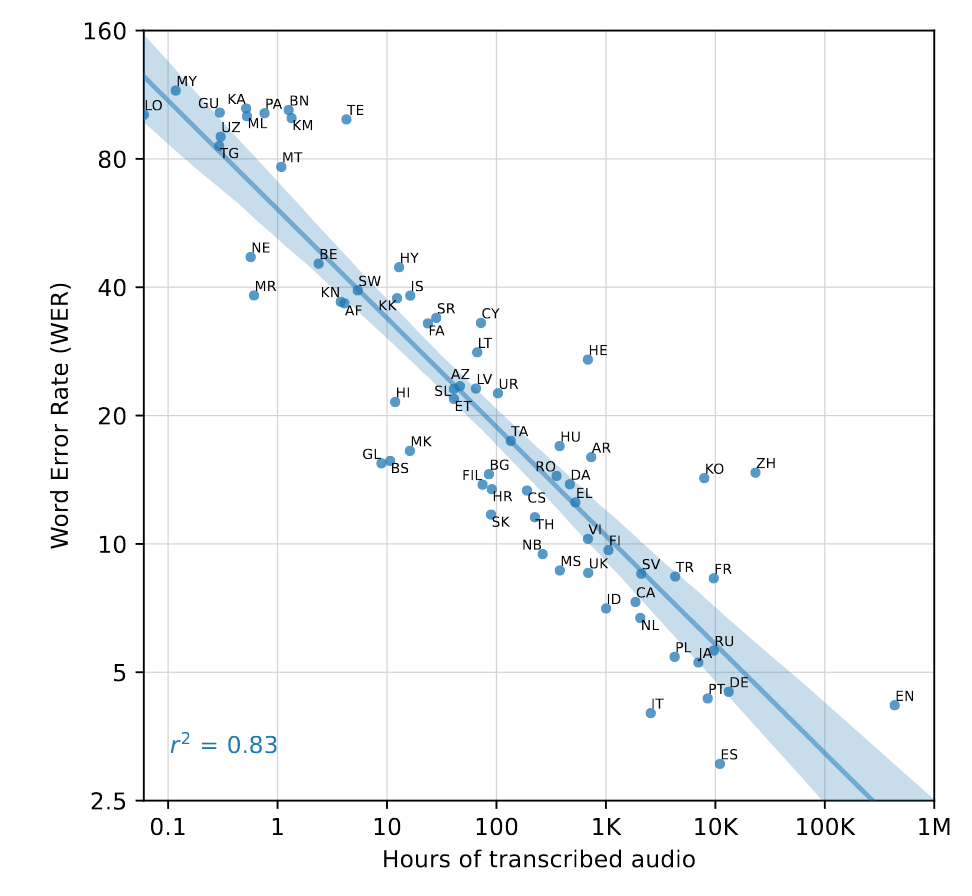
作者发现单词错误率的对数和每种语言的训练数据量的对数之间存在0.83的强平方相关,即数据量每增加16倍,WER就会减半,此外部分语言由于和印欧语言体系不同,导致结果远不如预期,如HE,TE,ZH和KO。根本原因在于字节级BPE tokenizer与这些语言不匹配。
3.5. Translation

作者在CoVoST2数据集上评估模型的翻译能力,由于Whisper的评估是零样本,因此在该数据集上低资源分组表现出色,但是在高资源数据上没有明显提升。
3.6. Language Identification
作者在Fleurs上评估模型的语言识别能力,64.5%的零样本性能比当前mSLAM-CTC 2B的77.7%低了13.6%,没有竞争力。这是因为Whisper不包含Fleurs上20种语言的训练数据。在有的语言上,准确率达到了80.3%。
4. Analysis and Ablations
4.1. Dataset Scaling
为了衡量数据的大小对Whisper性能的影响,作者在中型模型上对不同规模的数据进行了评估。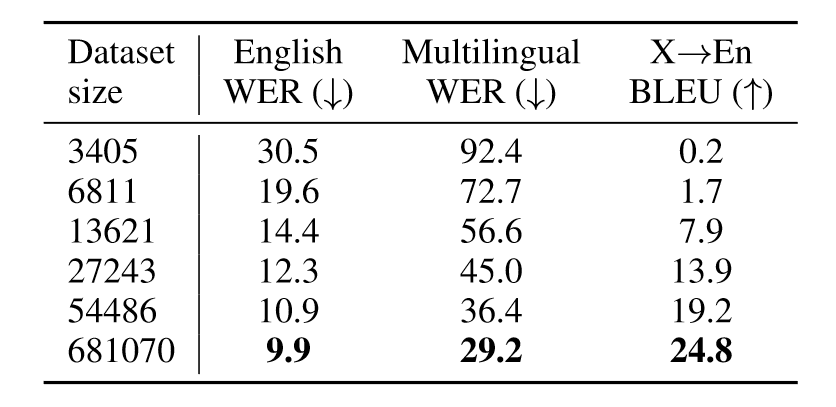
可以看到,数据集大小的增加会提升所有任务的性能,虽然不同任务的性能增幅不同。
4.2. Model Scaling
作者还做了模型大小的分析。
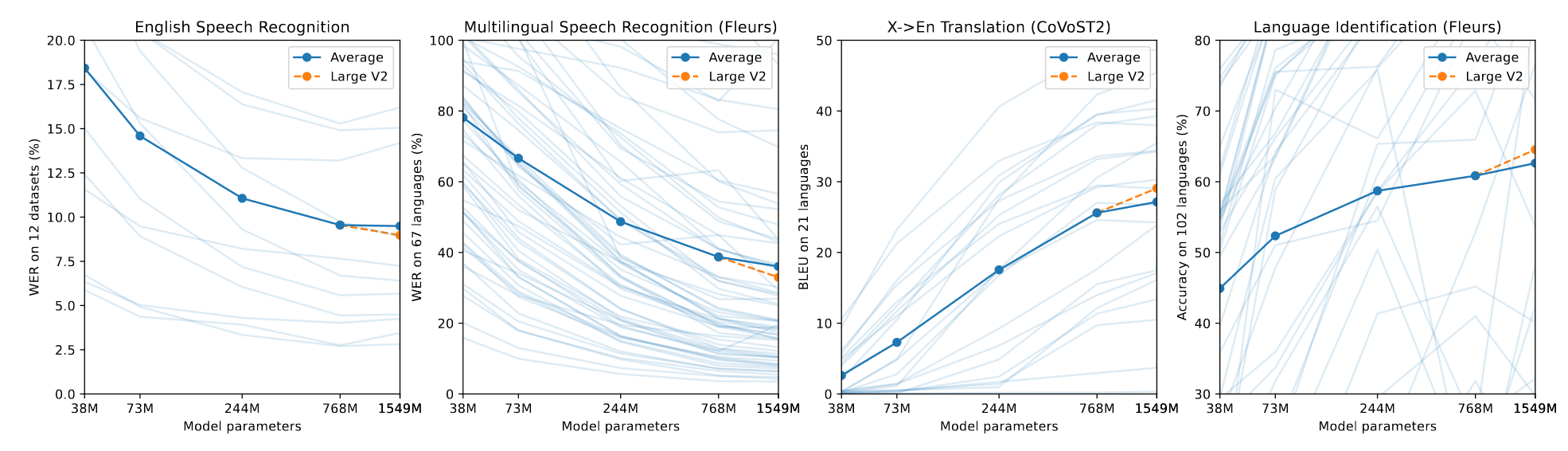
基本上所有任务都随着模型大小的增加而不断提高。
4.3. Multitask and Multilingual Transfer
大一统的模型可能会导致模型的性能不如单任务模型。为此作者将仅英语训练模型和Whisper进行零样本英语语音识别的比较。
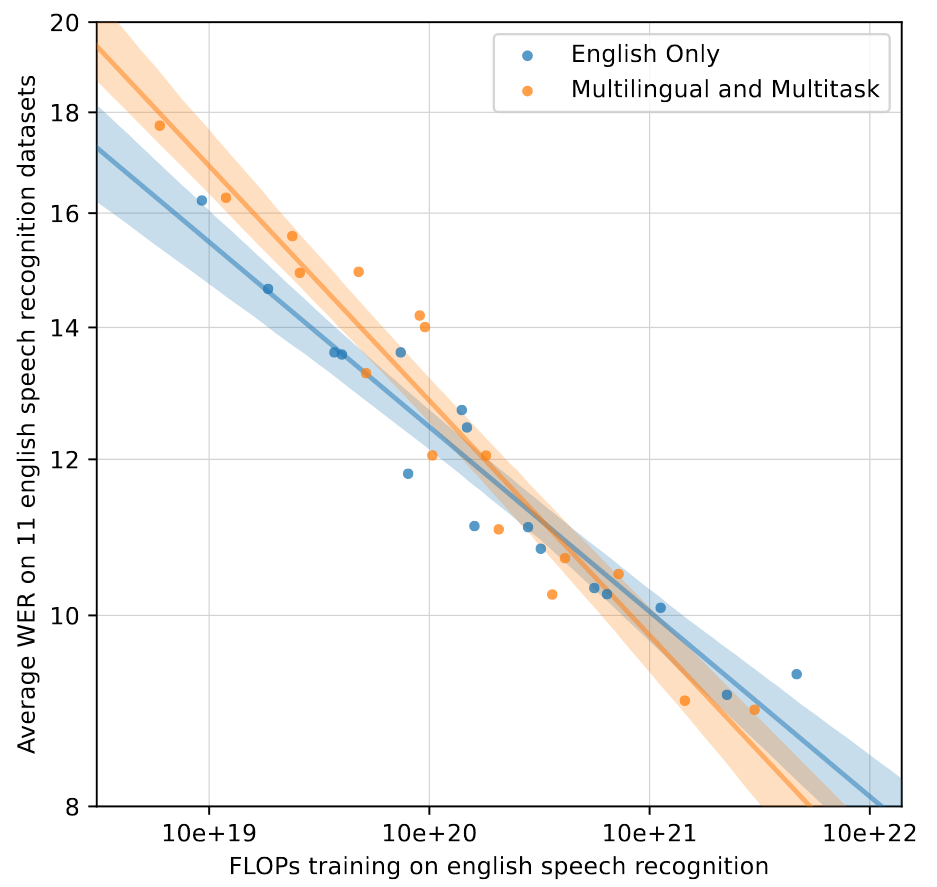
可以看到,在中等计算量的小模型上存在着负迁移,但是多任务和多语言模型的扩展性更好,随着计算量增大其性能超过单任务模型,表明其具有积极的迁移性能。
5. Related Work
略。
6. Conclusion
Whisper的工作表明,在语音领域,大规模的弱监督预训练一直没受到重视。虽然当前大规模无监督预训练是主流,但是在语音领域,显然大规模弱监督预训练可以解决更多的任务,并且具有良好的鲁棒性。
阅读总结
Whisper的工作方法简单,效果显著,虽然并没有公布弱监督训练数据集的具体内容,但是这样也从侧面反应,对于一些跨领域的任务,单单无监督预训练是远远不够的。正如第六节总结部分所言,Whisper的工作表表明,在语音领域大规模的弱监督预训练一直没受到重视,我想很多领域也一定是同样的情况。
我在之前ViT和MAE工作的博客中曾经说过,大规模的监督训练只是做着简单的分类任务,因此不能像无监督预训练那样很好学习到当前领域数据的特征信息。当然这肯定不是错误的言论,对于MAE来说,进行过大规模无监督预训练后,还是需要在下游任务上微调才能解决相应任务,远远不如零样本模型来的方便。在语音领域,Whisper之所以成功我认为还是预训练任务并不是纯粹的分类任务,它是需要解码器进行生成的,再加上多任务和大规模弱监督数据的加持,因此性能优于无监督预训练微调的模型。但是Whisper应该还有很多的改进空间:、
- 大规模的弱监督数据进一步清洗,除了启发式或者规则方法,还可以训练模型来清洗。
- Whisper可以先在大规模的无监督语音数据上进行预训练,相信一定会学到更多语音的特征。
此外,本文的模型图让我印象深刻,简洁明了,思路清晰,让人一目了然,非常值得学习借鉴。