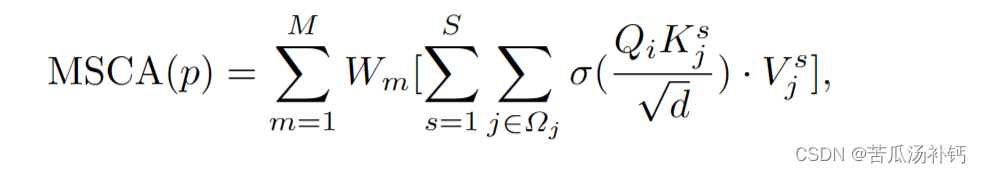文章目录
- 一、概述
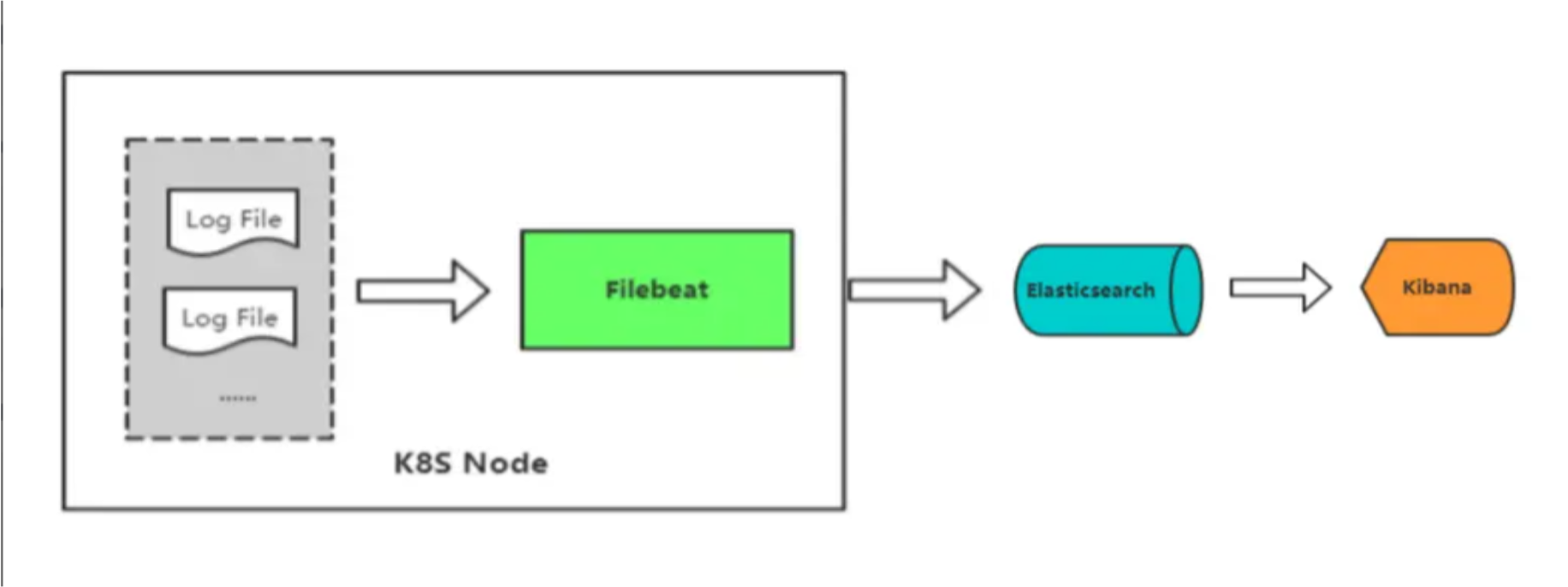
- 1)采集 Pod 日志流程介绍
- 3)采集 Events 日志流程介绍
- 二、K8s 集群部署
- 三、ElasticSearch 和 kibana 环境部署
- 四、Filebeat 采集配置
- 1)采集 Pod 日志配置
- 2)采集 Events 日志配置
- 1、创建 filebeat 授权 token
- 2、filebeat 配置
一、概述
要使用 Filebeat 采集 Kubernetes 中的 Pod 和 Events 日志,您需要配置Filebeat 以适应这两种类型的数据。以下是详细说明:
1)采集 Pod 日志流程介绍
Pod 日志是容器内产生的日志数据。Filebeat 可以监控这些日志并将它们发送到中央存储或分析系统。下面是如何配置 Filebeat 来采集 Pod 日志:
1、配置输入模块:
使用Filebeat的输入模块配置,选择 type: container。这告诉Filebeat应该监控容器的标准输出和日志文件。
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
in_cluster: true
这个配置指定 Filebeat 监控容器的日志文件,同时使用add_kubernetes_metadata处理器添加 Kubernetes 元数据,以便在日志中包含有关 Pod 和容器的信息。
2、指定输出目标:
配置Filebeat的输出目标,通常是 Elasticsearch 或 Logstash ,以将采集到的Pod日志发送到中央存储。
output.elasticsearch:
hosts: ["elasticsearch:9200"]
这个示例配置指定将日志发送到Elasticsearch集群。
3)采集 Events 日志流程介绍
Kubernetes Events 日志记录了集群中发生的事件,如 Pod 的创建、删除、调度等。Filebeat 可以监控这些事件日志并将其发送到相同或不同的目标位置。以下是如何配置 Filebeat 来采集 Kubernetes Events 日志:
1、配置输入模块:
使用Filebeat的输入模块配置,选择type: kubernetes。这告诉Filebeat应该监控Kubernetes Events。
filebeat.inputs:
- type: kubernetes
include_events: [".*"]
这个配置指定 Filebeat 监控所有类型的事件。您可以根据需求过滤特定类型的事件。
2、指定输出目标:
配置 Filebeat 的输出目标,通常是 Elasticsearch 或 Logstash ,以将采集到的 Events 日志发送到中央存储。
output.elasticsearch:
hosts: ["elasticsearch:9200"]
这个示例配置指定将事件日志发送到 Elasticsearch 集群。
二、K8s 集群部署
k8s 环境安装之前写过很多文档,可以参考我以下几篇文章:
- 【云原生】k8s 离线部署讲解和实战操作
- 【云原生】k8s 环境快速部署(一小时以内部署完)
三、ElasticSearch 和 kibana 环境部署
虚拟机部署非常简单,开箱即用的,这里选择更加快捷的部署方式,k8s 部署,可以参考我这篇文章:ElasticSearch+Kibana on K8s 讲解与实战操作(版本7.17.3)
git clone https://gitee.com/hadoop-bigdata/elasticsearch-kibana-on-k8s.git
cd elasticsearch-kibana-on-k8s
### 1、开始部署elasticsearch
# 如果没有挂载目录,则需要提前创建,也可自己更换挂载目录
# 先创建本地存储目录
mkdir -p /opt/bigdata/servers/elasticsearch/data/data1
chmod -R 777 /opt/bigdata/servers/elasticsearch/data/data1
helm install my-elasticsearch ./elasticsearch -n elasticsearch --create-namespace
# 查看
helm get notes my-elasticsearch -n elasticsearch
kubectl get pods,svc -n elasticsearch -owide
# 查看日志
kubectl logs -f elasticsearch-master-0 -n elasticsearch
# 测试验证
curl http://192.168.182.110:30920/
curl http://192.168.182.110:30920/_cat/nodes
curl http://192.168.182.110:30920/_cat/health?pretty
### 2、开始部署kibana
# 先创建本地存储目录
mkdir -p /opt/bigdata/servers/kibana/data/data1
chmod -R 777 /opt/bigdata/servers/kibana/data/data1
helm install my-kibana ./kibana -n kibana --create-namespace
# 查看
helm get notes my-kibana -n kibana
kubectl get pods,svc -n kibana -owide
四、Filebeat 采集配置
filebeat 的介绍可以参考我这篇文章:轻量级的日志采集组件 Filebeat 讲解与实战操作
1)采集 Pod 日志配置
filebeat.yaml 示例配置如下:
filebeat.inputs:
- type: container
enabled: true
paths:
- /var/log/containers/*.log
fields:
app: myapp
env: production
index: k8s-pod-log
processors:
- add_fields:
fields:
app: myapp
env: production
- drop_fields:
fields: ["sensitive_data"]
- add_kubernetes_metadata:
in_cluster: true
output.elasticsearch:
hosts: ["192.168.182.110:30920"]
index: "filebeat-%{[fields][index]}-%{+yyyy.MM.dd}"
setup.template.name: "default@template"
setup.template.pattern: "filebeat-k8s-*"
setup.ilm.enabled: false
主要参数讲解:
- 上述配置中,Filebeat的输入模块是container,它监视容器的日志文件,然后使用
add_kubernetes_metadata处理器添加Kubernetes元数据,需要设置in_cluster为true。日志将被发送到Elasticsearch。 setup.template.name是 Filebeat 配置中的一个选项,用于设置为 Elasticsearch 索引模板的名称。索引模板定义了 Elasticsearch 中索引的结构,包括字段映射和设置。setup.template.pattern是 Filebeat 配置中的一个选项,用于设置 Elasticsearch 索引模板的模式(pattern)。setup.ilm.enabled是 Filebeat 配置中的一个选项,用于启用或禁用索引生命周期管理(Index Lifecycle Management,ILM)。ILM 是 Elasticsearch 的功能,用于自动管理索引的生命周期,包括索引的创建、滚动、删除等操作。
2)采集 Events 日志配置
【温馨提示】
Kubernetes (k8s)事件(Events)日志通常存储在 Kubernetes 集群的etcd存储中,默认情况下,事件数据在 Kubernetes 集群ETCD中保存1小时。
修改 kube-apiserver 的配置文件(/etc/kubernetes/manifests/kube-apiserver.yaml)可以调整 events 日志保留时长,并为 --event-ttl参数设置新的值。
因为 events 日志不存在文件存储,所以这里使用 k8s api 接口采集方式,当然也可以通过 kubectl get events -A -w 采集。
1、创建 filebeat 授权 token
filebeat-serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat-service-account
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat-role
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat-role-binding
subjects:
- kind: ServiceAccount
name: filebeat-service-account
namespace: default
roleRef:
kind: ClusterRole
name: filebeat-role
apiGroup: rbac.authorization.k8s.io
# 创建用户和角色
kubectl apply -f filebeat-service-account.yaml
获取 ServiceAccount 令牌:
kubectl get secret $(kubectl get serviceaccount filebeat-service-account -o jsonpath='{.secrets[0].name}') -o jsonpath='{.data.token}' | base64 -d
测试一下。
TOKEN=`kubectl get secret $(kubectl get serviceaccount filebeat-service-account -o jsonpath='{.secrets[0].name}') -o jsonpath='{.data.token}' | base64 -d`
echo $TOKEN
curl -ks --header "Authorization: Bearer $TOKEN" https://192.168.182.110:6443/api/v1/events?watch=true
# 也可以通过ca证书这样访问
curl --cacert "/etc/kubernetes/pki/ca.crt" --header "Authorization: Bearer $TOKEN" https://192.168.182.110:6443/api/v1/events?watch=true
2、filebeat 配置
filebeat.yaml 示例配置如下:
filebeat.inputs:
- type: httpjson
enabled: true
name: k8s-events
url: "https://192.168.182.110:6443/api/v1/events?watch=true"
http_method: "GET"
ssl.certificate_authorities: ["/etc/kubernetes/pki/ca.crt"]
#ssl.verification_mode: none
json.keys_under_root: true
interval: 10s
fields:
type: k8s-events
index: k8s-event-log
#paths:
# - "/"
#headers:
# Authorization: "Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6Ilh0Y2k0a1NOdXIyZnRNTUE2STZ5TEtqcnBRMkpOcDh4UHFOZzlMeW9UQXcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImZpbGViZWF0LXNlcnZpY2UtYWNjb3VudC10b2tlbi1wNGtqNyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJmaWxlYmVhdC1zZXJ2aWNlLWFjY291bnQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJhNTEyNzQ3Ny0zYjIwLTQzMjAtODY0MS1hNmJmOTFlYTBhMzIiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6ZGVmYXVsdDpmaWxlYmVhdC1zZXJ2aWNlLWFjY291bnQifQ.j3qmbs3n45xpWUHMyviHsmsGLQOhH6gz6FtkPKLDr-1D4m4paOivoS1Coy7pdlC5J40YNQeEwrHA9L7Hy1UQ-02Y98rrHn0O_oOxE4qR06-bmua7j3lAEWHCRrmmsmk9HGkPar1HxIERn6BNwRyWeQdHc6CvnCbwqvBBnpYuZ7lcO1agbZZ3E02MUwNN1ZG2n_dWi9dnRJGuc9Capm50AZzolo8k8frK5nLs8T5GxDI4bMC7Gbq6FaL8RVI_DVJpm7zGFJrtzPwhVFnqCAdMFeQbRIzpmWseSA-GHH4WQ3JpLdkvzUZr8jhZ6jMSCE6u8UGO2AeEjBElZpzpwVk4cg"
logging.level: debug
output.elasticsearch:
hosts: ["192.168.182.110:30920"]
index: "filebeat-%{[fields][index]}-%{+yyyy.MM.dd}"
setup.template.name: "default@template"
setup.template.pattern: "filebeat-k8s-*"
setup.ilm.enabled: false
【温馨提示】也可以把header打开,并设置 ssl.verification_mode: none。正对应下面的两种curl方式:
TOKEN=`kubectl get secret $(kubectl get serviceaccount filebeat-service-account -o jsonpath='{.secrets[0].name}') -o jsonpath='{.data.token}' | base64 -d`
echo $TOKEN
curl -ks --header "Authorization: Bearer $TOKEN" https://192.168.182.110:6443/api/v1/events?watch=true
# 也可以通过ca证书这样访问
curl --cacert "/etc/kubernetes/pki/ca.crt" --header "Authorization: Bearer $TOKEN" https://192.168.182.110:6443/api/v1/events?watch=true
字段解释:
json.keys_under_root:默认情况下(json.keys_under_root 为 false),Filebeat 将在 Elasticsearch 中创建一个名为 “json” 的字段,包含整个 JSON 数据。如果将 json.keys_under_root 设置为 true,则 Filebeat 将直接在 Elasticsearch 中创建 “log”、“message” 和 “level” 这些字段,使它们成为根级别字段。setup.template.name是 Filebeat 配置中的一个选项,用于设置为 Elasticsearch 索引模板的名称。索引模板定义了 Elasticsearch 中索引的结构,包括字段映射和设置。setup.template.pattern是 Filebeat 配置中的一个选项,用于设置 Elasticsearch 索引模板的模式(pattern)。setup.ilm.enabled是 Filebeat 配置中的一个选项,用于启用或禁用索引生命周期管理(Index Lifecycle Management,ILM)。ILM 是 Elasticsearch 的功能,用于自动管理索引的生命周期,包括索引的创建、滚动、删除等操作。
【温馨提示】注意版本,低版本的是不支持httpjson的,这里我选择的是这个
7.17.14版本,https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.14-linux-x86_64.tar.gz
查看ES 索引是否正常采集(索引会自动创建)
curl http://192.168.182.110:30920/_cat/indices
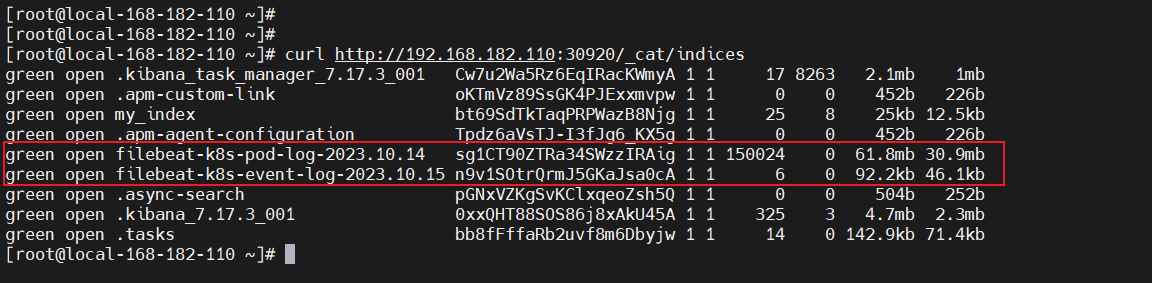
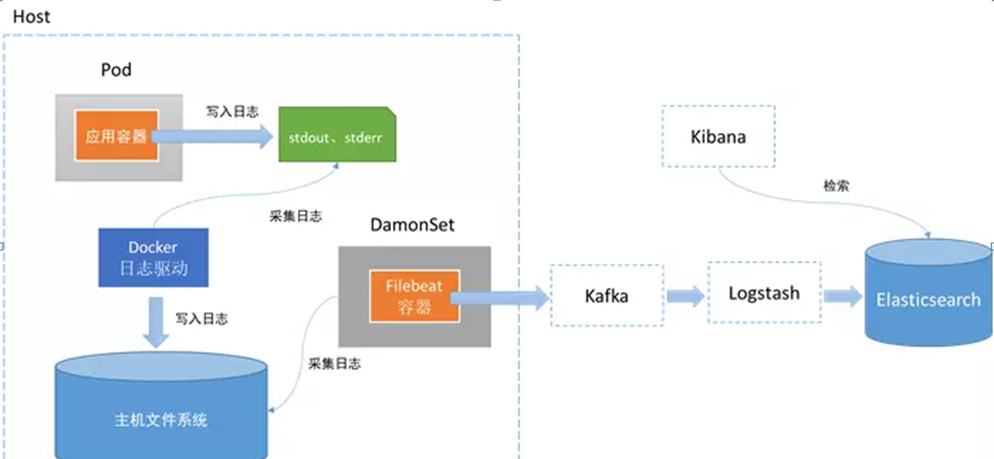
这里只是为了讲述如何采集 pod 和 Events 日志,一般不会直接采集到 ES,而是会通过 kafka中间件作为缓冲,这样可以避免大数据量导致 ES 压力过大。生成环境的采集架构图如下(后面也会讲解):
Filebeat 采集 k8s Pod 和 Events 日志实战操作讲解就先到这里了,有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~