1. 提出ECAPA-TDNN架构
TDNN本质上是1维卷积,而且常常是1维膨胀卷积,这样的一种结构非常注重context,也就是上下文信息,具体而言,是在frame-level的变换中,更多地利用相邻frame的信息,甚至跳过t − 1 , t + 1 的frame,而去对t − 2 , t + 2 的frame进行连接
在ECAPA-TDNN中,更是进一步利用了膨胀卷积,出现了 dilation=2,3,4的情况。此外,还引入了Res2Net,从而获得了多尺度的context,所谓多尺度,指的是各种大小的感受野
代码实现
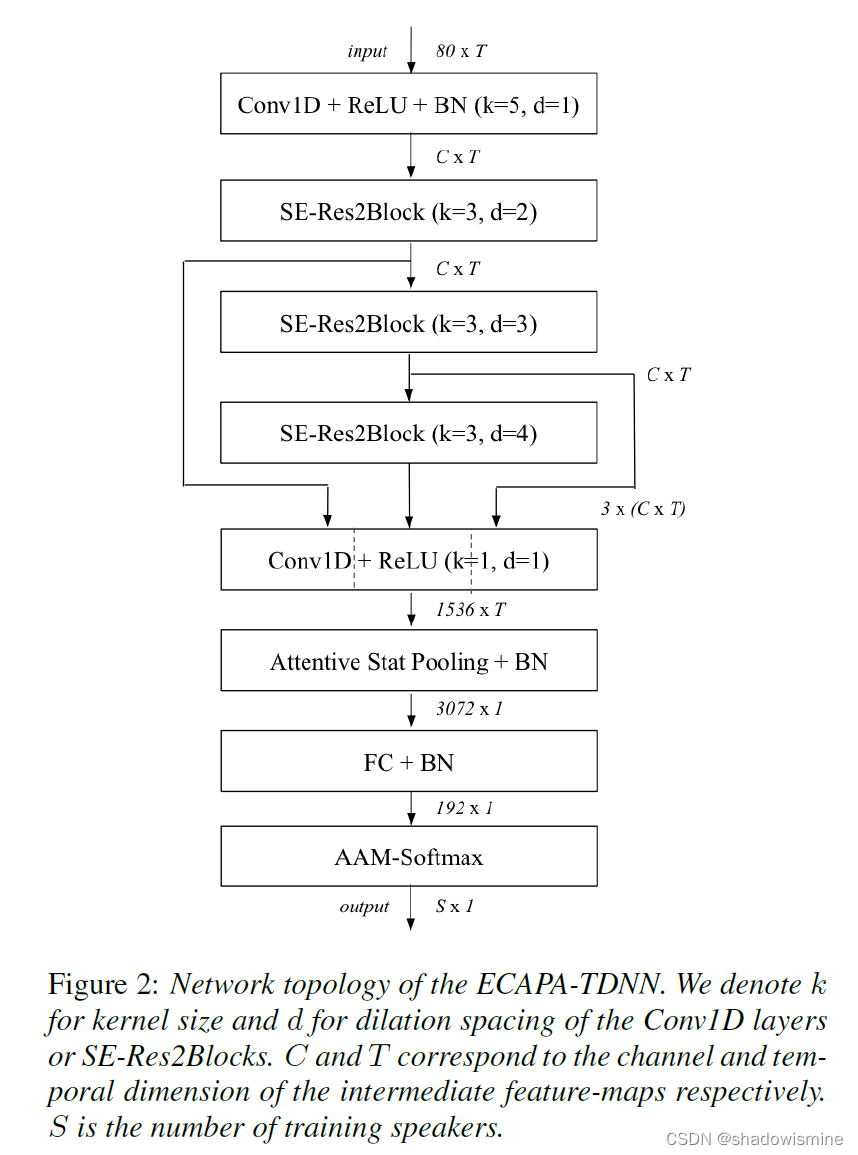
网络结构如下
- 数据增强
- TDNN block
- 多层特征聚合
- 注意力统计池化
- FC+BN
- 输出
def forward(self, x, aug):
#数据增强
with torch.no_grad():
x = self.torchfbank(x)+1e-6
x = x.log()
x = x - torch.mean(x, dim=-1, keepdim=True)
if aug == True:
x = self.specaug(x)
#相当于一个TDNN block
x = self.conv1(x)
x = self.relu(x)
x = self.bn1(x)
#多层特征聚合
x1 = self.layer1(x)
x2 = self.layer2(x+x1)
x3 = self.layer3(x+x1+x2)
x = self.layer4(torch.cat((x1,x2,x3),dim=1))
x = self.relu(x)
#注意力统计池化
t = x.size()[-1]
global_x = torch.cat((x,torch.mean(x,dim=2,keepdim=True).repeat(1,1,t), torch.sqrt(torch.var(x,dim=2,keepdim=True).clamp(min=1e-4)).repeat(1,1,t)), dim=1)
w = self.attention(global_x)
mu = torch.sum(x * w, dim=2)
sg = torch.sqrt( ( torch.sum((x**2) * w, dim=2) - mu**2 ).clamp(min=1e-4) )
x = torch.cat((mu,sg),1)
x = self.bn5(x)
x = self.fc6(x)
x = self.bn6(x)
return x
SpecAugment算法
SpecAugment算法是一种添加掩码的数据增强算法,步骤如下:
- 预加重:PreEmphasis(torch.nn.Module)
- 提取梅尔 torchaudio.transforms.MelSpectrogram(sample_rate=16000, n_fft=512, win_length=400, hop_length=160, f_min = 20, f_max = 7600, window_fn=torch.hamming_window, n_mels=80)
- 将梅尔进行零均值归一化,可以直接将Mask位置设为0
- 时间维度掩码
- 频率维度掩码
with torch.no_grad():
#预加重和提取梅尔
x = self.torchfbank(x)+1e-6
#对数梅尔
x = x.log()
x = x - torch.mean(x, dim=-1, keepdim=True)
if aug == True:
#添加掩码
x = self.specaug(x)
掩码部分主要代码:
1.获取梅尔的维度,分别赋值为batch, fea, time
batch为每批次输入梅尔的数量;
fea为每一个梅尔的特征维度,这里应该为80;
time为每一个梅尔的时间维度
2.掩码的长度:生成[batch, 1, 1]维数组
3.掩码的位置:生成[batch, 1 ,1]维数组,根据长度和梅尔的维度调整
4.生成一个D维张量,并将其增加维度至[1,1,D]
5.根据掩码长度和掩码位置得到掩码:[batch, 1 , D] ->[batch, D] ->[batch, 1 , D] or [batch, D, 1]
6.将梅尔掩码的地方赋值为0
def mask_along_axis(self, x, dim):
original_size = x.shape
batch, fea, time = x.shape
if dim == 1:
D = fea
width_range = self.freq_mask_width
else:
D = time
width_range = self.time_mask_width
mask_len = torch.randint(width_range[0], width_range[1], (batch, 1), device=x.device).unsqueeze(2)
mask_pos = torch.randint(0, max(1, D - mask_len.max()), (batch, 1), device=x.device).unsqueeze(2)
arange = torch.arange(D, device=x.device).view(1, 1, -1)
mask = (mask_pos <= arange) * (arange < (mask_pos + mask_len))
mask = mask.any(dim=1)
if dim == 1:
mask = mask.unsqueeze(2)
else:
mask = mask.unsqueeze(1)
#用0填充张量x中对应mask位置处为True的元素
x = x.masked_fill_(mask, 0.0)
return x.view(*original_size)
2. Channel- and context-dependent statistics pooling
多头注意力机制的成功展示了确定说话人的属性可以在不同的帧集上被提取出来,将时间注意力机制进一步扩展到通道维度是有益的。这使得网络能够更多的关注说话人的特征,而不是激活相同或者相似的时间实例,例如,说话人特有的元音属性与说话人特有的辅音属性。
我们将注意力机制调整为通道的:![]()
ht - 时间步长t时的最后一帧层的激活。
W和b - 自注意力的信息投影到一个更小的R维度表示中,该表示在所有C通道中共享,以减少参数计数和过拟合风险。![]()
在非线性层f(.)之后,这个信息通过权重vc和偏差kc的线性层转化为依赖通道的自注意力分数。
然后再所有帧上通过再信道上应用softmax函数将标量分数et,c归一化。
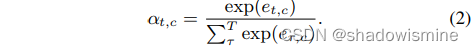
自注意力分数αt,c表示给定通道下每帧的重要性,用于计算通道c的加权统计量。对于每一个话语,加权平均向量μ的信道分量μc和加权标准差向量σ的通道分量σc估计为:
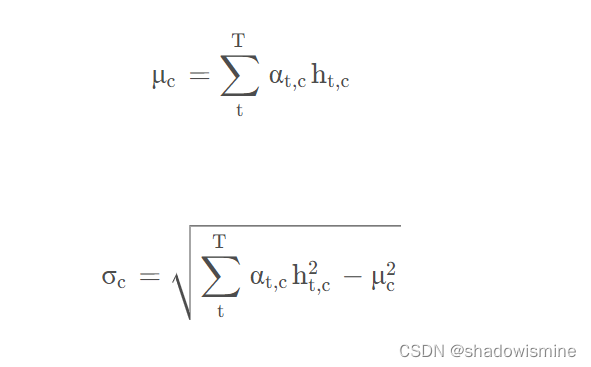
池化层的最终输出由加权平均μ和加权标准差σ的向量串联得到。
另外,通过允许自注意力观察话语的全局属性,我们扩展了池化层的时间上下文。我们将(1)中的局部输入ht与ht在时域的全局非加权平均值和标准偏差连接起来。这个上下文向量应该允许注意力机制适应话语的全局属性,如噪音或录音条件。
对比Statistic Pooling 和 Attentive Statistic Pooling如下图:
Statistic Pooling
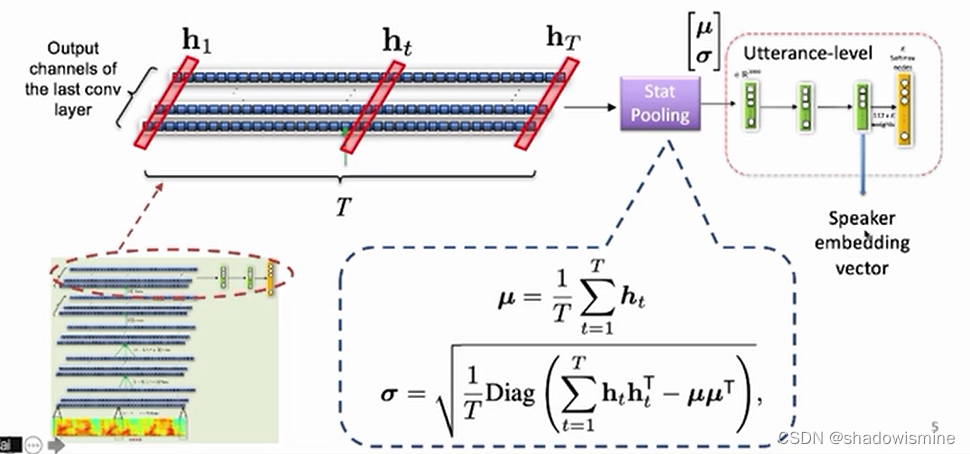
Attentive Statistics Pooling
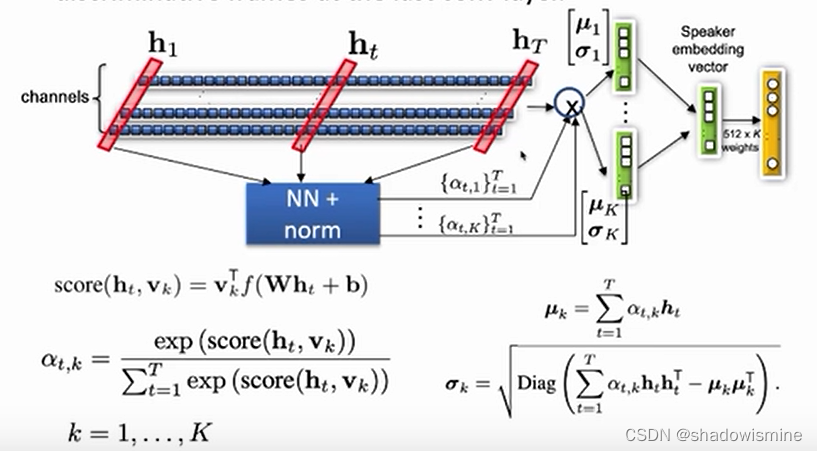
ECAPA-TDNN中对ASP进行了改进,首先将之前3个SE-Res2Block的输出,按照特征维度进行串联,假设frame-level变换中的特征维度是512,由于3个SE-Res2Block的输出维度都是 (bs,512,T),所以串联之后是(bs,512*3,T),之后经过一个CRB结构,输出维度固定为(bs,1536,T),即便frame-level的特征维度是1024,该CRB的输出维度也不变。如下图所示
对特征图(bs,1536,T),记为h,按照T维度计算每个特征维度的均值和标准差,从而T维度消失,得到的均值和标准差维度均为(bs,1536)
之后的操作很神奇,将均值在T维度重复堆叠T次,维度恢复为 (bs,1536,T),对标准差也是堆叠,维度恢复为(bs,1536,T),接着将特征图、均值和标准差在特征维度进行串联,得到的特征图维度为(bs,1536∗3,T),记为H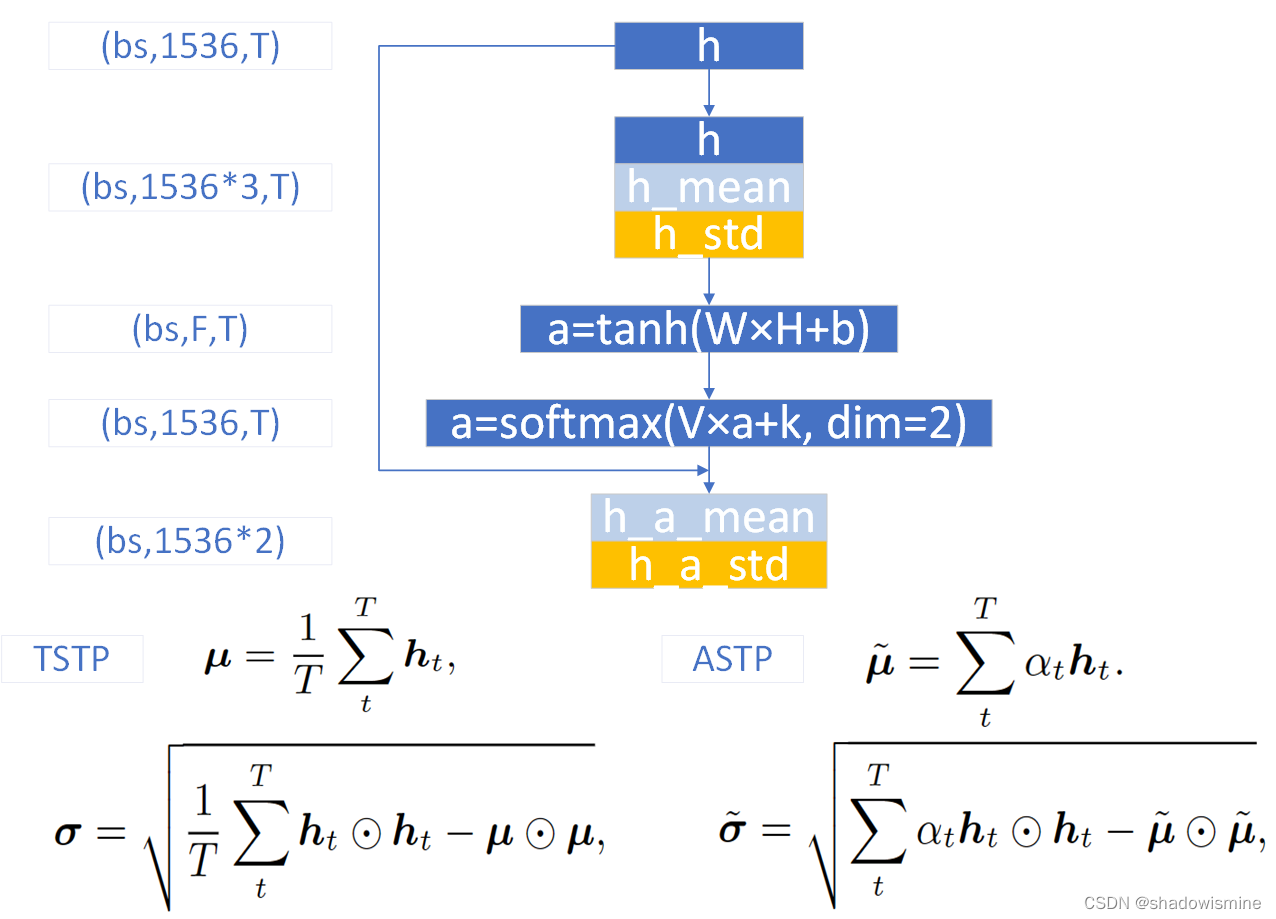
对H进行1维卷积,等价于上图的W × H + b ,目的是将每个frame的特征从1536*3维降维映射到F维,F可取128,然后经过tanh激活函数,得到特征图a,维度为(bs , F , T )
对a进行1维卷积,等价于上图的V × a + k,目的是将每个frame的特征从F维恢复映射到与h相同的维度,即1536,然后在T维度,进行softmax激活,得到特征图a,维度为(bs,1536,T)
此时的特征图a的每一行特征,在T维度上求和,都等于1,这是softmax激活的效果,又因为与h的维度相同,所以可以将a视为一种Attention分数,利用上图的ASTP公式,对h求基于Attention的均值和标准差,关于Attention分数,可以参考深入理解Self-attention(自注意力机制)
基于Attention的均值和标准差,维度都为(bs,1536),再将它们按照特征维度进行串联,得到ASP最终的输出,维度为 (bs,1536*2),在ECAPA-TDNN中,ASP之后还会接一个BN
torch.nn.BatchNorm1d(num-features,eps=1e−05,momentum=0.1,affine=True,track-running-stats=True,device=None,dtype=None)
BN中的num-features是理解BN的关键,对于图像任务,num-features要等于输入特征图的通道数,而对于音频任务,num-features要等于 (bs,F,T)中的F
也就是说,BN必然是作用于图像的特征图通道,或者音频中frame的每个特征的,num-features是告诉BN,均值和标准差,这两个向量的长度
BN计算均值和标准差的操作,与上述ASP的第一步,计算h_mean和h_std是类似的,不过计算的范围是在一个batch中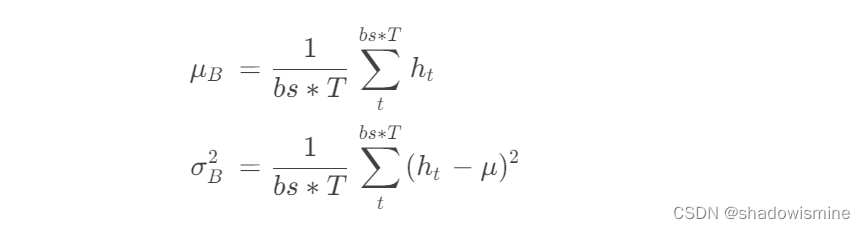
得到一个batch的统计量后,BN的输出也就确定了,不过需要先将μB 和σ^2B 重复堆叠成(bs,F,T)的大小,与输入BN的特征图H的维度相同,才能让其与H进行运算。在训练时,BN的输出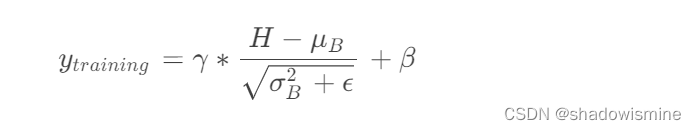
其中

此外,BN内部还有两个用于估计全局统计量的均值和标准差向量,在训练时,这两个向量根据每个batch的统计量进行更新,在测试时,BN会采用全局统计量对特征图进行规范化
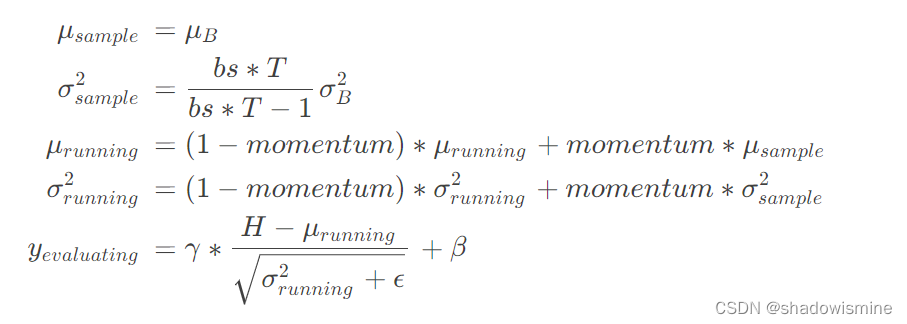
其中
下标running表示采用移动平均(running average)的方法对全局统计量进行估计
系数momentum是对当前batch的统计量的权重,可取0.1
实现代码如下:
# 得到时间帧
t = x.size()[-1]
# 获取时间帧维度的均值和标准差,然后串联原始数据
mean = torch.mean(x,dim=2,keepdim=True).repeat(1,1,t)
standrad = torch.sqrt(torch.var(x,dim=2,keepdim=True).clamp(min=1e-4)).repeat(1,1,t))
global_x = torch.cat((x, mean, standrad), dim=1)
#通过注意力网络得到注意力矩阵w
w = self.attention(global_x)
self.attention = nn.Sequential(
nn.Conv1d(4608, 256, kernel_size=1),
nn.ReLU(),
nn.BatchNorm1d(256),
nn.Tanh(), # I add this layer
nn.Conv1d(256, 1536, kernel_size=1),
nn.Softmax(dim=2),
)
mu = torch.sum(x * w, dim=2)
sg = torch.sqrt( ( torch.sum((x**2) * w, dim=2) - mu**2 ).clamp(min=1e-4) )
x = torch.cat((mu,sg),1)
3. 1-Dimensional Squeeze-Excitation Res2Blocks
Res2Net
- 经典的ResNet结构如下左图所示,先用kernel-size=1×1的卷积运算,相当于只针对每个像素点的特征通道进行变换,而不关注该像素点的任何邻近像素,并且是降低特征通道的,所以也被叫做Bottleneck,就好像将可乐从瓶口倒出来,如果是增加特征通道,那么就叫Inverted Bottleneck
- 1×1卷积后,会经过3 × 3 卷积,通常不改变特征通道,如果不需要在最后加上残差连接,那么stride=2,特征图的分辨率会被下采样,如果需要在最后加上残差连接,那么 stride=1,保持特征图分辨率不变。
- 最后还会有一个1 × 1卷积,目的是复原每个像素点的特征通道,使其等于输入时的特征通道,从而能够进行残差连接。整个Bottleneck block形似一个沙漏,中间是窄的(特征通道少),两边是宽的(特征通道多)
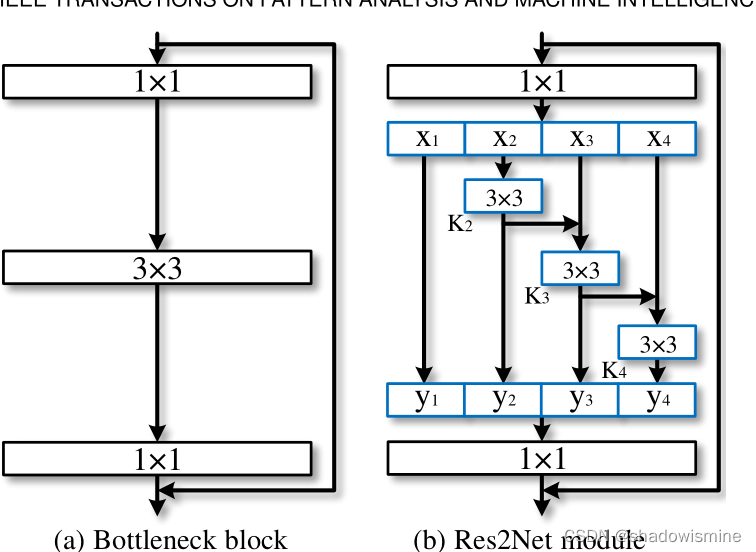
- 而Res2Net则是在中间的3 × 3 卷积进行的微创新,首先将1 × 1 卷积后的特征图,按照特征通道数进行平分,得到s c a l e 个相同的特征图(这里的scale是“尺度”的意思,Res2Net的作用就是多尺度特征,一语双关)
- 第一个特征图保留,不进行变换,这是对前一层特征的复用,同时也降低了参数量和计算量。从第二个特征图开始,都进行3 × 3 卷积,并且当前特征图的卷积结果,会与后一个特征图进行残差连接(逐元素相加),然后,后一个特征图再进行3 × 3 卷积
- 卷积中有一个概念叫感受野,是指当前特征图上的像素点,由之前某一个特征图在多大的分辨率下进行卷积得到的。如下图所示,dilation=1的3 × 3卷积,其输出特征图的每一个像素点的感受野都是3 × 3 ,再进行dilation=1的3 × 3卷积,其输出特征图的每一个像素点的感受野都是5 × 5
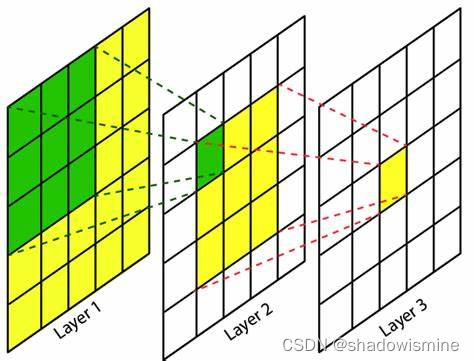
- 因此Res2Net中,第二个特征图的感受野为3 × 3 ,第三个特征图的感受野为5 × 5 + 3 × 3 ,第四个特征图的感受野为7 × 7 + 5 × 5 + 3 × 3 ,以此类推,从而得到多尺度特征
- 所有的卷积结果都会按照特征通道进行串联(concatenate),由于第一个特征图保留,不进行变换,所以后续的特征图维度必须与第一个特征图相同,因此3 × 3 卷积不改变特征通道和分辨率
- 最后的1 × 1 卷积,目的是复原每个像素点的特征通道,使其等于输入时的特征通道,从而能够进行残差连接
- Res2Net可以作为一个即插即用的结构,插入到现有的其他神经网络中,还可以与其他即插即用的结构一起工作,比如SENet和ResNeXt
SENet
SENet(Squeeze-and-Excitation Networks)是现代卷积神经网络所必备的结构,性能提升明显,计算量不大。基本思路是将一个特征图的每个特征通道,都映射成一个值(常用全局平均池化,即取该特征通道的均值,代表该通道),从而特征图会映射为一个向量,长度与特征通道数一致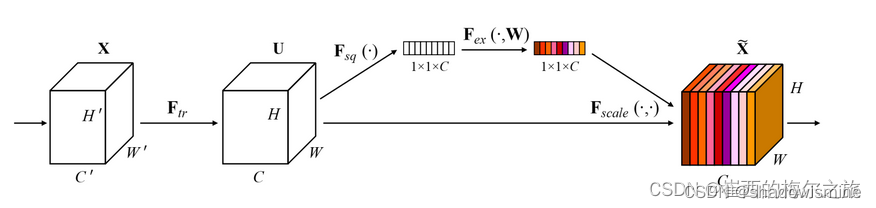
之后,对向量进行FC(用1维卷积也行,等价的),输出长度为特征通道数的1/r,然后经过激活函数ReLU,这个过程称为Squeeze(挤压);再进行FC,输出长度与特征通道数一致,然后经过激活函数Sigmoid,这个过程称为Excitation(激励);此时输出向量的每一个值,范围都是( 0 , 1 ) (0,1)(0,1),最后用输出向量的每一个值,对输入特征图的对应通道进行加权,这个过程称为Scale(伸缩)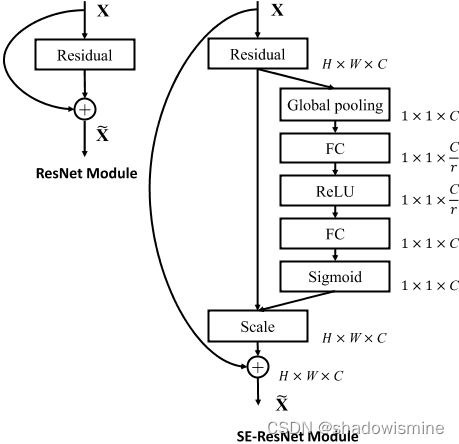
SENet的结构相当于对特征图的特征通道进行加权,因为每个特征通道的重要性是不一样的,所以让神经网络自行学习每个特征通道的权重,因此是一种Attention机制。并且输入特征图和输出特征图的维度完全一致,从而可以作为一个即插即用的结构,下面是Res2Net与SENet结合得到的结构,被称为SE-Res2Net。
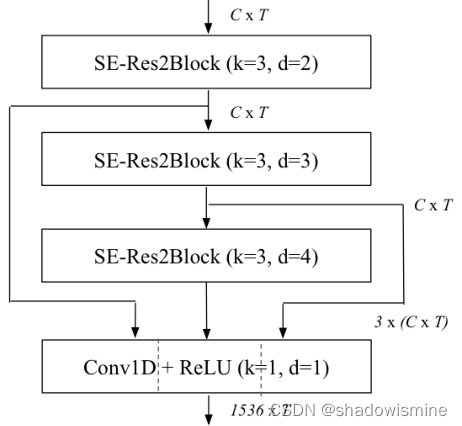
在ECAPA-TDNN中所用的Res2Net,是上述结构中的2维卷积全部换成1维卷积,采用的中间k = 3 卷积(1维卷积,不能用3 × 3 表示,以下都用k = 3 代替)为膨胀卷积,并且随着网络深度增加,dilation分别为2 , 3 , 4 。ECAPA-TDNN的结构图如下,SE-Res2Block后面括号内的参数,指的是Res2Block的中间k = 3卷积的参数。
SE block的第一个组成部分是压缩(squeeze)操作,为每一个通道生成一个描述符。压缩操作包括计算时间域的帧级特征的均值向量z:
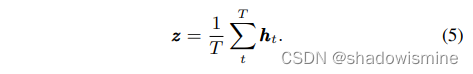
在激励操作中使用z中的描述符来计算每个通道的权重,我们定义后续的激励操作为
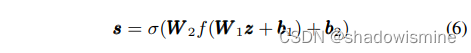
![]()
该操作作为bottleneck layer,C为输入通道数,R为降维数。得到的向量s包含介于0和1之间的权值sc,这些权值通过通道乘法作用于原始输入:
![]()
一维的SE-block可以以各种方式集成到x-vector中,在每次扩张卷积后使用它们是最直接的方法。但是,我们希望它们与残差连接的优点结合起来。
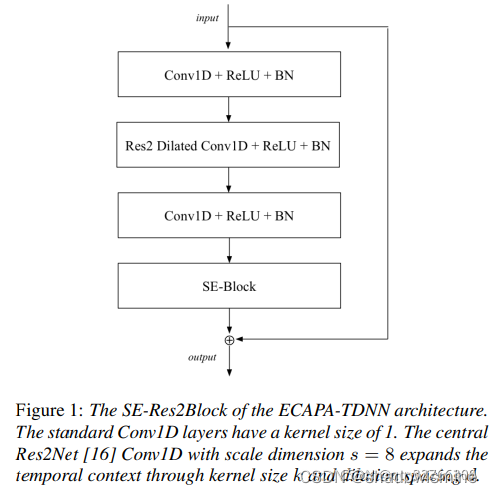
图1所示的SE-Res2Block包含了上面提到的需求。我们包含空洞卷积与前后密集层与上下文的一帧。第一个密集层用于降低特征维度,第二个密集层用于将特征数量恢复到原始维度。接下来是一个SE-block来缩放每一个通道,整个单元由一个跳跃连接覆盖。
代码实现
一维SE blocks,重新缩放帧级特征,得到通道的重要性。
过程为:
1.特征通过全局平均池化进行压缩
2.用两个全连接层,主要是为了应用relu和sigmoid(将输出映射至0和1)。第一个全连接层降低维度,第二个全连接层恢复维度。
3.输出为输入乘以权重矩阵。
def __init__(self, channels, bottleneck=128):
super(SEModule, self).__init__()
self.se = nn.Sequential(
#全局平均池化压缩为1个数
nn.AdaptiveAvgPool1d(1),
nn.Conv1d(channels, bottleneck, kernel_size=1, padding=0),
nn.ReLU(),
nn.Conv1d(bottleneck, channels, kernel_size=1, padding=0),
nn.Sigmoid(),
)
def forward(self, input):
#获得权重矩阵
x = self.se(input)
return input * x
res2net主要是利用细粒度的多尺度信息,产生多个感受野的组合。下面左图是res2net多尺度的具体做法,右图是本论文res2net模块的网络结构。
由左图可得,res2net将传统resnet中的3*3卷积进行了多尺度的解耦,在1 * 1卷积之后对通道进行分组,尺度越大计算开销越大。
由右图可知,包含了扩展卷积和前后密集层,第一个密集层用于降低维度,第二个密集层用于恢复维度,最后由SE模块缩放每一个通道。
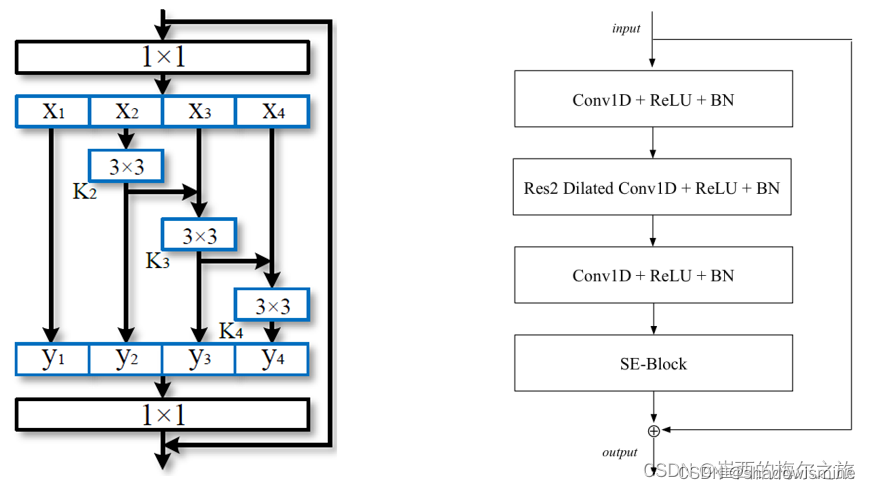
本文所用的res2net采用了8尺度,在代码中x1是作为最后一个直接送到。
def forward(self, x):
residual = x
#############################
out = self.conv1(x)
out = self.relu(out)
out = self.bn1(out)
#############################
#############################
#这里是res2net的核心
spx = torch.split(out, self.width, 1)
#分块卷积计算
for i in range(self.nums):
if i==0:
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
sp = self.relu(sp)
sp = self.bns[i](sp)
if i==0:
out = sp
else:
out = torch.cat((out, sp), 1)
#cat x1的块
out = torch.cat((out, spx[self.nums]),1)
###############################
###############################
out = self.conv3(out)
out = self.relu(out)
out = self.bn3(out)
###############################
out = self.se(out)
out += residual
return out
4. Multi-layer feature aggregation and summation
原始的x-vector系统只使用最后一帧层的特征图来计算合并的统计量。鉴于TDNN的层次性质,这些更深层次的特征是最复杂的,应该与说话人的身份密切相关。然而,由于[17,18]中的证据,我们认为,更浅的特征图也可以有助于更稳健的说话人嵌入码。对于每一帧,我们提出的系统将所有SE-Res2Blocks的输出特征映射连接起来。在多层特征聚合(MFA)之后,密集层处理连接的信息,生成关注统计池的特征。
另一种利用多层信息的互补方法是使用前面所有SE-Res2Blocks的输出和初始卷积层作为每个帧层块的输入。我们通过将每个SE-Res2Block中的剩余连接定义为前面所有块输出的和来实现这一点。我们选择特征映射的总和而不是连接来限制模型参数计数。没有累加剩余连接的最终架构如图2所示。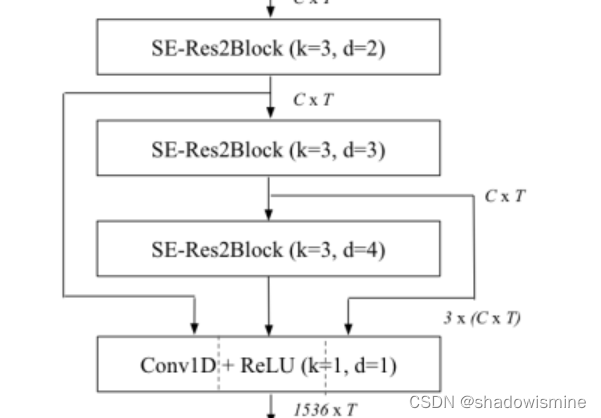
MFA是多层特征聚合,将SE Res2Blocks输出特征映射连接起来
整体代码
x1 = self.layer1(x)
x2 = self.layer2(x+x1)
x3 = self.layer3(x+x1+x2)
x = self.layer4(torch.cat((x1,x2,x3),dim=1))
x = self.relu(x)
5. 损失函数(AAMsoftmax(loss.py))
原理:最大化类间间距,最小化类内间距。
softmax loss在决策边界产生明显的模糊性,但是AAMsoftmax通过添加加性角度边距可以扩大类间的间隙。
1. 归一化输入特征和FC层权重。令所得归一化特征x_{i} 与第j类别的FC层权重点乘得到FC层的第j个输出cosθ_{j} ,将特征x_{i} 预测为第j类的预测值。
cosine = F.linear(F.normalize(x), F.normalize(self.weight))
2. 根据正余弦公式计算sinθ_{j}
sine = torch.sqrt((1.0 - torch.mul(cosine, cosine)).clamp(0, 1))
3. 根据当前夹角的正余弦,计算添加了加性角度边距m的cos(θ+m)
phi = cosine * self.cos_m - sine * self.sin_m
4. 松弛约束
phi = torch.where((cosine - self.th) > 0, phi, cosine - self.mm)
5. 生成矩阵标签
one_hot = torch.zeros_like(cosine) #全0矩阵
one_hot.scatter_(1, label.view(-1, 1), 1) #在label索引上用1替换0
6. 当输入特征x对应真实类别,采用新 Target Logit cos(θ_yi + m), 其余并不对应输入特征x的真实类别的类,保持原有的logit
output = (one_hot * phi) + ((1.0 - one_hot) * cosine)
7. 使用scale缩放新的logit
output = output * self.s
8.计算损失
loss = self.ce(output, label)
self.ce = nn.CrossEntropyLoss()
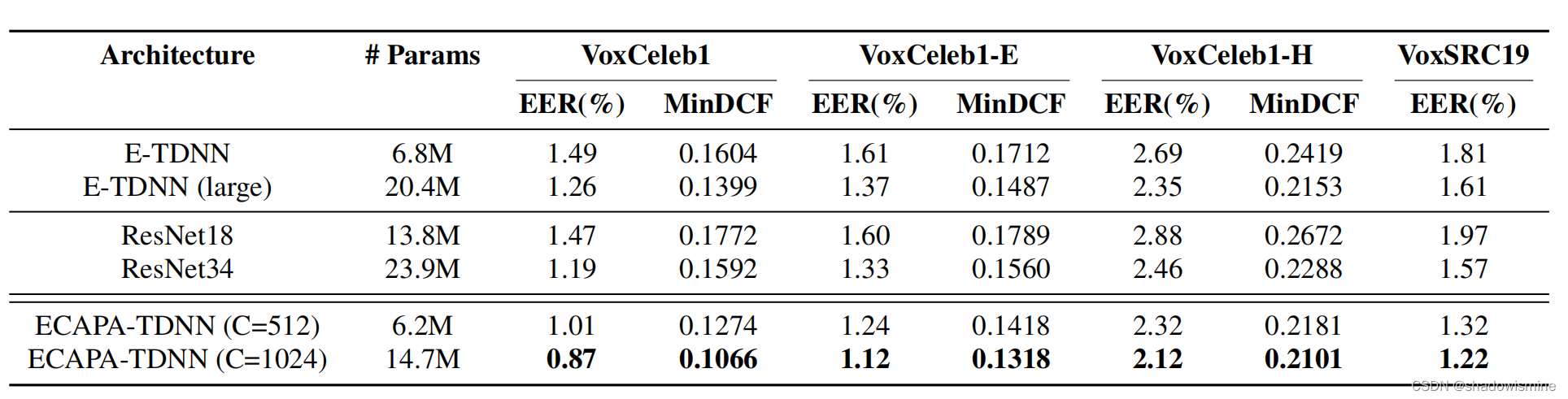
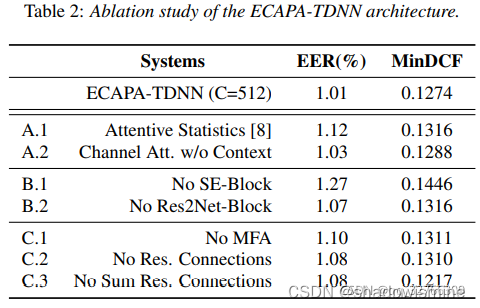
6. 模型评估
原文链接:https://blog.csdn.net/qq_32766309/article/details/121359110