大语言模型Llama2 7B+中文alpace模型本地部署
VX关注晓理紫并回复llama获取推理模型
[晓理紫]
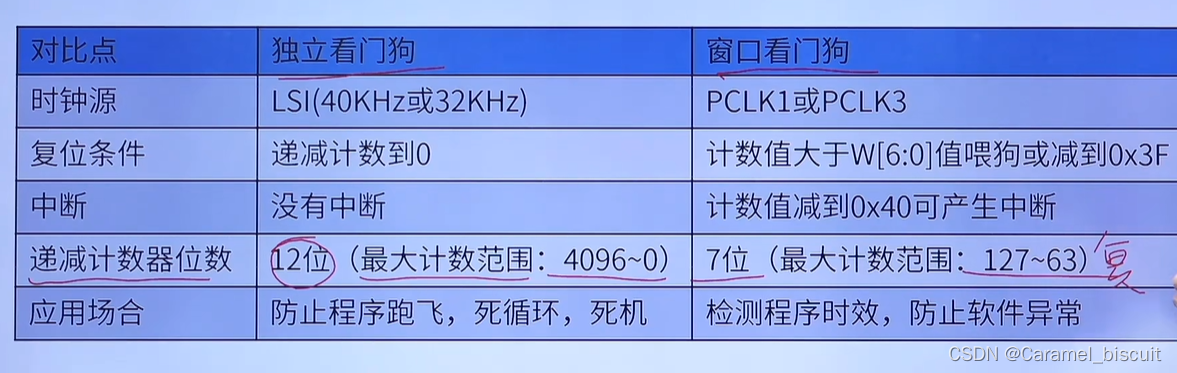
1、Llama模型
一个由facebook发布的生成式语言模型,具体可以到其官方了解。
为了大家更好理解,这里把目录结构显示下一如下图。

2、 下载Llama并配置环境
2.1 下载Llama源码
git clone https://github.com/facebookresearch/llama.git
2.2 创建环境
可以使用conda创建虚拟环境也可以直接使用pip创建环境,这里使用conda创建并激活环境。
conda create -n llama python=3.8
conda activate llama
进入到刚下载的源码目录
cd llama
pip install -e .
此时基本环境已经完成
3、下载权重
Llama提供好几种大小的权重,目前我只能跑最小的7B,因此下载7B大小权重。
3.1、Llama权重下载
到huggingface中进行搜索Llama即可。这个网站需要注册,这里也提高一个使用的下载地址。
https://huggingface.co/nyanko7/LLaMA-7B/tree/main
3.2、基于7B模型微调的中文alpace模型下载
可到下列地址进行下载
https://huggingface.co/ziqingyang/chinese-alpaca-lora-7b/tree/main
4、模型转换与合并
合并以及处理模型需要几个项目支持,下面用到哪个就配置哪个。
4.1模型转换
这里需要transformers进行转换。这里先下载源码并配置环境
git clone https://github.com/huggingface/transformers
cd transformers
python setup.py instal
pip install sentencepiece
pip install peft
环境配置好,执行下面语句进行将原版LLaMA模型转换为HF格式
python transformers/src/transformers/models/llama/convert_llama_weights_to_hf.py --input_dir ./7B/ --model_size 7B --output_dir ./huggingface/
--input_dir:属于的7B模型路径
--model_size:模型大小类型,7B,13B...
--output_dir: 转换后输出的路径
4.2、把中文模型与原模型合并
这里需要使用Chinese-LLaMA-Alpaca。这里先下载源码并配置环境
git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca.git
cd Chinese-LLaMA-Alpaca
pip install -r requirements.txt
环境配置好使用下面语句进行合并
python Chinese-LLaMA-Alpaca/scripts/merge_llama_with_chinese_lora.py --base_model ./huggingface/ --lora_model ./chinese-alpaca-lora-7b/ --output_dir ./out
--base_model:输入的是上一步中转换的输出路径
--lora_model:输入的是中文模型的路径
--output_dir:是可并输出的路径
4.3 进行模型量化
这里要分成两步进行并使用llama.cpp项目,先下载源码进行编译
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp && make
- 1 这个先把合并的模型转换成gguf格式
创建文件目标 zh-models,将之前Chinese-LLaMA-Alpaca文件夹中的tokenizer.model放入其中,然后在zh-models中建立7B文件夹,将上面合并生成的consolidated.00.pth和params.json放入其中。目录如图

python llama.cpp/convert-pth-to-ggml.py zh-models/7B/ 1
这个convert-pth-to-ggml.py文件在新版本中被删除了,可以在以前分支找到或者使用下面的代码
# Compatibility stub
import argparse
import convert
parser = argparse.ArgumentParser(
description="""[DEPRECATED - use `convert.py` instead]
Convert a LLaMA model checkpoint to a ggml compatible file""")
parser.add_argument('dir_model', help='directory containing the model checkpoint')
parser.add_argument('ftype', help='file type (0: float32, 1: float16)', type=int, choices=[0, 1], default=1)
args = parser.parse_args()
convert.main(['--outtype', 'f16' if args.ftype == 1 else 'f32', '--', args.dir_model])
- 2 对FP16模型进行Q4量化
使用下面命令进行量化
./llama.cpp/quantize zh-models/7B/ggml-model-f16.gguf ./zh-models/7B/ggml-model-q4_0.bin 2
5、进行运行
./llama.cpp/main -m ./zh-models/7B/ggml-model-q4_0.bin -f ./llama.cpp/prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3
效果如图(当然模型太小准确率呵呵呵)

下面提供一个最终推理使用的模型
模型获取方式
关注晓理紫并回复llama获取模型
{晓理紫|小李子}喜分享,也很需要你的支持,喜欢留下痕迹哦!