目录
- 背景
- 实验
- 总结
- 技术
- 官网
- 原理
背景
一直以为任何DDL操作都会造成锁表,所以之前每次线上业务需要DDL时都会停机维护,而一维护就需要熬夜,为了不熬夜,所以一直都在想DDL和DML为啥不能并行。
偶尔拿测试环境试了一下才知道,原来DDL和DML自从mysql5.5之后就可以并行了,是我一直没有养成逛官网的习惯,道听而途说,德之弃也,自从5.5之后Mysql这方便也一直在进展,而且正常的公司也不会允许线上业务随时维护的,都是7*24小时待机业务。
所以本来是为了发版更加方便,没想到原来mysql早就支持了在线DDL,即DDL与DML并行。实现原理是Online DDL。
实验
-
服务器配置
实例来源:云数据库MySQL 地域及可用区:华北2 (北京) 实例规格:4核16 GB 空间 1000 GB 实例类型:MySQL 5.7 主实例 网络类型:专有网络 DAS版本:基础版 只读实例:1 最大连接数:4000 最大IOPS:7000 存储空间:已使用 666.35G ( 共 1000G ) -
基本数据检测
cpu利用率:平时应该保持在10%之下,超过40%就会报警,前些天大量的2s慢查询将利用率一度拖到了80% 磁盘利用:稳步上涨,在业务稳定的情况下,不存在陡增。目前为不到700G iops使用率:上限为100,主要是大数据同步数据时的;平时峰值为40,均值为30 iops:上限为7000,平时峰值为3000,均值为2000;然后发现io曲线是折线图,也就是说并不是无时无刻都在高速io,是累计数据进行io的。 qps: 8-11、13-18点为业务高峰期,峰值为700,平均为400 tps: 业务高峰期同qps,峰值为120,均值为60;基本上一个tps对应6个qps。 会话数:峰值100,均值 40 insert_ps: 峰值 70,均值40 select_ps:峰值 450, 均值250 update_ps:峰值 45,均值25 以上三个同时进行,也就是mysql的qps可以达到700. 线程数:峰值100,均值50 -
第一次增加字段实验:
增加字段第一次实验,jml_onenjoyqrcode_shop表,表空间24.25 GB,索引空间4.28 GB,增加字段时,2400w数据加字段耗时300s,确定不会锁表,以此为例对数据库的影响如下: ALTER TABLE `jml_onenjoyqrcode_shop` ADD `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间', ADD `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间', ADD `record_type` TINYINT NOT NULL DEFAULT 1 COMMENT '记录类型'; 节点复制延迟:暂停,会等待表结构完成再复制,延迟时间取决于语句执行时间。 内存页:陡增,均值为100,陡增至900 InnoDB Redo 写次数:陡增至5w,平时为200,极小 InnoDB Data 读写吞吐量(KB/B):陡增至12M,平时2k,极小 刷盘次数;陡增至200,均值为50 IOPS:陡增至8K,平时为2K。 CPU:陡增至30%,也就是5G,平时为5%,即500M 磁盘:临时增加3G -
第二次增加字段实验:
增加字段第二次实验,jml_onenjoyqrcode_dealer表,表空间24.25 GB,索引空间13.20 GB,6300w数据耗时770s。 ALTER TABLE `jml_onenjoyqrcode_dealer` ADD `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '记录创建时间', ADD `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '记录更新时间', ADD `record_type` TINYINT NOT NULL DEFAULT 1 COMMENT '记录类型'; CPU:上涨至35% 磁盘:临时增加20G 其余如上类似 -
第一次增加索引实验:
增加索引第一次实验:jml_user表,表空间2.18 GB,索引空间687.19 MB,450w数据增加三个索引耗时30s。 ALTER TABLE jml_user ADD INDEX idx_nick1 (nick_name1), ADD INDEX idx_nick2 (nick_name2), ADD INDEX idx_update (update_time); 增加索引时与增加字段的影响基本类似,但影响更大,因为会对应大量的排序操作;与增加字段相比,CPU影响增高,IOPS影响降低 -
总结
//性能总结 1. DDL会导致cpu和io激增,内存影响不大,磁盘也会占用(主要用于创建临时表),无论并行DDL还是阻塞DDL。 2. IO:可以随便打满,因为有很多读写操作。均值在2K 3. CPU: 一般不超过1G,但是应该预留足够,不可以打满, 4. 会话连接:一般不超过1K,上限4K 5. 因此,目前15+2的数据库目前瓶颈在于IO和慢sql。 // 时间总结:百万以下为正比例函数,百万以上为指数函数 6. 4w数据加字段 0.1s 7. 11w数据加字段 0.25s 8. 19w数据加字段 0.46s 9. 46w数据更新语句 1s 10. 1500w数据加字段 150s 11. 1500w数据加索引 250s // 总结 12. 加字段:1w=0.1s,1500w=150s, 理论上来说比加索引耗时少一些。 13. 加索引:570w=64s,理论来说索引需要排序,数据量越大越难处理。 14. 删除字段:1w=0.1s,1500w=150s,和加字段耗时类型,瓶颈都在io 15. 删除索引:极快,因为io较小。索引存在一个单独的文件夹。 16. 修改默认值: 极快,没有io,只是修改语句而已。
总结
适用于mysql的5.7及以上的版本:
-
增加、删除索引不会锁表,且删除索引速度非常快,即使表很大的情况下,无关CREATE INDEX语句还是ALTER TABLE语句,CREATE INDEX的内部执行逻辑也是ALTER TABLE。
-
无限制条件的update语句也不会锁表:UPDATE jml_qrcode SET aaa = ‘22’; 它的执行逻辑应该是逐行修改,总之不会锁表,最多锁行。
-
修改字段默认值及修改字段限制也不会锁表,应该都是逐行;但是如果修改字段限制添加 not null时则需要保证执行期间不会插入null值,因为修改语句是事务操作,执行完毕之间插入的值不会收到限制, 所以一旦插入null值最终结果会失败。
– 所以如果要修改一个default null值修改为 not null default xxx,需要先更新该字段值,然后保证后续的插入语句不会插入null值,然后再修改字段限制。ALTER TABLEdb_jml_seventeen.jml_qrcodeMODIFY COLUMNaaavarchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT ‘333’ AFTERcreate_time -
增加字段不会锁表,但是建议增加字段时都用 not null default null;此时crud均不会收到影响。
-
删除字段也不会锁表:ALTER TABLE
db_jml_seventeen.jml_qrcodeDROP COLUMNbbb
ALTER TABLEdb_jml_seventeen.jml_qrcode
DROP COLUMNa,
DROP COLUMNb
技术
-
应对索引: MySQL使用了一种称为“In-Place Alter”的技术。这种技术允许在不锁定表的情况下进行修改。In-Place Alter使用了一种称为“Fast Index Creation”的技术来优化索引添加,它可以在不拷贝原始表数据的情况下创建新索引。
-
应对表结构:MySQL5.7使用了一种称为“Online DDL”的技术。Online DDL允许在不锁定表的情况下进行表结构修改。当修改表结构时,MySQL会创建一个新表,并将原始表中的数据复制到新表中。在复制数据期间,原始表仍然可读和可写。完成数据复制后,MySQL会将新表重命名为原始表的名称,并删除原始表。此过程通常只需要几秒钟或几分钟,并且可以在应用程序运行期间执行。
虽然In-Place Alter和Online DDL可以减少对表的锁定,但它们并不适用于所有情况。例如,在进行某些类型的表结构修改时,MySQL可能需要锁定整个表。在这种情况下,In-Place Alter和Online DDL可能不适用。
官网
任何技术的源头都是官网,mysql的官网做的很不错,有搜索功能。直接就可以根据关键字找到自己想查的东西。
https://www.mysql.com/; 主界面最上面即是搜索框,The world’s most popular open source database;并且搜索完后还可以筛选版本。
-
MySQL官网遇到一个新名词–二级索引(secondary index):
我们常说的索引类型有:主键索引、唯一索引、普通索引、前缀索引、全文索引,甚至还有聚簇索引、覆盖索引等。
其中,除主键索引外的其它索引都属于二级索引。 -
在MySQL 5.7中,支持两种Generated Column,即Virtual Generated Column和Stored Generated Column,前者只将Generated Column保存在数据字典中(表的元数据),并不会将这一列数据持久化到磁盘上;后者会将Generated Column持久化到磁盘上,而不是每次读取的时候计算所得。很明显,后者存放了可以通过已有数据计算而得的数据,需要更多的磁盘空间,与Virtual Column相比并没有优势,因此,MySQL 5.7中,不指定Generated Column的类型,默认是Virtual Column。
如果需要Stored Generated Golumn的话,可能在Virtual Generated Column上建立索引更加合适,一般情况下,都使用Virtual Generated Column,这也是MySQL默认的方式 -
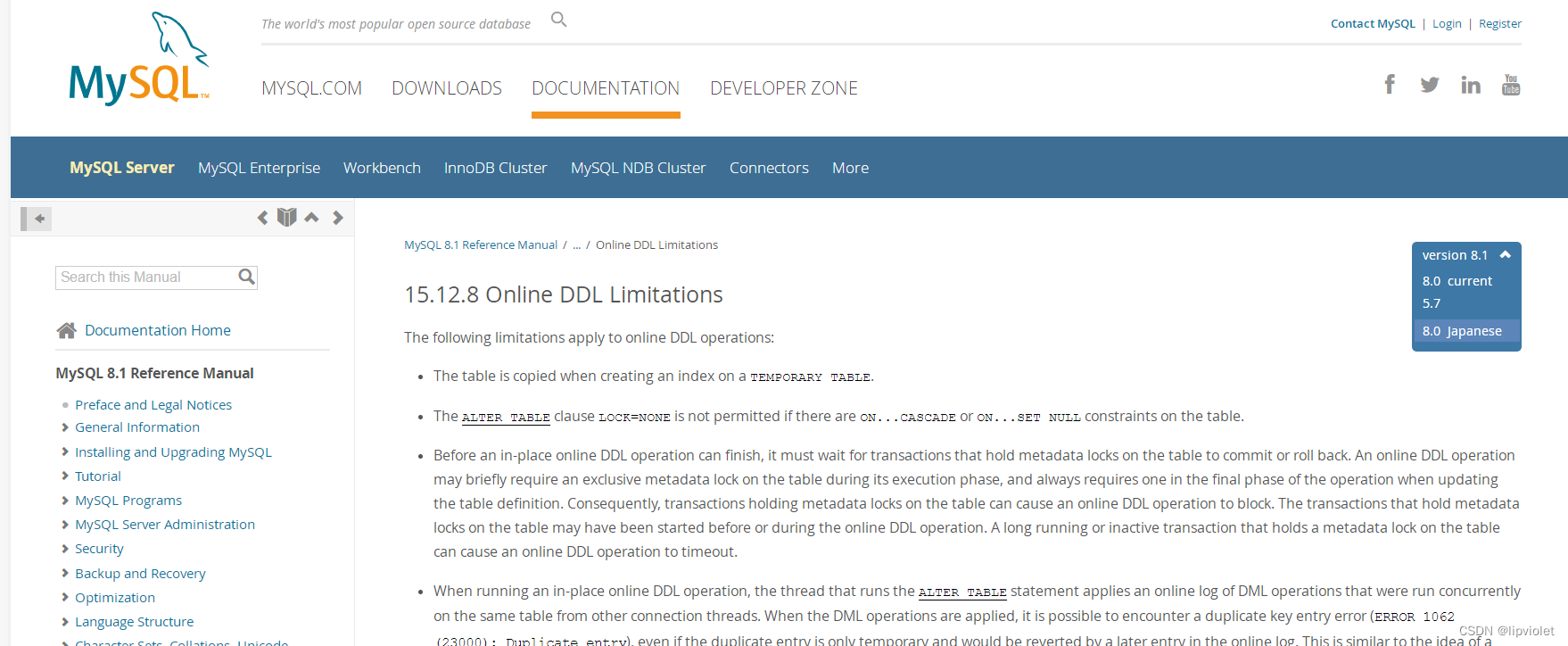
5.7无法在线DDL的类型,即阻塞DML的DDL
Adding a FULLTEXT index
Adding a SPATIAL index
Dropping a primary key
Changing the column data type
Generated Column Operations(即特殊的列创建,STORED column和VIRTUAL column)
Converting a character set
Partitioning Operations -
8.0比5.7没什么提升,仅仅是支持了在线增加分区和删除分区,而且还是有条件的增删。
-
总结就是,空间索引,全文索引,主键索引不支持在线修改;虚拟建不支持;涉及字符集的修改也不支持在线修改;分区相关操作也不支持在线修改。
原理
-
Online DDL 定义
在MySQL5.5以及之前的版本,通常更改数据表结构操作(DDL)会阻塞对表数据的增删改操作(DML) MySQL5.6提供Online DDL之后可支持DDL与DML操作同时执行,也就是降低了DDL期间对业务延迟带来的影响 Online DDL定义:指业务正常状态下进行数据表结构操作,不会影响不会阻塞表数据的增删改操作。 -
Online DDL特点
1.DDL操作可与应用的DML操作并发执行,改进在繁忙生产环境的响应和可用性,因为对于这种业务系统几分钟或几小时不可用是难以忍受的可以通过调整DDL的lock模式来平衡与DML操作的性能问题 2.Online DDL使用的是In-place方式,相较于table-copy方式能更少的使用I/O资源,在DDL期间也能有较高的吞吐量 3.In-place相较于table-copy还有一个优点是:table-copy读取数据多,频繁的使用buffer pool导致有效缓存数据被调出,影响缓存击中率 降低效率 在5.6版本之后,对于部分alter table ,加入新的执行算法,可以进行DDL时,“并行”有业务(DML操作)。 可以通过ALter table 时添加 ALGORITHM参数控制使用算法。 ALter table t1 add a int ALGORITHM=?; 目前可以支持的算法有三种: COPY INPLACE INSTANT DDL操作,在执行时,不管何种算法,都会经历三个阶段:准备阶段、执行阶段、提交阶段。不同之处是在三个阶段中分别作了不同的处理 online DDL in mysql 5.5 在mysql5.5版本中已经增加了in-place方式,但依然会阻塞insert,update,delete操作。 mysql 5.5 online ddl 原理: a. 按照原表的定义创建临时表; b. 对原表进行加写锁; c. 对新的临时表进行ddl操作; d. 将原表中的数据copy到临时表中; e. 释放原表的写锁; f. 将旧表删除,临时表重命名 存在的问题: a. 在进行copy data的过程中消耗的时间长,和消耗大量的存储空间; b. 在原表进行加锁时,业务会中断访问 online DDL in mysql5.6 在mysql5.6版本中,引入了新特性,Fast Index Create(FIC特性),支持更多的alter table语句来避免copy data同时支持了在线上DDL的过程中不阻塞DML操作。 mysql5.6参数设置: innodb_online_alter_log_max_size参数,默认为128M,但是在生产场景中512M会适合。在进行在线索引添加操作时,数据库性能有20-30%的下降 online DDL in mysql5.7 mysql5.7支持的新特性: a. 增加了alter table rename index 的语法支持,同时也继续支撑online DDL特性; b. 修改varchar列长度操作支持online特性。 mysql5.7 online DDL的原理: PREPARE: a. 创建新的临时.frm 文件; b. 持有排他-MDL锁,禁止读写; c. 根据alter 类型确定执行方式; d. 更新数据字典的内存对象; e. 分配row_log对象用来记录增量; f. 生成新的临时ibd文件; DDL: g. 降级排他锁为S锁; h. 扫描old_table的聚簇索引每一条记录reo,并遍历新表的索引进行处理; i. 根据reo构造对应的索引项对应的索引项,将构造索引项插入soft_buffer块排序; j. 将sort_buffer块更新到新的索引上; k. 记录ddl执行过程中产生的增量并在新表上重放; l. 记录ddl执行过程中产生的增量(仅rebuild类型需要); m. 重放row_log间产生dml操作append到row_log最后一个block; COMMIT; n. 当前block为row_log最后一个时,禁止读写,升级到排他-MDL锁; o.重做row_log中最后一部分增量; p.更新innodb的数据字典表; q. 提交事务(刷事务的redo日志) r. 修改统计信息; s. rename临时ibd文件,.frm文件 online DDL使用限制与问题: a. 仍然存在排他锁,有锁等待的风险; b. 跟5.6一样,增量日志大小是有限制的; c. 有可能造成主从延迟; d. 无法暂停,只能中断。 -
Online DDL过程介绍
ddl包含了copy和inplace方式,对于不支持online的ddl操作采用copy方式。对于inplace方式,mysql内部以“是否修改记录格式”为基准也分为两类,一类需要重建表(重新组织记录),比如optimize table、添加索引、添加/删除列、修改列NULL/NOT NULL属性等;另外一类是只需要修改表的元数据,比如删除索引、修改列名、修改列默认值、修改列自增值等。Mysql将这两类方式分别称为rebuild方式和no-rebuild方式。更多关于哪些DDL是否可以inplace的内容可以参考官方文档:https://dev.mysql.com/doc/refman/5.7/en/innodb-create-index-overview.html。 online ddl主要包括3个阶段,prepare阶段,ddl执行阶段,commit阶段,rebuild方式比no-rebuild方式实质多了一个ddl执行阶段,prepare阶段和commit阶段类似。ddl执行过程中包括三个阶段。 Prepare阶段: 创建新的临时frm文件 持有EXCLUSIVE-MDL锁,禁止读写 根据alter类型,确定执行方式(copy,online-rebuild,online-norebuild) 更新数据字典的内存对象 分配row_log对象记录增量 生成新的临时ibd文件 ddl执行阶段: 降级EXCLUSIVE-MDL锁,允许读写 扫描old_table的聚集索引每一条记录rec 遍历新表的聚集索引和二级索引,逐一处理 根据rec构造对应的索引项 将构造索引项插入sort_buffer块 将sort_buffer块插入新的索引 处理ddl执行过程中产生的增量(仅rebuild类型需要) commit阶段 升级到EXCLUSIVE-MDL锁,禁止读写 重做最后row_log中最后一部分增量 更新innodb的数据字典表 提交事务(刷事务的redo日志) 修改统计信息 rename临时idb文件,frm文件 变更完成 -
Copy 算法原理
指DDL时,会生成(临时)新表,将原表数据逐行拷贝到新表中,在此期间会阻塞DML,offline 准备阶段: 1、对表加元数据共享锁,读取frm元数据(此时DDL不能不行) 2、共享锁升级为排他锁;(此时DDL、DML都不能并行) 3、在Server层通过Create like语句,创建临时表,Engine层也生成对应ibd、frm文件 执行、提交阶段: 1、修改临时表元数据 2、拷贝原表数据到临时表 3、重命令临时表及文件 4、删除原表及文件 5、提交事务,释放锁 -
INPLACE 算法原理
无需拷贝全表数据到新表,但可能还是需要IN-PLACE方式(原地,无需生成新的临时表)重建整表。这种情况下,在DDL的初始准备和最后结束两个阶段时通常需要加排他MDL锁(metadata lock,元数据锁),除此外,DDL期间不会阻塞DML 准备阶段: 1、对表加元数据共享升级锁,并升级为排他锁;(此时DML不能并行) 2、判断语句rebuild table,no-rebuild,no-rebuild 在原表所在的路径下创建.frm和.ibd临时中转文件; no-rebuild除创建二级索引外只创建.frm文件,其中添加二级索引操作最为特殊,该操作属于no-rebuild不会生成.ibd,但实际上对.ibd文件却做了修改,该操作会在参数tmpdir指定路径下生成临时文件,用于存储索引排序结果,然后再合并到.ibd文件中. 3、申请row log空间,用于存放DDL执行阶段产生的DML操作。(no-rebuild不需要) 执行阶段: (online) 1、释放排他锁,保留元数据共享升级锁;(此时DML可以并行) 2、扫描原表主键以及二级索引的所有数据页,生成 B+ 树,存储到临时文件中; 3、将所有对原表的DML操作记录在日志文件row log中。 提交阶段: 1、升级元数据共享升级锁,产生排他锁锁表;(此时DML不能并行) 2、重做row log中的内容;(no-rebuild不需要) 3、重命名原表文件,将临时文件改名为原表文件名,删除原表文件; 4、提交事务,变更完成。 在DDL期间产生的数据,会按照正常操作一样,写入原表,记redolog、undolog、binlog,并同步到从库去执行,只是额外会记录在row log中,并且写入row log的操作本身也会记录redolog,而在提交阶段才进行row log重做,此阶段会锁表,此时主库(新表空间+row log)和从库(表空间)数据是一致的,在主库DDL操作执行完成并提交,这个DDL才会写入binlog传到从库执行,在从库执行该DDL时,这个DDL对于从库本地来讲仍然是online的,也就是在从库本地直接写入数据是不会阻塞的,也会像主库一样产生rowlog。但是对于主库同步过来DML,此时会被阻塞,是offline的,DDL是排他锁的在复制线程中也是一样,所以不只会阻塞该表,而是后续所有从主库同步过来的操作(主要是在复制线程并行时会排他,同一时间只有他自己在执行)。所以大表的DDL操作,会造成同步延迟。 PREPARE: a. 创建新的临时.frm 文件; b. 持有排他-MDL锁,禁止读写; c. 根据alter 类型确定执行方式; d. 更新数据字典的内存对象; e. 分配row_log对象用来记录增量; f. 生成新的临时ibd文件; DDL: g. 降级排他锁为S锁; h. 扫描old_table的聚簇索引每一条记录reo,并遍历新表的索引进行处理; i. 根据reo构造对应的索引项对应的索引项,将构造索引项插入soft_buffer块排序; j. 将sort_buffer块更新到新的索引上; k. 记录ddl执行过程中产生的增量并在新表上重放; l. 记录ddl执行过程中产生的增量(仅rebuild类型需要); m. 重放row_log间产生dml操作append到row_log最后一个block; COMMIT; n. 当前block为row_log最后一个时,禁止读写,升级到排他-MDL锁; o.重做row_log中最后一部分增量; p.更新innodb的数据字典表; q. 提交事务(刷事务的redo日志) r. 修改统计信息; s. rename临时ibd文件,.frm文件 online DDL使用限制与问题: a. 仍然存在排他锁,有锁等待的风险; b. 跟5.6一样,增量日志大小是有限制的; c. 有可能造成主从延迟; d. 无法暂停,只能中断。 -
INPLACE 与COPY区别
ALGORITHM=COPY是MySQL5.5以及之前的方式 ALGORITHM=INPLACE是MySQL5.6引入的方式 COPY算法,由service层创建一个临时表用于copy数据,然后用新表替换旧表 INPLACE算法,“原位替换” 其实主要是指在InnoDB内部完成的DDL操作,在InnoDB内部创建临时文件。整个 DDL 过程都在 InnoDB 内部完成。对于 server 层来说,没有把数据挪动到临时表,是一个“原地”操作,这就是“inplace”名称的来源。 因此对于INPLACE其实分为非重建表和重建表两类方式,非重建表方式直接在原表基础上更新,效率最高;重建表同样需要copy数据(比如新增字段) 详情请参考mysql5.7