实际开发中会遇到使用mysql分组统计,并且要求取每组数据的前1条数据
如下:需要根据模块分组,取每组中的前1条优质供应商数据,取前几条数据,其实会用到上篇文章中的排名函数row_number() 函数来实现,其含义可以点击此函数跳转查看上篇文章
select supplier_company_name,Logo,ModuleType, row_num
FROM(
select sr.supplier_company_name,bc.Logo,ss.ModuleType,
ROW_NUMBER() OVER (PARTITION BY ss.ModuleType ORDER BY sr.recommendation_order DESC) row_num
from supd_supply_recommend sr
INNER JOIN base_companyinfo bc ON sr.user_id=bc.UserId
INNER JOIN supd_supply_info ss on sr.user_id=ss.CreatorId AND ss.IsDeleted=0
-- WHERE ss.ModuleType='22'
WHERE sr.`Status`='Show'
GROUP BY ss.ModuleType,ss.CreatorId
) as t
WHERE row_num <2注意:逻辑就是先使用PARTITION BY根据模块类型ss.ModuleType分区(即分组,把相同的内容分成一组)、
根据推荐序号sr.recommendation_order排名(把PARTITION BY分区的一组数据根据某个字段进行排名),
最后根据模块类型和供应商用户id分组查询(GROUP BY ss.ModuleType,ss.CreatorId)--这个理在使用GROUP BY是为了过滤一些重复的内容,比如:上面语句去掉GROUP BY ss.ModuleType,ss.CreatorId
select sr.supplier_company_name,bc.Logo,ss.ModuleType,
ROW_NUMBER() OVER (PARTITION BY ss.ModuleType ORDER BY sr.recommendation_order DESC) row_num
from supd_supply_recommend sr
INNER JOIN base_companyinfo bc ON sr.user_id=bc.UserId
INNER JOIN supd_supply_info ss on sr.user_id=ss.CreatorId AND ss.IsDeleted=0
-- WHERE ss.ModuleType='22'
WHERE sr.`Status`='Show' 其结果如下:
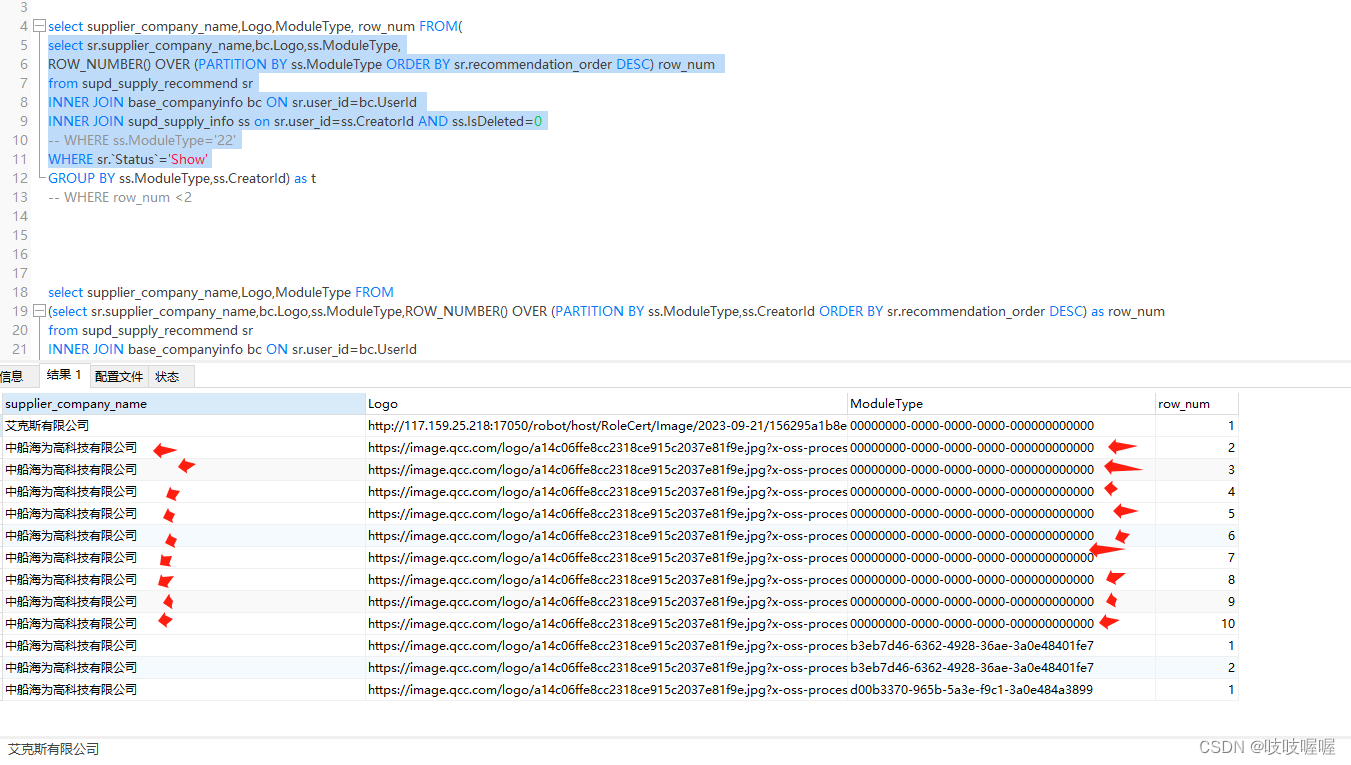
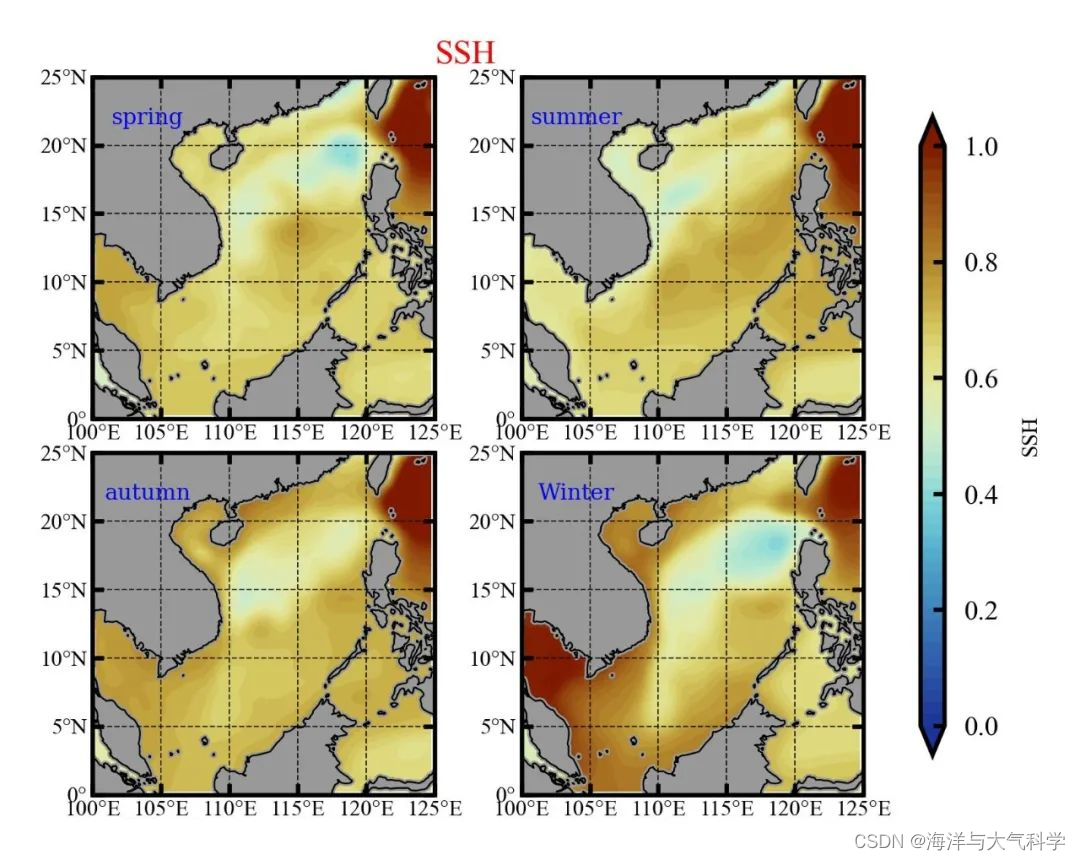
同意模块ModuleType=00000000-0000-0000-0000-000000000000的同一分区下 出现了10条重复的中船海为高科技有限公司供应商,这里我的逻辑其实是要同一分区下,不同供应商进行排名,
即只显示分区ModuleType=00000000-0000-0000-0000-000000000000下的艾克斯有限公司和中船海为高科技有限公司的排名,所以加上GROUP BY ss.ModuleType,ss.CreatorId来过滤重复数据。
row_num<2 就是取排名中小于第二名的数据,也就是前1条数据,如果你的实际需求也是取前一条最好写成row_num=1;我这里需求是前10条,只不过为了演示给大家,所以写成取前1条了
结果如下:未取前1条数据前的查询结果
取前一条记录的查询结果
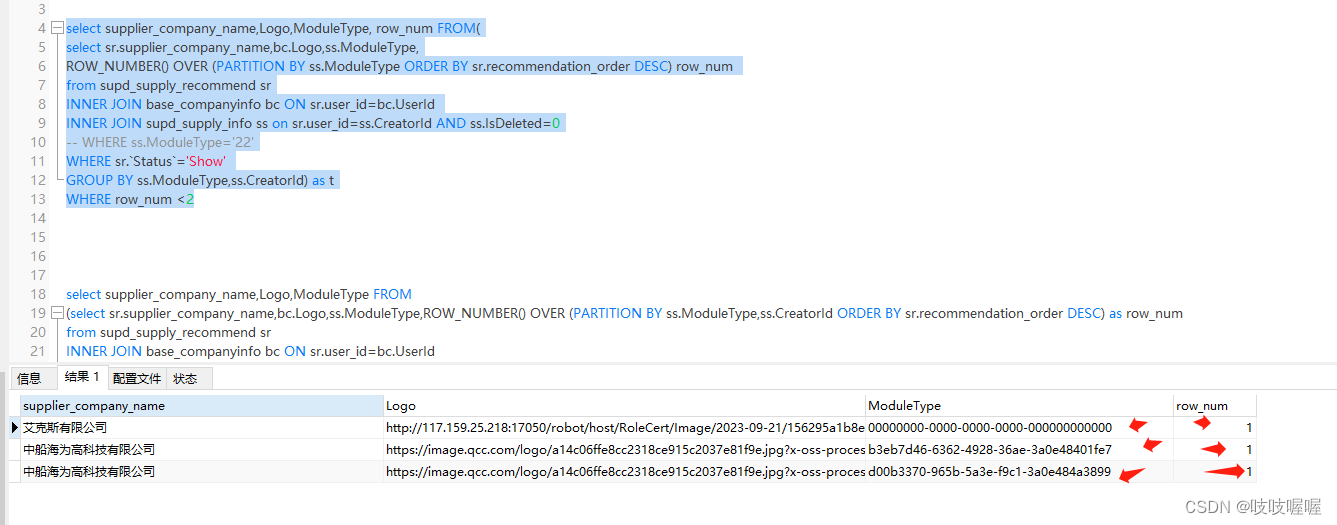
如上取出每个模块分区(ModuleType)下的第一条数据