【日常业务开发】接口性能优化
- 缓存
- 本地缓存
- 分布式缓存
- 数据库
- 分库分表
- SQL 优化
- 业务程序
- 并行化
- 异步化
- 池化技术
- 预先计算
- 事务粒度
- 批量读写
- 锁的粒度
- 尽快return
- 上下文传递
- 空间换时间
- 集合空间大小
缓存
本地缓存
本地缓存,最大的优点是应用和cache同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适。缺点也是因为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
常用的本地缓存框架有 Guava、Caffeine 等,都是些单独的jar包 ,直接导入到工程里即可使用。
我们可以根据自己的需要灵活选择想要哪个框架。
@Configuration
public class CaffeineCacheConfig {
@Bean
public Cache<String, Object> caffeineCache() {
return Caffeine.newBuilder()
// 设置最后一次写入或访问后经过固定时间过期
.expireAfterWrite(60, TimeUnit.SECONDS)
// 初始的缓存空间大小
.initialCapacity(100)
// 缓存的最大条数
.maximumSize(1000)
.build();
}
}
本地缓存适用两种场景:
- 对缓存内容时效性要求不高,能接受一定的延迟,可以设置较短过期时间,被动失效更新保持数据的新鲜度。
- 缓存的内容不会改变。比如:订单号与uid的映射关系,一旦创建就不会发生改变。
注意问题:
- 内存 Cache 数据条目上限控制,避免内存占用过多导致应用瘫痪。
- 内存中的数据移出策略。
- 虽然实现简单,但潜在的坑比较多,最好选择一些成熟的开源框架。
分布式缓存
本地缓存的使用很容易让你的应用服务器带上“状态”,而且容易受内存大小的限制。
分布式缓存借助分布式的概念,集群化部署,独立运维,容量无上限,虽然会有网络传输的损耗,但这1~2ms的延迟相比其更多优势完成可以忽略。
优秀的分布式缓存系统有大家所熟知的Memcached 、Redis。对比关系型数据库和缓存存储,其在读和写性能上的差距可谓天壤之别,redis单节点已经可以做到8W+ QPS(系统每秒处理查询的次数)。设计方案时尽量把读写压力从数据库转移到缓存上,有效保护脆弱的关系型数据库。
注意问题:
- 缓存的命中率,如果太低无法起到抗压的作用,压力还是压到了下游的存储层。
- 缓存的空间大小,这个要根据具体业务场景来评估,防止空间不足,导致一些热点数据被置换出去。
- 缓存数据的一致性。
- 缓存的快速扩容问题。
- 缓存的接口平均RT,最大RT,最小RT。
- 缓存的QPS。
- 网络出口流量。
- 客户端连接数。
数据库
分库分表
MySQL的底层 innodb 存储引擎采用 B+ 树结构,三层结构支持千万级的数据存储。
当然,现在互联网的用户基数非常大,这么大的用户量,单表通常很难支撑业务需求,将一个大表水平拆分成多张结构一样的物理表,可以极大缓解存储、访问压力。
SQL 优化
虽然有了分库分表,从存储维度可以减少很大压力,但「富不过三代」,我们还是要学会精打细算,就比如所有的数据库操作都是通过 SQL 来执行。
一个不好的SQL会对接口性能产生很大影响。
比如:
1、搞了个深度翻页,每次数据库引擎都要预查非常多的数据。
select * from purchase_record where productCode = 'PA9044' and status=4 order by orderTime desc limit 100000,200
limit 100000,200 意味着会扫描 100200 行,然后返回 200 行,丢弃掉前 100000 行。所以执行速度很慢。一般可以采用标签记录法来优化,比如:
select * from purchase_record where productCode = 'PA9044' and status=4 and id > 100000 limit 200
这样优化的好处是命中了主键索引,无论多少页,性能都还不错,但是局限性是id需要一个连续自增的字段
2、索引缺失,走了全表扫描。
3、避免一次从 DB 中查询大量的数据到内存中,可能会导致内存不足,建议采用分批、分页查询。
业务程序
并行化
梳理业务流程,画出时序图,分清楚哪些是串行?哪些是并行?充分利用多核 CPU 的并行化处理能力。
如下图所示,存在上下文依赖的采用串行处理,否则采用并行处理。

JDK 的 CompletableFuture 提供了非常丰富的API,大约有50种 处理串行、并行、组合以及处理错误的方法,可以满足我们的场景需求。
异步化
一个接口的 RT 响应时间是由内部业务逻辑的复杂度决定的,执行的流程约简单,那接口的耗费时间就越少。
所以,普遍做法就是将接口内部的非核心逻辑剥离出来,异步化来执行。
下图是一个电商的创建订单接口,创建订单记录并插入数据库是我们的核心诉求,至于后续的用户通知,如:给用户发个短信等,如果失败,并不影响主流程的完成。
我们会将这些操作从主流程中剥离出来。

异步的实现方式,可以用线程池,也可以用消息队列,还可以用一些调度任务框架。
业务的普遍做法就是,下单成功后,发送一条异步消息到MQ 服务器,由消费端监听 topic,异步消费执行。
池化技术
我们都用过数据库连接池,线程池等,这就是池思想的体现,它们解决的问题就是避免重复创建对象或创建连接,可以重复利用,避免不必要的损耗,毕竟创建销毁也会占用时间。
池化技术的核心是资源的“预分配”和“循环使用”,常见的池化技术的使用有:线程池、内存池、数据库连接池、HttpClient 连接池等。
连接池的几个重要参数:最小连接数、空闲连接数、最大连接数。
比如创建一个线程池:
new ThreadPoolExecutor(3, 15, 5, TimeUnit.MINUTES,
new ArrayBlockingQueue<>(10),
new ThreadFactoryBuilder().setNameFormat("data-thread-%d").build(),
(r, executor) -> {
(r instanceof BaseRunnable) {
((BaseRunnable) r).rejectedExecute();
}
});
预先计算
有很多业务的计算逻辑比较复杂,比如页面要展示一个网站的 PV、微信的拼手气红包等。
如果在用户访问接口的瞬间触发计算逻辑,而这些逻辑计算的耗时通常比较长,很难满足用户的实时性要求。
也就是预取思想,就是提前要把查询的数据,提前计算好,放入缓存,接口访问时,只需要读缓存即可,会大幅提高接口性能。
比如:定时同步mysql库存数据到redis中,当请求扣减库存时,先通过redis setNX去重/mysql去重表,再通过redis decrement减库存数据,然后发送一条异步消息到MQ 服务器
消费端监听 topic,异步多线程消费。
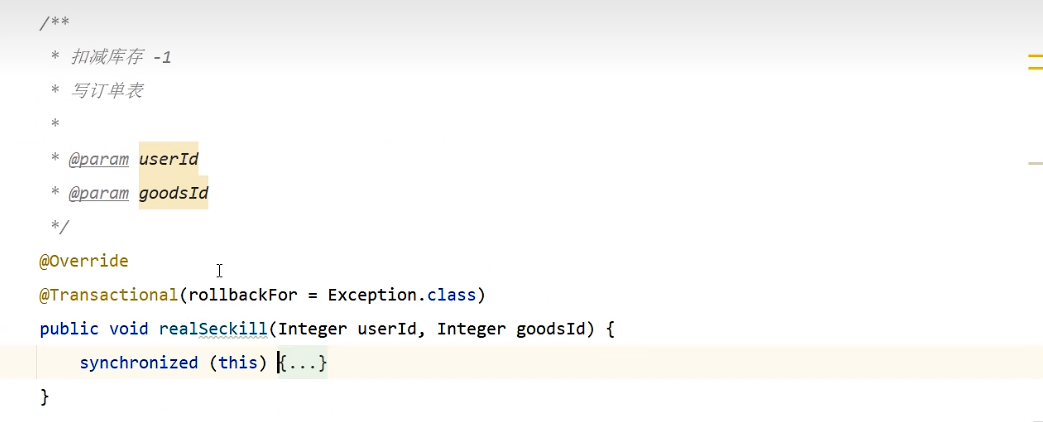
1、减库存(先查在更新),写订单表,必须是同一个事物。如果是单节点,可以使用synchronized加锁,解决线程安全问题。
synchronized错误加锁方法: 锁在事物里面
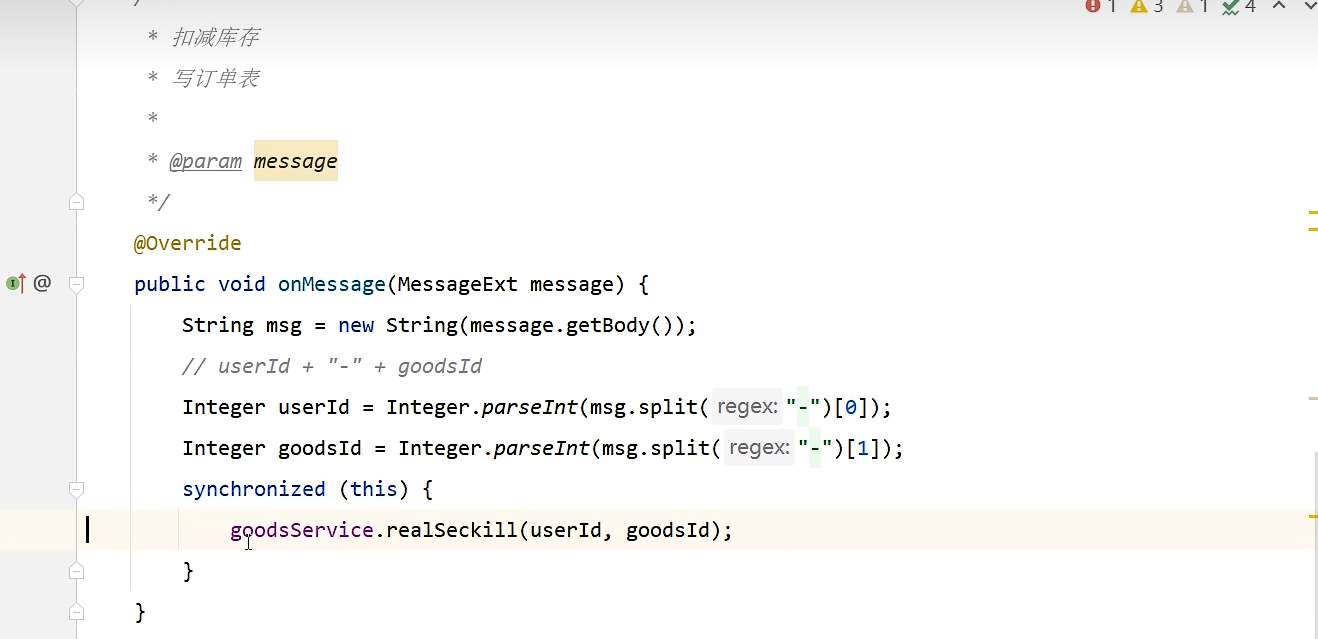
synchronized正确加锁方法: 锁在事物外面
2、如果是分布式多节点,需要加分布式锁 : mysql行锁/redis锁。
mysql行锁: 向下提取,并发不高可以使用,并发高,导致数据库压力大。
update goods set total_stocks = total_stocks-1 where user_id = ? and total_stocks-1>=0
redis锁: 向上提取,redis setnx分布式锁,压力会分摊到redis和程序中执行 缓解db的压力
redisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
判断是否需要自旋
1、while(true) {} 实现自旋
@Component
@RocketMQMessageListener(topic = "seckillTopic3",
consumerGroup = "seckill-consumer-group3",
consumeMode = ConsumeMode.CONCURRENTLY,
consumeThreadMax = 40
)
public class SeckillListener implements RocketMQListener<MessageExt> {
@Autowired
private GoodsService goodsService;
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public void onMessage(MessageExt message) {
String msg = new String(message.getBody());
Integer userId = Integer.parseInt(msg.split("-")[0]);
Integer goodsId = Integer.parseInt(msg.split("-")[1]);
while (true) {
// 这里给一个key的过期时间,可以避免死锁的发生
Boolean flag = redisTemplate.opsForValue().setIfAbsent("lock:" + goodsId, "", Duration.ofSeconds(30));
if (flag) {
// 拿到锁成功
try {
goodsService.realSeckill(userId, goodsId);
return;
} finally {
// 删除
redisTemplate.delete("lock:" + goodsId);
}
} else {
try {
Thread.sleep(200L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
2、递归调用实现自旋
@Override
public void onMessage(MessageExt message) {
String msg = new String(message.getBody());
Integer userId = Integer.parseInt(msg.split("-")[0]);
Integer goodsId = Integer.parseInt(msg.split("-")[1]);
// 这里给一个key的过期时间,可以避免死锁的发生
Boolean flag = redisTemplate.opsForValue().setIfAbsent("lock:" + goodsId, "", Duration.ofSeconds(30));
if (flag) {
// 拿到锁成功
try {
goodsService.realSeckill(userId, goodsId);
} finally {
// 删除
redisTemplate.delete("lock:" + goodsId);
}
} else {
try {
Thread.sleep(200L);
} catch (InterruptedException e) {
e.printStackTrace();
}
onMessage(message);
}
}
@Service
public class GoodsServiceImpl implements GoodsService {
@Resource
private GoodsMapper goodsMapper;
@Autowired
private OrderMapper orderMapper;
/**
* 行锁(innodb)方案 mysql 不适合用于并发量特别大的场景
* 因为压力最终都在数据库承担
*
* @param userId
* @param goodsId
*/
@Override
@Transactional(rollbackFor = Exception.class)
public void realSeckill(Integer userId, Integer goodsId) {
// update goods set total_stocks = total_stocks - 1 where goods_id = goodsId and total_stocks - 1 >= 0;
// 通过mysql来控制锁
int i = goodsMapper.updateStock(goodsId);
if (i > 0) {
Order order = new Order();
order.setGoodsid(goodsId);
order.setUserid(userId);
order.setCreatetime(new Date());
orderMapper.insert(order);
}
}
}
修改库存
<update id="updateStock">
update goods set total_stocks = total_stocks - 1 ,update_time = now() where goods_id = #{value} and total_stocks - 1 >= 0
</update>
写订单表
<insert id="insert" keyColumn="id" keyProperty="id" parameterType="cn.zysheep.domain.Order" useGeneratedKeys="true">
insert into `order` (userid, goodsid, createtime
)
values (#{userid,jdbcType=INTEGER}, #{goodsid,jdbcType=INTEGER}, #{createtime,jdbcType=TIMESTAMP}
)
</insert>
事务粒度
很多业务逻辑有事务要求,针对多个表的写操作要保证事务特性。
但事务本身又特别耗费性能,为了能尽快结束,不长时间占用数据库连接资源,我们一般要减少事务的范围。
将很多查询逻辑放到事务外部处理。
另外在事务内部,一般不要进行远程的 RPC 接口访问,一般占用的时间比较长。引发的问题主要有:死锁、接口超时、主从延迟等。
批量读写
当下的计算机CPU处理速度还是很多的,而 IO 一般是个瓶颈,如:磁盘IO、网络IO。
有这么一个场景,查询 100 个人的账户余额?
有两个设计方案:
方案一:开单次查询接口,调用方内部循环调用 100 次。
方案二:服务提供方开一个批量查询接口,调用方只需查询 1 次。
你觉得那种方案更好?
答案不言而喻,肯定是方案二。
数据库的写操作也是一样道理,为了提高性能,我们一般都是采用批量更新。
锁的粒度
锁一般是为了在高并发场景下保护共享资源采用的一种手段,但是如果锁的粒度太粗,会很影响接口性能。
关于锁粒度:就是你要锁的范围有多大,不管是synchronized 还是 redis分布式锁,只需要在临界资源处加锁即可,不涉及共享资源的,不必要加锁,就好比你要上卫生间,只需要把卫生间的门锁上就可以,不需要把客厅的门也锁上。
控制锁的范围是我们要考虑的重点。
错误的加锁方式:
//非共享资源
private void notShare(){
}
//共享资源
private void share(){
}
private int wrong(){
synchronized (this) {
share();
notShare();
}
}
正确的加锁方式:
//非共享资源
private void notShare(){
}
//共享资源
private void share(){
}
private int right(){
notShare();
synchronized (this) {
share();
}
}
尽快return
业务逻辑开始前先对必要参数或者集合进行判断,不成立尽快return/throw返回
if(CollectionUtils.isEmpty(list)) {
throw new RuntimeException("数据不合法");
}
上下文传递
当需要一个数据时,如果没有调 RPC 接口去查,比如想用户信息这种通用型接口。
因为前面要用,肯定已经查过。但是我们知道方法的调用都是以栈帧的形式来传递,随着一个方法执行完毕而出栈,方法内部的局部变量也就被回收了。
后面如果又要用到这个信息,只能重新去查。
如果能定义一个Context 上下文对象(ThreadLocal),将一些中间信息存储并传递下来,会大大减轻后面流程的再次查询压力。
空间换时间
一个很好理解的空间换时间的例子是合理使用缓存,针对一些频繁使用且不频繁变更的数据,可以提前缓存起来,需要时直接查缓存,避免频繁地查询数据库或者重复计算。
集合空间大小
如果我们预先知道集合要存储多少元素,初始化集合时尽量指定大小,尤其是容量较大的集合。
ArrayList 初始大小是 10,超过阈值会按 1.5 倍大小扩容,涉及老集合到新集合的数据拷贝,浪费性能。