文章目录
- 一.PromQL 简介
- 1.PromQL概念
- 2.时间序列
- 3.Prometheus数据模型
- 4.指标名称及标签使用注意事项
- 5.样本数据格式
- 二.PromQL 的数据类型
- 1.PromQL 的表达式中支持 4 种数据类型
- 2.时间序列选择器(Time series Selectors)
- ①瞬时向量选择器由两部分组成
- ②定义瞬时向量选择器
- ③偏移向量选择器
- ④向量表达式使用要点
- 三.PromQL 的指标类型
- 1.PromQL 有四个指标类型
- ①Counter
- ②Gauge
- ③Histogram
- 2.Histogram 与 Summary 的异同:
- 四.Prometheus 的聚合函数
- 1.概念
- 2.Prometheus 内置提供的 11 个聚合函数,也称为聚合运算符
- 3.PromQL 的聚合表达式
- ①PromQL 的聚合表达式分类及概念
- ②示例
- 五.传统部署 Alertmanager 发送告警
- 1.为何会有 Alertmanager
- 2.部署 Alertmanager
- (1)导入安装包
- (2)修改 alertmanager 配置文件,添加邮件告警路由信息
- (3)配置启动文件
- (4)添加告警规则
- (5)修改 prometheus 配置文件,添加 Alertmanager 实例的配置
- (6)测试告警
- 3.使用钉钉告警
- (1)上传部署安装包
- (2)在钉钉上进行群设置
- (3)修改 dingtalk 告警插件配置文件
- (4)修改 alertmanager 配置文件
- (5)测试告警
一.PromQL 简介
1.PromQL概念
PromQL (Prometheus Query Language) 是 Prometheus 内置的数据查询语言。支持用户进行实时的数据查询及聚合操作。
2.时间序列
Prometheus 基于指标名称(metrics name)以及附属的标签集(labelset)唯一定义一条时间序列
●指标名称代表着监控目标上某类可测量属性的基本特征标识
●标签则是这个基本特征上再次细分的多个可测量维度
基于 PromQL 表达式,用户可以针对指定的特征及其细分的纬度进行过滤、聚合、统计等运算从而产生期望的计算结果
●PromQL 使用表达式(expression)来表述查询需求
●根据其使用的指标和标签,以及时间范围,表达式的查询请求可灵活地覆盖在一个或多个时间序列的一定范围内的样本之上,甚至是只包含单个时间序列的单个样本
3.Prometheus数据模型
Prometheus 中,每个时间序列都由指标名称(Metric Name) 和标签 (Label) 唯一标识
格式为:<metric_name>{<label_name>=<label_value>, …}
●指标名称:通常用于描述系统上要测定的某个特征
例如,prometheus_http_requests_total 表示接收到的 HTTP 请求总数
●标签:键值型数据,附加在指标名称之上,从而让指标能够支持多纬度特征;可选项
例如,prometheus_http_requests_total{code=“200”} 和 prometheus_http_requests_total{code=“302”} 代表着两个不同的时间序列
●双下划线的标签(例如 __address__ )是 Prometheus 系统默认标签,是不会显示在 /metrics 页面里面的;
●系统默认标签在 target 页面中也是不显示的,需要鼠标放到 label 字段上才会显示。
●常见的系统默认标签:
__address__ :当前 target 实例的套接字地址 <host>:<port>
__scheme__ :采集当前 target 上指标数据时使用的协议(http 或 https)
__metrics_path__ :采集当前 target 上的指标数据时使用 URI 路径,默认为 /metrics
__param_<name> :传递的 URL 参数中第一个名称为 <name> 的参数的值
__name__ : 此标签是标识指标名称的预留标签,能够使用标签选择器对指标名称进行过滤
4.指标名称及标签使用注意事项
●指标名称和标签的特定组合代表着一个时间序列;指标名称相同,但标签不同的组合分别代表着不同的时间序列;不同的指标名称自然更是代表着不同的时间序列
●PromQL支持基于定义的指标维度进行过滤和聚合;更改任何标签值,包括添加或删除标签,都会创建一个新的时间序列;应该尽可能地保持标签的稳定性,否则,则很可能创建新的时间序列,更甚者会生成一个动态的数据环境,并使得监控的数据源难以跟踪,从而导致建立在该指标之上的图形、告警及记录规则变得无效
5.样本数据格式
Prometheus 的每个数据样本由两部分组成
●毫秒精度的时间戳
●float64 格式的数据
prometheus_http_requests_total{code="200", handler="/targets", instance="localhost:9090", job="prometheus"} @1434317560885 28
prometheus_http_requests_total{code="200", handler="/targets", instance="localhost:9090", job="prometheus"} @1434317561483 35
prometheus_http_requests_total{code="200", handler="/targets", instance="localhost:9090", job="prometheus"} @1434317562589 42
prometheus_http_requests_total{code="200", handler="/targets", instance="localhost:9090", job="prometheus"} @1434317563654 50
| || | | | |
---------- 指标名称 -------- ------------------------ 标签 --------------------------------------------- -- 时间戳 -- 样本值
二.PromQL 的数据类型
1.PromQL 的表达式中支持 4 种数据类型
●瞬时向量 (Instant vector): 特定或全部的时间序列集合上,具有相同时间戳的一组样本值
●区间向量 (Range vector): 特定或全部的时间序列集合上,在指定的同一时间范围内的所有样本值
●标量数据 (Scalar): 一个浮点型的数据值
●字符串 (String): 一个字符串,支持使用单引号、双引号进行引用
2.时间序列选择器(Time series Selectors)
PromQL 的查询操作可能需要针对若干个时间序列上的样本数据进行,挑选出目标时间序列是构建表达式时最为关键的一步;
用户可使用向量选择器表达式来挑选出给定指标名称下的所有时间序列或部分时间序列的即时样本值或至过去某个时间范围内的样本值,前者称为瞬时向量选择器,后者称为区间向量选择器。
●瞬时向量选择器(Instant Vector Selectors)
瞬时向量选择器可以返回 0 个、1 个或多个时间序列上在给定时间戳(instant)上的各自的一个样本。
①瞬时向量选择器由两部分组成
◆指标名称:用于限定特定指标下的时间序列,即负责过滤指标;可选
◆标签选择器:用于过滤时间序列上的标签;定义在 {} 之中;可选
②定义瞬时向量选择器
(1)定义瞬时向量选择器时,以上两个部分应该至少给出一个;因此存在以下三种组合:
◆仅给定指标名称,或在标签名称上使用了空值的标签选择器:返回给定的指标下的所有时间序列各自的即时样本
例如,prometheus_http_requests_total 和 prometheus_http_requests_total{} 的功能相同,都是用于返回这个指标下各时间序列的即时样本
◆仅给定标签选择器:返回所有符合给定的标签选择器的所有时间序列上的即时样本
例如,{code=“200”, job=“prometheus”} ,这样的时间序列可能会有着不同的指标名称
◆指标名称和标签选择器的组合:返回给定的指标下的,且符合给定的标签过滤器的所有时间序列上的即时样本
例如,prometheus_http_requests_total{code=“200”, job=“prometheus”},用于返回这个指标 code 为 200, 并且 job 为 prometheus 的时间序列的即时样本
(2)标签选择器用于定义标签过滤条件,目前支持如下4种匹配操作符:
= :完全相等
!= : 不相等
=~ : 正则表达式匹配
!~ : 正则表达式不匹配
(3)注意事项
◆匹配到空标签值的标签选择器时,所有未定义该标签的时间序列同样符合条件
例如,prometheus_http_requests_total{handler= “”},则该指标名称上所有未使用该标签(handler)的时间序列也符合条件
◆正则表达式将执行完全锚定机制,它需要匹配指定的标签的整个值
◆向量选择器至少要包含一个指标名称,或者至少有一个不会匹配到空字符串的标签选择器
例如,{ job=“”} 为非法的向量选择器
◆使用 name 做为标签名称,还能够对指标名称进行过滤
例如,{name=~“.*http_requests_total”} 能够匹配所有以 http_requests_total 为后缀的所有指标
●区间向量选择器(Range Vector Selectors)
区间向量选择器可以返回 0 个、1 个或多个时间序列上在本。
区间向量选择器的不同之处在于,需要通过在瞬时向量选择器表达式后面添加包含在给定时间范值围内的各自的一组样 [] 里的时长来表达需在时间时序上返回的样本所处的时间范围。
时间范围:以当前时间为基准时间点,指向过去一个特定的时间长度;例如,[5m] 是指过去 5 分钟之内。
◆可用的时间单位有 ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)和 y(年)
◆必须使用整数时间,且能够将多个不同级别的单位进行串联组合,以时间单位由大到小为顺序,例如 1h30m,但不能使用 1.5h
③偏移向量选择器
前面介绍的选择器默认都是以当前时间为基准时间,偏移修饰器用来调整基准时间,使其往前偏移一段时间。偏移修饰器紧跟在选择器后面,使用关键字 offset 来指定要偏移的量。
例如,prometheus_http_requests_total offset 5m ,表示获取以 prometheus_http_requests_total 为指标名称的所有时间序列在过去 5 分钟之时的即时样本;
prometheus_http_requests_total[5m] offset 1d ,表示获取距此刻 1 天时间之前的 5 分钟之内的所有样本
④向量表达式使用要点
●表达式的返回值类型亦是即时向量、范围向量、标题或字符串4种数据类型其中之一,但是,有些使用场景要求表达式返回值必须满足特定的条件,例如:
(1)需要将返回值绘制成图形时,仅支持即时向量类型的数据;
(2)对于诸如 rate、irate 之类的速率函数来说,其要求使用的却又必须是区间向量型的数据
●由于区间向量选择器的返回的是区间向量型数据,它不能用于表达式浏览器中图形绘制功能
●区间向量选择器通常会结合速率类的函数 rate、irate 一同使用
三.PromQL 的指标类型
1.PromQL 有四个指标类型
●Counter :计数器,用于保存单调递增型的数据;例如站点访问次数等。数据单调递增,不支持减少,不能为负值,重启进程后,会被重置回 0 ;
●Gauge :仪表盘,用于存储有着起伏特征的指标数据,例如内存空闲大小等。数据可变大,可变小;重启进程后,会被重置;
●Histogram :累积+直方图,将时间范围内的数据划分成不同的时间段,并各自评估其样本个数及样本值之和,因而可计算出分位数;
◆可用于分析因异常值而引起的平均值过大的问题;
◆分位数计算要使用专用的 histogram_quantile 函数;
●Summary :类似于 Histogram,但会在客户端直接计算并上报分位数;在客户端算几率比服务端更高 精确度更高
①Counter
通常,Counter 的总数并没有直接作用,而是需要借助于 rate、topk、increase 和 irate 等函数来生成样本数据的变化状况(增长率/变化率):
●topk(3, prometheus_http_requests_total),获取该指标下 http 请求总数排名前 3 的时间序列
●rate(prometheus_http_requests_total[1h]) ,获取 1 小内,该指标下各时间序列上的 http 总请求数的增长速率
●irate(prometheus_http_requests_total[1h])
irate 为高灵敏度函数,用于计算指标的瞬时速率,基于样本范围内的最后两个样本进行计算,相较于 rate 函数来说,irate 更适用于短期时间范围内的变化速率分析。
②Gauge
Gauge 用于存储其值可增可减的指标的样本数据,常用于进行求和、取平均值、最小值、最大值等聚合计算;
也会经常结合 PromQL 的 delta 和 predict_linear 函数使用:
●delta 函数计算范围向量中每个时间序列元素的第一个值与最后一个值之差,从而展示不同时间点上的样本值的差值
例如,delta(cpu_temp_celsius{host=“node01”}[2h]) ,返回该服务器上的CPU温度与2小时之前的差异
●predict_linear 函数可以预测时间序列 v 在 t 秒后的值,它通过线性回归的方式,对样本数据的变化趋势做出预测
例如,predict_linear(node_filesystem_free{job=“node”}[2h], 4 * 3600) ,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况
③Histogram
(1)对于 Prometheus 来说,Histogram 会在一段时间范围内对数据进行采样(通常是请求持续时长或响应大小等),并将其计入可配置的 bucket(存储桶)中 ,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
(2)Prometheus 取值间隔的划分采用的是累积区间间隔机制,即每个 bucket 中的样本均包含了其前面所有 bucket 中的样本,因而也称为累积直方图。
(3)Histogram 类型的每个指标有一个基础指标名称 ,它会提供多个时间序列:
●_sum :所有样本值的总和
●_count :总的采样次数,它自身本质上是一个 Counter 类型的指标
●_bucket{le=“<上边界>”} :观测桶的上边界,即样本统计区间,表示样本值小于等于上边界的所有样本数量
_bucket{le=“+Inf”} :最大区间(包含所有样本)的样本数量
(4)使用 histogram
在大多数情况下人们一般倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 Web 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10 ms 之间的请求数有多少,而 10~20 ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
2.Histogram 与 Summary 的异同:
它们都包含了 _sum 和 _count 指标,Histogram 需要通过 _bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
四.Prometheus 的聚合函数
1.概念
一般说来,单个指标的价值不大,监控场景中往往需要联合并可视化一组指标,这种联合机制即是指“聚合”操作,例如,将计数、求和、平均值、分位数、标准差及方差等统计函数应用于时间序列的样本之上生成具有统计学意义的结果等。
对查询结果事先按照某种分类机制进行分组(group by)并将查询结果按组进行聚合计算也是较为常见的需求,例如分组统计、分组求平均值、分组求和等。
Prometheus 的聚合操作由聚合函数针对一组值进行计算并返回值作为结果。
2.Prometheus 内置提供的 11 个聚合函数,也称为聚合运算符
●sum():对样本值求和
●min() :求取样本值中的最小者
●max() :求取样本值中的最大者
●avg() :对样本值求平均值
●count() :对分组内的时间序列进行数量统计
●stddev() :对样本值求标准差,以帮助用户了解数据的波动大小(或称之为波动程度)
●stdvar() :对样本值求方差,它是求取标准差过程中的中间状态
●topk() :逆序返回分组内的样本值最大的前 k 个时间序列及其值,即最大的 k 个样本值
●bottomk() :顺序返回分组内的样本值最小的前 k 个时间序列及其值,即最小的 k 个样本值
●quantile() :分位数,用于评估数据的分布状态,该函数会返回分组内指定的分位数的值,即数值落在小于等于指定的分位区间的比例
●count_values() :对分组内的时间序列的样本值进行数量统计,即等于某值的样本个数
3.PromQL 的聚合表达式
①PromQL 的聚合表达式分类及概念
PromQL 中的聚合操作语法格式可采用如下面两种格式之一:
● <聚合函数>(向量表达式) by|without (标签)
● <聚合函数> by|without (标签) (向量表达式)
分组聚合:先分组、后聚合
by :仅使用by子句中指定的标签进行聚合,结果向量中出现但未被 by 指定的标签则会被忽略;
为了保留上下文信息,使用 by 子句时需要显式指定其结果中原本出现的 job、instance 等一类的标签。(和without正好相反,结果向量中只保留列出的标签,其余标签全部移除)
without:从结果向量中删除由 without 指定的标签,未指定的那部分标签则用作分组标准**(用于从计算结果中移除列举的标签而保留其他标签)**
②示例
(1)每台主机 CPU 在最近 5 分钟内的平均使用率
(1 - avg(rate(node_cpu_seconds_total{mode=“idle”}[5m])) by (instance)) * 100

(2)查询 1 分钟的 load average 的时间序列是否超过主机 CPU 数量 2 倍就会触发告警
node_load1 > on (instance) 2 * count (node_cpu_seconds_total{mode=“idle”}) by (instance)
(3)计算主机内存使用率
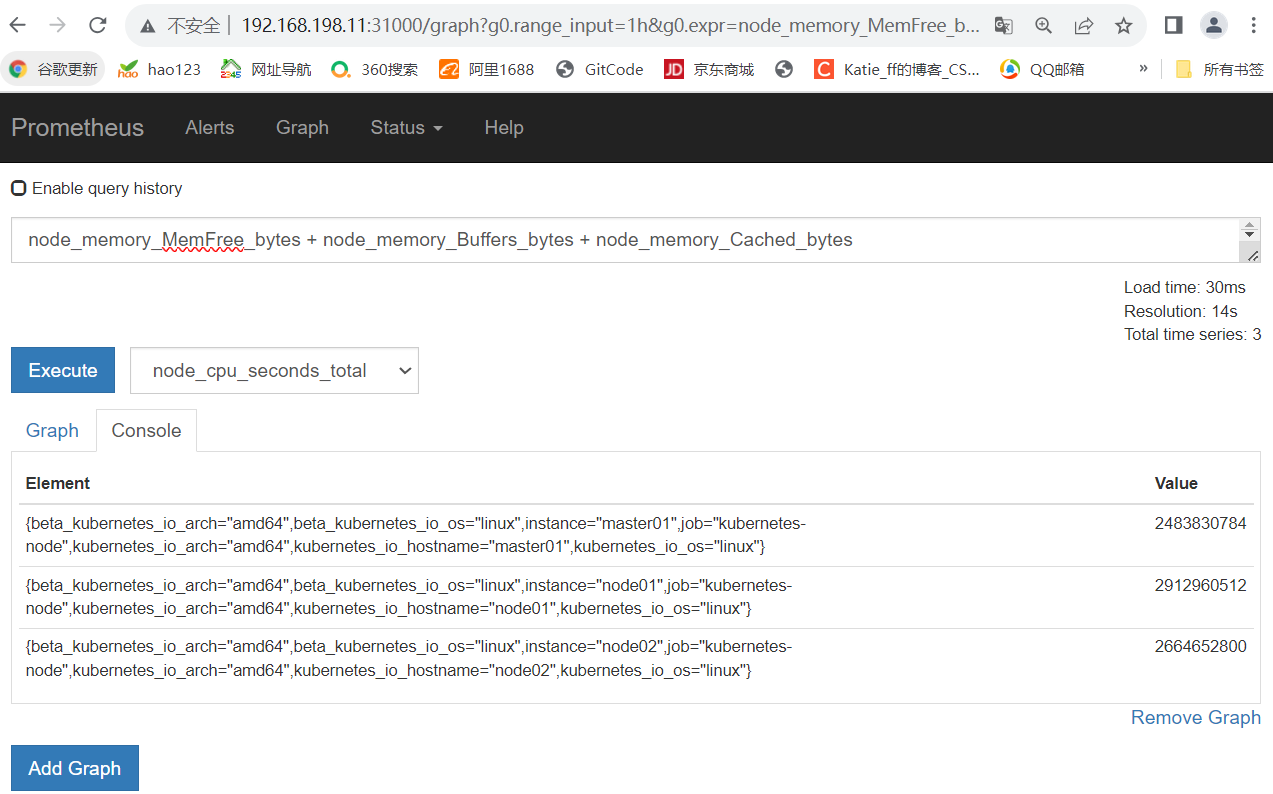
可用内存空间:空闲内存、buffer、cache 指标之和
node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes
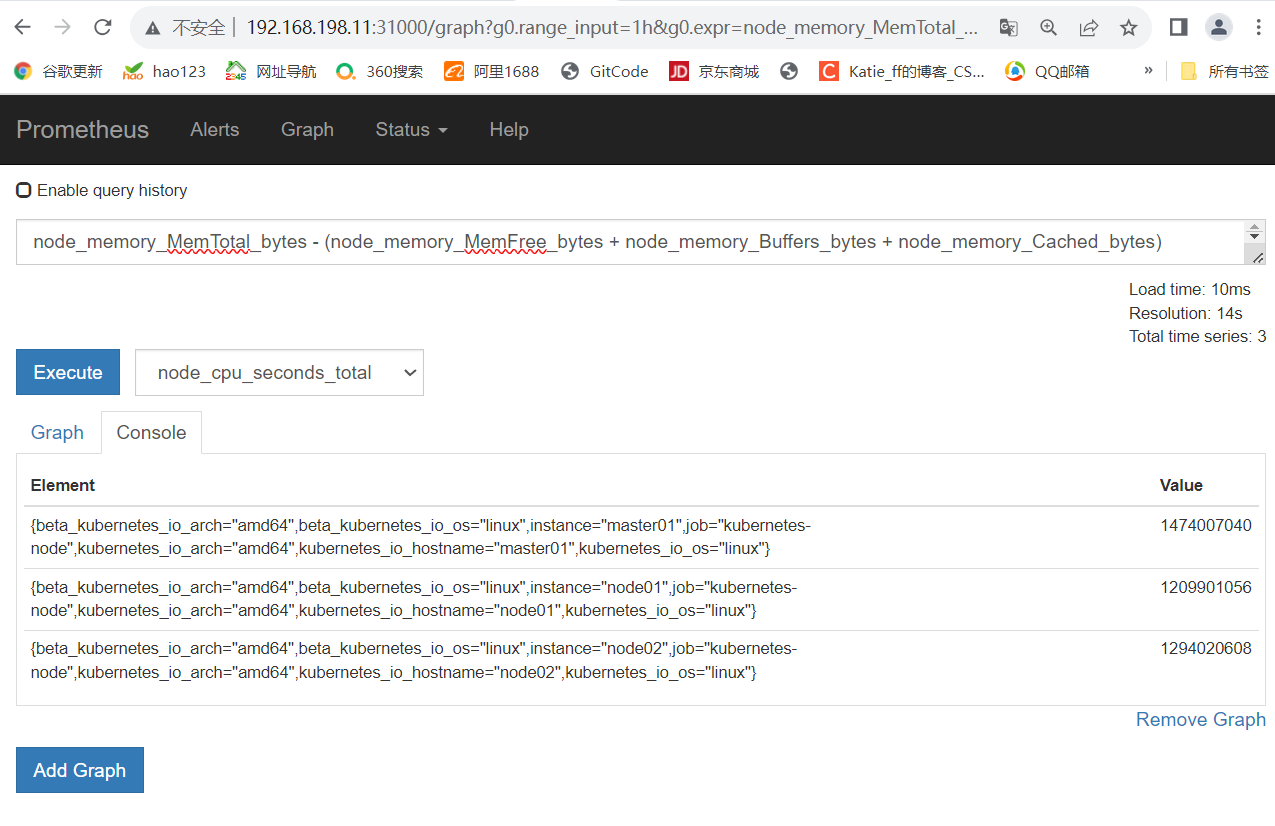
已用内存空间:总内存空间减去可用空间
node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)
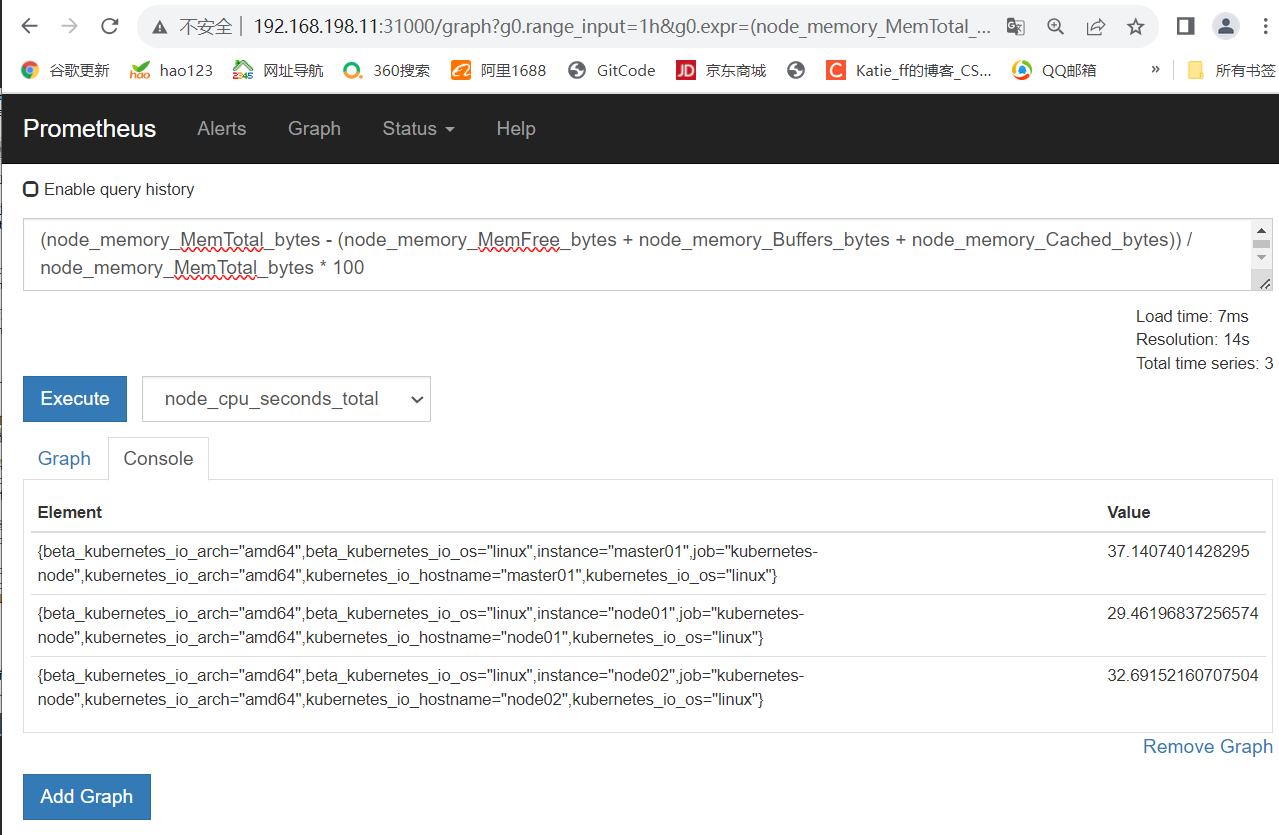
使用率:已用空间除以总空间
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100
(4)计算所有 node 节点所有容器总计内存:
sum by (instance) (container_memory_usage_bytes{instance=~“node*”})/1024/1024/1024
(5)计算 node01 节点最近 1m 所有容器 cpu 使用率:
sum (rate(container_cpu_usage_seconds_total{instance=“node01”}[1m])) / sum (machine_cpu_cores{instance=“node01”}) * 100
#container_cpu_usage_seconds_total 代表容器占用CPU的时间总和
(6)计算最近 5m 每个容器 cpu 使用情况变化率
sum (rate(container_cpu_usage_seconds_total[5m])) by (container_name)
(7)查询 K8S 集群中最近 1m 每个 Pod 的 CPU 使用情况变化率
sum (rate(container_cpu_usage_seconds_total{image!=“”, pod_name!=“”}[1m])) by (pod_name)
#由于查询到的数据都是容器相关的,所以最好按照 Pod 分组聚合
五.传统部署 Alertmanager 发送告警
1.为何会有 Alertmanager
Prometheus 对指标的收集、存储与告警能力分属于 Prometheus Server 和 AlertManager 两个独立的组件,前者仅负责定义告警规则生成告警通知, 具体的告警操作则由后者完成。
Alertmanager 负责处理由 Prometheus Server 发来的告警通知,Alertmanager对告警通知进行分组、去重后,根据路由规则将其路由到不同的receiver,如
Email、钉钉或企业微信等。
除了基本的告警通知能力外,Altermanager还支持对告警进行去重、分组、抑制、静默和路由等功能:
●分组(Grouping):将相似告警合并为单个告警通知的机制,在系统因大面积故障而触发告警潮时,分组机制能避免用户被大量的告警噪声淹没,进而导致关键信息的隐没
●抑制(Inhibition):系统中某个组件或服务故障而触发告警通知后,那些依赖于该组件或服务的其它组件或服务可能也会因此而触发告警,抑制便是避免类似的级联告警的一种特性,从而让用户能将精力集中于真正的故障所在
●静默(Silent):是指在一个特定的时间窗口内,即便接收到告警通知,Alertmanager也不会真正向用户发送告警信息的行为;通常,在系统例行维护期间,需要激活告警系统的静默特性
●路由(route):用于配置Alertmanager如何处理传入的特定类型的告警通知,其基本逻辑是根据路由匹配规则的匹配结果来确定处理当前告警通知的路径和行为
2.部署 Alertmanager
(1)导入安装包
#上传 alertmanager-0.24.0.linux-amd64.tar.gz 到 /opt 目录中,并解压
cd /opt/
tar xf alertmanager-0.24.0.linux-amd64.tar.gz
mv alertmanager-0.24.0.linux-amd64 /usr/local/alertmanager
(2)修改 alertmanager 配置文件,添加邮件告警路由信息
vim /usr/local/alertmanager/alertmanager.yml
#global 配置段用于定义全局配置
#templates 配置段负责自定义告警内容模板文件
#route 配置段用于指定如何处理传入的告警
#receiver 配置段则定义了告警信息的接收器,每个接收器都应该有其具体的定义
global: #在全局配置段设置发件人邮箱信息
resolve_timeout: 5m #定义持续多长时间未接收到告警通知后,就将告警状态标记为resolved
smtp_smarthost: 'smtp.qq.com:25'
smtp_from: 'qwe4546456@qq.com'
smtp_auth_username: 'qwe4546456@qq.com'
smtp_auth_password: 'zxnlltckqkrxxxcc' #此处为授权码,登录QQ邮箱【设置】->【账户】中的【生成授权码】获取
smtp_require_tls: false #禁用TLS的传输方式
route: #设置告警的分发策略
group_by: ['alertname'] #采用哪个标签来作为分组依据,这里使用告警名称做为规则,满足规则的告警将会被合并到一个通知中
group_wait: 20s #一组告警第一次发送之前等待的时延,即产生告警20s将组内新产生的消息合并发送,通常是0s~几分钟(默认是30s)
group_interval: 5m #一组已发送过初始告警通知的告警,接收到新告警后,下次发送通知前等待时延,通常是5m或更久(默认是5m)
repeat_interval: 20m #一组已经发送过通知的告警,重复发送告警的间隔,通常设置为3h或者更久(默认是4h)
receiver: 'my-email' #定义告警接收人
receivers: #设置收件人邮箱信息
- name: 'my-email'
email_configs:
- to: 'qwe4546456@wo.cn' #设置收件人邮箱地址
send_resolved: true
(3)配置启动文件
cat > /usr/lib/systemd/system/alertmanager.service <<'EOF'
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--log.level=debug
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
#启动 Alertmanager
systemctl start alertmanager
systemctl enable alertmanager
netstat -natp | grep :9093
(4)添加告警规则
mkdir /usr/local/prometheus/alter_rules
vim /usr/local/prometheus/alter_rules/instance_down.yaml
groups:
#若某个 Instance 的 up 指标的值转为 0 持续超过 1 分钟后,将触发告警
- name: AllInstances
rules:
- alert: InstanceDown #告警规则的名称,一个组内的告警规则名称必须惟一
# Condition for alerting
expr: up == 0 #基于PromQL表达式的告警触发条件(布尔表达式)
for: 1m #控制在触发告警之前,测试表达式的值必须为true的时长
#表达式值为true,但其持续时间未能满足for定义的时长时,相关的告警状态为pending
#满足该时长之后,相关的告警将被触发,并转为firing状态
#表达式的值为false时,告警将处于inactive状态
# Annotation - additional informational labels to store more information
annotations: #附加在告警之上的注解信息
title: 'Instance down'
description: Instance has been down for more than 1 minute.'
# Labels - additional labels to be attached to the alert
labels:
severity: 'critical' #在告警上附加的自定义的标签
#CPU 使用率大于 80% 触发告警
- name: node_alert
rules:
- alert: cpu_alert
expr: 100 -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)* 100 > 80
for: 5m
labels:
level: warning
annotations:
description: "instance: {{ $labels.instance }} ,cpu usage is too high ! value: {{$value}}"
summary: "cpu usage is too high"
怎么基于prometheus监控的?
基于PromQL表达式的告警触发条件(布尔表达式)
expr: up == 0 或者不等于0
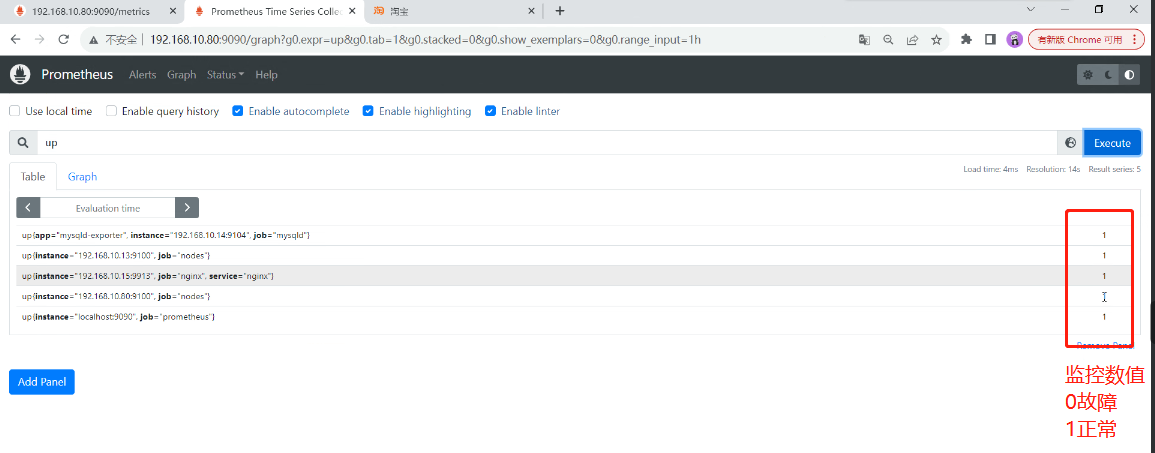
怎么监控cpu?
使用expr判断条件是否成立,条件成立会立刻告警,在一定的等待时间后会发送,
(5)修改 prometheus 配置文件,添加 Alertmanager 实例的配置
vim /usr/local/prometheus/prometheus.yml
......
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.198.11:9093
rule_files:
- "/usr/local/prometheus/alert_rules/*.yaml"
systemctl reload prometheus
(6)测试告警
systemctl stop node_exporter
3.使用钉钉告警
(1)上传部署安装包
上传 prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz 到 /opt 目录中,并解压
cd /opt/
tar xf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
mv prometheus-webhook-dingtalk-2.1.0.linux-amd64 /usr/local/dingtalk
(2)在钉钉上进行群设置
创建群 -> 群设置 -> 智能群助手 -> 添加机器人 -> 添加机器人 -> 自定义
消息推送 开启
Webhook 复制
安全设置 -> 勾选 加签 -> 复制
点击完成
(3)修改 dingtalk 告警插件配置文件
cd /usr/local/dingtalk
cp -p config.example.yml config.yml
vim config.yml
timeout: 5s
## Uncomment following line in order to write template from scratch (be careful!)
#no_builtin_template: true
## Customizable templates path
templates:
- contrib/templates/legacy/template.tmpl
## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
default_message:
title: '{{ template "legacy.title" . }}'
text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook1:
url: <粘贴Webhook的内容>
# secret for signature
secret: <粘贴加签的内容>
#启动服务
./prometheus-webhook-dingtalk
(4)修改 alertmanager 配置文件
vim /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: [alertname]
group_wait: 10s
group_interval: 15s
repeat_interval: 20m
receiver: 'dingding.webhook1'
receivers:
- name: 'dingding.webhook1'
webhook_configs:
- url: 'http://192.168.80.30:8060/dingtalk/webhook1/send'
send_resolved: true
systemctl reload alertmanager
(5)测试告警
systemctl stop node_exporter

![[华为杯研究生创新赛 2023] 初赛 REV WP](https://img-blog.csdnimg.cn/fbf3817cca904f3caa73e2ff31e9252c.png)