PyCaret 简介
PyCaret 是一个用于简化 Python 机器学习工作流程的开源库。它提供了一个高级、低代码的接口,用于自动化机器学习流程的各个方面,使数据科学家和分析师更容易构建和部署机器学习模型。PyCaret 的一些关键特点和用途包括:
1. 自动化机器学习 (AutoML):PyCaret 可以自动化机器学习中许多繁琐和耗时的任务,如数据预处理、特征选择、超参数调整、模型选择和评估。
2. 简化的工作流程:它提供了一致性和有组织的工作流程,允许用户仅需几行代码执行常见的机器学习任务。
3. 模型选择:PyCaret 支持多种机器学习算法,帮助用户快速比较和选择最适合特定任务的模型。
4. 超参数调整:它自动化了超参数调整的过程,帮助用户找到模型的最佳超参数。
5. 模型评估:PyCaret 提供全面的模型评估和比较指标,帮助用户了解模型的性能,并做出明智的决策。
6. 数据预处理:它自动化了数据预处理步骤,如缺失值填补、分类编码和特征缩放。
7. 可视化:PyCaret 提供各种可视化工具,帮助用户探索数据、理解模型性能,并做出数据驱动的决策。
8. 模型部署:它允许用户轻松将机器学习模型部署到生产环境,因此适用于创建端到端的机器学习流水线。
9. 异常检测:PyCaret 还包括异常检测功能,有助于在数据集中检测异常值。
10. 自然语言处理 (NLP):它支持自然语言处理任务,使其适用于各种机器学习应用。
PyCaret 特别适用于希望快速尝试不同机器学习模型和技术,而不必为每个步骤编写大量代码的数据科学家和分析师。它旨在减少构建和部署机器学习模型所需的时间和工作量,因此在数据科学和机器学习社区中是一项有价值的工具。
示例代码(Classification)
1. setup
该函数初始化训练环境并创建转换管道。 设置函数必须在执行任何其他函数之前调用。 它需要两个必需参数:数据和目标。 所有其他参数都是可选的。
import pandas as pd
from pycaret.datasets import get_data
pd.set_option('display.max_columns', None)
data = get_data('diabetes')
PyCaret 3.0 有两个 API。 您可以根据自己的喜好选择其中之一。 功能与实验结果一致。
Functional API
from pycaret.classification import *
s = setup(data, target = 'Class variable', session_id = 123)
OOP API
from pycaret.classification import ClassificationExperiment
s = ClassificationExperiment()
s.setup(data, target = 'Class variable', session_id = 123)2. Compare Models
该函数使用交叉验证来训练和评估模型库中所有可用估计器的性能。 该函数的输出是具有平均交叉验证分数的评分网格。 可以使用 get_metrics 函数访问 CV 期间评估的指标。 可以使用 add_metric 和 remove_metric 函数添加或删除自定义指标。
# functional API
best = compare_models()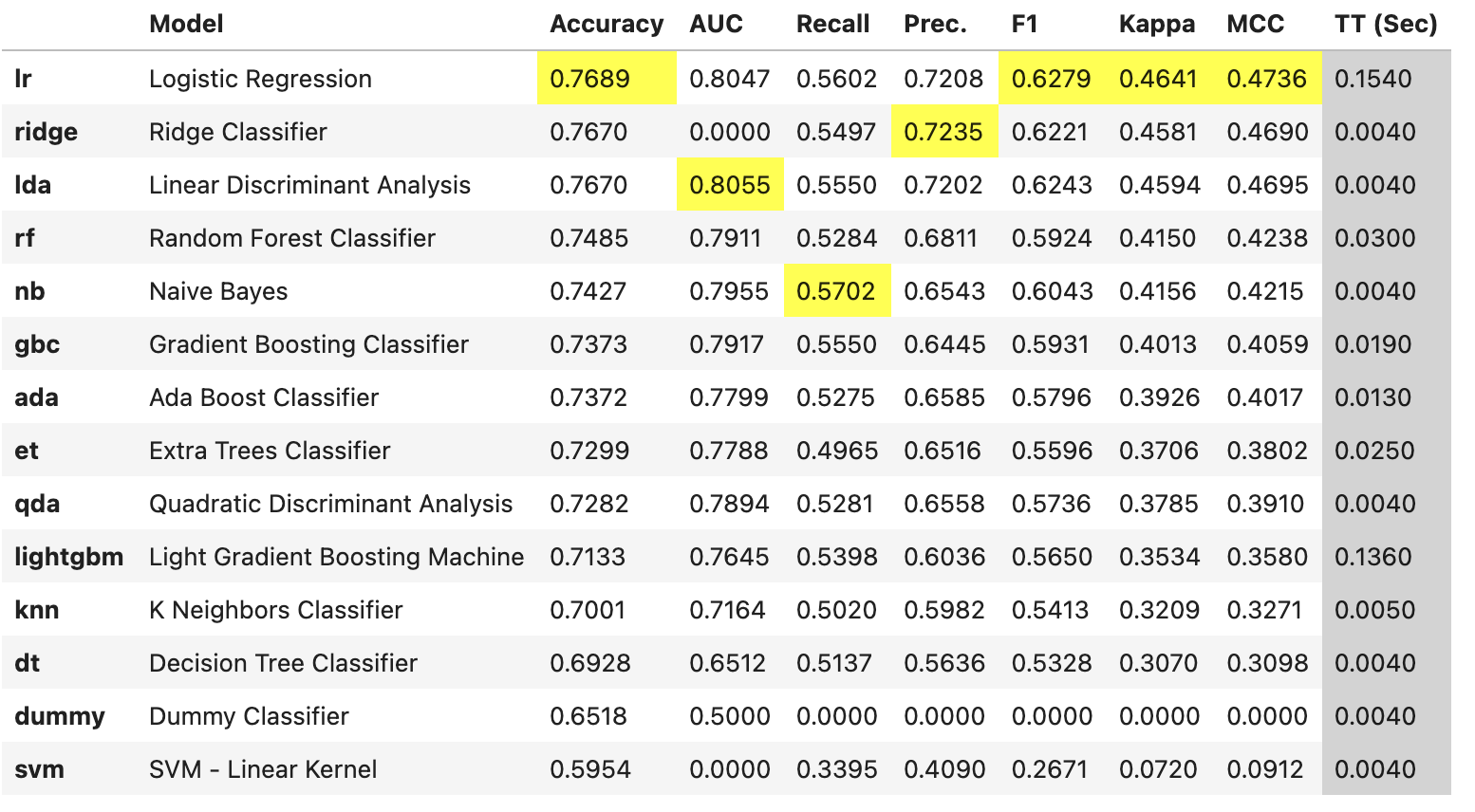
# OOP API
best = s.compare_models()3. Analyze Model
该函数分析训练模型在测试集上的性能。 在某些情况下可能需要重新训练模型。
# functional API
evaluate_model(best)
# OOP API
s.evaluate_model(best)evaluate_model 只能在 Notebook 中使用,因为它使用 ipywidget 。 您还可以使用plot_model函数单独生成图。
# functional API
plot_model(best, plot = 'auc')
# OOP API
s.plot_model(best, plot = 'auc')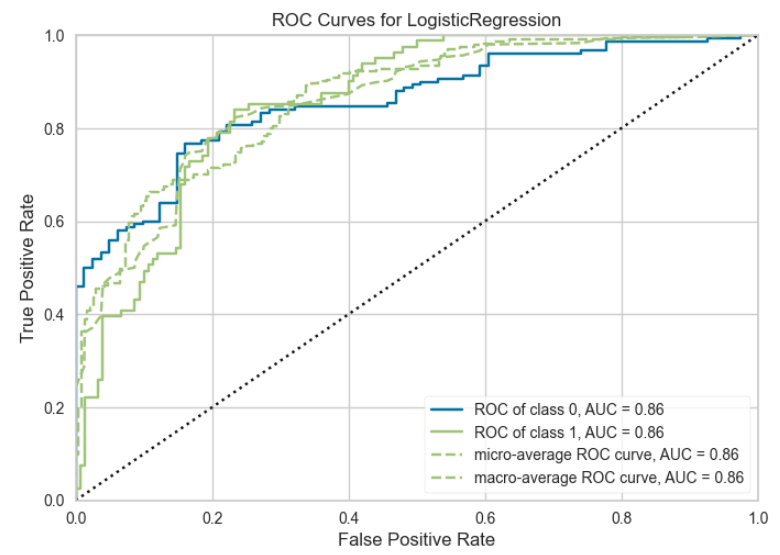
# functional API
plot_model(best, plot = 'confusion_matrix')
# OOP API
s.plot_model(best, plot = 'confusion_matrix')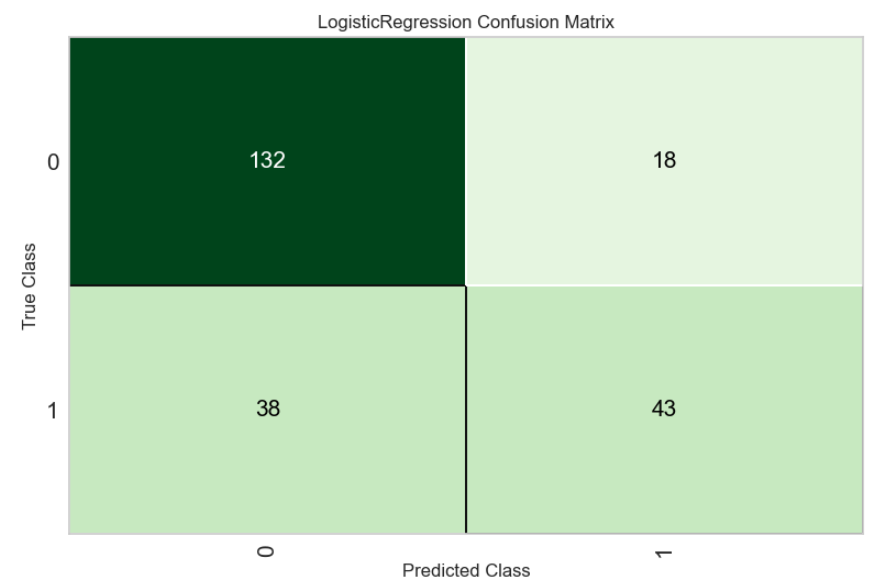
4. Predictions
该函数对数据进行评分并返回预测类别的prediction_label和prediction_score概率)。 当数据为 None 时,它预测测试集上的标签和分数(在设置函数期间创建)。
# functional API
predict_model(best)
# OOP API
s.predict_model(best)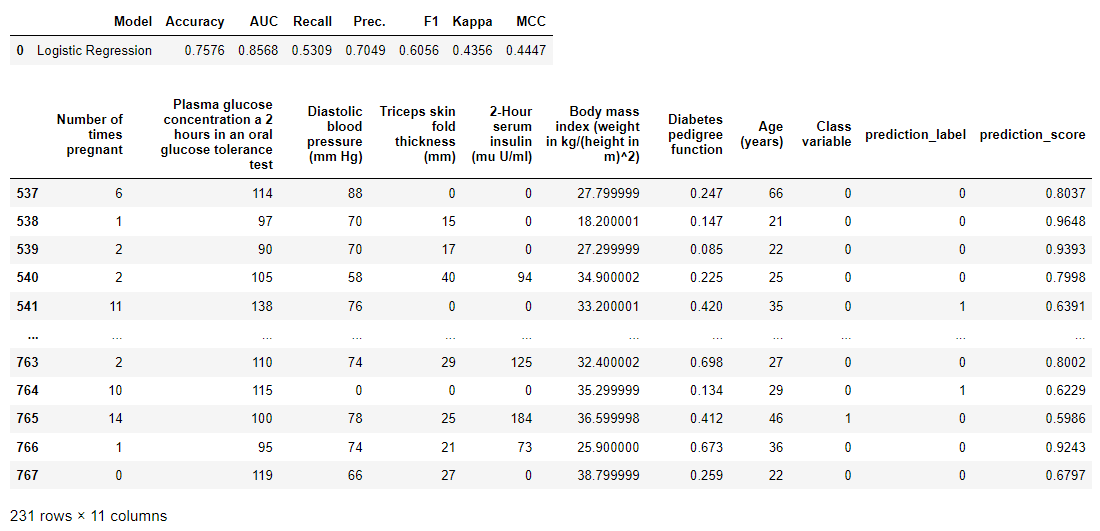
评估指标是在测试集上计算的。 第二个输出是 pd.DataFrame,其中包含对测试集的预测(请参阅最后两列)。 要在未见过的(新)数据集上生成标签,只需将数据集传递到 Predict_model 函数下的 data 参数中即可。
# functional API
predictions = predict_model(best, data=data)
predictions.head()
# OOP API
predictions = s.predict_model(best, data=data)
predictions.head()分数表示预测类别(不是正类)的概率。 如果prediction_label为0且prediction_score为0.90,这意味着类0的概率为90%。如果您想查看这两个类的概率,只需在predict_model函数中传递raw_score=True即可。
# functional API
predictions = predict_model(best, data=data, raw_score=True)
predictions.head()
# OOP API
predictions = s.predict_model(best, data=data, raw_score=True)
predictions.head()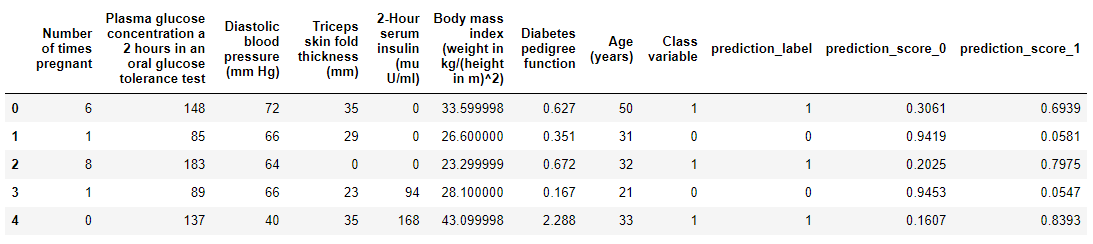
5. Save the model
# functional API
save_model(best, 'my_best_pipeline')
# OOP API
s.save_model(best, 'my_best_pipeline')6. To load the model back in environment:
# functional API
loaded_model = load_model('my_best_pipeline')
print(loaded_model)
# OOP API
loaded_model = s.load_model('my_best_pipeline')
print(loaded_model)遇到的错误
1. 在mac电脑上,安装pycaret的时候遇到问题 “Could not build wheels for lightgbm, which is required to install pyproject.toml-based projects”
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for lightgbm
Failed to build lightgbm
ERROR: Could not build wheels for lightgbm, which is required to install pyproject.toml-based projects
解决方法
先运行brew install libomp, 再安装pip install pycaret
2. lib_lightgbm.so' (mach-o file, but is an incompatible architecture (have (x86_64), need (arm64e))
解决方法:
conda install \
--yes \
-c conda-forge \
'lightgbm>=3.3.3'python - Is LightGBM available for Mac M1? - Stack Overflow