文章目录
- 引言
- 正文
- Abstract
- Introduction介绍
- 问题
- FALL-E
- 2.1 Architexture结构
- 2.2 Training and Inference Details
- 3 Evaluation And Analysis测试和分析
- Conlusion
- 总结
引言
- 这篇文章是DCASE中少有的,没有使用DIffusion的方法,可以学习一下。
- 这篇文章的作者GAUDIO公司,也是提出这个比赛的参与者。
正文
Abstract
- 介绍一下这个系统,名字叫做FALL-E。该系统采用级联方法,包括低分辨率谱图生成、谱图超分辨率和声码器。每一个声音模型都是使用额外的数据集从零开始训练的,初次之外,我们还是使用了预训练的语言模型。
- 我们使用与数据集相对应的文本对模型进行条件化,并且基于文本输入记录环境声音。
- 同时,我们利用了额外的语言模型去改善数据集的文本描述,为了提高质量,连贯性和多样性,我们还执行了prompt工程。
- 这个模型原来是针对一般声音生成的,不仅仅是针对特定的声音。
Introduction介绍
-
生成AI这两年在文本和图片生成领域快速发展。但是在声音生成领域就相对比较慢。为了解决这个差距,我们提出了FoleySound合成系统开发的挑战,并被DCASW官方采用。
-
目前有关声音生成最主流的方向是基于文本描述生成声音的,成果包括AudioGen,还有AudioLDM。这一类系统的一些基本的组件包括,HiFi-GAN、SoundStream、EnCodec、潜在扩散模型还有频谱图超分辨率技术。(这里的一些技术细节具体看下一小章的问题)
-
在文本输入和文本条件生成中,已经引入了如T5、GPT、文本提示工程和带条件的生成模型的扩散等模型。由于大型深度学习模型的行为有些难以分析,这些工作使我们作为用户能够通过精心选择的文本输入来指导模型。
-
在上下文中 ,**我们提出了合成系统的新方法,那就是利用由低分辨率谱图生成、谱图超分辨率和声码器构成的级联系统。**虽然这个说明主要是针对DCASE比赛的,但是我们的应用主要是针对通用的所有的声音,并不仅仅是那几种声音。
文章结构介绍
-
第二部分:我们提出我们的模型FALL-E,并介绍具体的结构,同时包括每一个模块的实现细节,以及他们是如何连接起作用的。
-
第三部分:我们对测试结果进行深层次地分析,并解释我们方法的有效性。
-
第四部分:我们对工作和贡献进行了总结。
-
总体来说,我们相信我们的系统代表了foley合成系统迈出的重要一步,我们很高兴分享我们的研究发现。
问题
SoundStream
- SoundStream是一种新型的神经音频编解码器,能够高效地压缩语音、音乐和一般音频,其比特率与专为语音定制的编解码器相当。SoundStream的模型结构由一个完全卷积的编码器/解码器网络和一个残差矢量量化器组成,并且共同端到端地进行训练。
- 该训练利用了文本到语音和语音增强的最新进展,这些进展结合了对抗性和重建损失,允许从量化嵌入中生成高质量的音频内容。通过对量化器层应用结构化dropout进行训练,单一模型可以在从3kbps到18kbps的可变比特率下操作,与固定比特率下训练的模型相比,质量损失可以忽略不计。
- 此外,该模型适用于低延迟实现,支持流式推理,并在智能手机CPU上实时运行。在使用24kHz采样率的音频的主观评估中,3kbps的SoundStream性能优于12kbps的Opus,并接近9.6kbps的EVS。此外,我们能够在编码器或解码器端进行联合压缩和增强,无需额外的延迟,我们通过背景噪声抑制来演示这一点。
EnCodec
- 我们介绍了一个利用神经网络的最先进的实时、高保真音频编解码器。它由一个流式编码器-解码器架构组成,具有量化的潜在空间,并以端到端的方式进行训练。我们通过使用单一的多尺度频谱图对抗来简化和加速训练,有效地减少了伪影并产生了高质量的样本。
- 我们引入了一个新的损失平衡机制来稳定训练:损失的权重现在定义了它应该代表的整体梯度的比例,从而使这个超参数的选择与损失的典型规模解耦。最后,我们研究了如何使用轻量级的Transformer模型进一步压缩获得的表示,压缩率高达40%,同时速度比实时还快。
- 我们提供了所提模型的关键设计选择的详细描述,包括:训练目标、架构变化和各种感知损失函数的研究。我们为一系列的带宽和音频领域(包括语音、嘈杂的混响语音和音乐)提供了广泛的主观评估(MUSHRA测试)以及消融研究。在所有评估的设置中,我们的方法都优于基线方法,包括24 kHz单声道和48 kHz立体声音频。代码和模型可在github.com/facebookresearch/encodec上获得。
Latent Diffusion
- 通过将图像形成过程分解为对去噪自动编码器的顺序应用,扩散模型(DMs)在图像数据及其之外实现了最先进的合成结果。此外,它们的公式还允许有一个指导机制来控制图像生成过程,而无需重新训练。
- 然而,由于这些模型通常直接在像素空间中操作,因此优化强大的DMs通常需要数百天的GPU时间,而且由于顺序评估,推断是昂贵的。
- 为了在有限的计算资源上进行DM训练,同时保持其质量和灵活性,我们将它们应用于强大的预训练自动编码器的潜在空间。与之前的工作相比,对这样的表示进行扩散模型训练首次允许在复杂性减少和细节保留之间达到接近最优的点,极大地提高了视觉保真度。
- 通过在模型架构中引入交叉注意力层,我们将扩散模型转化为对于文本或边界框等一般条件输入的强大和灵活的生成器,并以卷积方式实现高分辨率合成。
- 我们的潜在扩散模型(LDMs)在图像修复方面实现了新的最先进技术,并在各种任务上都取得了高度竞争性的性能,包括无条件的图像生成、语义场景合成和超分辨率,同时与基于像素的DMs相比,大大减少了计算需求。代码可在https://github.com/CompVis/latent-diffusion 上获得。
Spectrogram super-resolution频谱超分辨率
- 在语音合成和语音增强系统中,梅尔频谱图需要在声学表示上非常精确。但是,生成的频谱图过于平滑,不能产生高质量的合成语音。受到图像到图像转换的启发,我们通过结合Pix2PixHD和ResUnet的学习基础后滤波器来解决这个问题,以重构梅尔频谱图并进行超分辨率处理。
- 通过得到的超分辨率频谱图网络,我们可以生成增强的频谱图,从而产生高质量的合成语音。使用Griffin-Lim和WaveNet作为声码器时,我们提出的模型分别在基线结果的3.29和3.84上实现了3.71和4.01的平均意见分数(MOS)的提高。
FALL-E
- 文章具体结构以及各个模块的介绍。
2.1 Architexture结构
-
级联结构应用很广泛,因为训练起来比较方便,并且已经广泛使用在以下几个领域
-
符号音乐生成(基于乐谱生成相关的声音)
- Symbolic Music Generation with Diffusion Models
- Symbolic Music generation with transformer-GANs
-
文本语音合成系统
- Tacoreon:Towards End-to-End Speech Synthesis
- Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron
- FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
-
声音生成
- AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
-
目前在音频和语音生成的系统中,大部分都是使用mel频谱图作为中间特征,我们的系统也是采用这种方式进行研究。
-
我们提出的系统叫做FALL-E,具体构成如下,是由三个独立训练的模型构成
-
基于Glide特征生成模型
-
基于扩散模型的上采样模型
-
基于HiFi-GAN的mel频谱图反转模型
Feature generation model
-
我们的特征生成模型是基于Glide的,该模型基于扩散生成模型,主要用于文本到图片的生成。为了从文本提示中生成信号,我们借用了Glide的主要分支,除了与图像相关的文本编码器。
-
该模型的架构和UNet差不多,UNet两侧的5个模块都保留了,并且卷积通道开始是192,每深入一层,就扩大两倍。
Text Encoder文本编码器
- 系统的文本编码器是一个预训练的 Flan-T5,一个 T5 模型的指令微调变体,它在各种应用中表现出更好的性能 [23]。我们将该模型的一系列文本嵌入馈送到基于 Glide 的特征生成模型,并省略句子级嵌入。为了生成基于类别的音频信号,使用了预定义的文本提示。
Upsampling mode上菜样模型
- 上采样模型是另外一个基于扩散模型的生成模型。他是负责从生成的低分辨率的mel频谱图合成高分辨率的mel频谱图。这个模型的整体结构也是UNet,和特征生成模型很相似,但是超参数不同,他的参数更小。每一个边使用了4个block,开始的通道数是128.
Mel反转模型
-
mel反转模型是将mel频谱图转为波形图,这个模型和HiFi–GAN声码器很相似,但是我们对于每一个层都增加了跳跃连接,这主要是为了改善一般音频信号的阶段重建效果。
-
整个系统总共有624M个参数,系统在单个GPU上也应用很成功。
2.2 Training and Inference Details
Dataset数据集
- 用于训练模型的数据集包括公开数据集和私人数据集,包括AudioSet[24]、CLOTHO[25]、Sonsniss、1WeSoundEffects、2 ODEON、3 和 FreeToUsounds.4 为了防止数据不平衡或模型不当行为的潜在风险,根据元数据过滤掉具有语音或音乐内容的音频样本。在过滤之后,我们使用 3815 小时音频信号进行训练。
Text Conditioning文本条件构成
- 可以优化或设计文本条件以提高训练和推理的模型行为。我们的重点是控制生成信号的记录条件/环境,以便模型也可以从众包噪声(低信噪比级别)数据集中学习,同时能够产生高质量的音频。在我们使用的数据集中,AudioSet 是唯一“嘈杂”的数据集。我们在训练期间将指示嘈杂数据集的特殊标记附加到文本输入中。对于其他数据集,我们附加了干净的数据集令牌。稍后将讨论这个附加令牌的影响。我们还通过删除一些停用词和数字来清理文本标签(即文本规范化)。这里比较迷幻,看的不是很懂
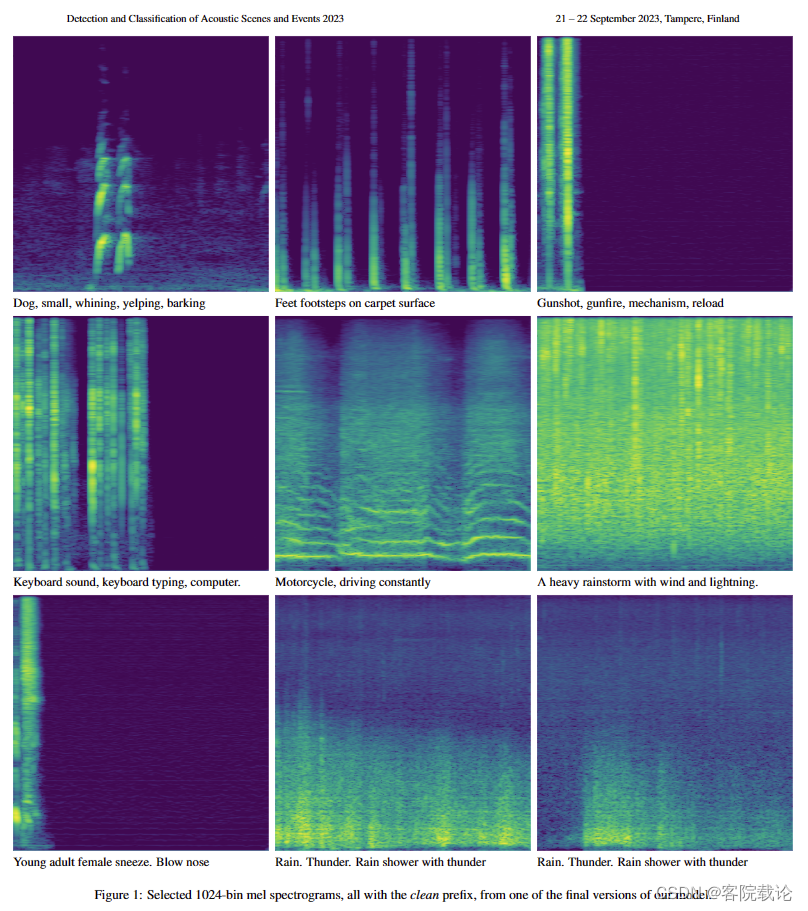
3 Evaluation And Analysis测试和分析
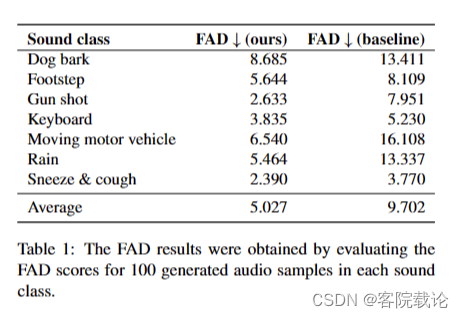
- 表格一,可以看出我们的模型效果很棒,各个类别的声音都比baseline的声音要好很多,尤其是下雨声和摩托车发动的声音,这两类声音都是没有比较稳定,没有明显的开始和结束,属于白噪声。
-
这里不得不说一下FAD作为唯一参考的客观指标的缺点,因为FAD是根据参考数据来恒量生成数据的,如果生成数据改良的效果很好,和参考数据差别很大,那么就会被认为是较差的数据。除此之外,FAD并没有办法恒量声音的质量,、信噪比等参数。
-
我们开发的模型主要是为了产生适用于现实世界场景的高质量声音。虽然我们训练集中的大部分声音音质都很差,主要是因为里面掺杂了背景音、泡泡声、风声还有设备运行的声音,以及解码器的失真,但是我们确认我们的模型生成的声音效果不错。
-
如第 2.2 节所述,我们通过将特殊标记作为原始文本的前缀来控制音频样本质量。鉴于无法客观地评估音频质量,我们对具有干净前缀和噪声前缀的相同文本进行了听力测试。根据使用的前缀,我们观察到所有声音类别的音质的显着改进。如图2所示,我们可以清楚地看到,使用干净的前缀对音频质量有明显的影响,如mel谱图图像所示。这种通过提示进行的模型转向在其他领域很流行,据我们所知,我们的工作是第一个成功显示它在音频生成方面的工作。 (这个可以借鉴一下)
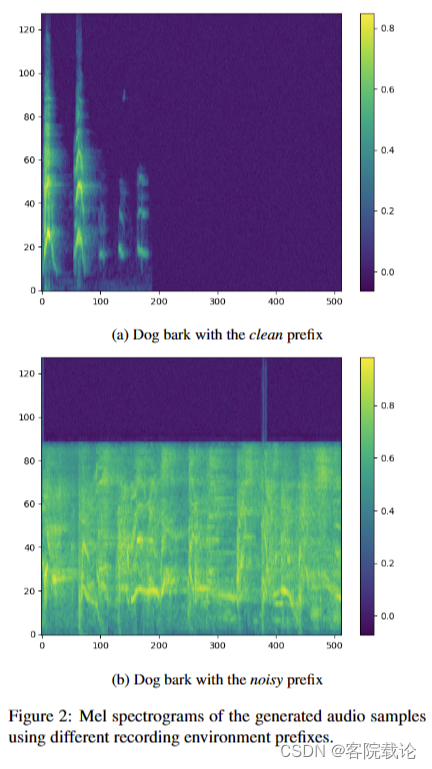
-
我们的模型还做了基本文本描述生成声音的相关研究,效果还行。但是有一个问题,也是目前大多数基于文本描述生成声音的弊端,那就是没有办法理解文本描述中的一些细节,只能做一些简单的生成和混响。比如说,输入的文本是“一个男生穿着运动鞋,牵着一个穿着高跟鞋的女生,走在教堂里”,基于这个描述产生的声音,要考虑到脚步声的速度,以及脚步声在教堂中的回响等不同的因素,但是目前大多数模型都没有考虑到。
Conlusion
- 在本文中,我们介绍了 FALL-E、Gaudio 的 foley 合成系统。**FALL-E 采用级联方法,具有低分辨率频谱图生成、超分辨率模块和声码器。**通过我们广泛的数据集和语言模型条件以及提示工程,我们获得了高质量、多样化和连贯的声音生成结果。
- 在音频领域开发生成 AI 具有巨大的潜力。随着技术的不断进步,声音生成的新可能性出现了,这项技术的潜在应用是巨大的。**例如,在电影和游戏制作中,与传统的佛利艺术家相比,foley 合成可用于产生更真实的声音效果、节省时间和资源。**我们相信 FALL-E 以及该领域的其他工作将为生成音频技术的未来进步铺平道路,我们期待这一令人兴奋的研究领域的持续发展。
总结
-
如果单纯使用没有经过特征提取的频谱图,扩散模型要实现一个很好的效果,需要几天的GPU时间,耗费的时间和算力太多了,并不可取。所以这就需要对频谱图进行特征提取,降维,这样需要学习的特征向量就没有那么多了,训练的时间就比较短。
-
这篇文章使用了一个完全不同的思路,需要好好学一下。