第六章 查找
- 基本概念
- 静态查找表
- 顺序表上的查找
- 有序表上的查找
- 索引顺序表上的查找
- 二叉排序树
- 散列表
- 常见散列法
- 散列表的实现
- 小试牛刀
基本概念
- 查找表是由同一类型的数据元素构成的集合,它是一种以查找为“核心”,同时包括其他运算的非常灵活的数据结构
- 查找就是从大量的数据元素中找出某个指定的数据元素。
- 关键字,简称键是数据元素中某个数据项;关键字分为主关键字和次关键字,主关键字可以唯一标识一个数据元素(一行);次关键字可以识别若干数据元素(多行)
- 静态查找表包括下列三种基本运算:
- 建表Create(ST):操作结果是生成一个由用户给定的若干数据元素组成的静态查找表ST
- 查找Search(ST,key):若ST中存在关键字值等于key的数据元素,操作结果为该数据元素的值,否则操作结果为空
- 读表中元素Get(ST,pos):若ST中存在关键字值等于key的数据元素,操作结果为该数据元素的值,否则操作结果为空
- 动态查找表包括以下五种基本运算:
- 初始化Initiate(ST):设置一个空的动态查找表ST
- 查找Search(ST,key):同静态查找表
- 读表中元素Get(ST,pos):同静态查找表
- 插入Insert(ST,key):若ST中不存在关键字值等于key的元素,则将一个关键字值等于key的新元素插入到ST中
- 删除Delete(ST,key):当ST中存在关键字值等于key的元素时,将其删除
静态查找表
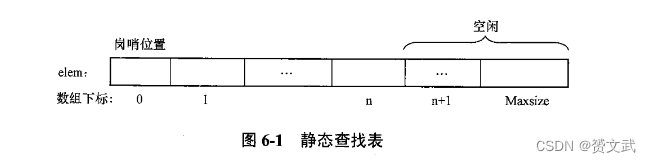
顺序表上的查找
- 将静态查找表中的数据元素存放在上述数组的第1到n个单元格中,第n+1备用,第0个元素设置“岗哨或参照”、
查找算法描述如下:
int SearchSqTable(SqTable T,KeyType key)
{
T.elem[0].key=key; //设置岗哨
i=T.n
while(T.elem[i].key!=key)
i--; //未找到,修改位置继续查找
return i;
}
有序表上的查找
- 顺序表中数据元素是按照键值大小顺序排列的,称为有序表
- 二分查找:每次用给定值与处在表的中间位置的数据元素的键值进行比较,确定给定值所在的区间,逐步缩小查找区间,直到找到该元素;算法描述如下:
int Search(SqTable T,KeyType key)
{
int low,high;
low=1;high=T.n; //置查找区间初值
while(low<=high)
{
mid=(low+high)/2 //对区间折半,/为整除
if(key==T.elem[mid].key) return mid;
else if (key<T.elem[mid].key) high=mid-1; //在前半区间查找
else low=mid+1; //在后半区间查找
}
return 0; //找不到返回0
}
- 思考:现有一个含有9个数据元素的有序表(关键字即为数据元素的值):(10,13,17,20,30,55,68,89,95)请给出用二分查找算法查找key=17的过程
索引顺序表上的查找
- 索引顺序表由两部分组成:索引表:通过索引将顺序表分割为若干块;顺序表:存储数据使之呈现按块有序的性质
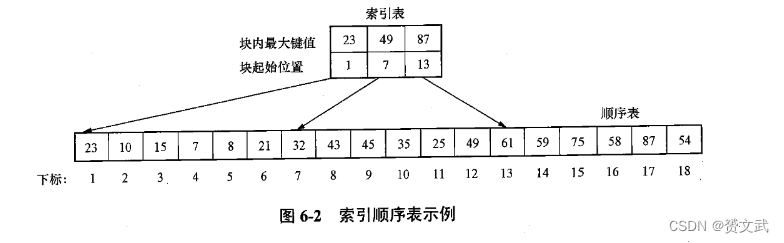
- 按块有序指顺序表中数据元素被划分成一些子块,并且对其中任意两个相邻资本来说,排在后面的子表中的任一数据元素的键值大于排在前面的子表中的所有数据元素的键值
- 对于顺序表中的每一块,索引表中有相应的一个索引项。每个索引项分为块内最大键值和块初始位置
- 索引顺序表上的查找即分块查找可以分两步进行:
- 确定待查数据元素所在块,
- 在块内顺序查找
注:分块查找时间性能高于顺序查找低于二分查找,但分块查找不要求存储结构中数据元素按键值有序
二叉排序树
- 一棵二叉排序树或者是一棵空二叉树,或者具有如下性质:
- 若它的左子树不空,则左子树上所有结点的键值均小于它的根结点键值
- 若它的右子树不空,则右子树上所有结点的键值均大于它的根结点键值
- 根的左右子树也分别为二叉排序树
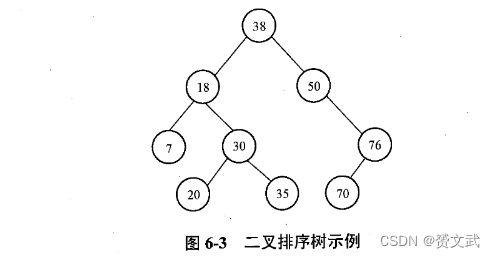
- 二叉排序树上的查找:要找键值比某结点键值小的结点,只需通过该结点的左指针到它的左子树 中去找;算法描述如下:
BinTree SearchBST(BinTree bst,KeyTree key)
//在根指针bst所指的二叉排序树上递归的查找键值等于key的结点,若成功,则返回指向该结点的指针,否则返回空指针
{
if(bst==NULL) return NULL; //不成功返回NULLL作为标记
else if(key==bst->key) return bst; //成功返回结点地址
else if(key<bst->key)
return SearchBST(bst->lchild,key); //继续在左子树查找
else
return SearchBST(bst->rchild,key); //继续在右子树中查找
}
- 二叉排序树的插入:必须保证插入一个新结点后,仍为一棵二叉排序树
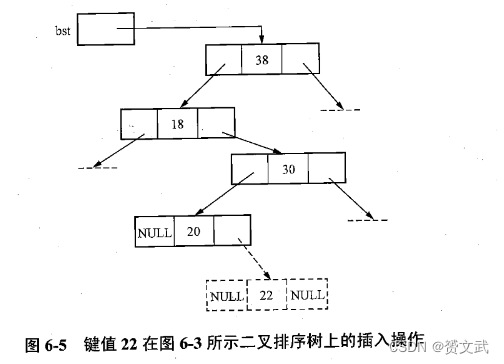
- 二叉排序树上的平均查找长度ASL<=1+log2n介于O(n)和O(log2n)之间
散列表
- 数据元素的键值和存储位置之间建立的对于关系H称为散列函数
- 用键值通过散列函数获取存储位置的这种存储方式构造的存储结构称为散列表
- 用键值通过散列函数获取存储位置的过程称为散列
- 设有散列函数H和键值k1、k2,若k1!=k2,但是H(k1)=H(k2),则这种现象称为冲突,且称k1、k2是相对于H 的同义词
常见散列法
- 数字分析法(又称数字选择法),收集所有可能出现的键值,排列在一起,对键值的每一位进行分析,选择分布较均匀的若干位组成散列地址。所取的位数取决于散列表的表长
- 除留余数法(常用),选择一个不大于散列表长n的正整数p,以键值除以p所得的余数作为散列地址:
H(key)=key mod p (p<=n)
- 平方取中法:以键值平方的中间几位作为散列地址
- 基数转换法:将键值看成另一种进制的数再转换成原来进制的数,然后选其中几位作为散列地址
散列表的实现
-
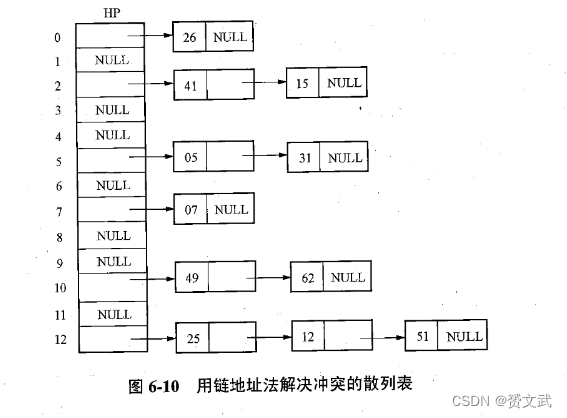
解决冲突的方法:
- 线性探测法(先按构造方法求散列地址若冲突则往后移动直到不冲突):对任何键值key,设H(key)=d,设散列表的容量为m;线性探测法容易产生堆积
- 二次探测法:生成的后继散列地址不是连续的,而是跳跃式的,以便为后续数据元素留下空间以减少堆积,二次探测法不易探测到整个散列表的所有空间:
d0=H(key)
di=(d0+i) mod m (i=12,–12,22,-22,…,±k2(k<=m/2))- 链地址法:对每一个同义词都建一个单链表解决冲突
- 多重散列法:设立多规格散列函数,当给定值与散列表中某个键值是相对于某个函数的同义词而冲突时,则换一个函数继续计算散列地址,直到不产生冲突为止;优点:不容易产生“堆积”,计算量大
- 公共溢出区法:散列表由两个一维数组组成,一个为基本表,一个为溢出表,插入首先在基本表进行,发生冲突则将同义词存入溢出表
小试牛刀
- 一个有序表含有22个数据元素,且第一个元素下标为1,按二分查找方法查找元素A[16],所比较元素下标依次是______
- 二分查找算法的时间复杂度为______
- 索引顺序查找通常分两个阶段进行,首先采用顺序查找法或_______确定所要查找的块,然后再用顺序查找法在块中找到具体的元素
- 在散列函数H(k)=k mod m 中,一般来讲,m应取______
- 数据在计算机存储器内表示时,根据结点的关键字直接计算出该结点的存储地址,这种方法称为_________
- 给定有序表D={006,087,155,188,220,465,505,508,511,586,656,670,700,766},用二分查找法在D中查找511,试给出查找过程