前言
代码 论文
# Mask-rcnn 算法在 torch vision 中有直接实现,可以直接引用使用在自己的工作中。
import torchvision
model = torchvision.models.detection.maskrcnn_resnet50_fpn(weights=MaskRCNN_ResNet50_FPN_Weights.DEFAULT)
Mask R-CNN(Mask Region-based Convolutional Neural Network)是一种用于目标检测和实例分割的深度学习模型,它是 Faster R-CNN 的扩展,同时可以生成目标的二进制掩码(mask),因此可以实现精确的实例分割。
\1. 骨干网络:Mask R-CNN通常使用骨干网络(如 ResNet)来提取图像特征。这些特征用于目标检测和分割任务。
\2. 区域建议网络(RPN):RPN 用于生成候选区域,它是 Faster R-CNN 中的组件,用于确定可能包含目标的图像区域。
\3. 目标检测:Mask R-CNN 使用区域建议来检测图像中的目标对象,通常通过分类和回归来确定每个目标的位置和类别。
\4. 实例分割:除了目标检测,Mask R-CNN 还生成每个检测到的目标的精确二进制掩码。这允许对目标进行精确的像素级分割。
\5. 多任务学习:Mask R-CNN 采用多任务学习的方法,通过同时训练目标检测和实例分割任务,从而提高模型的性能。
\6. ROI Pooling / ROI Align:用于从特征图中提取每个候选区域的特征,以供后续任务使用。
\7. 损失函数:Mask R-CNN 使用多个损失函数,包括分类损失、回归损失和分割损失,来训练模型。
一、maskrcnn介绍
总体框架
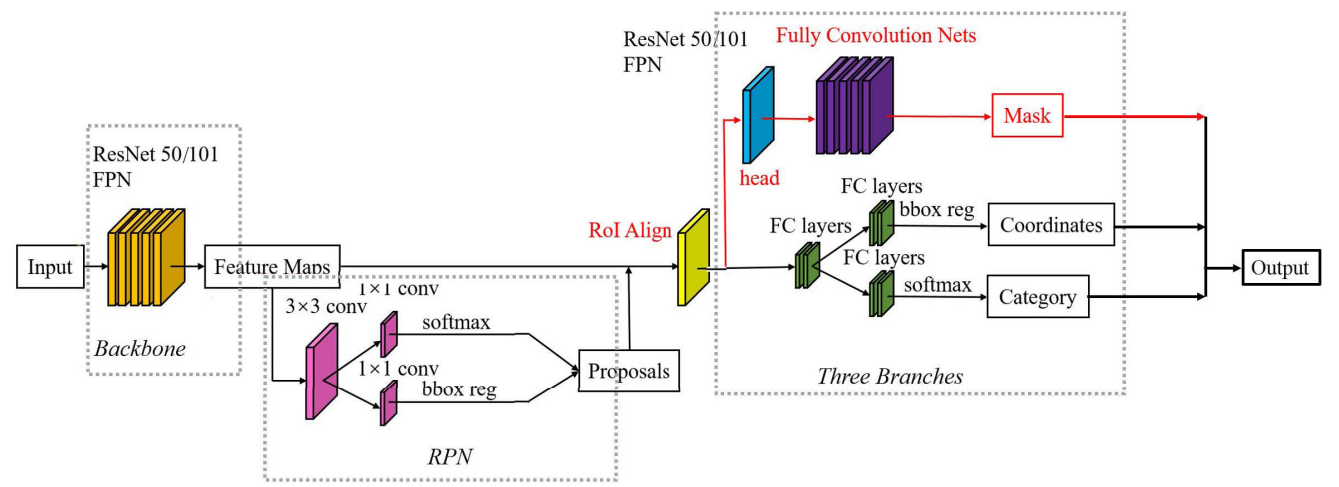
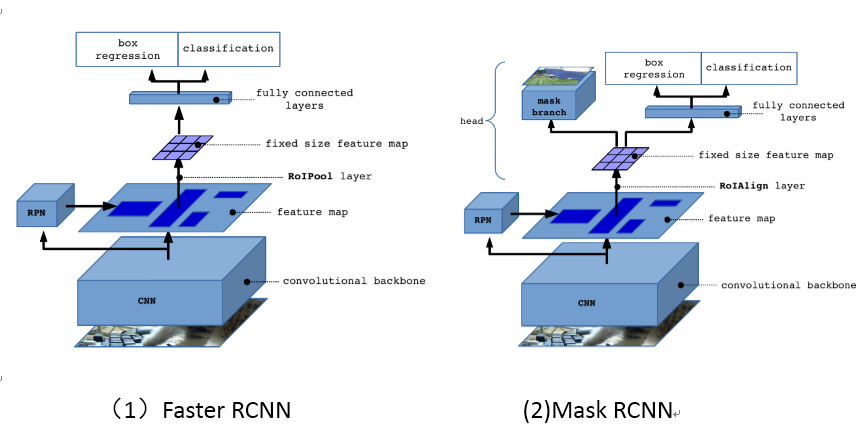
针对目标检测算法 Faster-RCNN 加入语义分割算法 FCN,使得完成目标检测的同时也得到语义分割的结果,算法对 Faster-RCNN 的一些细节做了调整,最终的组成部分是 RPN + ROIAlign + Fast-rcnn + FCN。所以要了解 Mask-RCNN 的细节就需要了解 RCNN、Fast-RCNN、Faster-RCNN 这一系列算法的实现过程。
主干结构(backbone)
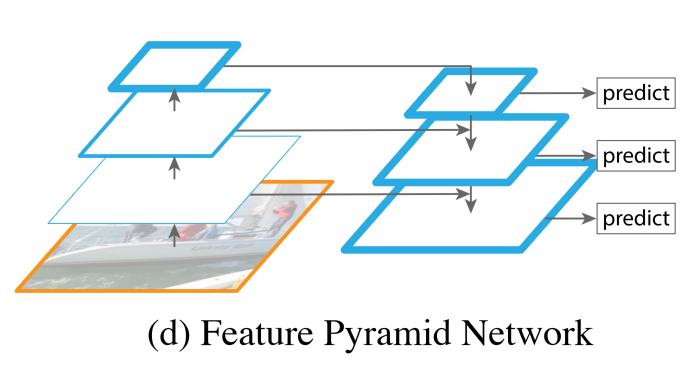
和前作 Faster RCNN 一样,Mask RCNN 的第一部分是一个标准的 CNN 卷积网络(ResNet50,ResNet101,ResNet50 + FPN,ResNet101 + FPN),目的用来提取图像中的信息。除此之外,Mask-RCNN 还使用了 FPN (Feature Pyramid Networks 特征金字塔网络) 来提升网络的性能。

可以看到第二种方法针对 Mask 使用了不同的 RoI,这样 Mask 使用的 RoI 输出大小更大,预测可以做的更精细。 另外,Mask 分支在训练和预测时也有一些小差异,训练网络时的目标是由 RPN 提供的(Proposal),但在预测时的目标是由其他两个分支(Faster-RCNN)提供的,这样做辅助提高了训练模型的能力以及预测的准确度(RPN 提供的类别都是准确的正样本但是完整边界不准确,而预测时 Faster-RCNN 提供的边界是准确的)。
FPN
多尺度特征融合,yolo提过
RPN
RPN(Region Proposal Network)的主要功能是产生物品检测框。相对于传统方法,RPN生成检测框的速度大大提高,这也是Faster RCNN/Mask RCNN的重要优势,能极快又准地实现预测.
RPN的核心操作是根据特征图按照一定规律生成一系列锚框(anchor box),假设特征图的尺寸为W×H,那么就生成W×H×k个锚框,即特征图上每个点生成k个锚框。一般根据原论文,k取9即选取9个锚框,这9个锚框中有三种形状长宽比分别为{1:1,1:2,2:1}以及三种面积尺度128²,256²,512²,对应生成3×3=9个锚框。
根据上述操作,我们生成了大量的锚框,忽略掉跨越边界的锚框后一般仍有几千至几万个,这些锚框对的候选框之间存在着大量的重叠,RPN采用非极大至抑制的方法,IoU设置为0.7,这样候选框数量大致可以减少到两千个。在这些锚框中进行初步筛选得到固定数量(256个)的锚框用于后续计算,为使得数据平衡,这些锚框中正样本与负样本(背景)的数量要大致相当。
在得到这些锚框后,RPN中还需要完成两项工作,首先判断这个锚框中是否存在待识别的物体,这是一个二分类问题,第二项工作是怎样调整锚框才能使得其和真实值更接近。观察整个RPN网络的具体结构,可以看到RPN网络可以分为两部分,分别用来解决这两个问题:计算分类误差损失以及边界框回归损失。第一部分的输出是一个大小为W×H×k×2的矩阵,只分类锚框中有物品或者是只有背景的概率,故每个锚框有两个输出。第二部分的输出是大小为W×H×k×4的矩阵,用来判断原始锚框需要做的平移以及缩放,这里的损失计算函数与整个模型的计算方式相同,具体细节写在了边界框回归损失部分。
ROI
ROI 意为 Region of Interest 即感兴趣的区域。从 Mask-RCNN 的架构可以看出,ROI 有两部分输入,第一部分是由 backbone 生成的特征图像(feature map),另一部分是由 RPN 生成的检测框 (proposal),ROI 这一部分的主要职责就是把生成的检测框对应到特征图像上。
RoIPooling(老方法)
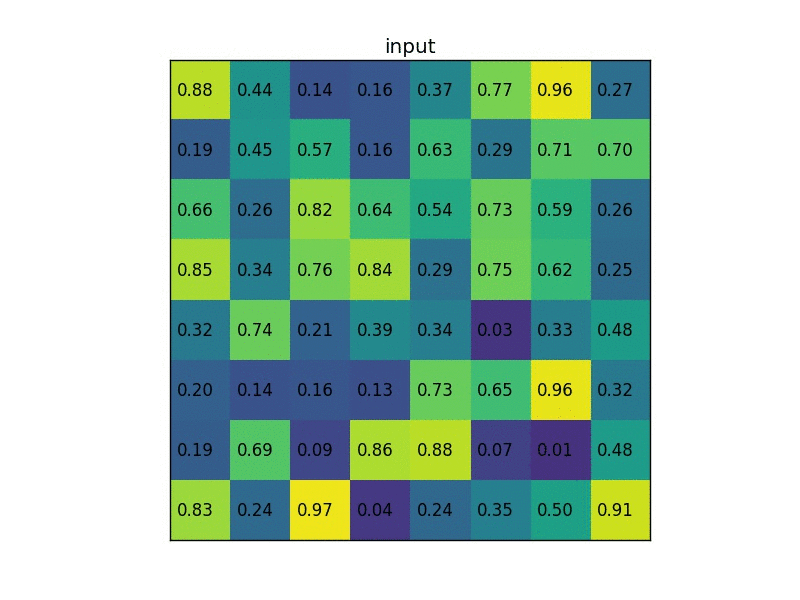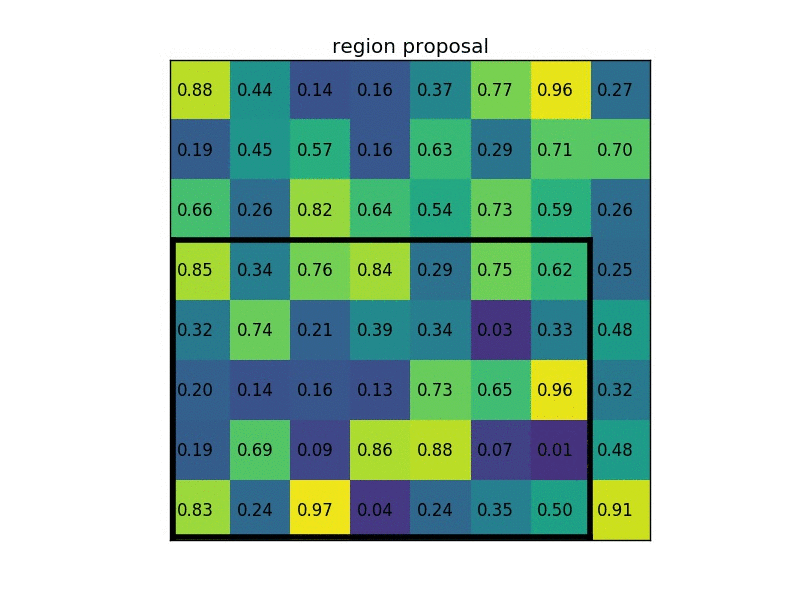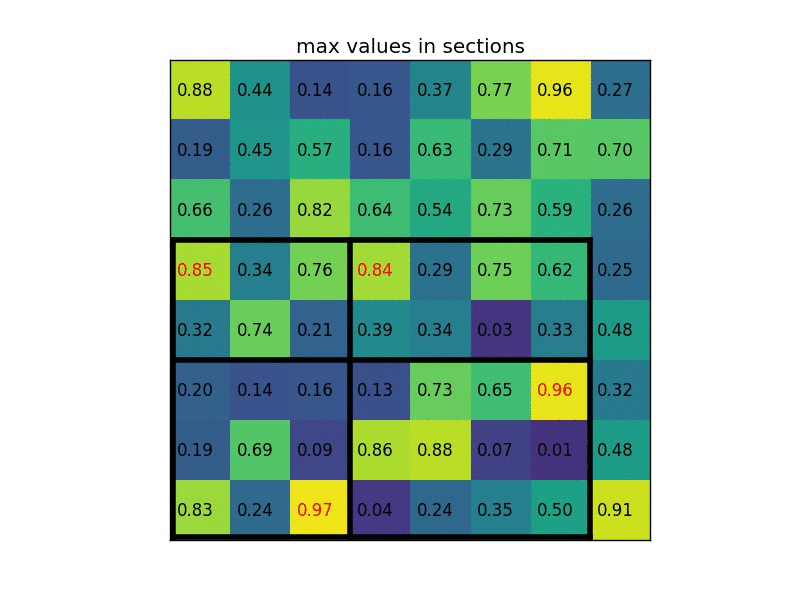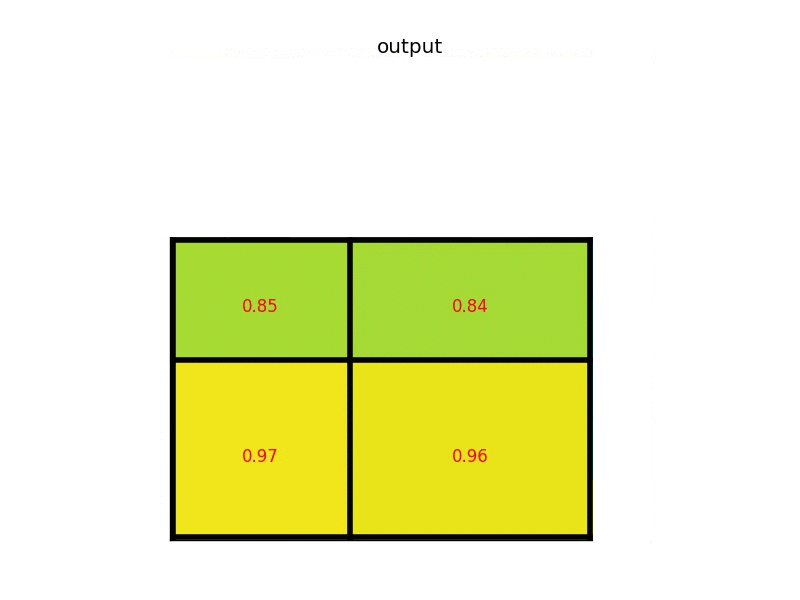
RoIPooling 是 Faster-RCNN 提取特征的模块。整个 RoIPooling 可以分成前后两步,第一步将候选框缩放到特征层上,对于非整数的情况四舍五入取整。第二步操作类似 MaxPooling,将刚得到的区域缩放到一个预定义的大小(比如7x7),当无法整除时各部分大小再次做取整操作,每个区域内选取最大值作为输出。下面是在一个8x6特征图上选取输出大小2x2为的动图示例 。
RoIAlign(改进)
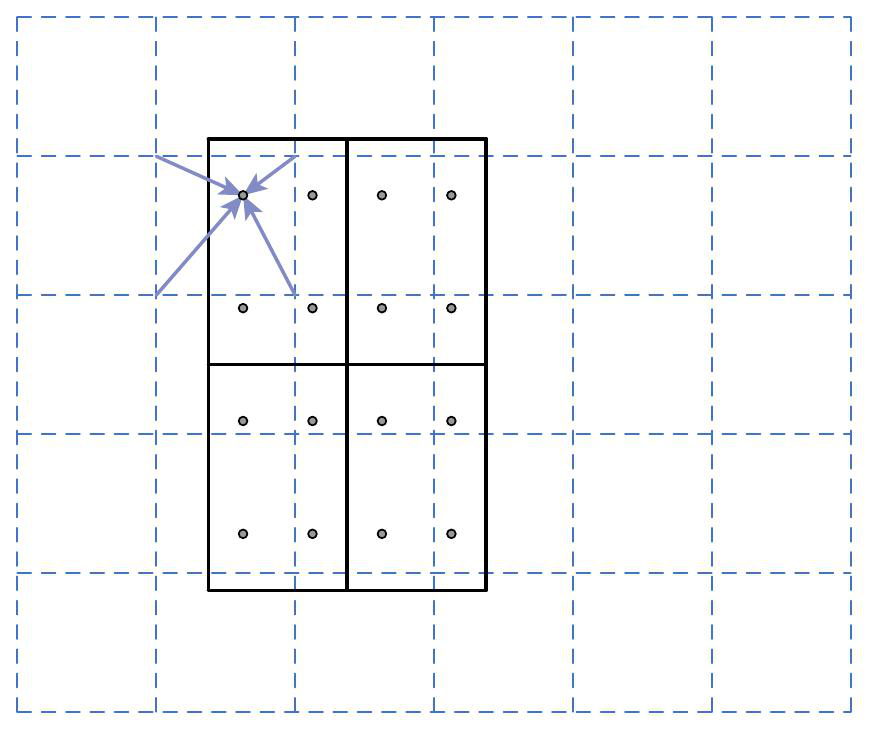
RoIAlign 是 Mask-RCNN 对 RoIPooling 的改进,也是用于提取特征,主要是针对 RoIPooling 中的取整操作带来的误差 (misalignment)。ROIPooling 主要有两部分取整带来的误差,第一个是候选框对应到特征层上时的取整,第二个是区域缩放时不能整除时对边界的取整。RoIAlign 主要就是对这两个地方进行优化,对于没有落在真实像素点的计算,不再取整改用最近的四个点进行双线性插值。上面是 Mask-RCNN 原论文中 RoIAlign 的示意图,保留每一步的计算精度不取整直至最后,利用双线性插值计算每个子区域四个点,比较出最大值作为这一部分的输出(最终的采样结果对采样点位置以及采用点个数并不敏感,所以一般都直接使用四个采样点)。
ProposalLayer层
对20W+候选框进行过滤,先按照前景得分排序;取6000个得分高的,把之前得到的每个框回归值都利用上;看总体图可知:将RPN网路的输出作为该模块的输入,首先利用rpn_bbox对anchors进行第一次修正,得到ROI并删除其中的一部分超界的ROI。接着,对剩下的ROI进行score排序,保留其中预测为前景色概率大的一部分。最后,利用NMS获得最终的RP。
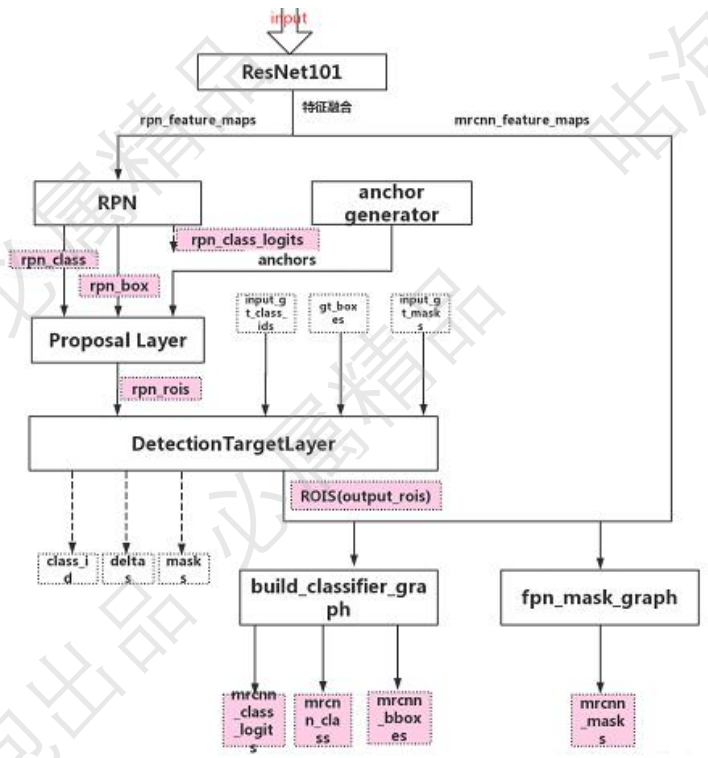
DetectionTargetLayer
1.之前得到了2000个ROI,可能有pad进来的(0充数的)这些去掉
2.有的数据集一个框会包括多个物体,这样情况剔除掉
3.判断正负样本,基于ROI和GT,通过IOU与默认阈值0.5判断
4.设置负样本数量是正样本的3倍,总数默认400个
5.每一个正样本(ROI),需要得到其类别,用IOU最大的那个GT
6.每一个正样本(ROI),需要得到其与GT-BOX的偏移量
7.每一个正样本(ROI),需要得到其最接近的GT-BOX对应的MASK
8.返回所有结果,其中负样本偏移量和MASK都用0填充
DetectionTargetLayer的输入包含了,target_rois, input_gt_class_ids, gt_boxes, input_gt_masks。其中target_rois是ProposalLayer输出的结果。首先,计算target_rois中的每一个rois和哪一个真实的框gt_boxes iou值,如果最大的iou大于0.5,则被认为是正样本,负样本是是iou小于0.5。选择出了正负样本,还要保证样本的均衡性,具体可以才配置文件中进行配置。最后计算了正样本中的anchor和哪一个真实的框最接近,用真实的框和anchor计算出偏移值,并且将mask的大小resize成28*28,这些都是后面的分类和mask网络要用到的真实的值。
损失函数
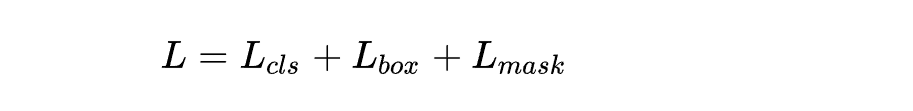
经过 RoI 处理后的特征矩阵一般有确定大小(原论文是7x7),将这样的矩阵展平经过一系列全链接层得到预测结果,对于 Mask-RCNN 网络有三个预测输出结构,分别输出预测预测的种类类别、预测物品的矩形展示框以及待预测物品的准确边界(像素级分类)。
类别损失
第一种输出种类类别的预测器非常简单,与普通的 CNN 模型后面类似,一系列全连接层激活函数层最后加一层 softmax 层预测各个种类的概率,损失函数使用的是多类别的交叉熵损失函数。
边界框回归损失
第二部分损失是用来物品边界框回归器用来计算边界框的损失。
Mask 损失
第三部分损失是物品准确边界的计算损失。在这一部分中, Mask-RCNN 中选取了 FCN 算法作为 Mask 的预测方法。FCN 算法可以对任意大小的矩阵做像素级分类
总损失
其实 Mask-RCNN 的扩展性非常强,模型结构可以按照具体的问题进行调整,比如在关键点检测中,就可以像 Mask 分支一样再并联一个关键点检测分支。最后的整体误差损失是各个部分的损失加在一起,对于标准的 Mask-RCNN,总损失有 5 部分:类别误差、回归框误差、Mask 预测误差、RPN 类别误差损失、RPN 边界框误差损失,将这些误差损失求和就是整体误差,用来训练评估模型。