前言:
truncate操作误删数据之后想恢复数据通常比较困难,因为truncate操作属于ddl操作无法使用直接undo闪回查询方式恢复数据,并且由于空间大小、备份时间以及变更操作不规范原因,往往在执行操作之前没有对表进行CTAS备份或者其他有效的逻辑备份导致恢复truncate的误删数据困难。
本文接下来将介绍常用的5种truncate误删数据的恢复办法,希望对读者有所借鉴或是启发。
数据恢复介绍:
在进行数据恢复之前,我们需要先获取一个非常关键的数据,就是truncate操作的时间点,这个时间点的准确性对数据的恢复非常关键,因为会影响数据恢复的完整性,时间点可以从以下途径获取
1 执行人员的大脑记忆,获取的时间点相对模糊
2 数据库的审计,操作记录日志,获取的时间点准确
3 dba_objects视图的last_ddl_time,获取时间点准确,前提是truncate是最近一次的DDL操作
4 从redo日志里面获取,获取的时间点准确
5 从历史相关视图获取v$sql,v$active_session_history获取的时间点准确,单不一定有记录
方式一:通过基于时间点的rman备份恢复
这种方式是相对稳妥的方式,但缺点也比较明显全量数据恢复时间相对较长,需要一倍空间以及恢复环境,而Oracle也推出更加简便快速的不用恢复全量数据的恢复方式,在Oracle10G以上可以使用TSPITR基于时间点恢复表空间的方式恢复数据,具体操作步骤可以参考Oracle-表空间基于时间点恢复(TSPITR),而在Oracle12c版本以上可以使用基于时间点的recover table的方式直接从备份里面基于时间快速恢复表或者是表分区,具体操作步骤可以参考Oracle-12c新功能基于时间点recover table
方式二:通过expdp,exp等逻辑备份恢复
可以这种方式恢复数据简单,灵活,但是逻辑备份通常没有增量的方式,都是单次的固定时间点执行全量备份,所以备份恢复的数据数据点与删除时间点可能会出现相差较多的问题,导致恢复的数据出现不完整的情况
方式三:flashback闪回数据库
flashback闪回数据库,将整个数据库数据闪回到误删数据前的时间点,这种方式的缺点非常明显就是闪回是将整个数据库的数据一起闪回,而这样的恢复方式在生产主库环境操作几乎不可能,因为不可能为了一张表的数据,将整个数据库的数据都闪回到之前的时间点,因此这种方式合适在备库环境进行,在备库开启了flashback的功能情况下,我们可以选择在备库上进行闪回恢复数据
具体操作步骤如下
--查看备库闪回日志的最老时间点,要低于误删数据的操作时间点
SQL> select *
SQL> from v$flashback_database_log;
OLDEST_FLASHBACK_SCN OLDEST_FLASHBACK_TI RETENTION_TARGET FLASHBACK_SIZE ESTIMATED_FLASHBACK_SIZE
-------------------- ------------------- ---------------- -------------- ------------------------
17239007 2023-10-11 17:42:31 1440 209715200 0
--将备库启动到mount
SQL> shutdown immediate;
SQL> startup mount;
--备库闪回到truncate之前的时间点
SQL>flashback database to timestamp to_timestamp('2023-10-11 17:45:00','yyyy-mm-dd hh24:mi:ss');
--只读打开数据库,确认是要恢复的数据
SQL> alter database open read only;
SQL> select count(*) from test.testdebug;
COUNT(*)
----------
172864
--备库开启到快照库模式导出表数据
SQL> alter database convert to snapshot standby;
SQL> Alter database open;
--expdp导出表数据
expdp 'userid="/ as sysdba"' dumpfile=test.dmp tables=test.testdebug directory=expdir logfile=test.log
--转为物理备库恢复同步
SQL> shutdown immediate;
SQL> startup mount ;
SQL> alter database convert to physical standby;
--重新恢复同步
SQL> shutdown immediate;
SQL> startup;
SQL> alter database recover managed standby database using current logfile disconnect from session; 方式四:延迟备库恢复
通过ADG延迟备库功能恢复数据,延迟备库是通过主动设置备库日志的应用延时,从而避免主库的操作在备库被立即应用,这样在主库发生误删数据时,备库的数据可以保证在延迟时间期限内未被删除,这样我们可以从延迟备库中恢复数据
具体操作步骤如下
--备库立即取消日志应用
SQL> alter database recover managed standby database cancel;
--主库切换日志
SQL> alter system switch logfile;
--备库启动到mount状态
SQL> shutdown immediate;
startup mount
--备库收到recover恢复到truncate之前的时间点
run
{
set until time "to_date('2023-10-11 16:45:00','yyyy-mm-dd hh24:mi:ss')";
recover database;
}
--只读打开备库
SQL> alter database open read only;
--确认是要恢复的数据
SQL> select count(*) from test.testdebug;
COUNT(*)
----------
86432
--备库开启到快照库模式导出表数据
SQL> alter database convert to snapshot standby;
SQL> Alter database open;
--expdp导出表数据
expdp 'userid="/ as sysdba"' dumpfile=test.dmp tables=test.testdebug directory=expdir logfile=test.log
--转为物理备库重新恢复同步
SQL> shutdown immediate;
SQL> startup mount ;
SQL> alter database convert to physical standby;
--重新恢复同步
SQL> shutdown immediate;
SQL> startup;
SQL> alter database recover managed standby database delay 120 disconnect from session;方式五:通过数据挖掘方式恢复数据
在数据库没有开启闪回功能,没有有效备份以及延迟备库环境的情况下,想恢复truncate误删数据方法只剩下从已有的数据块里面挖掘恢复数据,前提是误删的数据块还未被覆盖,如果数据块已经被覆盖,那么数据可能就再也找不回来了
所以,在没有有效的恢复方式的情况下,应尽可能的避免数据块被覆盖导致数据丢失,最好将数据所在的表空间设置为只读保留误删环境,如果有备库环境,可以立即取消日志应用然后将备库激活为快照库作为数据挖掘的环境
alter tablespace test1 read only;接下来进行数据挖掘,truncate表操作我们可以通过10046以及redo日志内容大概了解到truncate包含了以下的步骤
--10046
1 将truncate表加上独占锁
LOCK TABLE "TESTDEBUG" IN EXCLUSIVE MODE NOWAIT
2 执行truncate
truncate table testdebug
3 更新统计信息监控的数据
update sys.mon_mods$ set inserts = inserts + :ins, updates = updates + :upd, deletes = deletes + :del, flags = (decode(bitand(flags, :flag), :flag, flags, flags + :flag)), drop_segments = drop_segments + :drops
eg, timestamp = :time where obj# =88185
4 删除基本superobj$下的信息
delete from superobj$ where subobj# = 88185
5 删除基表统计信息
delete from tab_stats$ where obj#=88185
6 更新基表tab$的信息,包含更新data_object_id为新的值,文件块的信息
update tab$
7 删除基表索引统计信息
delete from ind_stats$ where obj#=:1
8 更新基表索引对象信息,包含更新data_object_id为新的值,文件块的信息
update ind$ set
9 更新基表seg$信息,包含更新extent的信息
update seg$
10 更新基表obj$信息,包含dataobj
--从redo 日志里面,我们还可以看到truncate期间直接更新的块信息
1 segment header(dataobj#、LHWM、HHWM、extent map、aux map以及extents个数)
2 L1,L2块(dataobj#,extent map)从中我们可以发现,truncate操作涉及修改的基表、块信息较为复杂,想直接通过修改回原来的块信息,基表信息的恢复方式难度较大,因此我们选择直接从块里面挖掘数据,关键点如下
1.使用rowid的方式直接访问误删数据所在的数据块,避免访问segment header,L1,L2块
2.误删数据可能包含在这以下3种块
-
空闲块(dba_free_space)
-
被分配给其他段但还没被使用覆盖(也就是每个段最后申请的一个extent)
-
当前对象所在段的第一个extent
3.obj$基表的data_object_id要跟挖掘原来数据的rowid里面的data_object_id一致,不然访问会出现无效rowid的报错
4.根据误删数据可能所在所在块的RELATIVE_file_id,block_id以及data_object_id,使用dbms_rowid.rowid_create函数构造误删数据的rowid
数据挖掘步骤如下:
1.找到被truncate表上一次的data_object_id
2 更新误删表在obj$基表上的data_object_id为原来的删除前的值
3.通过dba_extents,dba_free_space获取误删数据可能所在的块
4.通过dbms_rowid.rowid_create来创建误删数据的的rowid
5.利用rowid来挖掘抽取数据
6.验证挖掘的数据
7 将误删表在obj$基表上的data_object_id修改为删除后的值
8.将数据插入原表
具体操作步骤如下:
假设误删了表test.testdebug数据
truncate table test.testdebug;通过redo 查找truncate之前的data_object_id
--dump出删除操作期间的redo
alter system dump logfile '+DATADG/db/onlinelog/group_2.262.1132512359';
--搜索关键字Newobjd,找出修改之前的dataobj#
Redo on Level1 Bitmap Block
Change objd
Newobjd: 184880
CHANGE #2 CON_ID:0 TYP:0 CLS:8 AFN:7 DBA:0x01c000c8 OBJ:184880 SCN:0x000000000178875c SEQ:1 OP:13.22 ENC:0 RBL:0 FLG:0x0000
Redo on Level1 Bitmap Block
Change objd
Newobjd: 184890更新误删表在obj$基表上的data_object_id为原来的删除前的值
update obj$ set dataobj#=184880 where obj#=184880;
commit;
alter system flush shared_pool;
alter system flush buffer_cache;通过dba_extents,dba_free_space获取误删数据可能所在的块,并生成rowid
--存储过程执行用户权限
SQL> grant dba,resource,connect to <username>;
SQL> grant select on dba_extents to <username>;
SQL> grant select on dba_free_space to <username>;
SQL> grant select on dba_tables to <username>;
SQL> grant create table to <username>;
--存储过程get_data_rowid参数
1.p_old_owner truncate表的用户名
2.p_table truncate的表名
3.p_old_data_object_id 表truncate前的data_object_id
4.p_block_row 单个块最多包含的行数,根据表的列数量进行调整
5.p_parallel 挖掘数据的并行度
--创建存储过程get_data_rowid
create or replace procedure get_data_rowid(p_old_owner in varchar2,p_table in varchar2,p_old_data_object_id number,p_block_row number,p_parallel number)
is
v_fno number;
v_s_bno number;
v_e_bno number;
v_rowid rowid;
v_owner varchar2(50); -- truncate表用户名
v_table varchar2(100); -- truncate表名
v_data_obj number; -- truncate前dba_objects.data_object_id
v_block_row number; -- 理论上每个块最多存放接近680行数据
v_parallel number;
v_rowid_table varchar2(40); -- 存放rowid的表
v_table_seq number;
v_sql1 varchar(1000);
v_sql2 varchar(1000);
begin
v_owner := p_old_owner;
v_table := p_table;
v_data_obj := p_old_data_object_id;
v_block_row:=p_block_row;
v_parallel:=p_parallel;
begin
for t in 1..v_parallel loop
v_rowid_table:='rowid_data_table_'||t;
v_sql1:='create table '||v_rowid_table||'(BLOCK_ID NUMBER,ROW_ID rowid)';
execute immediate v_sql1;
end loop;
EXCEPTION
when OTHERS then
raise;
commit;
end;
for i in (select relative_fno, block_id, blocks --通过dba_extents,dba_free_space获取误删数据可能所在的块
from dba_extents
where owner = v_owner
and segment_name = v_table
and extent_id = 0
union all
select relative_fno, block_id, blocks
from dba_free_space
where tablespace_name in (select tablespace_name
from dba_tables
where owner = v_owner
and table_name = v_table)
union all
select relative_fno, block_id, blocks
from (select relative_fno,
block_id,
blocks,
row_number() over(partition by owner, segment_name, PARTITION_NAME order by extent_id desc) rn
from dba_extents
where tablespace_name in
(select tablespace_name
from dba_tables
where owner = v_owner
and table_name = v_table)
and extent_id > 0)
where rn = 1) loop
v_fno:=i.relative_fno;
v_s_bno:=i.block_id;
v_e_bno:=i.block_id+i.blocks-1;
for j in v_s_bno .. v_e_bno loop
begin
for x in 0..v_block_row loop -- 通过dbms_rowid.rowid_create来创建潜在的rowid
v_rowid:=dbms_rowid.rowid_create(1, v_data_obj,v_fno,j,x);
v_table_seq:=mod(j,v_parallel)+1;
v_rowid_table:='rowid_data_table_'||v_table_seq;
v_sql2:='insert into '||v_rowid_table||' values(:1,:2)';
execute immediate v_sql2 using j,v_rowid;
end loop;
exception
when others then
raise;
end;
commit;
end loop;
end loop;
end;
/
--执行存储过程生成要挖掘的rowid
exec get_data_rowid('TEST','TESTDEBUG',184880,100,16);
--这里使用了16个并行,所以rowid会分布在rowid_data_table_1-16表里面利用rowid来挖掘抽取数据
--创建存放挖掘数据的备份表
create table test.testdebug_bak tablespace users as select * from TEST.testdebug where 1=2;
--存储过程insert_data_by_rowid参数
1.p_old_owner truncate表的用户名
2.p_table truncate的表名
3.p_bak_owner 备份表的用户名
4.p_bak_table 备份表的表名
5.p_slave 并行的子进程号
--创建存储过程insert_data_by_rowid
create or replace procedure insert_data_by_rowid(p_old_owner in varchar2,p_table in varchar2,p_bak_owner in varchar2,p_bak_table in varchar2,p_slave number)
is
v_owner varchar2(50);
v_table varchar2(100);
v_bak_owner varchar2(50);
v_bak_table varchar2(100);
v_sql varchar2(2000);
v_slave number;
v_err_code varchar2(50);
v_err_msg varchar2(500);
v_rowid_table VARCHAR(40);
c_rowid sys_refcursor;
v_rowid dbms_sql.urowid_table;
v_sql1 varchar2(1000);
v_sql2 varchar2(1000);
begin
v_owner := p_old_owner;
v_table := p_table;
v_bak_owner:=p_bak_owner;
v_bak_table:=p_bak_table;
v_slave:=p_slave;
v_rowid_table:='rowid_data_table_'||v_slave;
v_sql1:='select row_id from '||v_rowid_table;
v_sql2 := 'insert into '||v_bak_owner||'.'||v_bak_table||' select * from '||v_owner||'.'||v_table||' where rowid=:1';
open c_rowid for v_sql1;
LOOP
fetch c_rowid bulk collect into v_rowid limit 10000;
exit when v_rowid.count=0;
begin
forall i in v_rowid.first..v_rowid.last SAVE EXCEPTIONS
execute immediate v_sql2 using v_rowid(i);
EXCEPTION
when OTHERS
then
-- DBMS_OUTPUT.put_line (SQLERRM);
-- FOR indx IN 1 .. SQL%BULK_EXCEPTIONS.COUNT
-- LOOP
-- DBMS_OUTPUT.put_line ('Oracle error is '|| SQLERRM (-1 * SQL%BULK_EXCEPTIONS (indx).ERROR_CODE));
-- END LOOP;
null;
end;
commit;
end loop;
close c_rowid;
end;
/
--16个窗口并行挖掘,注意会消耗大量的PGA进程内存以及产生大量单块读IO
set serveroutput on
set timing on
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',1);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',2);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',3);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',4);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',5);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',6);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',7);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',8);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',9);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',10);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',11);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',12);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',13);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',14);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',15);
exec insert_data_by_rowid('TEST','TESTDEBUG','TEST','TESTDEBUG_BAK',16);验证挖掘的数据,将数据插回原表
--从表的字段逻辑,业务数据逻辑,表数据量验证数据
select count(*) from test.testdebug_bak;
select sum(SESSIONID+ENTRYID+STATEMENT) from test.testdebug_bak;
--将误删表在obj$基表上的data_object_id修改为删除后的值
update obj$ set dataobj#=184890 where obj#=184880;
commit;
alter system flush shared_pool;
alter system flush buffer_cache;
--表空间设置为读写
alter tablespace test1 read write;
--将数据插回原表,完成数据挖掘工作
insert into test.testdebug select * from test.testdebug_bak;总结:
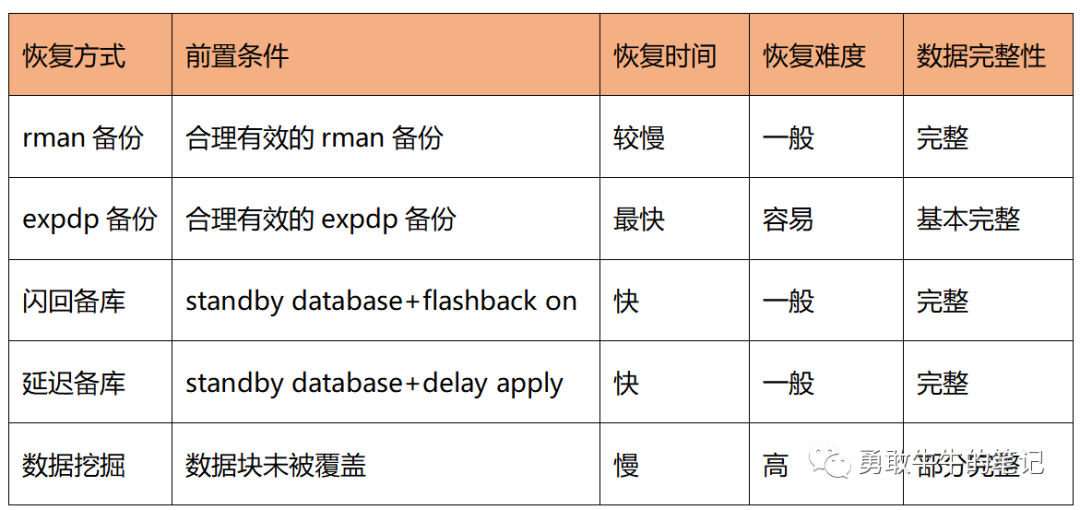
5种恢复方式综合来看,延迟备库恢复以及闪回备库从恢复时间、恢复难度以及恢复数据完整性来看整体最好,是恢复truncate误删数据的首选,这也是为什么对于重要的核心数据库通常建议配置一主两备的原因,RAC(主)+实时备库(flashback on 8小时)+延迟备库(delay 24小时)+合理有效的rman备份策略的配置可以最大限度的保障数据安全









![[网站部署03]宝塔+worldPress部署Ripro主题网站](https://img-blog.csdnimg.cn/799705bfde9742fa987e2c68326dbb73.png)