EntityManager 介绍
Java Persistence API 规定,操作数据库实体必须要通过 EntityManager 进行,而我们前面看到了所有的 Repository 在 JPA 里面的实现类是 SimpleJpaRepository,它在真正操作实体的时候都是调用 EntityManager 里面的方法。
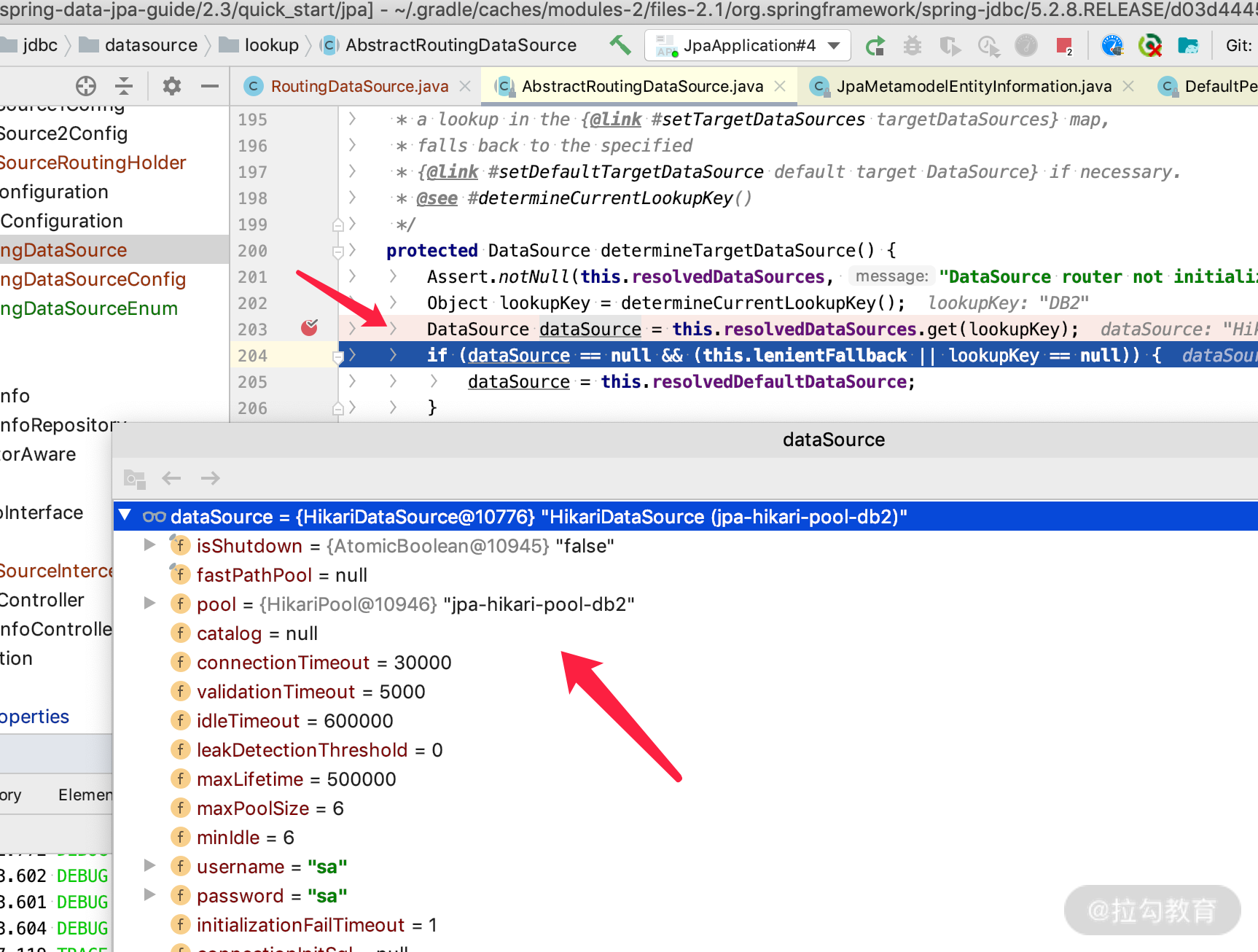
我们在 SimpleJpaRepository 里面设置一个断点,这样可以很容易看得出来 EntityManger 是 JPA 的接口协议,而其现类是 Hibernate 里面的 SessionImpl,如下图所示:

那么我们看看 EntityManager 给我们提供了哪些方法。
EntityManager 方法有哪些?
下面介绍几个重要的、比较常用的方法,不常用的我将一笔带过,如果你有兴趣可以自行查看。
复制代码
public interface EntityManager {
//用于将新创建的Entity纳入EntityManager的管理。该方法执行后,传入persist()方法的 Entity 对象转换成持久化状态。
public void persist(Object entity);
//将游离态的实体merge到当前的persistence context里面,一般用于更新。
public <T> T merge(T entity);
//将实体对象删除,物理删除
public void remove(Object entity);
//将当前的persistence context中的实体,同步到数据库里面,只有执行了这个方法,上面的EntityManager的操作才会DB生效;
public void flush();
//根据实体类型和主键查询一个实体对象;
public <T> T find(Class<T> entityClass, Object primaryKey);
//根据JPQL创建一个Query对象
public Query createQuery(String qlString);
//利用CriteriaUpdate创建更新查询
public Query createQuery(CriteriaUpdate updateQuery);
//利用原生的sql语句创建查询,可以是查询、更新、删除等sql
public Query createNativeQuery(String sqlString);
...//其他方法我就不一一列举了,用法很简单,我们只要参看SimpleJpaRepository里面怎么用的,我们怎么用就可以了;
}
这一课时我们先知道 EntityManager 的语法和用法就好,在之后的第 21 课时介绍 Persistence Context 的时候,再详细讲一下其对实体状态的影响,以及每种状态代表什么意思。
那么现在你知道了这些语法,该怎么使用呢?
EntityManager 如何使用?
它的使用方法很简单,我们在任何地方只要能获得 EntityManager,就可以进行里面的操作。
获得 EntityManager 的方式:通过 @PersistenceContext 注解。
将 @PersistenceContext 注解标注在 EntityManager 类型的字段上,这样得到的 EntityManager 就是容器管理的 EntityManager。由于是容器管理的,所以我们不需要、也不应该显式关闭注入的 EntityManager 实例。
下面是关于这种方式的例子,我们想要在测试类中获得 @PersistenceContext 里面的 EntityManager,看看代码应该怎么写。
复制代码
@DataJpaTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class UserRepositoryTest {
//利用该方式获得entityManager
@PersistenceContext
private EntityManager entityManager;
@Autowired
private UserRepository userRepository;
/**
* 测试entityManager用法
*
* @throws JsonProcessingException
*/
@Test
@Rollback(false)
public void testEntityManager() throws JsonProcessingException {
//测试找到一个User对象
User user = entityManager.find(User.class,2L);
Assertions.assertEquals(user.getAddresses(),"shanghai");
//我们改变一下user的删除状态
user.setDeleted(true);
//merger方法
entityManager.merge(user);
//更新到数据库里面
entityManager.flush();
//再通过createQuery创建一个JPQL,进行查询
List<User> users = entityManager.createQuery("select u From User u where u.name=?1")
.setParameter(1,"jack")
.getResultList();
Assertions.assertTrue(users.get(0).getDeleted());
}
}
我们通过这个测试用例,可以知道 EntityManager 使用起来还是比较容易的。不过在实际工作中,我不建议直接操作 EntityManager,因为如果你操作不熟练的话,会出现一些事务异常。因此我还是建议你通过 Spring Data JPA 给我们提供的 Repositories 方式进行操作。
提示一下,你在写框架的时候可以直接操作 EntityManager,切记不要在任何业务代码里面都用到 EntityManager,否则自己的代码到最后就会很难维护。
EntityManager 我们了解完了,那么我们再看下 @EnableJpaRepositories 对自定义 Repository 起了什么作用。
@EnableJpaRepositories 详解
下面分别从 @EnableJpaRepositories 的语法,以及其默认加载方式来详细介绍一下。
@EnableJpaRepositories 语法
我们还是直接看代码,如下所示:
复制代码
public @interface EnableJpaRepositories {
String[] value() default {};
String[] basePackages() default {};
Class<?>[] basePackageClasses() default {};
Filter[] includeFilters() default {};
Filter[] excludeFilters() default {};
String repositoryImplementationPostfix() default "Impl";
String namedQueriesLocation() default "";
Key queryLookupStrategy() default Key.CREATE_IF_NOT_FOUND;
Class<?> repositoryFactoryBeanClass() default JpaRepositoryFactoryBean.class;
Class<?> repositoryBaseClass() default DefaultRepositoryBaseClass.class;
String entityManagerFactoryRef() default "entityManagerFactory";
String transactionManagerRef() default "transactionManager";
boolean considerNestedRepositories() default false;
boolean enableDefaultTransactions() default true;
}
下面我对里面的 10 个方法进行一下具体说明:
1)value 等于 basePackage
用于配置扫描 Repositories 所在的 package 及子 package。
可以配置为单个字符串。
复制代码
@EnableJpaRepositories(basePackages = "com.example")
也可以配置为字符串数组形式,即多个情况。
复制代码
@EnableJpaRepositories(basePackages = {"com.sample.repository1", "com.sample.repository2"})
默认 @SpringBootApplication 注解出现目录及其子目录。
2)basePackageClasses
指定 Repository 类所在包,可以替换 basePackage 的使用。
一样可以单个字符,下面例子表示 BookRepository.class 所在 Package 下面的所有 Repositories 都会被扫描注册。
复制代码
@EnableJpaRepositories(basePackageClasses = BookRepository.class)
也可以多个字符,下面的例子代表 ShopRepository.class, OrganizationRepository.class 所在的 package下面的所有 Repositories 都会被扫描。
复制代码
@EnableJpaRepositories(basePackageClasses = {ShopRepository.class, OrganizationRepository.class})
3)includeFilters
指定包含的过滤器,该过滤器采用 ComponentScan 的过滤器,可以指定过滤器类型。
下面的例子表示只扫描带 Repository 注解的类。
复制代码
@EnableJpaRepositories( includeFilters={@ComponentScan.Filter(type=FilterType.ANNOTATION, value=Repository.class)})
4)excludeFilters
指定不包含过滤器,该过滤器也是采用 ComponentScan 的过滤器里面的类。
下面的例子表示,带 @Service 和 @Controller 注解的类,不用扫描进去,当我们的项目变大了之后可以加快应用的启动速度。
复制代码
@EnableJpaRepositories(excludeFilters={@ComponentScan.Filter(type=FilterType.ANNOTATION, value=Service.class),@ComponentScan.Filter(type=FilterType.ANNOTATION, value=Controller.class)})
5)repositoryImplementationPostfix
当我们自定义 Repository 的时候,约定的接口 Repository 的实现类的后缀是什么,默认是 Impl。例子我在下面详细讲解。
6)namedQueriesLocation
named SQL 存放的位置,默认为 META-INF/jpa-named-queries.properties
例子如下:
复制代码
Todo.findBySearchTermNamedFile=SELECT t FROM Table t WHERE LOWER(t.description) LIKE LOWER(CONCAT('%', :searchTerm, '%')) ORDER BY t.title ASC
这个你知道就行了,我建议不要用,因为它虽然功能很强大,但是,当我们使用了这么复杂的方法时,你需要想一想是否有更简单的方法。
7)queryLookupStrategy
构建条件查询的查找策略,包含三种方式:CREATE、USE_DECLARED_QUERY、CREATE_IF_NOT_FOUND。
正如我们前几课时介绍的:
- CREATE:按照接口名称自动构建查询方法,即我们前面说的 Defining Query Methods;
- USE_DECLARED_QUERY:用 @Query 这种方式查询;
- CREATE_IF_NOT_FOUND:如果有 @Query 注解,先以这个为准;如果不起作用,再用 Defining Query Methods;这个是默认的,基本不需要修改,我们知道就行了。
8)repositoryFactoryBeanClass
指定生产 Repository 的工厂类,默认 JpaRepositoryFactoryBean。JpaRepositoryFactoryBean 的主要作用是以动态代理的方式,帮我们所有 Repository 的接口生成实现类。例如当我们通过断点,看到 UserRepository 的实现类是 SimpleJpaRepository 代理对象的时候,就是这个工厂类干的,一般我们很少会去改变这个生成代理的机制。
9)entityManagerFactoryRef
用来指定创建和生产 EntityManager 的工厂类是哪个,默认是 name=“entityManagerFactory” 的 Bean。一般用于多数据配置。
10)Class repositoryBaseClass()
用来指定我们自定义的 Repository 的实现类是什么。默认是 DefaultRepositoryBaseClass,即表示没有指定的 Repository 的实现基类。
11)String transactionManagerRef() default “transactionManager”
用来指定默认的事务处理是哪个类,默认是 transactionManager,一般用于多数据源。
以上就是 @EnableJpaRepositories 的基本语法了,涉及的方法比较多,你可以慢慢探索。下面再看看默认是怎么加载的。
@EnableJpaRepositories 默认加载方式
默认情况下是 spring boot 的自动加载机制,通过 spring.factories 的文件加载 JpaRepositoriesAutoConfiguration,如下图:
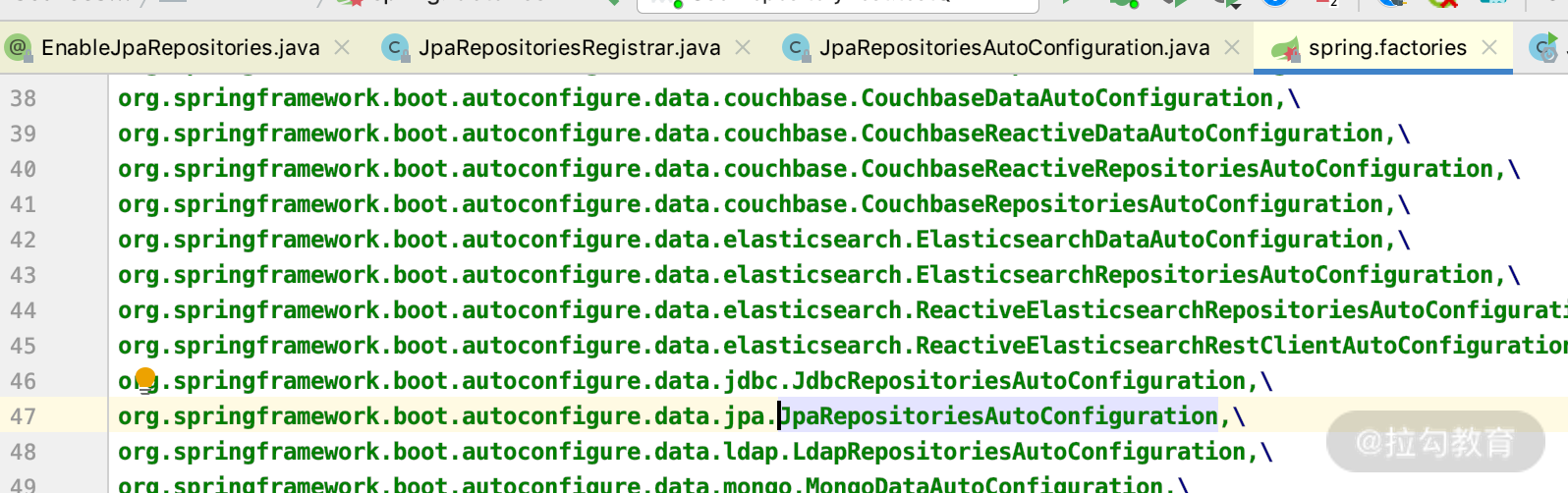
JpaRepositoriesAutoConfiguration 里面再进行 @Import(JpaRepositoriesRegistrar.class) 操作,显示如下:

而 JpaRepositoriesRegistrar.class 里面配置了 @EnableJpaRepositories,从而使默认值产生了如下效果:
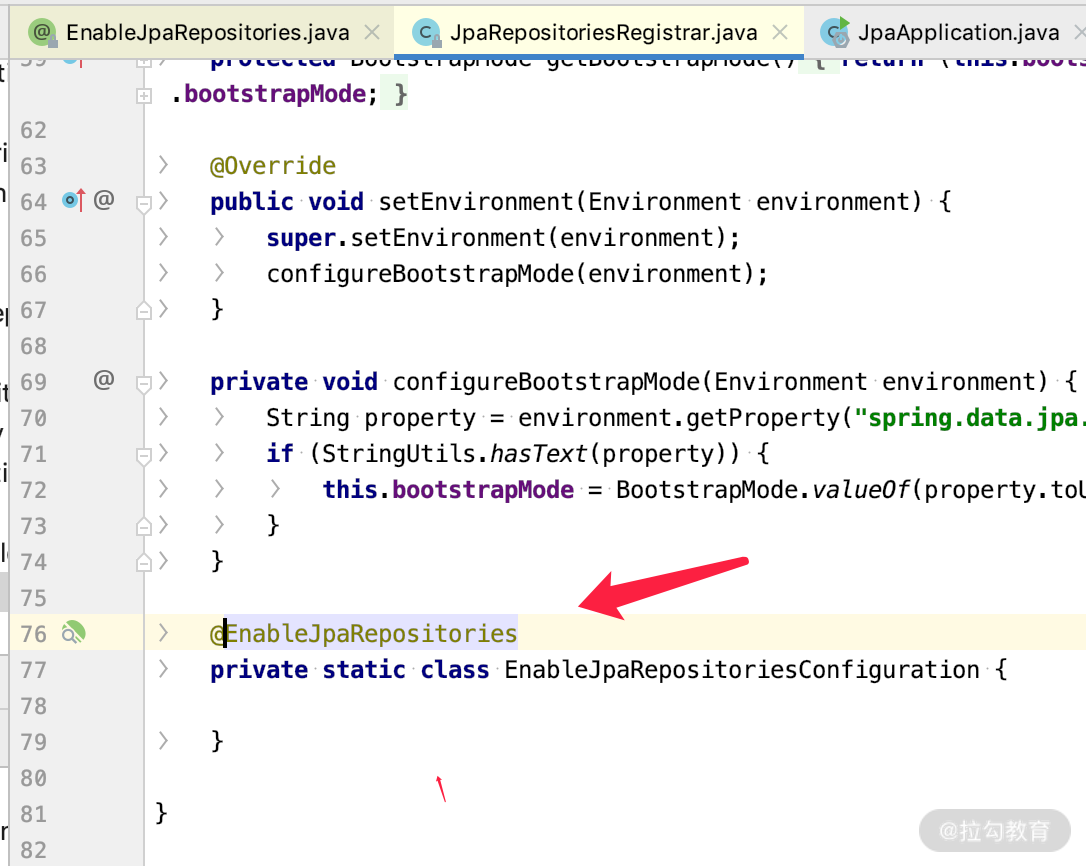
这样关于 @EnableJpaRepositories 的语法以及默认加载方式就介绍完了,你就可以知道通过 @EnableJpaRepositories 可以完成很多我们自定义的需求。那么到底如何定义自己的 Repository 的实现类呢?我们接着看。
自定义 Repository 的 impl 的方法
定义自己的 Repository 的实现,有以下两种方法。
第一种方法:定义独立的 Repository 的 Impl 实现类
我们通过一个实例说明一下,假设我们要实现一个逻辑删除的功能,看看应该怎么做?
第一步:定义一个 CustomizedUserRepository 接口。
此接口会自动被 @EnableJpaRepositories 开启之后扫描到,代码如下:
复制代码
package com.example.jpa.example1.customized;
import com.example.jpa.example1.User;
public interface CustomizedUserRepository {
User logicallyDelete(User user);
}
第二步:创建一个 CustomizedUserRepositoryImpl 实现类。
并且实现类用我们上面说过的 Impl 结尾,如下所示:
复制代码
package com.example.jpa.example1.customized;
import com.example.jpa.example1.User;
import javax.persistence.EntityManager;
public class CustomizedUserRepositoryImpl implements CustomizedUserRepository {
private EntityManager entityManager;
public CustomizedUserRepositoryImpl(EntityManager entityManager) {
this.entityManager = entityManager;
}
@Override
public User logicallyDelete(User user) {
user.setDeleted(true);
return entityManager.merge(user);
}
}
其中我们也发现了 EntityManager 的第二种注入方式,即直接放在构造方法里面,通过 Spring 自动注入。
第三步:当用到 UserRepository 的时候,直接继承我们自定义的 CustomizedUserRepository 接口即可。
复制代码
public interface UserRepository extends JpaRepository<User,Long>, JpaSpecificationExecutor<User>, CustomizedUserRepository {
}
第四步:写一个测试用例测试一下。
复制代码
@Test
public void testCustomizedUserRepository() {
//查出来一个User对象
User user = userRepository.findById(2L).get();
//调用我们的逻辑删除方法进行删除
userRepository.logicallyDelete(user);
//我们再重新查出来,看看值变了没有
List<User> users = userRepository.findAll();
Assertions.assertEquals(users.get(0).getDeleted(),Boolean.TRUE);
}
最后调用刚才我们自定义的逻辑删除方法 logicallyDelete,跑一下测试用例,结果完全通过。那么此种方法的实现原理是什么呢?我们通过 debug 分析一下。
原理分析
我们在上面讲过 Class<?> repositoryFactoryBeanClass() default JpaRepositoryFactoryBean.class,repository 的动态代理创建工厂是: JpaRepositoryFactoryBean,它会帮我们生产 repository 的实现类,那么我们直接看一下JpaRepositoryFactoryBean 的源码,分析其原理。
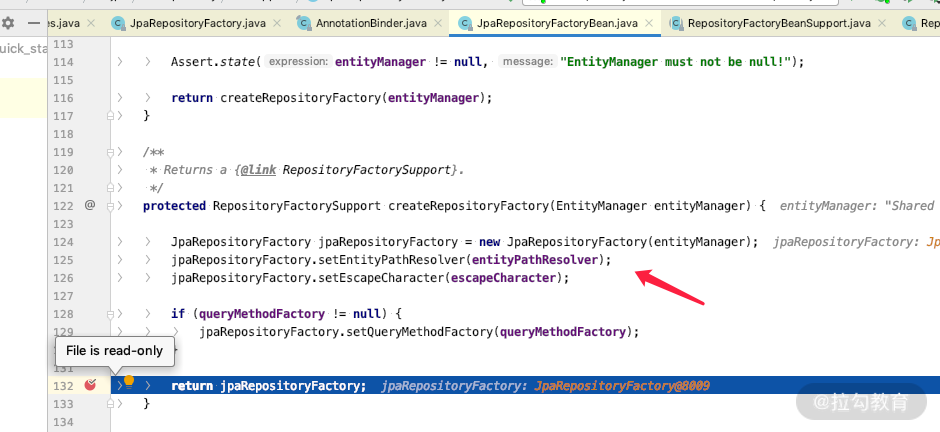
设置一个断点,就会发现,每个 Repository 都会构建一个 JpaRepositoryFactory,当 JpaRepositoryFactory 加载完之后会执行 afterPropertiesSet() 方法,找到 UserRepository 的 Fragment(即我们自定义的 CustomizedUserRepositoryImpl),如下所示:
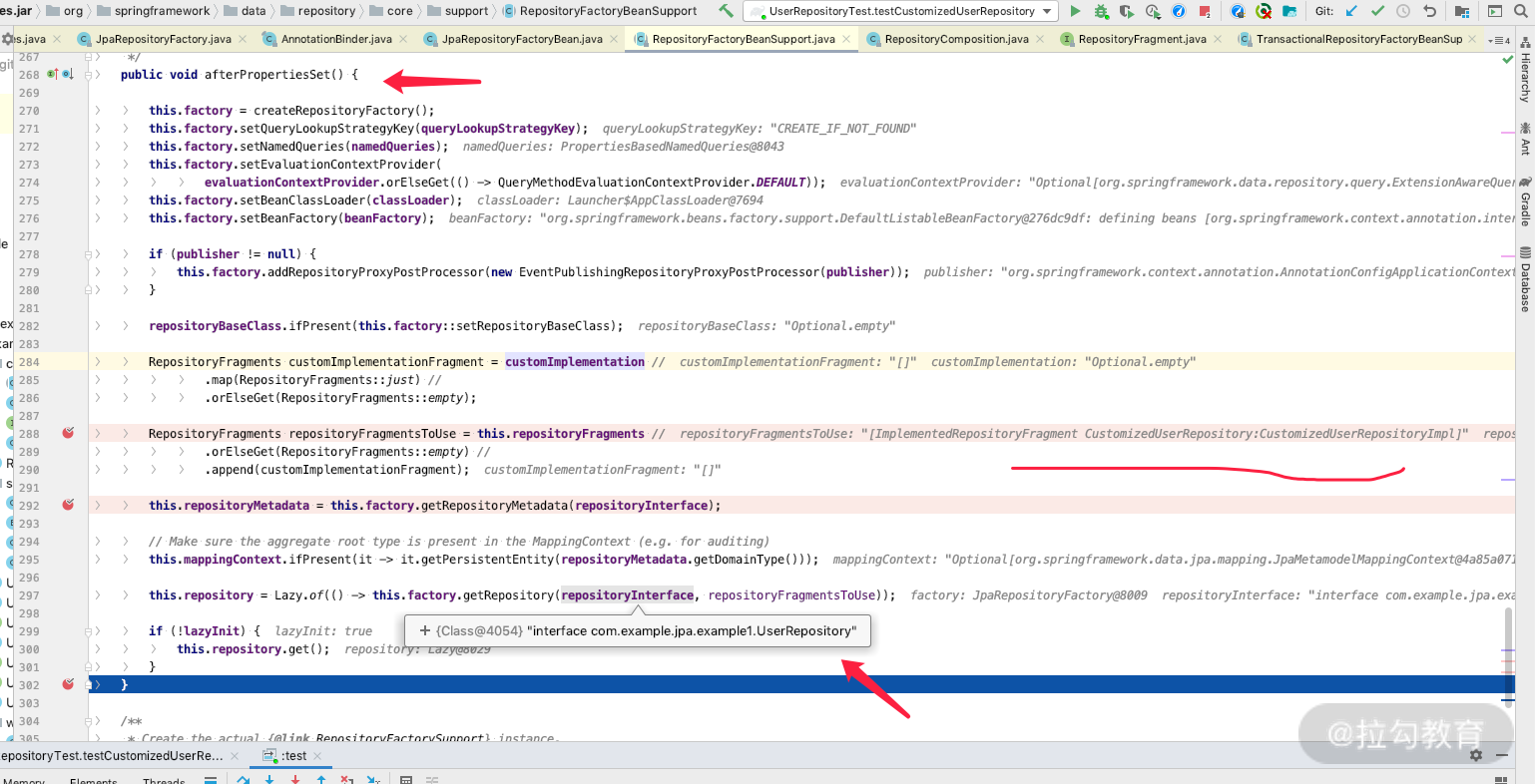
我们再看 RepositoryFactory 里面的所有方法,如下图,一看就是动态代理生成 Repository 的实现类,我们进到这个方法里面设置个断点继续观察。
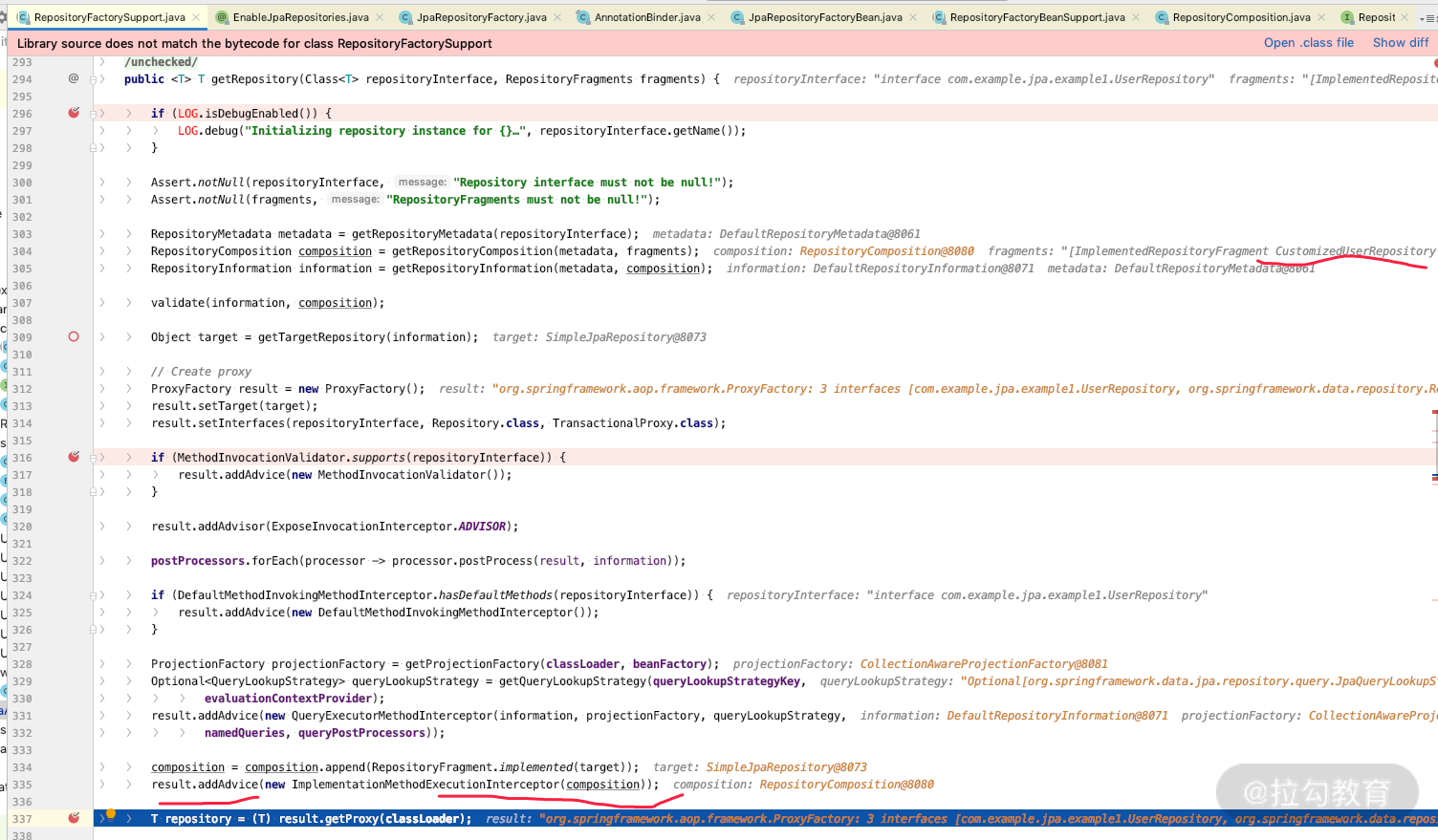
然后我们通过断点可以看到,fragments 放到了 composition 里面,最后又放到了 advice 里面,最后才生成了我们的 repository 的代理类。这时我们再打开 repository 详细地看看里面的值。
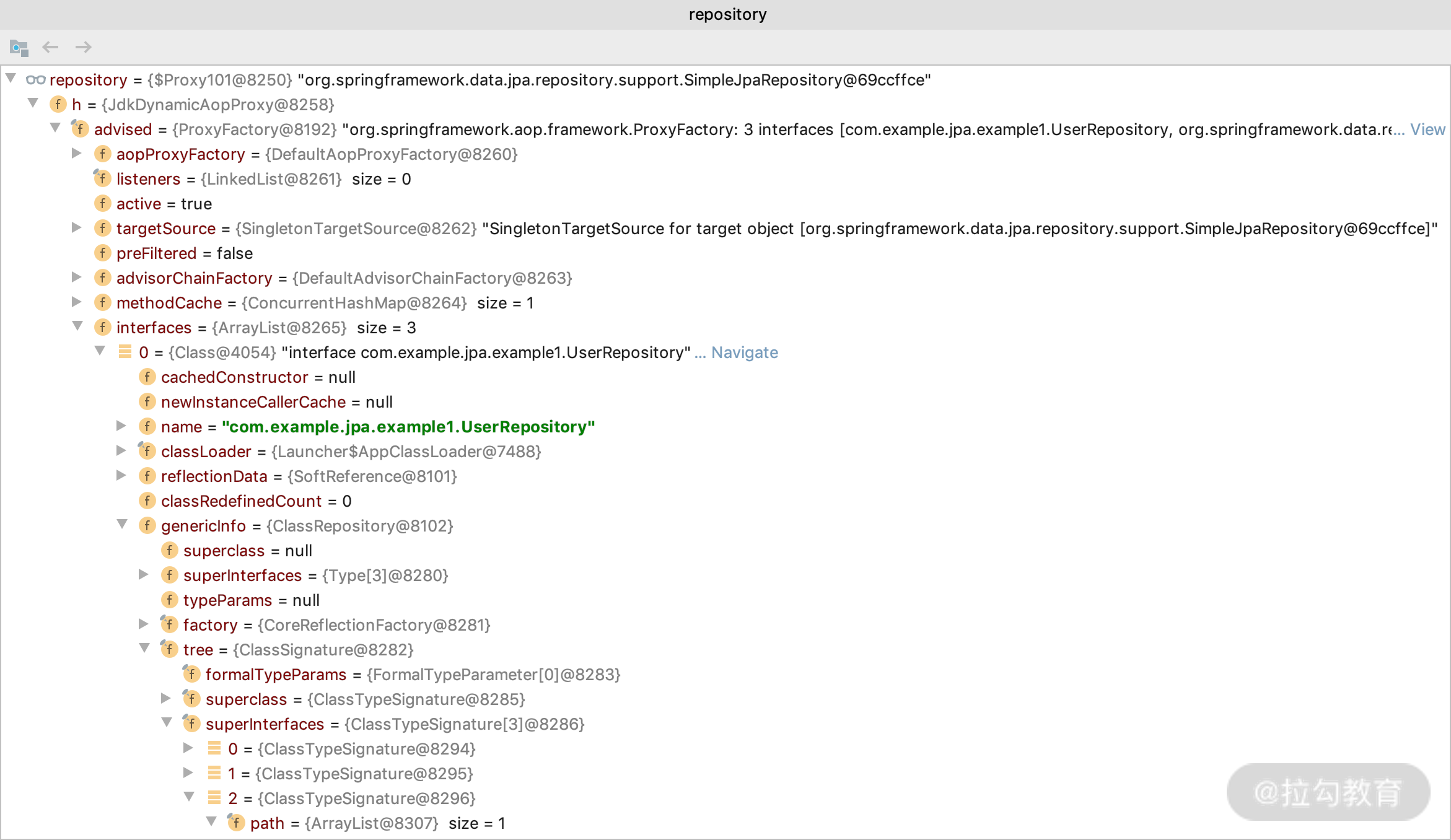
可以看到 repository 里面的 interfaces,就是我们刚才测试 userRepository 里面的接口定义的。
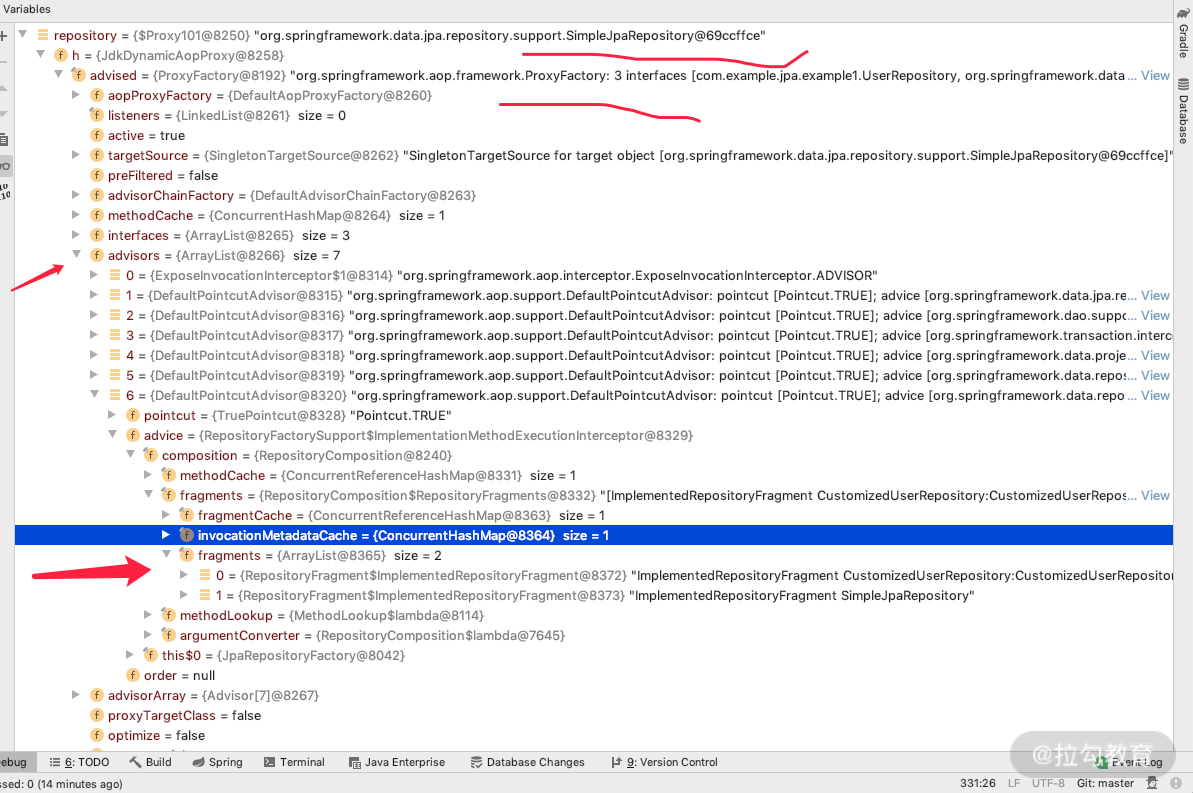
我们可以看到 advisors 里面第六个就是我们自定义的接口的实现类,从这里可以得出结论:spring 通过扫描所有 repository 的接口和实现类,并且通过 aop 的切面和动态代理的方式,可以知道我们自定义的接口的实现类是什么。
针对不同的 repository 自定义的接口和实现类,需要我们手动去 extends,这种比较适合不同的业务场景有各自的 repository 的实现情况。还有一种方法是我们直接改变动态代理的实现类,我们接着看。
第二种方法:通过 @EnableJpaRepositories 定义默认的 Repository 的实现类
当面对复杂业务的时候,难免会自定义一些公用的方法,或者覆盖一些默认实现的情况。举个例子:很多时候线上的数据是不允许删除的,所以这个时候需要我们覆盖 SimpleJpaRepository 里面的删除方法,换成更新,进行逻辑删除,而不是物理删除。那么接下来我们看看应该怎么做?
第一步:正如上面我们讲的利用 @EnableJpaRepositories 指定 repositoryBaseClass,代码如下:
复制代码
@SpringBootApplication
@EnableWebMvc
@EnableJpaRepositories(repositoryImplementationPostfix = "Impl",repositoryBaseClass = CustomerBaseRepository.class)
public class JpaApplication {
public static void main(String[] args) {
SpringApplication.run(JpaApplication.class, args);
}
}
可以看出,在启动项目的时候,通过 @EnableJpaRepositories 指定我们 repositoryBaseClass 的基类是 CustomerBaseRepository。
第二步:创建 CustomerBaseRepository 继承 SimpleJpaRepository 即可。
继承 SimpleJpaRepository 之后,我们直接覆盖 delete 方法即可,代码如下:
复制代码
package com.example.jpa.example1.customized;
import org.springframework.data.jpa.repository.support.JpaEntityInformation;
import org.springframework.data.jpa.repository.support.SimpleJpaRepository;
import org.springframework.transaction.annotation.Transactional;
import javax.persistence.EntityManager;
@Transactional(readOnly = true)
public class CustomerBaseRepository<T extends BaseEntity,ID> extends SimpleJpaRepository<T,ID> {
private final JpaEntityInformation<T, ?> entityInformation;
private final EntityManager em;
public CustomerBaseRepository(JpaEntityInformation<T, ?> entityInformation, EntityManager entityManager) {
super(entityInformation, entityManager);
this.entityInformation = entityInformation;
this.em = entityManager;
}
public CustomerBaseRepository(Class<T> domainClass, EntityManager em) {
super(domainClass, em);
entityInformation = null;
this.em = em;
}
//覆盖删除方法,实现逻辑删除,换成更新方法
@Transactional
@Override
public void delete(T entity) {
entity.setDeleted(Boolean.TRUE);
em.merge(entity);
}
}
需要注意的是,这里需要覆盖父类的构造方法,接收 EntityManager,并赋值给自己类里面的私有变量。
第三步:写一个测试用例测试一下。
复制代码
@Test
public void testCustomizedBaseRepository() {
User user = userRepository.findById(2L).get();
userRepository.logicallyDelete(user);
userRepository.delete(user);
List<User> users = userRepository.findAll();
Assertions.assertEquals(users.get(0).getDeleted(),Boolean.TRUE);
}
你可以发现,我们执行完“删除”之后,数据库里面的 User 还在,只不过 deleted,变成了已删除状态。那么这是为什么呢?我们分析一下原理。
原理分析
还是打开 RepositoryFactory 里面的父类方法,它会根据 @EnableJpaRepositories 里面我们配置的 repositoryBaseClass,加载我们自定义的实现类,关键方法如下:
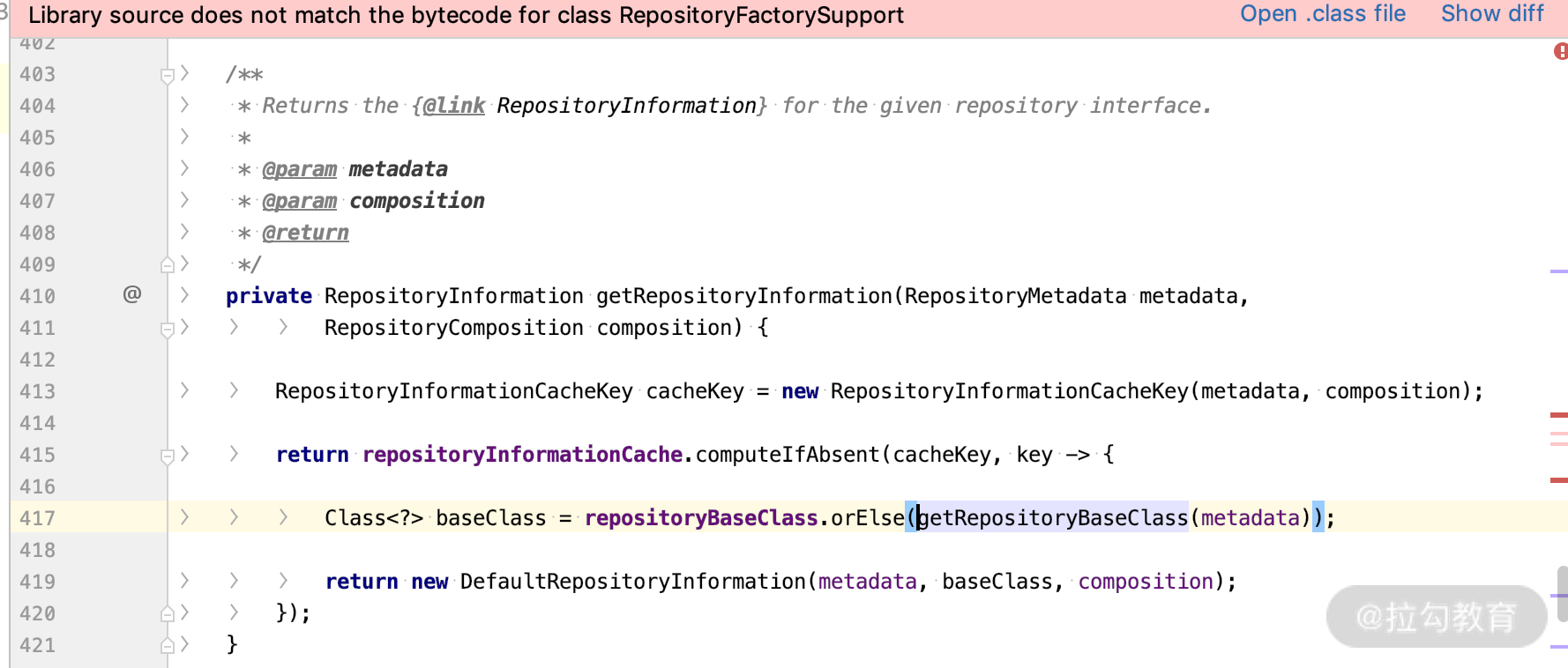
我们还看刚才的方法的断点,如下:
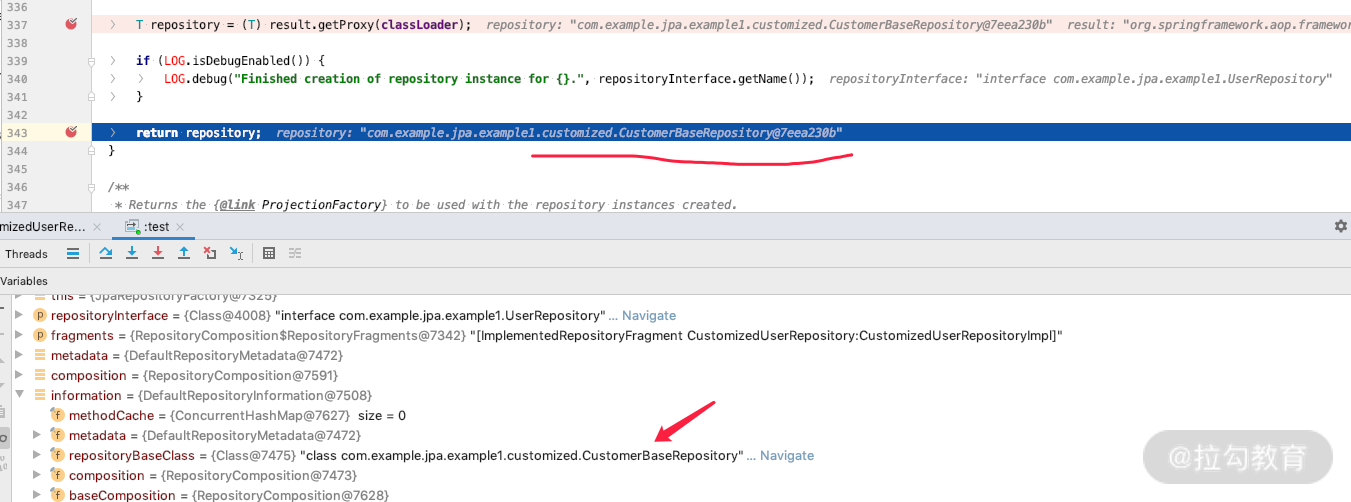
可以看到 information 已经变成了我们扩展的基类了,而最终生成的 repository 的实现类也换成了 CustomerBaseRepository。
自定义的方法,我们讲完了,那么它都会在哪些实际场景用到呢?接着看一下。
实际应用场景是什么?
在实际工作中,有哪些场景会用到自定义 Repository 呢?
- 首先肯定是我们做框架的时候、解决一些通用问题的时候,如逻辑删除,正如我们上面的实例所示的样子。
- 在实际生产中经常会有这样的场景:对外暴露的是 UUID 查询方法,而对内暴露的是 Long 类型的 ID,这时候我们就可以自定义一个 FindByIdOrUUID 的底层实现方法,可以选择在自定义的 Respository 接口里面实现。
- Defining Query Methods 和 @Query 满足不了我们的查询,但是我们又想用它的方法语义的时候,就可以考虑实现不同的 Respository 的实现类,来满足我们不同业务场景的复杂查询。我见过有团队这样用过,不过个人感觉一般用不到,如果你用到了说明你的代码肯定有优化空间,代码不应该过于复杂。
上面我们讲到了逻辑删除,还有一个是利用 @SQLDelete 也可以做到,用法如下:
复制代码
@SQLDelete(sql = "UPDATE user SET deleted = true where deleted =false and id = ?")
public class User implements Serializable {
....
}
这个时候不需要我们自定义 Respository 也可做到,这个方法的优点就是灵活,而缺点就是需要我们一个一个配置在实体上面。你可以根据实际场景自由选择方式。