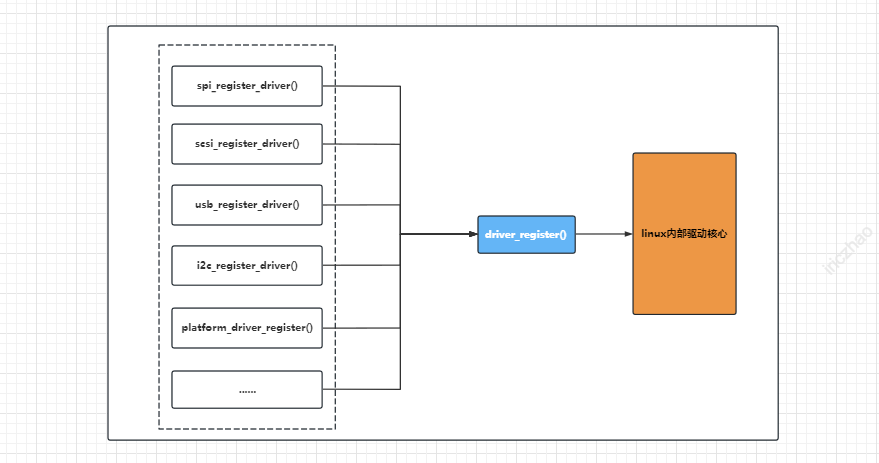
对称量化与非对称量化
量化分为对称量化与非对称量化。
非对称量化含有S和Z,对称量化Z为0,计算公式中只需S,为非饱和量化。
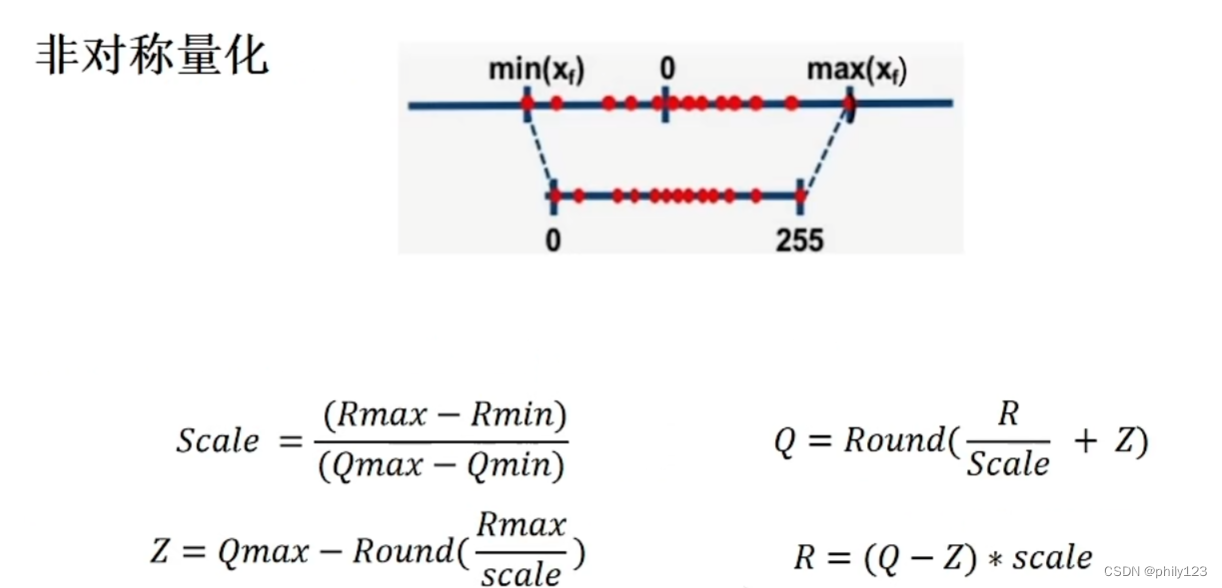
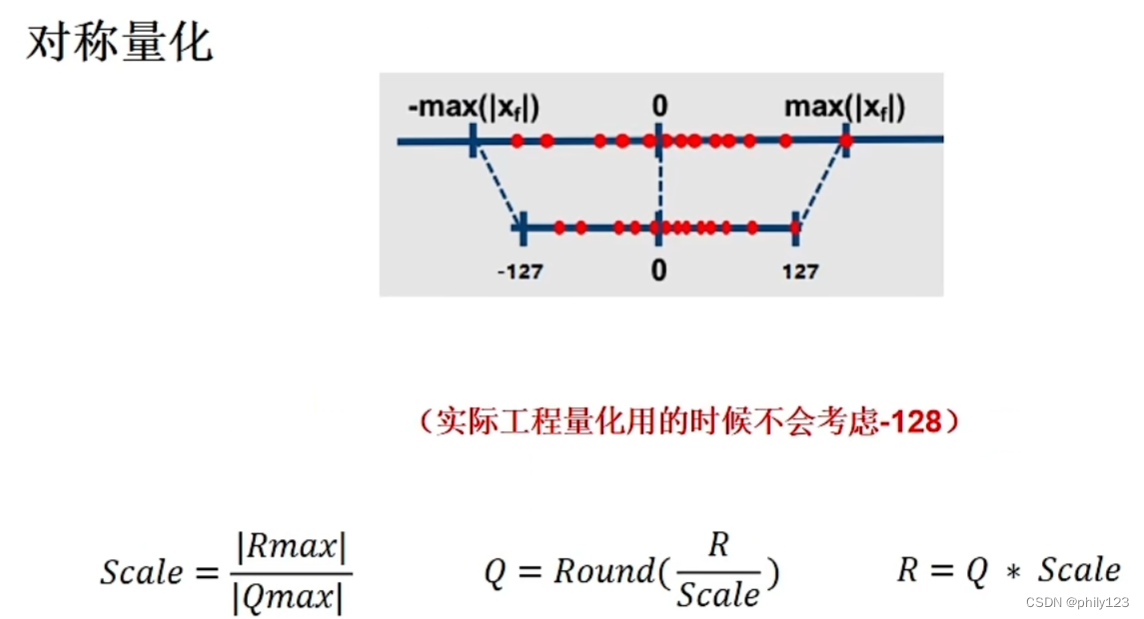
动态范围的确认
动态范围的确认Max(默认的是对称量化,即不用Z),Histgram和Entropy。
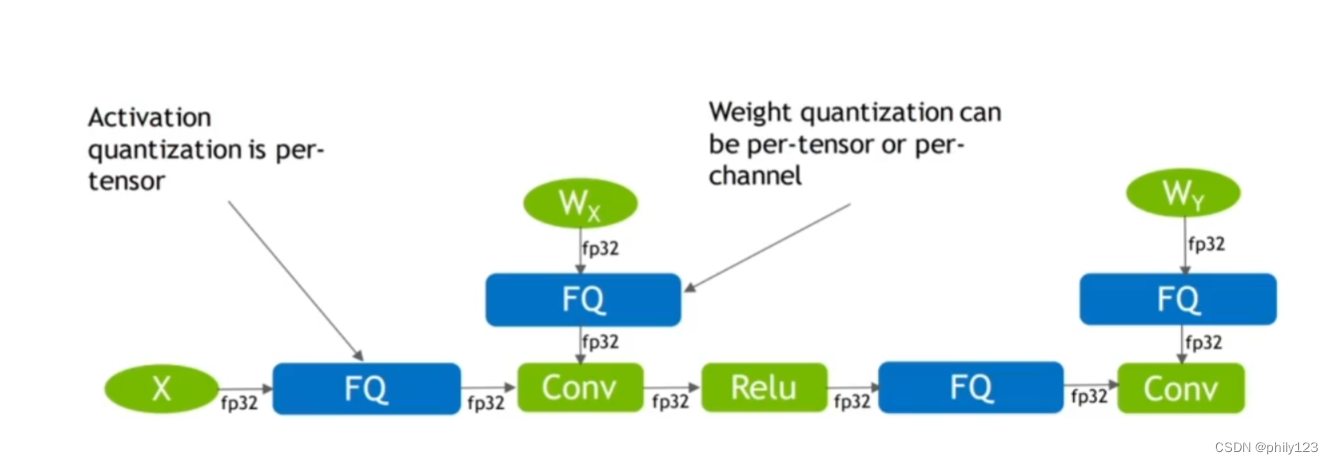
量化分为隐性量化和显性量化,区别在于显性量化含有QDQ节点。
隐式量化:PTQ且各层精度不可控。
显性量化:带QDQ节点的PTQ;带QDQ节点的QAT。
PTQ与QAT的区别是否用数据对模型进行finetune。
PTQ与QTA
PTQ
PTQ就是对训练好的模型进行量化,也就是对模型的权重与输入进行缩放。
流程:(1)获取校准数据(分布要与总体数据分布相同,为训练集子集);(2)获取预训练模型;(3)在网络中计算权重参数与激活值的动态范围计算出S;(4)对模型的权重参数(和激活值)进行量化得到量化参数;(5)获得量化后的模型。
优点是方便、速度快;缺点是无法手动设置某层的精度,某层的精度不可控。
QAT
流程:(1)获得预训练模型;(2)添加QAT算子;(3)对带有QAT算子的模型进行微调;(4)保存量化后的参数;(5)获得量化后的模型。
优点:每层精度可控;缺点:速度较慢。
例子
from pytorch_quantization import tensor_quant
import torch
torch.manual_seed(123)
x = torch.rand(10)
fake_quant_x = tensor_quant.fake_tensor_quant(x,x.abs().max())
print(x)
print(fake_quant_x)
tensor([0.2961, 0.5166, 0.2517, 0.6886, 0.0740, 0.8665, 0.1366, 0.1025, 0.1841,
0.7264])
tensor([0.2934, 0.5185, 0.2525, 0.6891, 0.0751, 0.8665, 0.1365, 0.1023, 0.1842,
0.7232])
对于模型输入tensor,是per tensor的,即只有一个scale;对于模型的权重,是per channel,即scale的个数等于channel数。
import torch
import torchvision
from pytorch_quantization import tensor_quant
from pytorch_quantization import quant_modules
from pytorch_quantization import nn as quant_nn
quant_modules.initialize()
model = torchvision.models.resnet50()
model.cuda()
inputs = torch.randn(1, 3, 224, 224, device='cuda')
quant_nn.TensorQuantizer.use_fb_fake_quant = True
torch.onnx.export(model, inputs, 'quant_resnet50.onnx',opset_version=13)
带有QDQ算子的PTQ(显性量化)
(1)定义模型
(2)对模型插入QDQ
(3)统计QDQ节点的range和scale,对模型进行标定(calibrate),这时得到的是ptq模型
(4)做敏感层的分析:需要知道,哪一层对精度指标影响较大,关闭对精度影响大的层
(5)导出一个带有QDQ节点的模型
(6)对模型进行finetune,得到qat模型
#
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import datetime
import os
import sys
import time
import argparse
import warnings
import collections
import torch
import torch.utils.data
from torch import nn
from tqdm import tqdm
import torchvision
from torchvision import transforms
from torchvision.models.utils import load_state_dict_from_url
from pytorch_quantization import nn as quant_nn
from pytorch_quantization import calib
from pytorch_quantization.tensor_quant import QuantDescriptor
from pytorch_quantization import quant_modules
import onnxruntime
import numpy as np
import models
from prettytable import PrettyTable
# The following path assumes running in nvcr.io/nvidia/pytorch:20.08-py3
sys.path.insert(0,"/opt/pytorch/vision/references/classification/")
# Import functions from torchvision reference
try:
from train import evaluate, train_one_epoch, load_data, utils
except Exception as e:
raise ModuleNotFoundError(
"Add https://github.com/pytorch/vision/blob/master/references/classification/ to PYTHONPATH")
def get_parser():
"""
Creates an argument parser.
"""
parser = argparse.ArgumentParser(description='Classification quantization flow script')
parser.add_argument('--data-dir', '-d', type=str, help='input data folder', required=True)
parser.add_argument('--model-name', '-m', default='resnet50', help='model name: default resnet50')
parser.add_argument('--disable-pcq', '-dpcq', action="store_true", help='disable per-channel quantization for weights')
parser.add_argument('--out-dir', '-o', default='/tmp', help='output folder: default /tmp')
parser.add_argument('--print-freq', '-pf', type=int, default=20, help='evaluation print frequency: default 20')
parser.add_argument('--threshold', '-t', type=float, default=-1.0, help='top1 accuracy threshold (less than 0.0 means no comparison): default -1.0')
parser.add_argument('--batch-size-train', type=int, default=128, help='batch size for training: default 128')
parser.add_argument('--batch-size-test', type=int, default=128, help='batch size for testing: default 128')
parser.add_argument('--batch-size-onnx', type=int, default=1, help='batch size for onnx: default 1')
parser.add_argument('--seed', type=int, default=12345, help='random seed: default 12345')
checkpoint = parser.add_mutually_exclusive_group(required=True)
checkpoint.add_argument('--ckpt-path', default='', type=str,
help='path to latest checkpoint (default: none)')
checkpoint.add_argument('--ckpt-url', default='', type=str,
help='url to latest checkpoint (default: none)')
checkpoint.add_argument('--pretrained', action="store_true")
parser.add_argument('--num-calib-batch', default=4, type=int,
help='Number of batches for calibration. 0 will disable calibration. (default: 4)')
parser.add_argument('--num-finetune-epochs', default=0, type=int,
help='Number of epochs to fine tune. 0 will disable fine tune. (default: 0)')
parser.add_argument('--calibrator', type=str, choices=["max", "histogram"], default="max")
parser.add_argument('--percentile', nargs='+', type=float, default=[99.9, 99.99, 99.999, 99.9999])
parser.add_argument('--sensitivity', action="store_true", help="Build sensitivity profile")
parser.add_argument('--evaluate-onnx', action="store_true", help="Evaluate exported ONNX")
return parser
def prepare_model(
model_name,
data_dir,
per_channel_quantization,
batch_size_train,
batch_size_test,
batch_size_onnx,
calibrator,
pretrained=True,
ckpt_path=None,
ckpt_url=None):
"""
Prepare the model for the classification flow.
Arguments:
model_name: name to use when accessing torchvision model dictionary
data_dir: directory with train and val subdirs prepared "imagenet style"
per_channel_quantization: iff true use per channel quantization for weights
note that this isn't currently supported in ONNX-RT/Pytorch
batch_size_train: batch size to use when training
batch_size_test: batch size to use when testing in Pytorch
batch_size_onnx: batch size to use when testing with ONNX-RT
calibrator: calibration type to use (max/histogram)
pretrained: if true a pretrained model will be loaded from torchvision
ckpt_path: path to load a model checkpoint from, if not pretrained
ckpt_url: url to download a model checkpoint from, if not pretrained and no path was given
* at least one of {pretrained, path, url} must be valid
The method returns a the following list:
[
Model object,
data loader for training,
data loader for Pytorch testing,
data loader for onnx testing
]
"""
# Use 'spawn' to avoid CUDA reinitialization with forked subprocess
torch.multiprocessing.set_start_method('spawn')
## Initialize quantization, model and data loaders
if per_channel_quantization:
quant_desc_input = QuantDescriptor(calib_method=calibrator)
quant_nn.QuantConv2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantLinear.set_default_quant_desc_input(quant_desc_input)
else:
## Force per tensor quantization for onnx runtime
quant_desc_input = QuantDescriptor(calib_method=calibrator, axis=None)
quant_nn.QuantConv2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantConvTranspose2d.set_default_quant_desc_input(quant_desc_input)
quant_nn.QuantLinear.set_default_quant_desc_input(quant_desc_input)
quant_desc_weight = QuantDescriptor(calib_method=calibrator, axis=None)
quant_nn.QuantConv2d.set_default_quant_desc_weight(quant_desc_weight)
quant_nn.QuantConvTranspose2d.set_default_quant_desc_weight(quant_desc_weight)
quant_nn.QuantLinear.set_default_quant_desc_weight(quant_desc_weight)
if model_name in models.__dict__:
model = models.__dict__[model_name](pretrained=pretrained, quantize=True)
else:
quant_modules.initialize()
model = torchvision.models.__dict__[model_name](pretrained=pretrained)
quant_modules.deactivate()
if not pretrained:
if ckpt_path:
checkpoint = torch.load(ckpt_path)
else:
checkpoint = load_state_dict_from_url(ckpt_url)
if 'state_dict' in checkpoint.keys():
checkpoint = checkpoint['state_dict']
elif 'model' in checkpoint.keys():
checkpoint = checkpoint['model']
model.load_state_dict(checkpoint)
model.eval()
model.cuda()
## Prepare the data loaders
traindir = os.path.join(data_dir, 'train')
valdir = os.path.join(data_dir, 'val')
_args = collections.namedtuple("mock_args", ["model", "distributed", "cache_dataset"])
dataset, dataset_test, train_sampler, test_sampler = load_data(
traindir, valdir, _args(model=model_name, distributed=False, cache_dataset=False))
data_loader_train = torch.utils.data.DataLoader(
dataset, batch_size=batch_size_train,
sampler=train_sampler, num_workers=4, pin_memory=True)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size_test,
sampler=test_sampler, num_workers=4, pin_memory=True)
data_loader_onnx = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size_onnx,
sampler=test_sampler, num_workers=4, pin_memory=True)
return model, data_loader_train, data_loader_test, data_loader_onnx
def main(cmdline_args):
parser = get_parser()
args = parser.parse_args(cmdline_args)
print(parser.description)
print(args)
torch.manual_seed(args.seed)
np.random.seed(args.seed)
## Prepare the pretrained model and data loaders
model, data_loader_train, data_loader_test, data_loader_onnx = prepare_model(
args.model_name,
args.data_dir,
not args.disable_pcq,
args.batch_size_train,
args.batch_size_test,
args.batch_size_onnx,
args.calibrator,
args.pretrained,
args.ckpt_path,
args.ckpt_url)
## Initial accuracy evaluation
criterion = nn.CrossEntropyLoss()
with torch.no_grad():
print('Initial evaluation:')
top1_initial = evaluate(model, criterion, data_loader_test, device="cuda", print_freq=args.print_freq)
## Calibrate the model
with torch.no_grad():
calibrate_model(
model=model,
model_name=args.model_name,
data_loader=data_loader_train,
num_calib_batch=args.num_calib_batch,
calibrator=args.calibrator,
hist_percentile=args.percentile,
out_dir=args.out_dir)
## Evaluate after calibration
if args.num_calib_batch > 0:
with torch.no_grad():
print('Calibration evaluation:')
top1_calibrated = evaluate(model, criterion, data_loader_test, device="cuda", print_freq=args.print_freq)
else:
top1_calibrated = -1.0
## Build sensitivy profile
if args.sensitivity:
build_sensitivity_profile(model, criterion, data_loader_test)
## Finetune the model
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.0001)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, args.num_finetune_epochs)
for epoch in range(args.num_finetune_epochs):
# Training a single epch
train_one_epoch(model, criterion, optimizer, data_loader_train, "cuda", 0, 100)
lr_scheduler.step()
if args.num_finetune_epochs > 0:
## Evaluate after finetuning
with torch.no_grad():
print('Finetune evaluation:')
top1_finetuned = evaluate(model, criterion, data_loader_test, device="cuda")
else:
top1_finetuned = -1.0
## Export to ONNX
onnx_filename = args.out_dir + '/' + args.model_name + ".onnx"
top1_onnx = -1.0
if export_onnx(model, onnx_filename, args.batch_size_onnx, not args.disable_pcq) and args.evaluate_onnx:
## Validate ONNX and evaluate
top1_onnx = evaluate_onnx(onnx_filename, data_loader_onnx, criterion, args.print_freq)
## Print summary
print("Accuracy summary:")
table = PrettyTable(['Stage','Top1'])
table.align['Stage'] = "l"
table.add_row( [ 'Initial', "{:.2f}".format(top1_initial) ] )
table.add_row( [ 'Calibrated', "{:.2f}".format(top1_calibrated) ] )
table.add_row( [ 'Finetuned', "{:.2f}".format(top1_finetuned) ] )
table.add_row( [ 'ONNX', "{:.2f}".format(top1_onnx) ] )
print(table)
## Compare results
if args.threshold >= 0.0:
if args.evaluate_onnx and top1_onnx < 0.0:
print("Failed to export/evaluate ONNX!")
return 1
if args.num_finetune_epochs > 0:
if top1_finetuned >= (top1_onnx - args.threshold):
print("Accuracy threshold was met!")
else:
print("Accuracy threshold was missed!")
return 1
return 0
def evaluate_onnx(onnx_filename, data_loader, criterion, print_freq):
"""Evaluate accuracy on the given ONNX file using the provided data loader and criterion.
The method returns the average top-1 accuracy on the given dataset.
"""
print("Loading ONNX file: ", onnx_filename)
ort_session = onnxruntime.InferenceSession(onnx_filename)
with torch.no_grad():
metric_logger = utils.MetricLogger(delimiter=" ")
header = 'Test:'
with torch.no_grad():
for image, target in metric_logger.log_every(data_loader, print_freq, header):
image = image.to("cpu", non_blocking=True)
image_data = np.array(image)
input_data = image_data
# run the data through onnx runtime instead of torch model
input_name = ort_session.get_inputs()[0].name
raw_result = ort_session.run([], {input_name: input_data})
output = torch.tensor((raw_result[0]))
loss = criterion(output, target)
acc1, acc5 = utils.accuracy(output, target, topk=(1, 5))
batch_size = image.shape[0]
metric_logger.update(loss=loss.item())
metric_logger.meters['acc1'].update(acc1.item(), n=batch_size)
metric_logger.meters['acc5'].update(acc5.item(), n=batch_size)
# gather the stats from all processes
metric_logger.synchronize_between_processes()
print(' ONNXRuntime: Acc@1 {top1.global_avg:.3f} Acc@5 {top5.global_avg:.3f}'
.format(top1=metric_logger.acc1, top5=metric_logger.acc5))
return metric_logger.acc1.global_avg
def export_onnx(model, onnx_filename, batch_onnx, per_channel_quantization):
model.eval()
quant_nn.TensorQuantizer.use_fb_fake_quant = True # We have to shift to pytorch's fake quant ops before exporting the model to ONNX
if per_channel_quantization:
opset_version = 13
else:
opset_version = 12
# Export ONNX for multiple batch sizes
print("Creating ONNX file: " + onnx_filename)
dummy_input = torch.randn(batch_onnx, 3, 224, 224, device='cuda') #TODO: switch input dims by model
try:
torch.onnx.export(model, dummy_input, onnx_filename, verbose=False, opset_version=opset_version, enable_onnx_checker=False, do_constant_folding=True)
except ValueError:
warnings.warn(UserWarning("Per-channel quantization is not yet supported in Pytorch/ONNX RT (requires ONNX opset 13)"))
print("Failed to export to ONNX")
return False
return True
def calibrate_model(model, model_name, data_loader, num_calib_batch, calibrator, hist_percentile, out_dir):
"""
Feed data to the network and calibrate.
Arguments:
model: classification model
model_name: name to use when creating state files
data_loader: calibration data set
num_calib_batch: amount of calibration passes to perform
calibrator: type of calibration to use (max/histogram)
hist_percentile: percentiles to be used for historgram calibration
out_dir: dir to save state files in
"""
if num_calib_batch > 0:
print("Calibrating model")
with torch.no_grad():
collect_stats(model, data_loader, num_calib_batch)
if not calibrator == "histogram":
compute_amax(model, method="max")
calib_output = os.path.join(
out_dir,
F"{model_name}-max-{num_calib_batch*data_loader.batch_size}.pth")
torch.save(model.state_dict(), calib_output)
else:
for percentile in hist_percentile:
print(F"{percentile} percentile calibration")
compute_amax(model, method="percentile")
calib_output = os.path.join(
out_dir,
F"{model_name}-percentile-{percentile}-{num_calib_batch*data_loader.batch_size}.pth")
torch.save(model.state_dict(), calib_output)
for method in ["mse", "entropy"]:
print(F"{method} calibration")
compute_amax(model, method=method)
calib_output = os.path.join(
out_dir,
F"{model_name}-{method}-{num_calib_batch*data_loader.batch_size}.pth")
torch.save(model.state_dict(), calib_output)
def collect_stats(model, data_loader, num_batches):
"""Feed data to the network and collect statistics"""
# Enable calibrators
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
# Feed data to the network for collecting stats
for i, (image, _) in tqdm(enumerate(data_loader), total=num_batches):
model(image.cuda())
if i >= num_batches:
break
# Disable calibrators
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.enable_quant()
module.disable_calib()
else:
module.enable()
def compute_amax(model, **kwargs):
# Load calib result
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax(**kwargs)
print(F"{name:40}: {module}")
model.cuda()
def build_sensitivity_profile(model, criterion, data_loader_test):
quant_layer_names = []
for name, module in model.named_modules():
if name.endswith("_quantizer"):
module.disable()
layer_name = name.replace("._input_quantizer", "").replace("._weight_quantizer", "")
if layer_name not in quant_layer_names:
quant_layer_names.append(layer_name)
for i, quant_layer in enumerate(quant_layer_names):
print("Enable", quant_layer)
for name, module in model.named_modules():
if name.endswith("_quantizer") and quant_layer in name:
module.enable()
print(F"{name:40}: {module}")
with torch.no_grad():
evaluate(model, criterion, data_loader_test, device="cuda")
for name, module in model.named_modules():
if name.endswith("_quantizer") and quant_layer in name:
module.disable()
print(F"{name:40}: {module}")
if __name__ == '__main__':
res = main(sys.argv[1:])
exit(res)