环境准备
阿里云个人认证后,可免费试用机器学习平台PAI,可提供适合大语言模型环境搭建的高配置服务器。
点击试用阿里云服务器
试用产品选择:选择交互式建模PAI-DSW
适合哪些场景
- 文章/知识库/帮助文档等的检索
- 基于现有知识库实现问答
- …
实践
Lang-Chain(ChatGLM)的搭建和测试
Lang-Chain(ChatGLM)为Lang-Chain系列0.1版本。旨在建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
本教程的实现过程包括加载文本->读取文本->文本分割->文本向量化->问句向量化->在文本向量中匹配出与问句向量最相似的Top k个答案->匹配出的文本作为上下文和问题一起添加到Prompt中->提交给LLM生成回答。
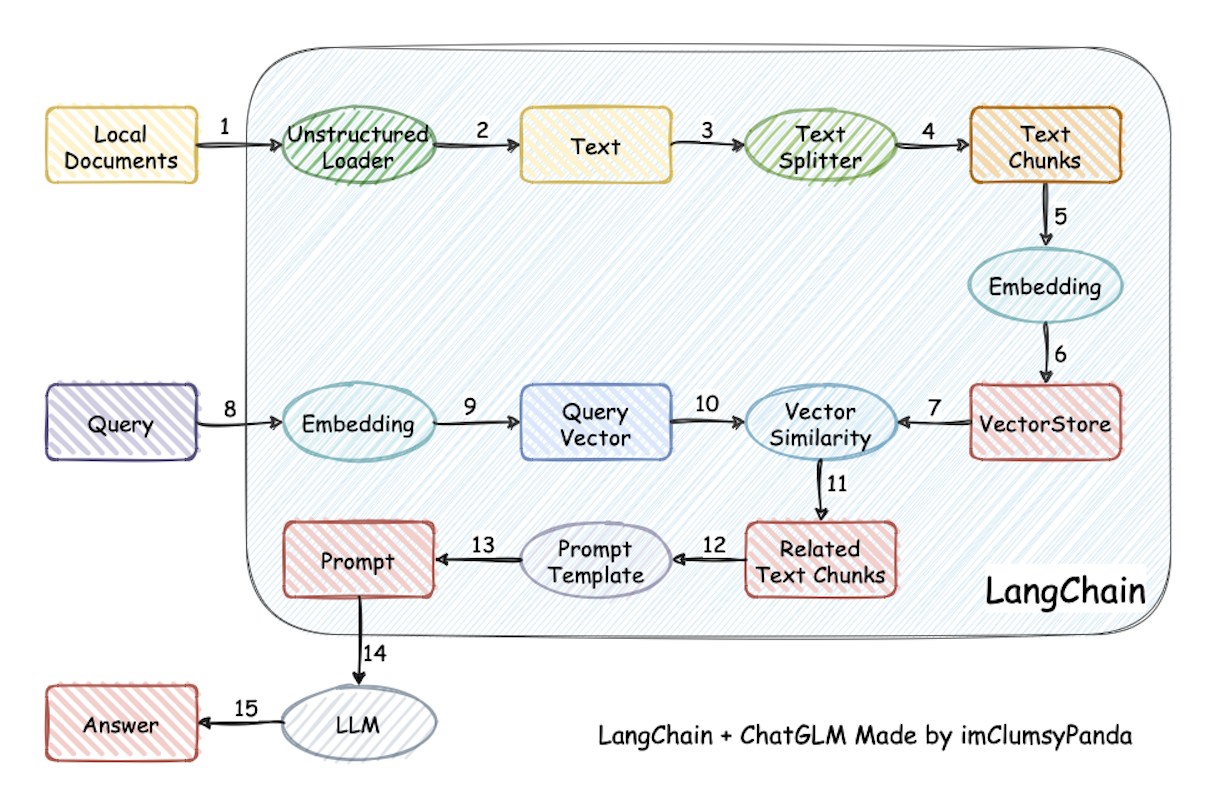
从文档处理角度来看,实现流程如下:
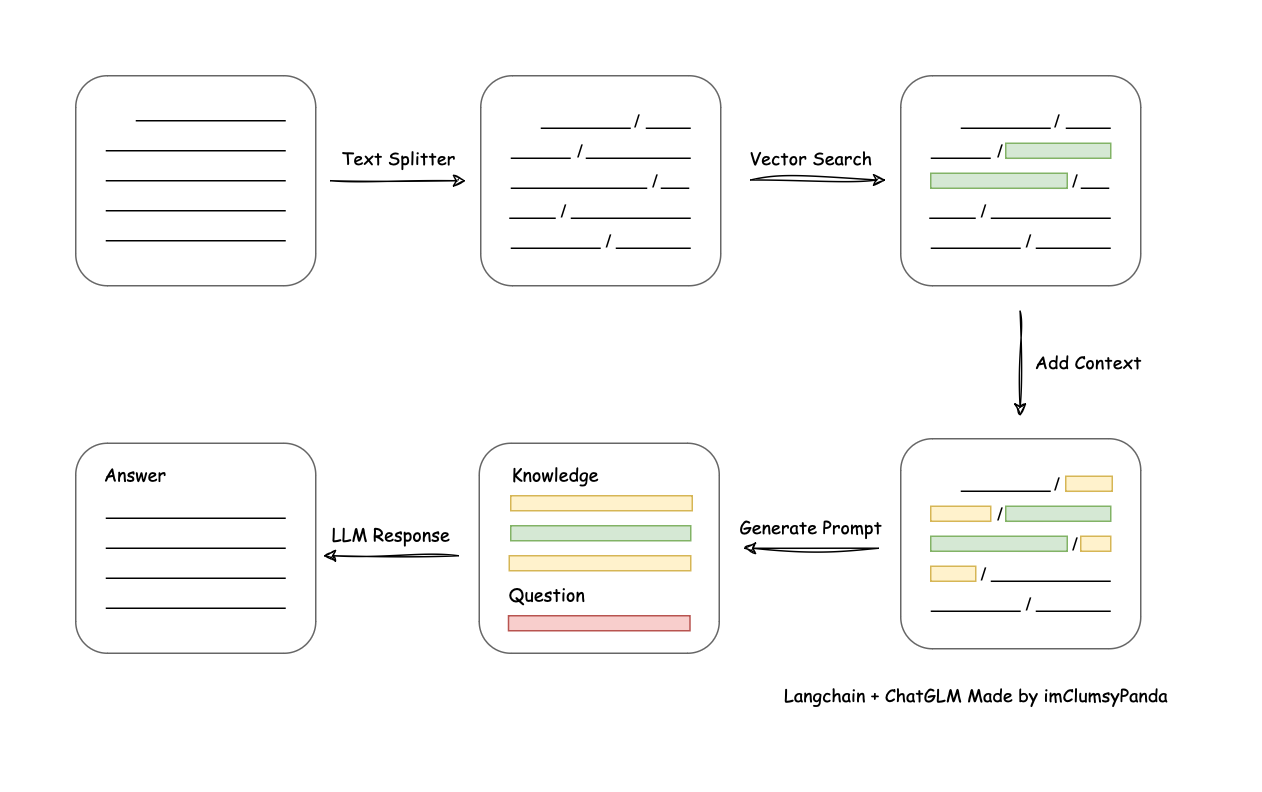
具体操作步骤可移步阿里云官方文档,按步骤操作下来即可。
基于LangChain的检索知识库问答
部署完成之后,我们就有了一个属于自己的智能问答库了。
使用体验如下:
- 本地知识库文件:没有固定格式,一段文字即可。
- 对于知识库已有的类似文本,模型可根据白话输入给出答复结果,准确度相对还较高,模型有时会自行进行扩展,其中扩展部分不一定准确。
- 对于从未有的问题,大模型会结合现有的内容给出答案,但也有可能是错误的答案。
- 对于准确性要求较高或规则性的结果,需要对输入、输出做二次处理。
初步查看,0.1版本的交互为websocket,没有发现openAPI等接口,和现有项目结合较为复杂,需要改造,所以需要部署0.2版本的ChatChat。
Lang-Chain(ChatChat)的搭建和测试
我们可以继续试用阿里云免费三个月的服务器,但是不采用其内置的模板进行搭建,我们自行搭建部署测试。
可在github上搜索Langchain-Chatchat,根据文档进行部署,如果网速不太好,可在码云gitee上搜索该关键字也可以。由于官方文档在实际的部署过程中,还碰到一些非技术上的问题,所以把自己部署的过程整理如下。
环境准备
阿里云免费试用的服务器已安装了基础的环境,我们只需要在此基础上进行后续的操作。
- Python 3.8 - 3.10 版本
python --version - 更新py库
pip3 install --upgrade pip - 拉取仓库
git clone https://github.com/chatchat-space/Langchain-Chatchat.git - 进入目录,安装全部依赖
cd Langchain-Chatchat
pip install -r requirements.txt
默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
下载模型至本地(重要)
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
但是大部分时间该网络不可达。
以本项目中默认使用的 LLM 模型 chatglm2-6b 与 Embedding 模型 m3e-base 为例。
-
下载chatglm2-6b
可结合如下两个地址进行下载:
https://aliendao.cn/models/THUDM/chatglm2-6b
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b%2F&mode=list
由于清华大学的镜像站中不全,所以小的文件可以在aliendao这个镜像站下载,大的文件在tsinghua镜像站下载,速度快。
通过wget命令下载到服务器的某一目录即可。 -
下载m3e-base
m3e-base模型目前发现只能在该镜像站下载https://aliendao.cn/models/moka-ai/m3e-base
不过该模型不是很大,1个小时左右即可下载完成,下载到服务器的某一目录即可。
设置配置项
- 将Langchain-Chatchat/configs目录下所有的*.example文件复制一份,并去掉.example
- 修改
configs中model_config.py配置文件,确认已下载至本地的 LLM 模型本地存储路径写在llm_model_dict对应模型的local_model_path属性中,如:"chatglm2-6b": "/Users/xxx/Downloads/chatglm2-6b",确认已下载至本地的 Embedding 模型本地存储路径写在embedding_model_dict对应模型位置,如:
"m3e-base": "/Users/xxx/Downloads/m3e-base"。
知识库初始化
如果您是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,或者之前的向量库没有开启 normalize_L2,需要以下命令初始化或重建知识库:$ python init_database.py --recreate-vs
一键启动 API 服务或 Web UI
python startup.py -a
其中:
- –all-webui 为一键启动 WebUI 所有依赖服务;
- –all-api 为一键启动 API 所有依赖服务;
- –llm-api 为一键启动 Fastchat 所有依赖的 LLM 服务;
- –openai-api 为仅启动 FastChat 的 controller 和 openai-api-server 服务;
若想指定非默认模型,需要用--model-name选项,示例:
python startup.py --all-webui --model-name Qwen-7B-Chat
各服务地址
-
startup 脚本用多进程方式启动各模块的服务,可能会导致打印顺序问题,请等待全部服务发起后再调用,并根据默认或指定端口调用服务(默认 LLM API 服务端口:127.0.0.1:8888,默认 API 服务端口:127.0.0.1:7861,默认 WebUI 服务端口:本机IP:8501)
-
服务启动时间示设备不同而不同,约 3-10 分钟,如长时间没有启动请前往 ./logs目录下监控日志,定位问题。
-
在Linux上使用ctrl+C退出可能会由于linux的多进程机制导致multiprocessing遗留孤儿进程,可通过shutdown_all.sh进行退出
我们可以在web ui界面上上传本地知识库,进行调试和测试。