目录
- 生成式学习的两种策略
- 生成的物件介绍
- 文句
- 影像
- 语音
- 策略一:各个击破(Autoregressive (AR) model
- 策略二:一次到位(Non-autoregressive (NAR) model)
- 二者的比较
- 其他策略
- 二合一
- 多次到位
- AIGC工具
- New Bing
- WebGPT
- WebGPT原理:搜索引擎+文字接龙
- WebGPT的训练
- Toolformer
- 生成训练数据
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索
本节对应两个视频。
生成式学习的两种策略
生成的物件介绍
文句
文句最小单位是Token,在中文中指字,英文中指Word piece,例如单词unbelievable的token为:un believ able
英文为什么不用单词作为token?
因为通过之前的学习我们知道,AIGC在微观上来看是一个分类问题,因此我们需要为模型提供所有可能的分类,而英语单词理论上来讲是无穷多的(因为里面有各种专有名词、人名、地名等),只能用更小的Word piece来对英文进行分类。
影像
影像由像素组成
谷歌的Imagen Video例子:
A teddy bear washing dishes.

A bunch of autumn leaves falling on a calm lake to form the text ‘Imagen Video’. Smooth.



语音
语言由采样点组成,例如一个16k采样率的声音信号,每秒有1.6w个采样点。
这里是语音生成不再是简单的将文字转成语音,而是还可以指定语调,例如:

腾讯出品:
http://dongchaoyang.top/InstructTTS/
还可以直接生成指定的声音,例如:
Two space shuttles are fighting in the space.
还有生成海的声音,当然我们不知道如何描述海的声音,因此先找ChatGPT先生成描述:
Describe the sound of the ocean
ChatGPT: The steady crashing of waves against the shore,high fidelity, the whooshing sound of water receding back into the ocean, the sound of seagulls and other coastal birds, and the distant sound of ships or boats.
当然还有比较有意思的,生成三章不同环境的音效:
A man is speaking in a huge room.
A man is speaking in a small room.
A man is speaking in a studio.
这里man的语言当然是我们听不懂的,如果这里的例子改为:
A man is speaking Cantonese in a huge room.
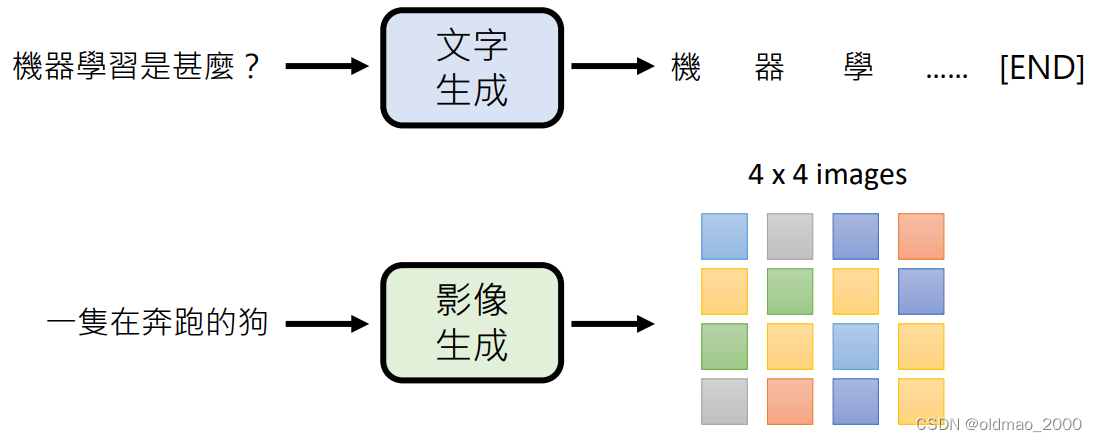
策略一:各个击破(Autoregressive (AR) model
)
一次生成一个部分,对于文字就是一次生成一个字,对于图像则是一次生成一个像素。
之前的课程里面就有用VAE一次生成一个像素的方式生成宝可梦的例子:https://blog.csdn.net/oldmao_2001/article/details/104023892
策略二:一次到位(Non-autoregressive (NAR) model)
一次将所有物件产生出来。文字就是一次把所有token都生成,图像就是把所有像素都生成。
由于物件是一次生成的,那模型如何知道停止输出呢?
第一种方式生成固定长度的结果,例如下图中的上半部分,当然如果在生成过程中有结束符号[END],则后面的内容可以直接忽略。
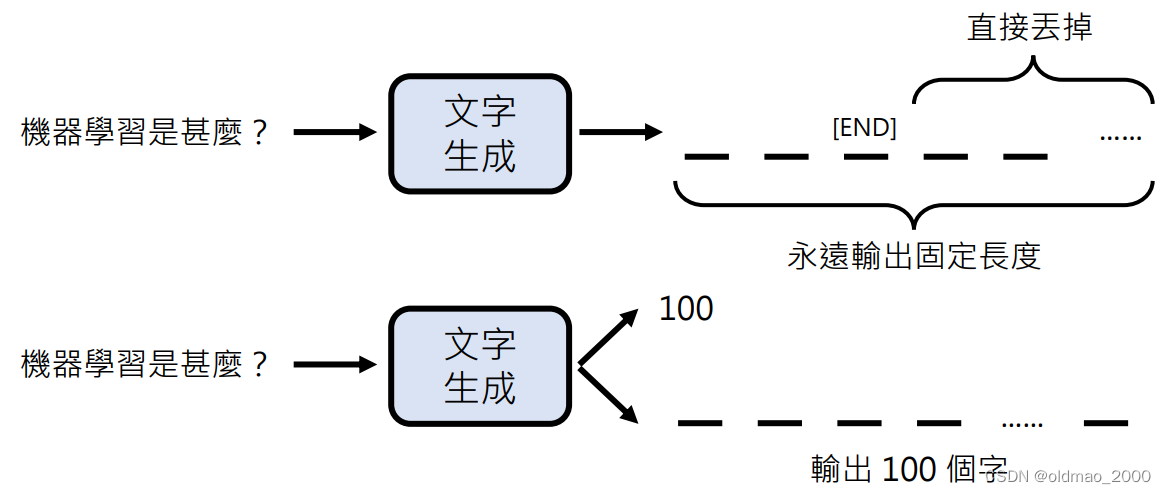
第二种方式是先生成一个数字,例如上图中的下半部分
二者的比较
直接上结论:
| AR | NAR | |
|---|---|---|
| 速度 | 慢 | 快 |
| 质量 | 高 | 低 |
| 应用 | 文字 | 图像 |
AR速度慢,因为每个字/像素都要等待前面一个字/像素生成后才能生成;
NAR 速度快,而且可以加上并行计算。
至于生成质量,看下图就可以知道了:
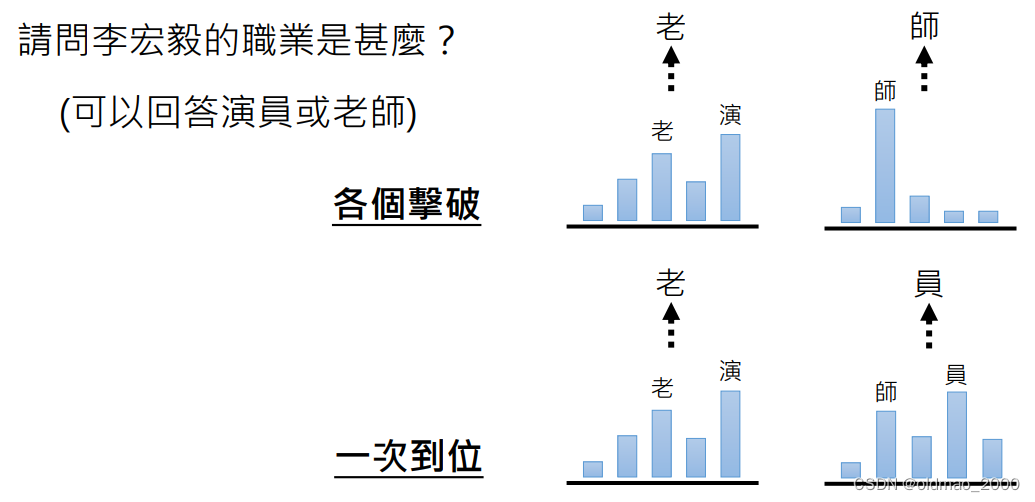
一次到位在采样过程中无法考虑上下文关系,因此会得到怪异的结果。
其他策略
二合一
早期在16年曾经有个wavenet,一次生成一个采样点,使用各个击破的方式来生成语音,由于采样点数量太大,因此生成速度非常慢。因此,将语音合成分成两个阶段:
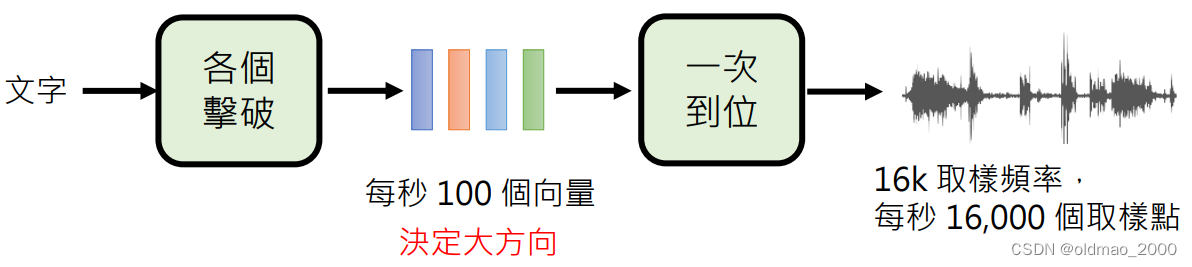
多次到位
每次产生比较模糊的图片,然逐渐清晰:
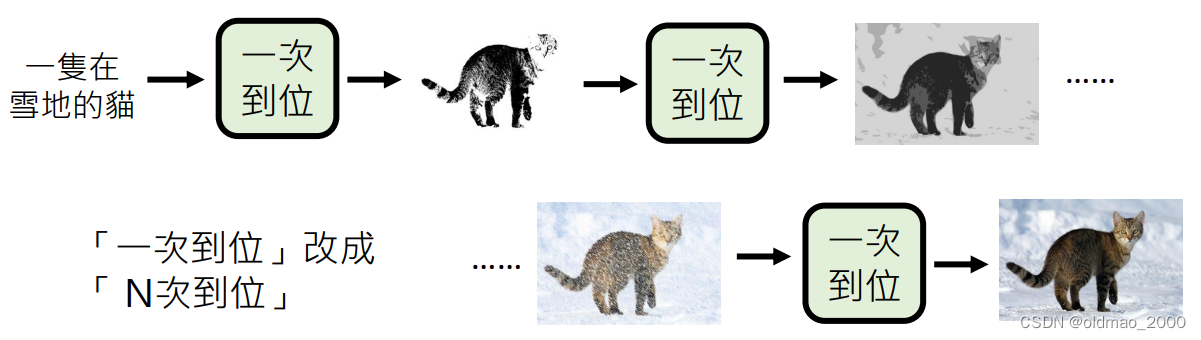
这也是Diffusion Model的思想。
AIGC工具
New Bing
微软的bing,貌似国内无法使用,需要科学上网后,登录微软账号就可以在左上角的聊天按钮中启动对话
与ChatGPT不一样的是,New Bing会联网,例如:
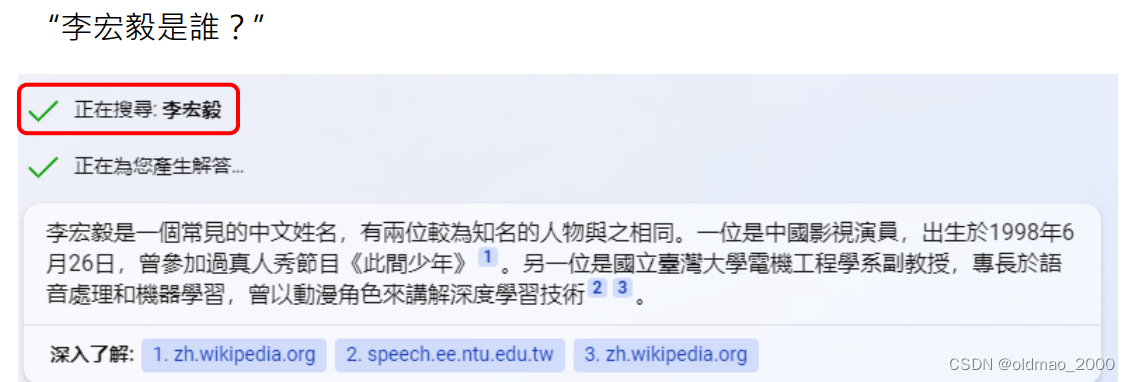
可以看到回答中标注出了从哪个网页中找到的内容。
联网过程中:
何时进行联网由模型自己决定,同一个问题可以联网也可能不联网,表现出一定随机性。
一个问题中会对多个专有名词进行联网查询。
即使是联网给出结果也不一定是事实。
New Bing+官方介绍有大概写了她的构架(普罗米修斯Prometheus):
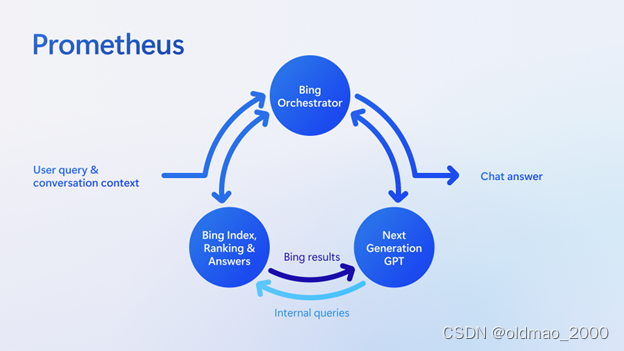
微软把用网络增强生成式模型的技术称为:Bing grounding technique
这与现有的WebGPT模型相似:

WebGPT
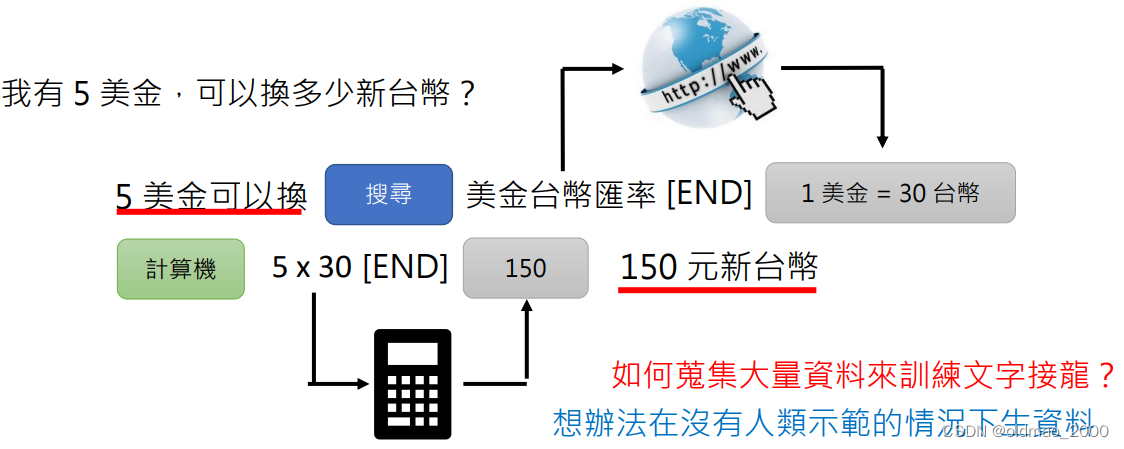
WebGPT原理:搜索引擎+文字接龙
以下面问题为例:
高雄过去有哪些名称?
先会判断是否要进行网络搜索,如果要则会先生成一个标志(蓝色长方形),并生成要搜索的关键句,最后以[END]结束。

得到结果:
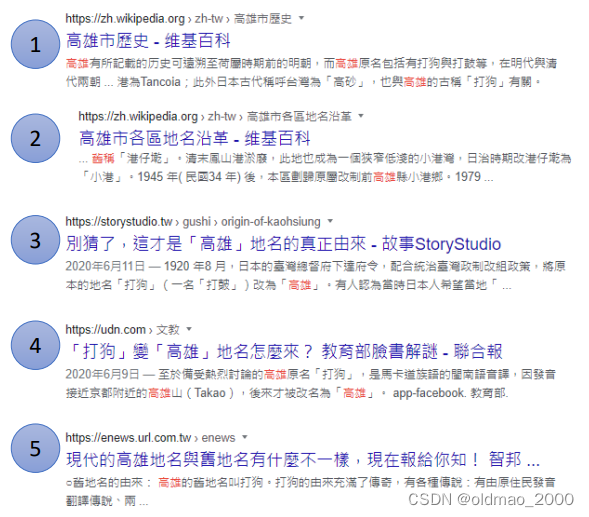
模型会生成另外一个标志(绿色长方形),表示要选择第几个搜索结果:

得到:
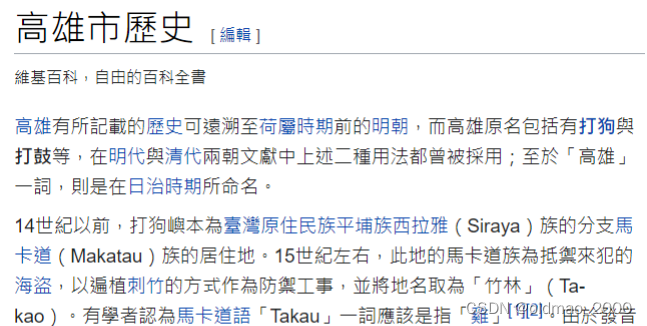
在实作上,模型不会读取整个网页,而是选择其中某个段落而已。
模型会生成第三个标志(橙色长方形),将上面搜索得到的具体结果收藏进来。

以上步骤可以执行多次,因为搜索的关键句有多种表达方式,例如:

搜索完毕后,模型会生成第四个标志(浅蓝色长方形),开始进入回答,将收藏的内容拿出来,开始文字接龙:

最后得到的结果如下:

WebGPT的训练
这里有收集人类查询的步骤:
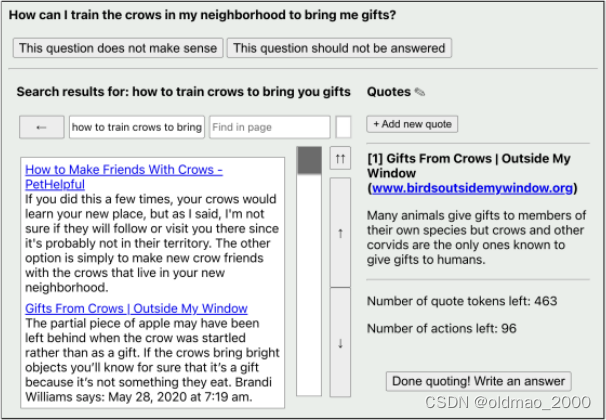
从图中可以看到,最上面会先判断这个搜索语句是不是有意义的,如果有,则会进入到下面的搜索框。人会根据搜索结果选择需要引用的链接(可以进行多次),完成后点右下角的按钮表示完成搜索进入生成答案环节。
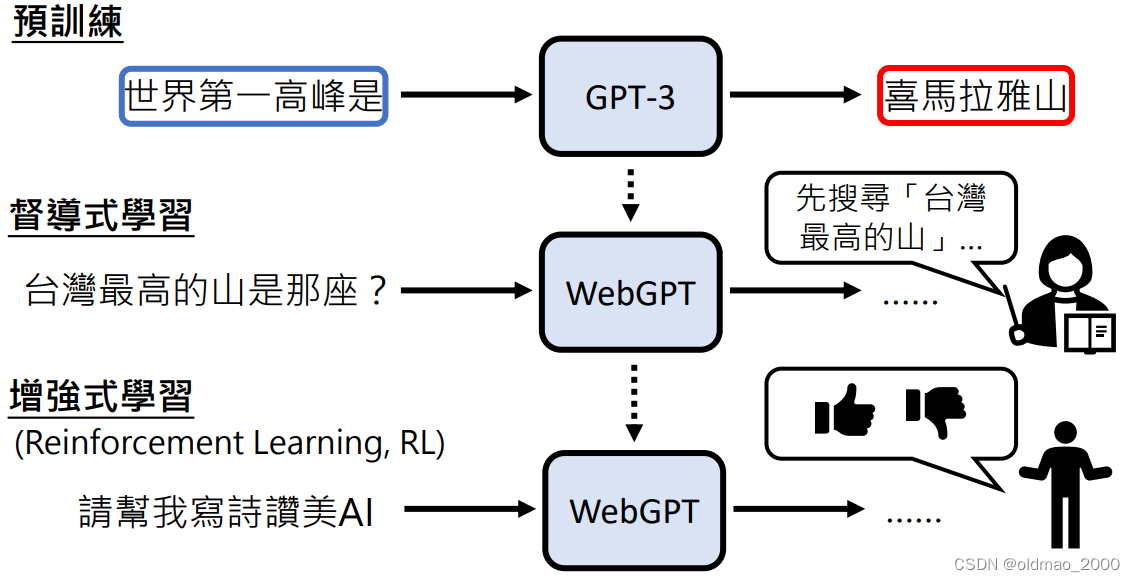
整个过程如下图:先是基于GPT-3进行预训练,然后加入人工监督学习,学习内容就是上面的图,最后加入RL,减少人工学习的复杂度。
Toolformer
原理和WebGPT其实差不多,但是这个模型利用的不仅仅是网络搜索,还加上了计算器,翻译器等
这里使用的工具比较多,很难像WebGPT一样单纯提供接口来使用人工监督的方式来生成训练资料。解决方式有两种:
生成训练数据
法一:利用语言模型生成
对语言模型下如下指令:
Your task is to add calls to a Question Answering API to a piece of text. The questions should help you get information required to complete the text. You can call the API by writing “[QA(question)]” where “question” is the question you want to ask. Here are some examples of API calls.
这里使用中括号来表示要调用的QA API,下面是例子:


我们希望得到的结果是,如果输入:
The highest mountain in Taiwan is Yushan.
得到:
The highest mountain in Taiwan is [QA(“highest mountain in Taiwan”)] Yushan.
当然,这样做得到结果噪音较多,实作效果不好。
法二:在法一的结果上进行提纯,使用语言模型对结果进行验证,验证方法如下:
先去掉QA API,丢入语言模型,看得到结果的几率是多少

然后加上QA API,丢入语言模型,看得到结果的几率是多少

如果得到正确结果的几率上升,说明API提示语有用,则该条数据保留,否则丢弃。