前序文章请看:
从裸机启动开始运行一个C++程序(七)
从裸机启动开始运行一个C++程序(六)
从裸机启动开始运行一个C++程序(五)
从裸机启动开始运行一个C++程序(四)
从裸机启动开始运行一个C++程序(三)
从裸机启动开始运行一个C++程序(二)
从裸机启动开始运行一个C++程序(一)
探秘IA-32
稍安勿躁,我们没有偏题
到这一章的程度,我相信一定会有读者有这样的疑问:你不是要介绍怎么从裸机启动开始运行一个C++程序吗?到现在别说C++了,我们连C的毛都没见到嘞,天天都是各种硬件构造什么的,你是不是歪楼了啊?
笔者确实很担心大家会有这样的想法,所以觉得这里有必要解释一下。我们在前面的章节也提到过,计算机能够直接运行的只能是机器指令,汇编语言虽然很接近机器指令,但还是需要先经过汇编器的转换。而像C语言这种上层语言,就更不可能直接被计算机识别了,它要经历很多繁琐的转换步骤(比如预处理、编译、链接)。
前面介绍的8086实模式也好,80286的保护模式也好,用的都是Intel的16位指令集。虽然说当年贝尔实验室的大佬用C语言去开发Linux的时候还没有80286,并且确实也有适配80286的16位指令集的C语言编译期存在。但这些东西都没有被广泛使用,前面我们切换保护模式的时候就已经出现了类似的问题,因为现在的CPU(即便是模拟器),都没有286的控制寄存器了,我们不得不用去操作CR0。
主要是因为,从80386开始确立的IA-32架构,在后续的很长一段时间内成为了PC机的主流架构,另一方面,目前C/C++的发行版编译期都是可以原生完美支持IA-32架构的编译的,但80286模式的确不能很好地支持,需要我们特殊去配置。
因此,笔者还是希望我们先稳定地了解到IA-32模式下,再考虑跟C语言去进行联动,所以这一章,还需要大家再坚持一下,当咱们的程序可以在IA-32模式下正常执行的时候,我们就可以开始跟C语言联动啦。
从286到386
80286最大的功劳就是引入了保护模式,这是一种完全不同于实模式的段分配方式。不知大家是否还记得,最初引入保护模式的两个主要目的是什么?一个是为了程序安全(所以引入了段权限),另一个则是因为寻址空间变大了,地址寄存器不够用。
而80386的最大功劳应该就是32位了,从386开始,不仅有了32位内存寻址空间,32位寄存器,同时还有了32位的指令集。
32位寻址空间也就意味着支持内存地址从0x00000000到0xffffffff一共4294967296B,合4GB的寻址空间。如果读者早年关注过个人PC的问题的话,可能会知道以前32位的电脑,最大只能支持4GB的内存,原因就是这个,因为寻址空间只有这么大。
寄存器方面,386将8个通用寄存器都扩展到了32位,分别是eax,ebx,ecx,edx,ebp,esp,edi,esi。注意这些寄存器的是在原本的16位寄存器上扩展得到的,例如说eax的低16位其实就是ax寄存器。当然了,指令寄存器ip也扩展到了eip,只不过这个寄存器不能随便使用罢了。同时还添加了gs和fs两个段寄存器。
而指令集也新添了32位指令集,注意这里是「添加」而不是「替换」,也就是说,386开始的CPU同样可以以实模式、286模式运行,这两种模式下执行的都是16位指令,只有在切换到386模式(或者叫IA-32模式)下,才会支持32位指令集。
IA-32模式也是保护模式,它跟286模式的区别在于指令集,所以286模式可以称为「16位保护模式」,IA-32模式可以称为「32位保护模式」。不过由于286比较短命,所以现在很少使用了,现代CPU也不会刻意进入286模式,而是会从实模式直接切换到IA-32模式(后面章节介绍切换方法的时候,这个问题就显而易见了),因此通常我们直接说「保护模式」,指的就是32位的保护模式,也就是IA-32模式。
IA-32汇编指令
这里需要给大家强调的是,汇编语言虽然很接近机器指令,但并不完全等价。同一条汇编指令,汇编为16位指令和32位指令可能是不同的,这一点大家一定要注意。
例如,mov ax, 5这句汇编,16位指令会汇编为B8 05 00,而32位指令会汇编为66 B8 05 00。所以我们在使用汇编语言的时候,除了要关注汇编语句本身,也要关注它的汇编环境才可以。
那么,如何在nasm中制定汇编指令集呢?方法如下:
[bits 32]
mov ax, 5
用[bits 32]语句声明后,从这一行往后的汇编指令,就会按照32位方式来汇编。如果想切回16位模式,那么就再声明[bits 16]即可。注意,如果我们没有显式声明的话,nasm默认是按照16位方式的,大家一定要注意。
不过现在我们写32位指令还无法运行,因为我们需要先将CPU切换到IA-32模式。
GDT的AVL保留位
在286的时候,我们配置GDT时,给了这样一张表:
| 内存偏移量(bit) | 符号 | 解释 |
|---|---|---|
| 0~15 | Limit | 段界限 |
| 16~39 | Base | 段基址 |
| 40 | A | 访问位 |
| 41~43 | Type | 描述符类型 |
| 44 | S | 系统/数据 |
| 45~46 | DPL | 权限级别 |
| 47 | P | 存在位 |
| 48~63 | AVL | 保留位 |
注意这里的48~63位这16位是保留字段,而到了IA-32开始,这保留字段就真正发挥它的意义了。首先,既然是32位寻址空间,那么段基址它至少得是一个32位地址才行吧,而现在只有16~39这24位地址,还有8位怎么办?就只能塞到这保留的16位中了。还剩下8位则是增加了一些其他功能。下面给出IA-32模式下的GDT配置字段意义表:
| 内存偏移量(bit) | 符号 | 解释 |
|---|---|---|
| 0~15 | Limit-Low | 段界限(低16位) |
| 16~39 | Base | 段基址(低24位) |
| 40 | A | 访问位 |
| 41~43 | Type | 描述符类型 |
| 44 | S | 系统/数据 |
| 45~46 | DPL | 权限级别 |
| 47 | P | 存在位 |
| 48~51 | Limit-High | 段界限(高4位) |
| 52 | G | 段粒度 |
| 53 | D/B | 16位/32位 |
| 54~55 | AVL | 保留位 |
| 56~63 | Base-High | 段基址(高8位) |
正是由于386是在286的基础上扩展的,所以才会造成这里的段基址配置没有写在一起,而是劈开了,因为低24位就是原先286上的,而高8位则是386开始扩展的。与此同时,386也扩充了段的上限,从以前的16位扩充到了20位,那么高4位也是分开写的。
正常来说,20位的界限的话,那一个段最多只能是1MB的大小,但这对于IA-32架构的4GB内存来说显得有点局促了。为了解决这个问题,G配置位表示「粒度」,通俗来说就是Limit的单位。当G为0时,Limit的单位是Byte,那么这个段最少为1B,最多可以有1MB;而G为1时,Limit的单位是4KB,那么这个段最少有4KB,最多可以有4GB。因此,通过Limit和G两个配置项共同决定一个段的大小是多少。
最后的这个D/B就是问题的关键了,它用来表示,这个段里面是16位数据(或指令)还是32为数据(或指令)的。对于代码段,如果D/B为0,则执行时会使用ip寄存器加载16位指令,如果D/B为1,则会使用eip寄存器加载32位指令。对于栈段,表示选择使用sp还是esp寄存器。换句话说,这一项配置的就是当前段要用16位模式还是32位模式来操作。(当然,如果是数据段的话,这一项就无所谓了,毕竟数据段的操作寄存器是由程序指定的,不需要通过段配置来确定。)如果说我们要把Kernel代码用32位方式来汇编的话,那么用于保存Kernel指令的内存段就要配置为32位的(也就是D/B要写1)才行,否则跳转后就不能正常执行指令。
那么我们就把前面的代码做一个修改,给GDT重新配置上前面的字段,对于1号段来说,是我们的指令段,也就是用于加载Kernel的内容,所以我们需要把D/B位置1,而粒度、还有地址的高位部分就先保持不变即可。2号段照理说不用改变,但我们还是保持统一,把D/B位置1,代码如下:
; 1号段
; 基址0x8000,大小8KB
mov [es:0x08], word 0x1fff ; Limit=0x001fff,这是低8位
mov [es:0x0a], word 0x8000 ; Base=0x00008000,这是低16位
mov [es:0x0c], byte 0 ; 这是Base的16~23位
mov [es:0x0d], byte 1_00_1_100_0b ; P=1, DPL=0, S=1, Type=100b, A=0
mov [es:0x0e], byte 0_1_00_0000b ; G=0, D/B=1, AVL=00, Limit的高4位是0000
mov [es:0x0f], byte 0 ; 这是Base的高8位
; 2号段
; 基址0xb8000,上限0xb8f9f,覆盖所有显存
mov [es:0x10], word 0x0f9f ; Limit=0x000f9f,这是低16位
mov [es:0x12], word 0x8000 ; Base=0x0b8000,这是低16位
mov [es:0x14], byte 0x0b ; 这是Base的高8位
mov [es:0x15], byte 1_00_1_001_0b ; P=1, DPL=0, S=1, Type=001b, A=0
mov [es:0x16], byte 0_1_00_0000b ; G=0, D/B=1, AVL=00, Limit的高4位是0000
mov [es:0x17], byte 0 ; 这是Base的高8位
32位Kernel
调整完GDT以后,当段选择子切换为对应段的时候,由于D/B位的原因,CPU就可以识别到,要用32位指令来解析代码了。但如果这时Kernel是没有调整过的,就会造成CPU会把16位指令「误认为」是32位指令进行解析。
; 原本的16位Kernel中的前两句
mov ax, 00010_00_0b
mov ds, ax
实际执行时会被认为:
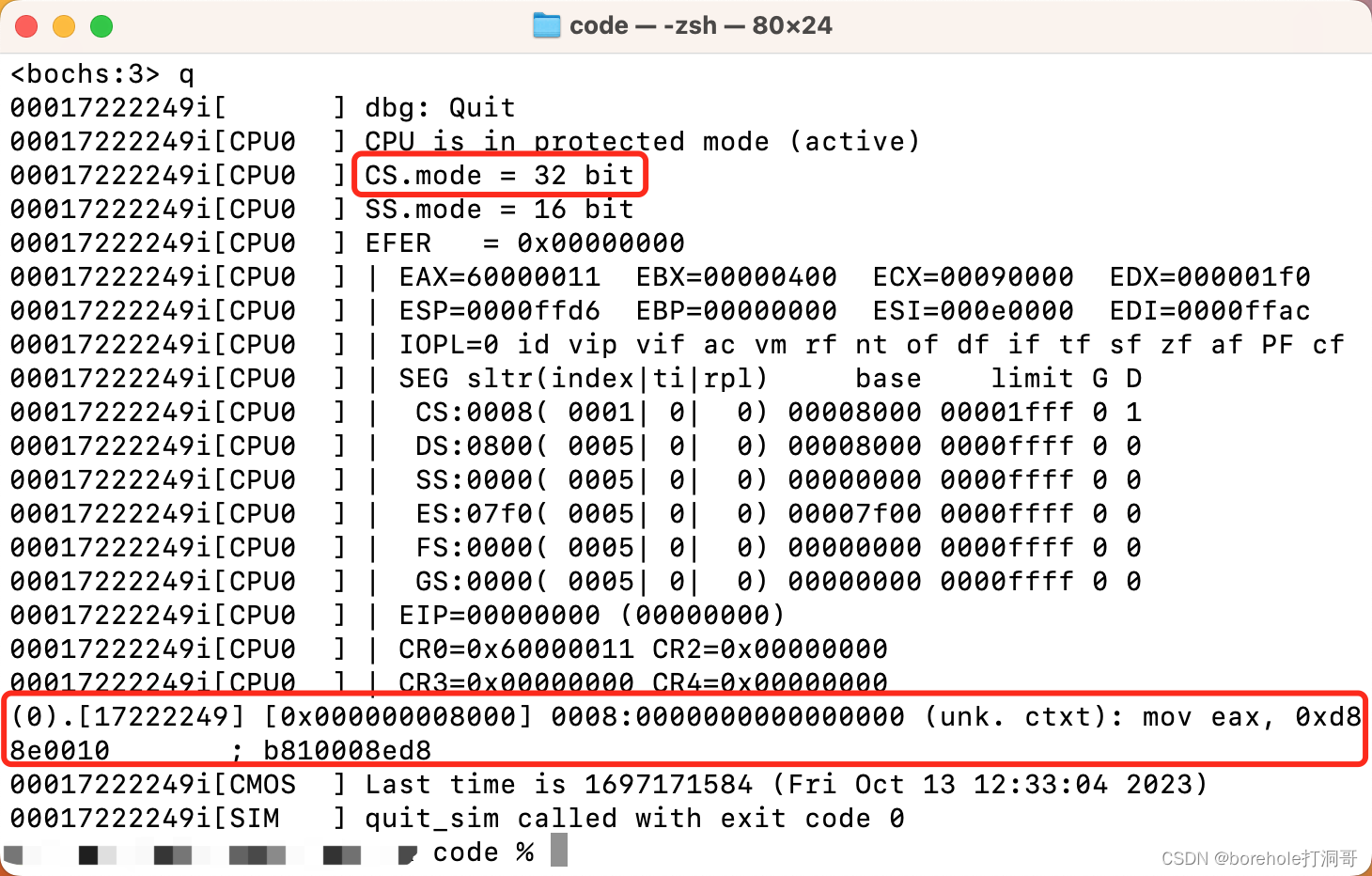
因此,这就需要我们制定Kernel代码,要按照32位指令集来汇编,方法在前面提到过,用[bits 32]:
[bits 32] ; 这里声明按照32位指令汇编
begin:
mov ax, 00010_00_0b ; 选择2号段,以操作显存
mov ds, ax
; 打印Hello
mov [0x0000], byte 'H'
mov [0x0001], byte 0x0f
; ...
重新构建后,就可以正常运行了:
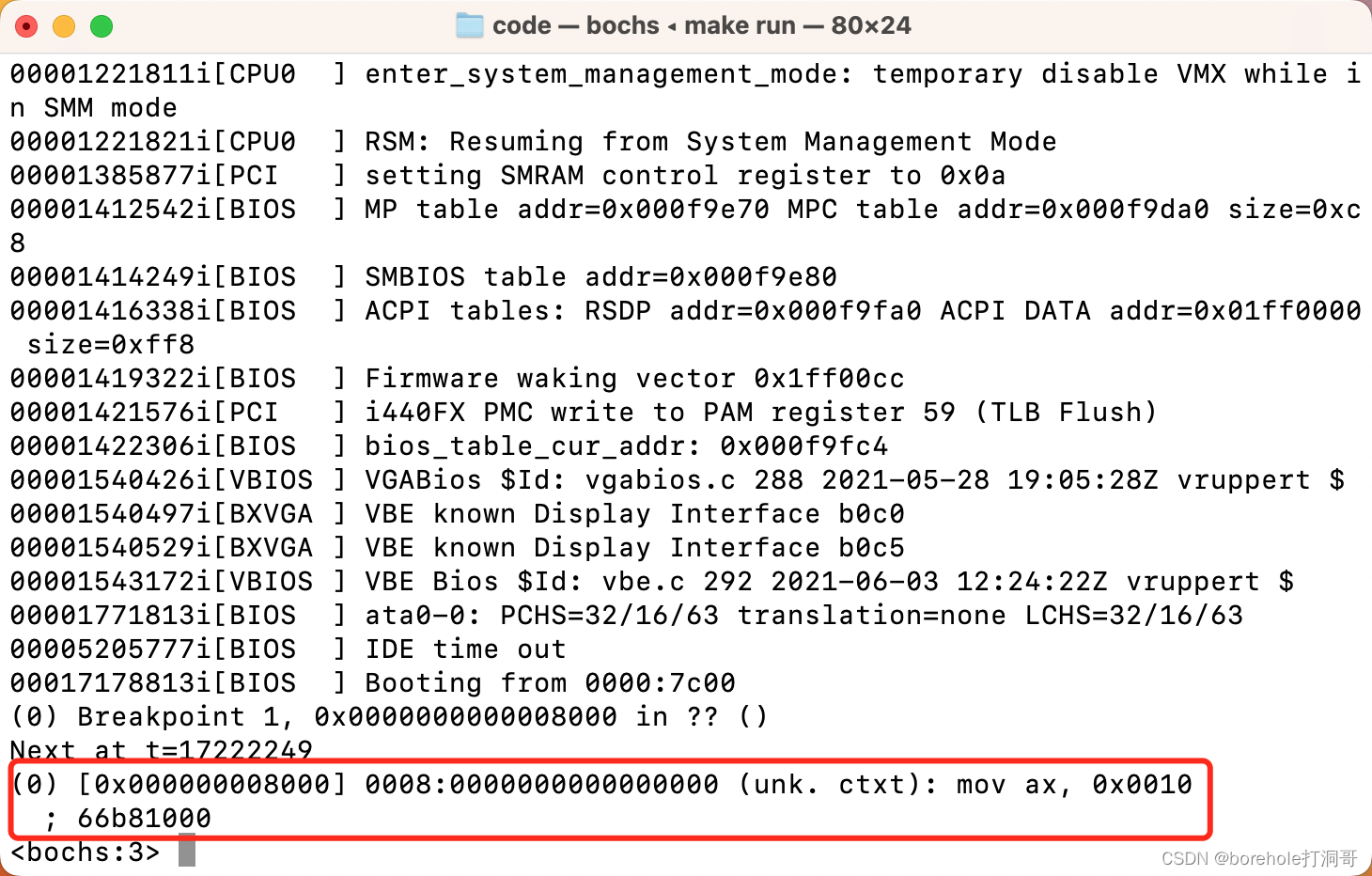
最后的运行效果如下:
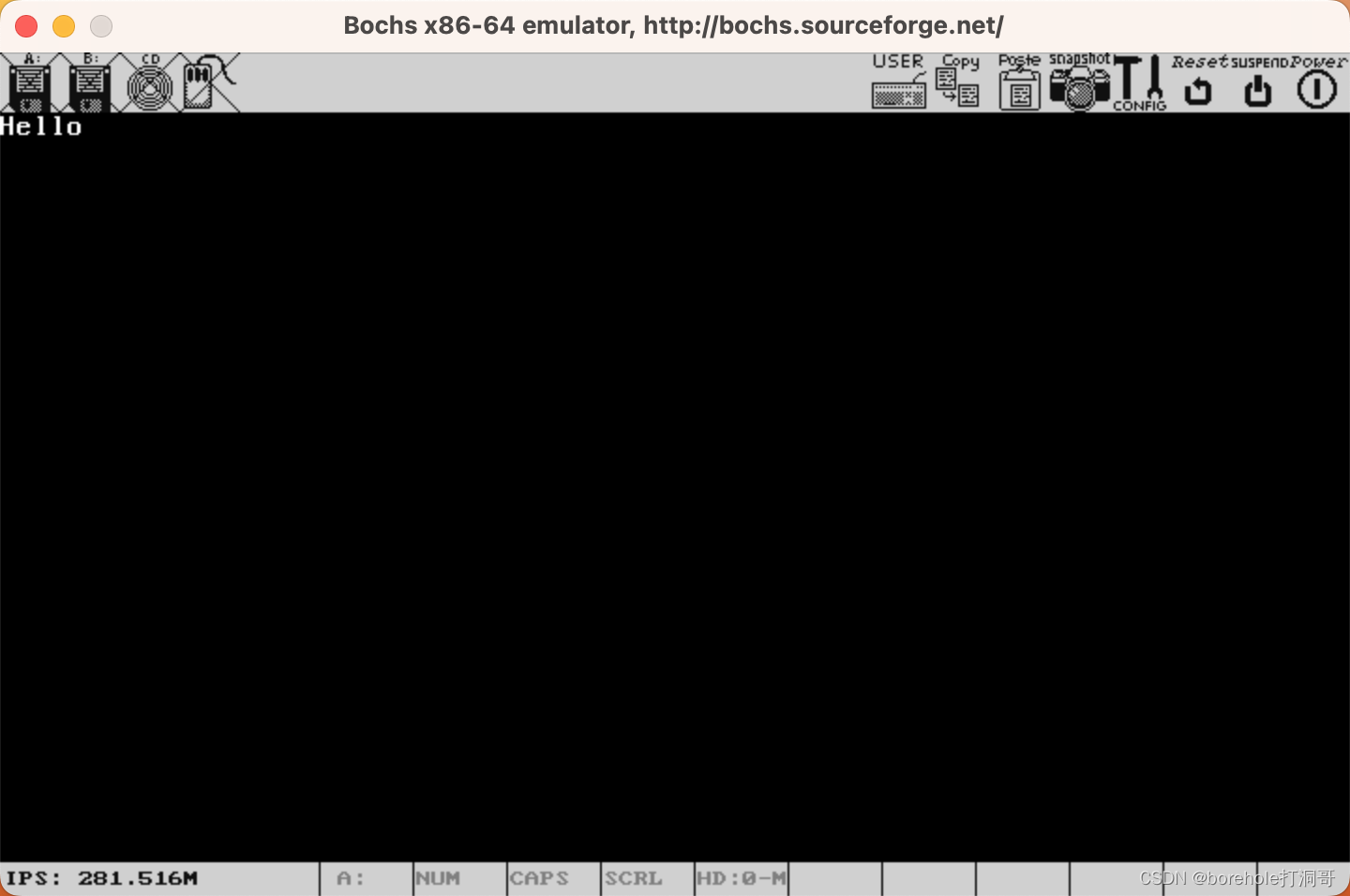
由此,我们在IA-32模式下,成功打印了Hello字样。后续我们的Kernel代码都会采用32位指令来编写。
调用栈
到目前为止,我们的代码还都是线性的,也就是按照我们书写顺序,逐条来执行的。但事实上真正可用的代码是不可能做到一条线走到底的,一定会有一些封装的子模块,然后互相调用。
就像一个C语言代码,我们不可能做到所有的代码全部挤在main函数中吧?一定是说main作为入口,然后跟其他函数再进行调用和返回这样的过程。
那么在IA-32汇编中如何完成类似的操作呢?要想实现这个功能,我们大致上需要3个方面的前置知识:
- 调用和回跳
- 参数传递
- 现场保留与现场还原
下面就逐一来介绍。
调用和回跳
前面我们介绍过几种跳转指令jmp,但它只能做到一次单纯的跳转,却没有办法记录我们是从哪里跳转来的,我们也就没办法做「回跳」。而要想实现类似于函数调用这样的功能,就必须要能够做到回跳。
比较容易想到的办法是,在jmp之前,我们先把当前的cs:eip的值保存在某一个位置,等后续执行完希望回跳的时候,再根据这里保存的cs:eip值跳转回来。
但这样做有两个问题。首先,cs和eip的值是没法直接读取到的,只能由CPU自己来控制。其次,多数情况下程序不会只做一层跳转和回跳,因为跳转之后还可能会再跳转,然后逐一回跳。所以固定空间记录回跳地址肯定是不可行的,必须要用到栈结构。当发生调用时,我们把当前地址压栈,而需要回跳时再弹栈并跳转,这样才能解决多层跳转问题。
IA-32汇编提供了单独的call和ret指令,用来解决上述需求。使用call指令时,会将当前的cs:eip压栈,写到ss:esp的位置,然后进行跳转。使用ret指令时,会先弹栈,然后再跳转到刚才从栈中弹出的地址,实现回跳功能。
既然用到了栈寄存器,那么肯定是需要我们要划分一片栈区才行。但目前我们划分的两个段都不太适合做栈区,毕竟1号段是指令,2号段是显存。所以看来,我们还是得补一个数据栈,用于存放指令执行过程中产生的临时数据才行。
因此,咱们就再回到MBR,配一个3号段作为数据段:
; 3号段
; 基址0x200000,大小4MB
mov [es:0x18], word 0x0400 ; Limit=0x3ff,这是低8位
mov [es:0x1a], word 0x0000 ; Base=0x00200000,这是低16位
mov [es:0x1c], byte 0x0020 ; 这是Base的16~23位
mov [es:0x1d], byte 1_00_1_001_0b ; P=1, DPL=0, S=1, Type=001b, A=0
mov [es:0x1e], byte 1_1_00_0000b ; G=1, D/B=1, AVL=00, Limit的高4位是0000
mov [es:0x1f], byte 0x00 ; 这是Base的高8位
我们这里分配了一个数据段3号段,分了4MB的大小,所以我们把G调成了1,然后Limit配了0x3ff所以大小是1024×4KB=4MB。至于基址,反正现在也有4GB的内存空间了,我们就往高地址一点的位置放,这里选择了0x200000。
记得要调整GDT的大小:
; 下面是gdt信息的配置(暂且放在0x07f00的位置)
mov ax, 0x07f0
mov es, ax
mov [es:0x00], word 31 ; 因为目前配了4个段,长度为32,所以limit为31
mov [es:0x02], dword 0x7e00 ; GDT配置表的首地址
同时注意,要调整一下虚拟机的内存大小:
a.img:
rm -f a.img
bximage -q -func=create -hd=4096M $@
之后,我们就可以在Kernel里去使用了,下面给一个简单的示例供大家参考:
[bits 32]
begin:
mov ax, 00011_00_0b ; 选择3号段,数据段
mov ss, ax
mov ax, 00010_00_0b ; 选择2号段,显存段
mov ds, ax
; 压栈
push 0x0f420f41
; 弹栈
pop edx
mov [0x0000], edx ; 写入显存
hlt
times 1024-($-begin) db 0 ; 补满2个扇区
如果顺利的话,显存里应该会有0x41和0x42两个字符(也就是AB):
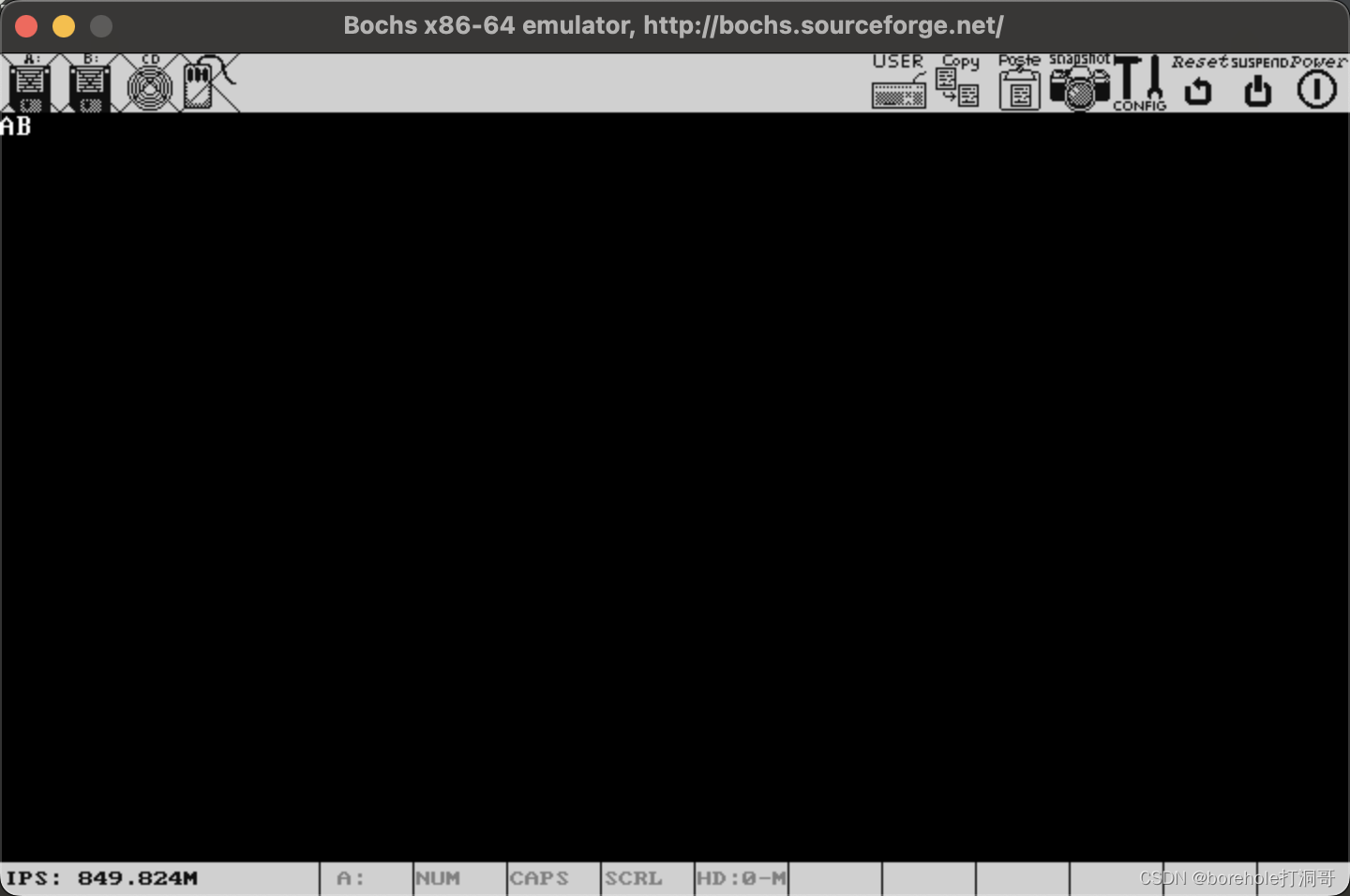
我们也可以通过命令查看此时的寄存器情况:
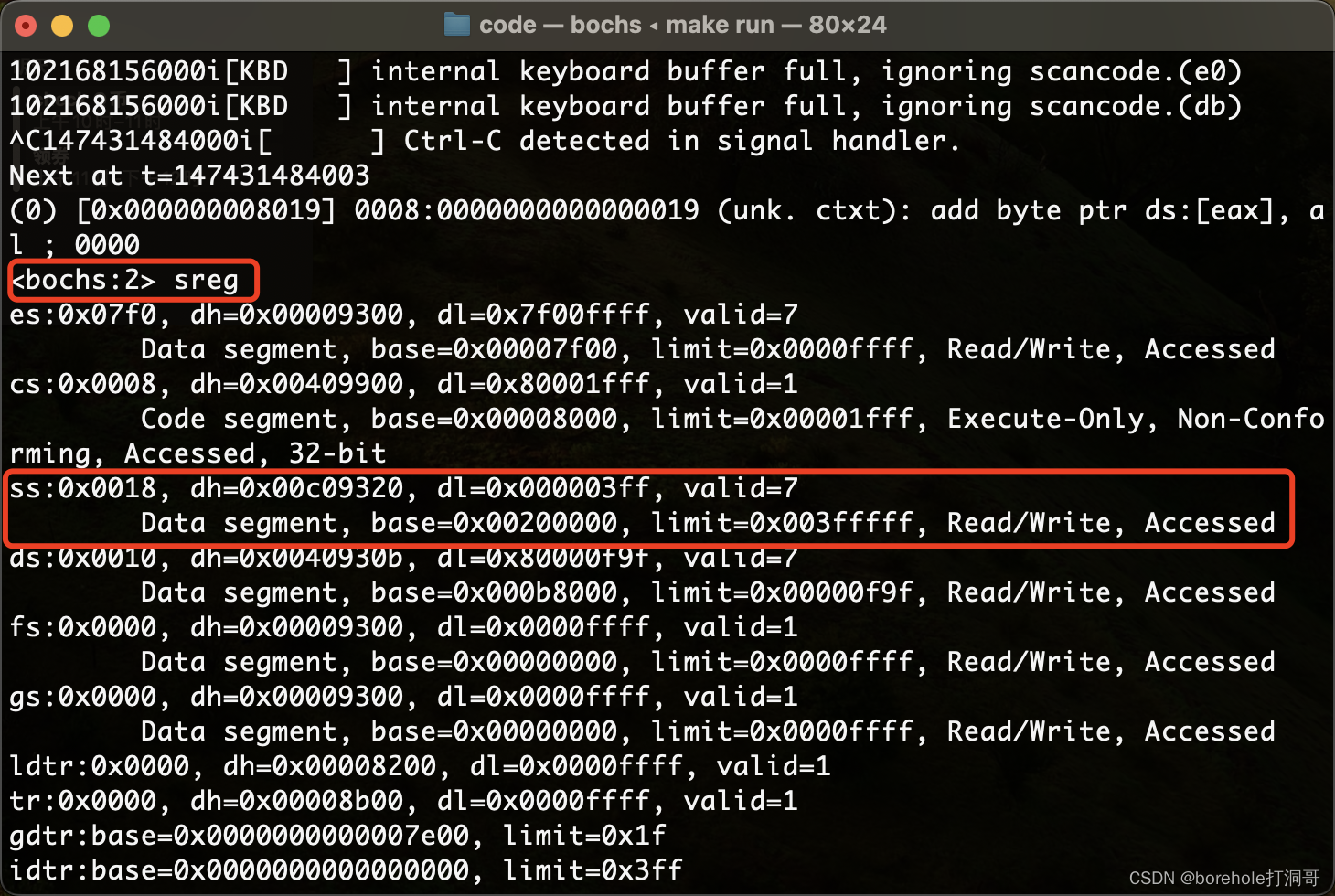
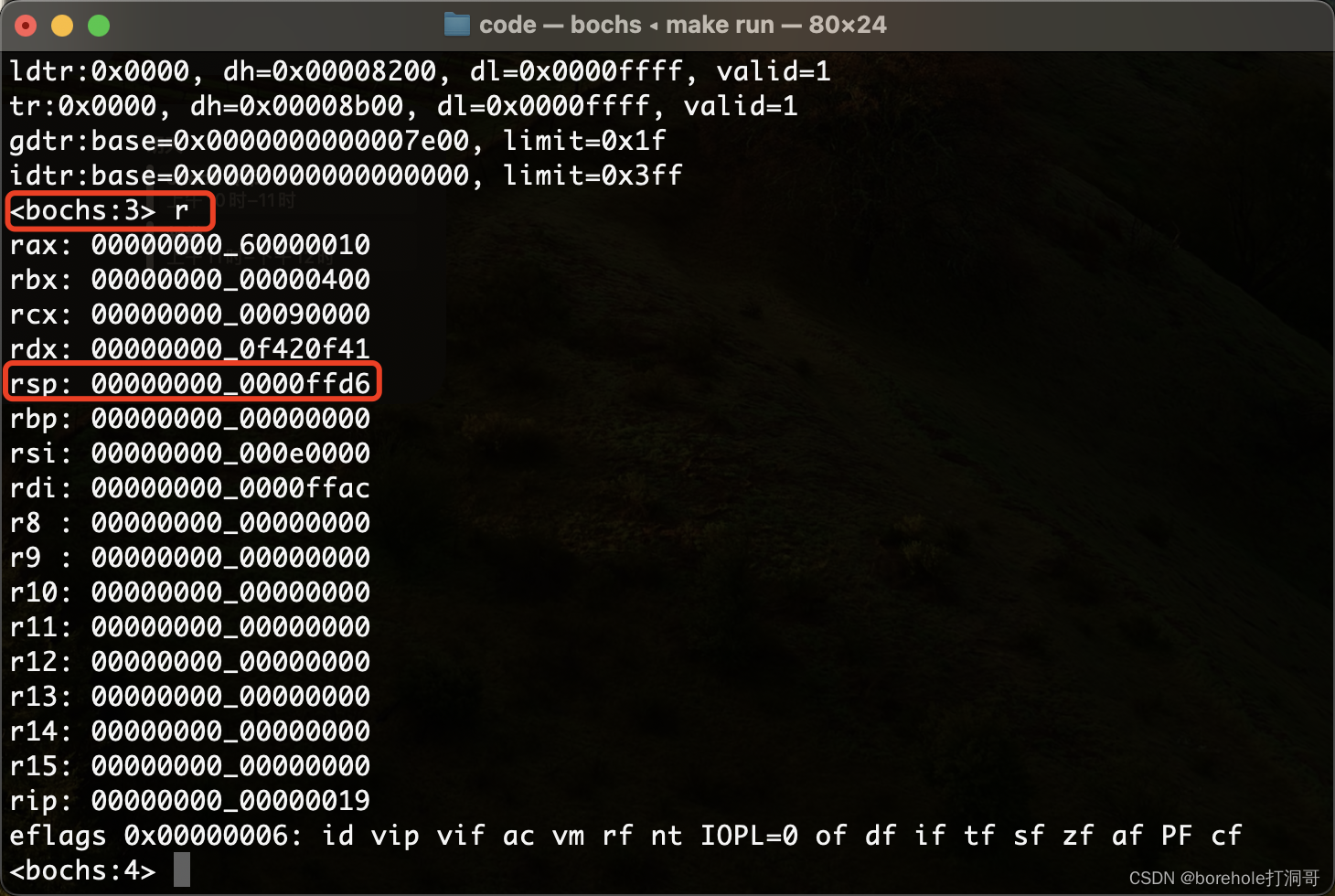
接下来我们就做一个调用和回调的验证。我们在begin段中先打印一些字符,然后跳转到f_test段中打印一些字符,然后返回回去之后再打印一些字符,验证是否能正常发生跳转。例程如下:
[bits 32]
begin:
mov ax, 00011_00_0b ; 选择3号段,数据段
mov ss, ax
mov ax, 00010_00_0b ; 选择2号段,显存段
mov ds, ax
mov [0x0000], byte '_'
mov [0x0001], byte 0x0f
mov [0x0002], byte '1'
mov [0x0003], byte 0x0f
mov [0x0004], byte '_'
mov [0x0005], byte 0x0f
call f_test ; 调用
; 调用后会回跳回来
mov [0x0010], byte '_'
mov [0x0011], byte 0x0f
mov [0x0012], byte '2'
mov [0x0013], byte 0x0f
mov [0x0014], byte '_'
mov [0x0015], byte 0x0f
hlt
f_test:
mov [0x0020], byte '_'
mov [0x0021], byte 0x0f
mov [0x0022], byte 'f'
mov [0x0023], byte 0x0f
mov [0x0024], byte '_'
mov [0x0025], byte 0x0f
ret ; 回跳
times 1024-($-begin) db 0 ; 补满2个扇区
如果说_1_、_2_和_f_都能打印出来的话,说明我们的跳转是成功的,结果如下:
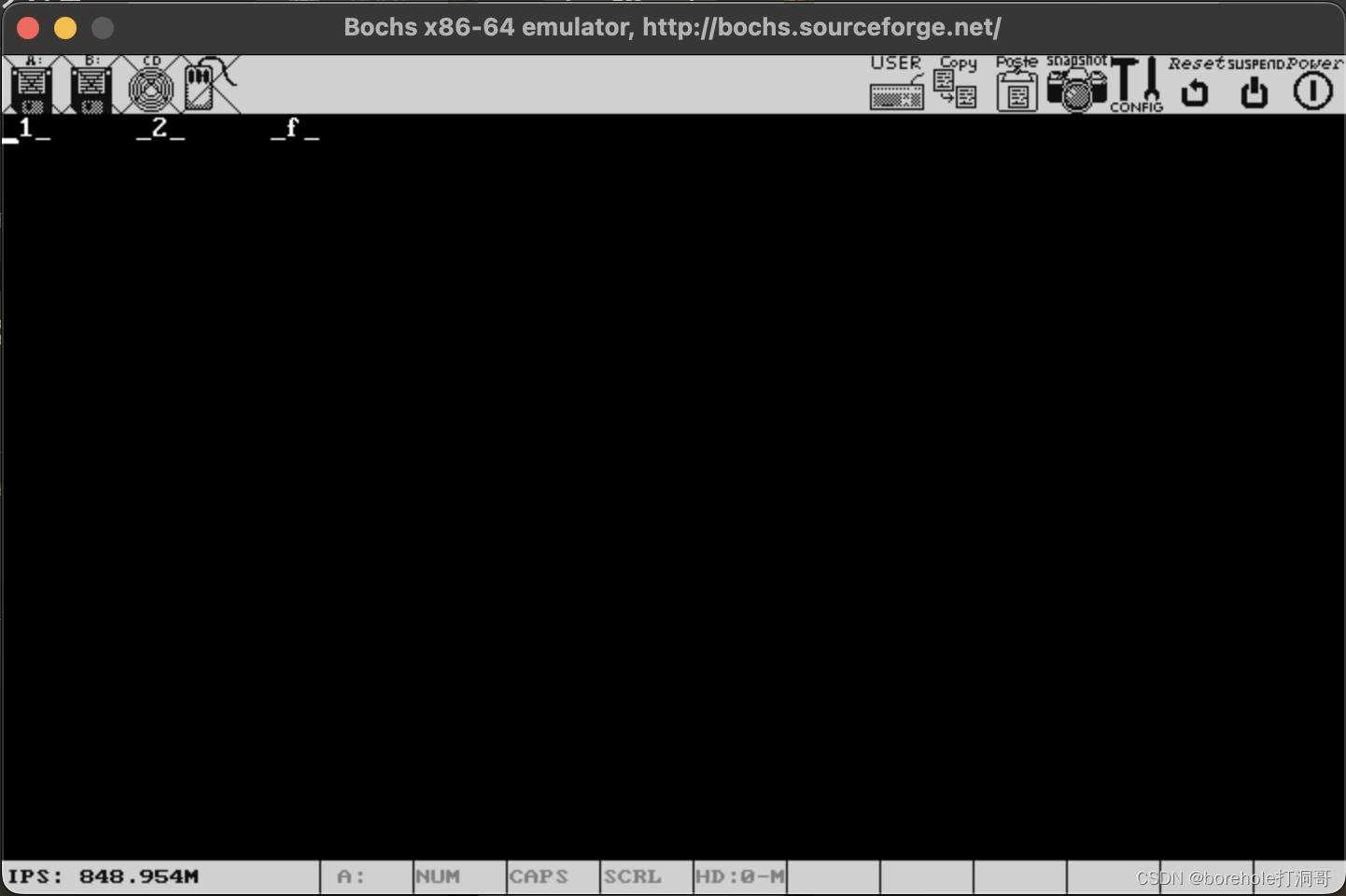
读者也可以自行进行验证,除了可以逐步调试观察寄存器以外,也可以自行尝试增添一些代码来做验证。
小结
这一篇我们进入了IA-32模式,并且成功执行了32位指令的Kernel。之后还简单体验了一下调用栈,下一篇会介绍如何在调用栈之间进行传参,以及如何进行现场保留和还原。
本节的实例工程将会上传至附件,读者可以自行取用。