💖作者:小树苗渴望变成参天大树🎈
🎉作者宣言:认真写好每一篇博客💤
🎊作者gitee:gitee✨
💞作者专栏:C语言,数据结构初阶,Linux,C++ 动态规划算法🎄
如 果 你 喜 欢 作 者 的 文 章 ,就 给 作 者 点 点 关 注 吧!

文章目录
- 前言
- 一、为什么会设计出lambda表达式
- 二、lambda表示的详解
- 2.1lambda的使用
- 2.2再次理解lambda和函数对象
- 三、可变模板参数
- 四、包装类
- 五、总结
前言
今晚我们再来讲解c++11的知识点,上篇我们讲解到最关键的一个知识点就是右值引用,他可以提高性能,今天我们也会学到这个提高性能的东西,可变模板参数,再次之前我们要讲一个轻量化的知识点就是lambda表达式,他是让看上去比较沉重的仿函数变的轻量化,他是一个用起来比较方便但是语法优点奇葩的知识点,看上去非常不c++,最后我们再讲解一下包装类。话不多说,我们开始进入正文的讲解
一、为什么会设计出lambda表达式
再之前我们的仿函数大多数场景都是出现再比较大小上的,一般都是设计排序相关的操作需要这样设计,搜索树的插入实际也是再排序,优先级队列都是类似的操作,一般的我们的排序都不是对整型进行排序,现实中这样排序是没有意义的,所以我们一般都是对一个对象里面的某一个属性排序,从而知道另一个属性,就好比高考,我们是对分数进行排序,但是我们更想知道分数最高对应的是谁,所以通过上面的说明,我们来写一个示例代码:
#include<vector>
#include<algorithm>
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
struct CompareNameGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
struct CompareNameLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._name < gr._name;
}
};
struct CompareEvaluateGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
struct CompareEvaluateLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._evaluate< gr._evaluate;
}
};
struct CompareEvaluateGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._evaluate > gr._evaluate;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), ComparePriceLess());
sort(v.begin(), v.end(), ComparePriceGreater());
sort(v.begin(), v.end(), CompareNameLess());
sort(v.begin(), v.end(), CompareNameGreater());
sort(v.begin(), v.end(), CompareEvaluateLess());
sort(v.begin(), v.end(), CompareEvaluateGreater());
}
我们总会有上面的需求,对商品不同的属性进行比较,上面则需要写六个类似的仿函数,这样就使得仿函数看上去太沉重了,所以为了解决这样的问题我们引入了lambda表达式,这个原先不是C++自己搞出来的,也是抄袭别人的,但是这东西确实好用,所以通过上面的案例,我先浅浅的带大家入门一下,看看lambda表达式时怎样解决这个问题的。
用法: (1)捕捉列表。(2)参数列表。(3)返回值。(4)函数体
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), [](Goods& g1, Goods& g2)->bool {return g1._price < g2._price; });
sort(v.begin(), v.end(), [](Goods& g1, Goods& g2)->bool {return g1._price > g2._price; });
sort(v.begin(), v.end(), [](Goods& g1, Goods& g2)->bool {return g1._name < g2._name; });
sort(v.begin(), v.end(), [](Goods& g1, Goods& g2)->bool {return g1._name > g2._name; });
sort(v.begin(), v.end(), [](Goods& g1, Goods& g2)->bool {return g1._evaluate < g2._evaluate; });
sort(v.begin(), v.end(), [](Goods& g1, Goods& g2)->bool {return g1._evaluate > g2._evaluate; });
}
使用上面的操作就可以省去许多类似的仿函数,这样就轻量化了不少。这也就是为什么会设计出lambda表达式的原因,其实lambda表达式就是一个类,是一个类对象,和仿函数是一样的,这个一会再详细介绍。
二、lambda表示的详解
2.1lambda的使用
上面我们大致看到lambda表达式的简单使用,但是我们还是不明白怎么使用的,所以接下来我将一步步的介绍。
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement }
-
lambda表达式各部分说明:
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来
判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda
函数使用。 -
(parameters): 参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以
连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量
性。使用该修饰符时,参数列表不可省略(即使参数为空)。 -
->returntype: 返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回
值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推
导。 -
{statement}: 函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获
到的变量。
注意:
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为
空。因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情。
通过上面的说明我们的lambda类似于一个匿名的函数。函数体,参数列表,返回值,只是多了一个捕捉列表,后面可以理解这个捕捉列表可以接收参数列表接收不了的参数。
示例一:可以省去返回值
int a = 0; int b = 2;
//返回值可写可不写,大部分都不写,编译器会推导返回类型的。这个返回值的类型不是f1的类型,前面铺垫过lambda表达式是一个类对象,一会介绍。
auto f1 = [](int a, int b)->int {return a + b; };
auto f2 = [](int a, int b) {return a + b; };
cout << f1(a, b) << endl;//类似于函数调用
示例二:函数体有多个语句
auto swap1 = [](int& x, int& y) {
int tmp = x;
x = y;
y = tmp;
};
swap1(a, b);
//去调用示例一的lambda。会报错,采用捕捉列表
auto swap1 = [](int& x, int& y) {
int tmp = x;
x = y;
y = tmp;
cout << f1(a, b) << endl;
};
swap1(a, b);
不带引用是错误的,因为这和函数传参一样的,是值拷贝。
捕捉列表:
(1)[var]:表示值传递方式捕捉变量var
int a = 0; int b = 2;
auto f3 = [a](int b) {return a + b; };//捕捉到a
f3(a);
auto f4 = [a,b]() {return a + b; };//把a,b都捕捉到
f4();
auto f5 = [a,b]{return a + b; };//参数列表没有就可以省略
f5();
//解决示例二的问题:捕捉到f1,因为f1没有办法通过参数列表获得
auto swap1 = [f1](int& x, int& y) {
int tmp = x;
x = y;
y = tmp;
cout << f1(a, b) << endl;
};
(2)[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
int a = 0; int b = 2;
auto f5 = [=]{return a + b; };//捕捉到a,b所以的
f5();
auto f6 = [=]{a++;b++};//我们通过传值的方式会导致变成const属性,所以不能进行修改
f6();
auto f6 = [=]()mutable{a++;b++};//加mutable就可以使得const变成可以修改的了,注意此时的参数列表就不可以省略。
f6();
auto f7 = [=,&b]()mutable{a++;b++; };//捕捉所有的,值传递,除了b是引用传递
f7();
//此时a=1,b=3;,mutable虽然改变了const属性,但还是值传递,内部修改不影响外部,b是传引用,会影响到外部
(3)[&]||[&var]:表示引用传递捕捉变量var
这个设计很奇葩,对象前面的&一般都是取地址,再这里是引用。
auto f8 = [&a,&b](){a++;b++; };//引用捕捉
f8();
auto f9 = [&]{a++;b++; };//引用捕捉所以的。
f9();
auto f10 = [&,b]()mutable{a++;b++; };//引用捕捉所以的,除了b是值传递,是值传递就是const属性,想要修改就要使用mutable
f10();
通过一开始案例以及上面的案例可以看出,lambda表达式实际上可以理解为无名函数,该函数无法直接调用,如果想要直接调用,可借助auto将其赋值给一个变量。
总结:
注意:
-
父作用域指包含lambda函数的语句块
-
语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量 -
捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复 -
在块作用域以外的lambda函数捕捉列表必须为空。
-
在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者
非局部变量都
会导致编译报错。
2.2再次理解lambda和函数对象
函数对象,又称为仿函数,即可以想函数一样使用的对象,就是在类中重载了operator()运算符的
类对象。
我们来看一个示例:
auto f1 = [](int x, int y) {return x + y; };
auto f2 = [](int x, int y) {return x + y; };
f1 = f2;
这样是不能赋值的,我们看上去是一样的,我们来把类型打印一下看看。

我们这两个都不是一个类型的。原因就是这是不同的类对象,所以类型不一样,后面的是uuid大家可以上网搜索一下,这是一个算法使得每次生成的码都不一样,这样就保证了,类名是不一样的,同一个工程是不能出现同名类的。
我们来写一个代码,让lambda表达式和函数对象对比,看看反汇编:
class Rate
{
public:
Rate(double rate) : _rate(rate)
{}
double operator()(double money, int year)
{
return money * _rate * year;
}
private:
double _rate;
};
int main()
{
// 函数对象
double rate = 0.49;
Rate r1(rate);
r1(10000, 2);
// lambda
auto r2 = [=](double monty, int year)->double {return monty * rate * year; };
r2(10000, 2);
return 0;
}
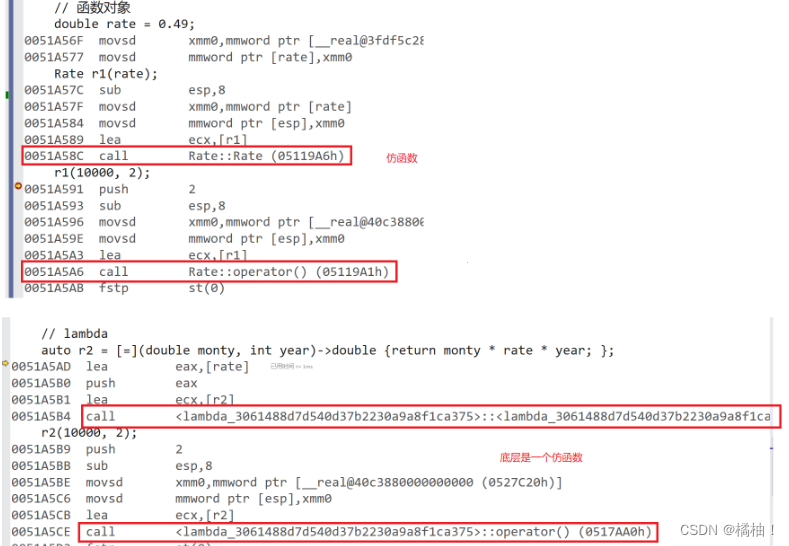
其实lambda和范围for一样,看着很神奇,其实就是底层偷偷调用了仿函数和迭代器。
如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
三、可变模板参数
这个涉及到包装类,所以要提前讲,这个知识点也是一个不太好理解的。
我们接触最早的可变模板参数在哪??是在printf和scanf这个函数中

还有我们最近说的emplace
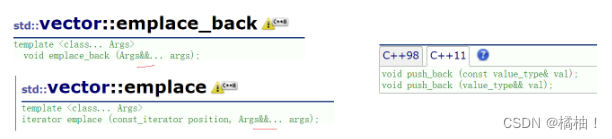
这个可变模板参数也会进一步的提高性能。
C++11的新特性可变参数模板能够让您创建可以接受可变参数的函数模板和类模板,相比
C++98/03,类模版和函数模版中只能含固定数量的模版参数,可变模版参数无疑是一个巨大的改
进。然而由于可变模版参数比较抽象,使用起来需要一定的技巧,所以这块还是比较晦涩的。现
阶段呢,我们掌握一些基础的可变参数模板特性就够我们用了,所以这里我们点到为止,以后大
家如果有需要,再可以深入学习。
下面就是一个基本可变参数的函数模板:
// Args是一个模板参数包,args是一个函数形参参数包
// 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。
template <class ...Args>
void ShowList(Args... args)
{}
上面的参数args前面有省略号,所以它就是一个可变模版参数,我们把带省略号的参数称为“参数
包”,它里面包含了0到N(N>=0)个模版参数。我们无法直接获取参数包args中的每个参数的,
只能通过展开参数包的方式来获取参数包中的每个参数,这是使用可变模版参数的一个主要特
点,也是最大的难点,即如何展开可变模版参数。由于语法不支持使用args[i]这样方式获取可变
参数,所以我们的用一些奇招来一一获取参数包的值
递归函数方式展开参数包
template<class ...args>
void showlist(args... args)
{
cout << sizeof...(args) << endl;
// 不支持这样写
for (size_t i = 0; i < sizeof...(args); i++)
{
cout << args[i] << endl;
}
}
所以我们必须使用下面的方式去获取参数包里面的值:
template<class T>
void _ShowList(T&val)//结束条件函数
{
cout << val << " ";
cout << endl;
}
template <class T, class ...Args>
void _ShowList(T val, Args... args)
{
cout << val << " ";
_ShowList(args...);
}
//args代表0-N的参数包
template <class ...Args>
void CppPrint(Args... args)
{
_ShowList(args...);
}
//参数包里面可以有不同的类型的参数
int main()
{
CppPrint(1);
CppPrint(1, 2);
CppPrint(1, 2, 2.2);
CppPrint(1, 2, 2.2, string("xxxx"));
return 0;
}

大家可以自己画递归展开图来分析怎么去实现的,是把包一层层的王下面传,这个也为后面介绍emplace这个接口做铺垫。
上面哪个至少要传一个参数,如果不传参数,就需要把结束条件函数改成下面的:
void _ShowList()
{
cout << endl;
}
逗号表达式展开参数包
这种展开参数包的方式,不需要通过递归终止函数,是直接在expand函数体中展开的, printarg
不是一个递归终止函数,只是一个处理参数包中每一个参数的函数。这种就地展开参数包的方式
实现的关键是逗号表达式。我们知道逗号表达式会按顺序执行逗号前面的表达式。
expand函数中的逗号表达式:(printarg(args), 0),也是按照这个执行顺序,先执行printarg(args),再得到逗号表达式的结果0。同时还用到了C++11的另外一个特性——初始化列表,通过初始化列表来初始化一个变长数组, {(printarg(args), 0)…}将会展开成((printarg(arg1),0), (printarg(arg2),0), (printarg(arg3),0), etc… ),最终会创建一个元素值都为0的数组int arr[sizeof…(Args)]。由于是逗号表达式,在创建数组的过程中会先执行逗号表达式前面的部分printarg(args)、打印出参数,也就是说在构造int数组的过程中就将参数包展开了,这个数组的目的纯粹是为了在数组构造的过程展开参数包
template <class T>
void PrintArg(T t)
{
cout << t << " ";
}
//展开函数
template <class ...Args>
void ShowList(Args... args)
{
int arr[] = { (PrintArg(args), 0)... };
cout << endl;
}
int main()
{
ShowList(1);
ShowList(1, 'A');
ShowList(1, 'A', std::string("sort"));
return 0;
}
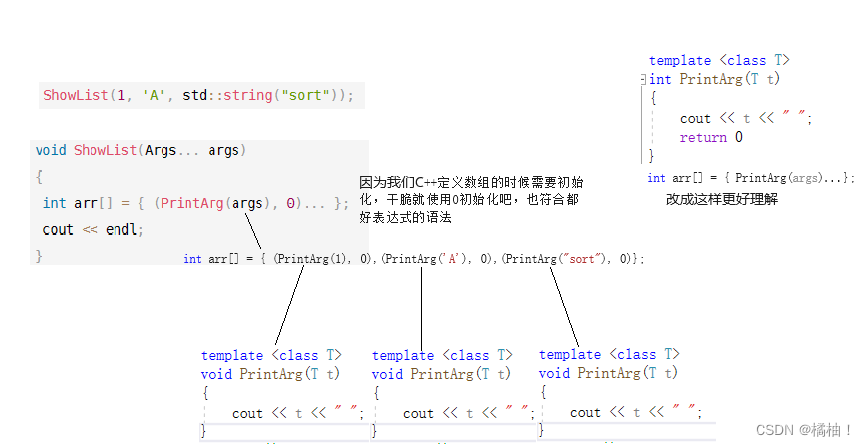
我们发现上面的函数都是通过一个函数一个个的取出来,但是我们的可变模板参数真正的用法再下面:
class Date
{
public:
Date(int year = 1, int month = 1, int day = 1)
:_year(year)
,_month(month)
,_day(day)
{
cout << "Date构造" << endl;
}
Date(const Date& d)
:_year(d._year)
, _month(d._month)
, _day(d._day)
{
cout << "Date拷贝构造" << endl;
}
private:
int _year;
int _month;
int _day;
};
template <class ...Args>
Date* Create(Args... args)
{
Date* ret = new Date(args...);
return ret;
}
int main()
{
//这个是直接把参数包带到Date的构造函数中进行构造
Date* p1 = Create();
Date* p2 = Create(2023);
Date* p3 = Create(2023, 9);
Date* p4 = Create(2023, 9, 27);
Date d(2023, 1, 1);
//这个是直接把d对象当成一个参数包传到Date的拷贝构造。
Date* p5 = Create(d);
return 0;
}
这个对下面的知识点非常重要,他可以对比push_back和emplace_back的区别,因为emplace_back就是接收可变模板参数,他是一层层的把参数包王下面传,减少了拷贝构造或者构造。接下来我们来看操作:
int main()
{
std::list<std::pair<int, char>> mylist;
// emplace_back支持可变参数,拿到构建pair对象的参数后自己去创建对象
// 那么在这里我们可以看到除了用法上,和push_back没什么太大的区别
mylist.emplace_back(10, 'a');
mylist.emplace_back(20, 'b');
//上面两个都是通过可变模板参数,参数包一层层的往下面传调用构造函数创建结点对象的
//下面这个是调用了拷贝构造去创建结点的对象的,都是值拷贝,和push_back差不多
mylist.emplace_back(make_pair(30, 'c'));
//而下面这个是通过右值引用,传进去的,最后一个是生成临时对象也是会有右值引用的那个插入函数的,所以最后都会调用拷贝构造,都是值拷贝,所以和emplace_back差不多
mylist.push_back(make_pair(40, 'd'));
mylist.push_back({ 50, 'e' });
return 0;
}
我们来看下面的例子:
int main()
{
// 下面我们试一下带有拷贝构造和移动构造的xdh::string,再试试呢
// 我们会发现其实差别也不到,emplace_back是直接构造了,push_back
// 是先构造,再移动构造,其实也还好。
std::list< std::pair<int, xdh::string> > mylist;
mylist.emplace_back(10, "sort");
mylist.push_back(make_pair(30, "sort"));
return 0;
}

我们看到和我们分析的一模一样,对于深拷贝,我觉得性能也没有提高多少,就是因为移动构造的代价太小了,就是交换了一下指针。
反而对于内置类型的类,性能提高不少

原因是只有内置类型的类,当内置类型比较多,类就比较大,少一个拷贝构造就相当于节省一半性能。这里面的移动构造和拷贝构造是一样的效果,都是按字节拷贝
四、包装类
function包装器 也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。
那么我们来看看,我们为什么需要function呢?
// 上面func可能是什么呢?那么func可能是函数名?函数指针?函数对象(仿函数对象)?也有可能
是lamber表达式对象?所以这些都是可调用的类型!如此丰富的类型,可能会导致模板的效率低下!
为什么呢?我们继续往下看
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i)//函数指针
{
return i / 2;
}
struct Functor//仿函数
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{
// 函数名
cout << useF(f, 11.11) << endl;
// 函数对象
cout << useF(Functor(), 11.11) << endl;
// lamber表达式
cout << useF([](double d)->double{ return d/4; }, 11.11) << endl;
return 0;
}
不同的类型就会实例化不同的函数,这也是函数模板的特点,如果是实例化出一个函数,静态变量count应该是3,因为调用了三次,我们来看看结果:

包装器的作用就是讲这三者类型统一起来,原因是可调用的对象也就是这三种,我们统一类型最重要的目的是再容器里面传类型,一会详细介绍。
包装器的用法
std::function在头文件<functional>
// 类模板原型如下
template <class T> function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;
//模板参数说明:
//Ret: 被调用函数的返回类型
//Args…:被调用函数的形参
//包装器 – 可调用对象的类型问题
function<double(double)> f1 = f;
function<double(double)> f2 = [](double d)->double { return d / 4; };
function<double(double)> f3 = Functor();

我们看到类型统一了,这样去调用一个模板函数就会实例化出一份函数,解决了性能问题,我们要知道可调用对象是一个大类,可以统一类型的,但是需要包装器去实现,不然就是不同的类型
可调用对象存储到容器中
vector<function<double(double)>> v = { f, [](double d)->double { return d / 4; }, Functor() };
double n = 3.3;
for (auto f : v)
{
cout << f(n++) << endl;
}

来看看使用包装器后最上面的代码有没有被实例化成一份:
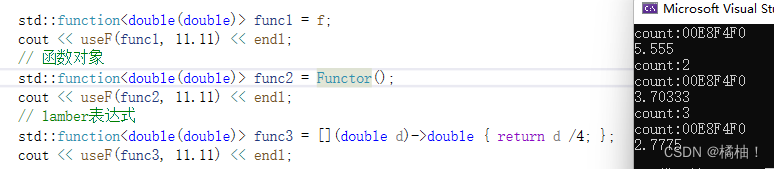
我们的包装器解决了问题,但是包装器的用法可不止在这。
我们来看看这种用法的示例:
150. 逆波兰表达式求值

原来的做法:
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> s;
for(int i=0;i<tokens.size();i++)
{
string& str=tokens[i];
if(!(str=="+"||str=="-"||str=="*"||str=="/"))
{
s.push(stoi(str));//操作数就入栈
}
else//操作符,操作数先出右再出左
{
int right=s.top();
s.pop();
int left=s.top();
s.pop();
switch(str[0])//运算后再入栈
{
case '+':
s.push(left+right);
break;
case '-':
s.push(left-right);
break;
case '*':
s.push(left*right);
break;
case '/':
s.push(left/right);//无除数为0的情况
break;
}
}
}
return s.top();
}
};
使用包装器后的做法:
class Solution {
public:
int evalRPN(vector<string>& tokens) {
map<string,function<double(int,int)>> ofmap={
{"+",[](int a,int b){return a+b;}},
{"-",[](int a,int b){return a-b;}},
{"*",[](int a,int b){return a*b;}},
{"/",[](int a,int b){return a/b;}},
};
stack<int> s;
for(auto &f:tokens)
{
if(ofmap.count(f))//操作符,先出左在出右
{
int right=s.top();
s.pop();
int left=s.top();
s.pop();
s.push(ofmap[f](left,right));
}
else/
{
s.push(stoi(f));//操作树就入栈
}
}
return s.top();
}
};
不管后来有多少操作符,在map里面添加就行了。
bind
对于包装器还有一个知识点没讲,就是绑定。
std::bind函数定义在头文件中,是一个函数模板,它就像一个函数包装器(适配器),接受一个可
调用对象(callable object),生成一个新的可调用对象来“适应”原对象的参数列表。一般而
言,我们用它可以把一个原本接收N个参数的函数fn,通过绑定一些参数,返回一个接收M个(M
可以大于N,但这么做没什么意义)参数的新函数。同时,使用std::bind函数还可以实现参数顺
序调整等操作。
// 原型如下:
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
// with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
可以将bind函数看作是一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对
象来“适应”原对象的参数列表。
调用bind的一般形式:auto newCallable = bind(callable,arg_list);
其中,newCallable本身是一个可调用对象,arg_list是一个逗号分隔的参数列表,对应给定的
callable的参数。当我们调用newCallable时,newCallable会调用callable,并传给它arg_list中
的参数。
arg_list中的参数可能包含形如_n的名字,其中n是一个整数,这些参数是“占位符”,表示
newCallable的参数,它们占据了传递给newCallable的参数的“位置”。数值n表示生成的可调用对
象中参数的位置:_1为newCallable的第一个参数,_2为第二个参数,以此类推。
我们来看示例:
::后面的是本身函数参数的位置,最左边就是第一个,以此类推。最多好像100左右
场景一:
交换传参顺序
int Sub(int a, int b)
{
return a - b;
}
function<int(int, int)> rSub = bind(Sub, placeholders::_1, placeholders::_2);
cout << rSub(10, 5) << endl;
function<int(int, int)> rSub = bind(Sub, placeholders::_2, placeholders::_1);
cout << rSub(10, 5) << endl;

大家可能会想为什么要这样设计,因为我们以后写项目调用的可能是同时的接口,也可能是线程库的接口,他的优先传参设计就不是那么顺心,这时候就需要自己去调整传参顺序,这个bind可以很灵活的做这样的事情。
场景二:
我们的函数总有一个固定值,但是我们不像传进来,怎么做。
double Plus(int a, int b, double rate)
{
return (a + b) * rate;
}
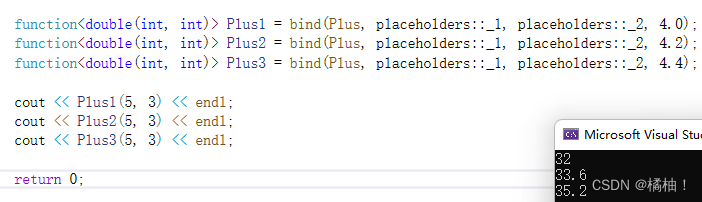
如果固定值在中间呢??
double PPlus(int a, double rate, int b)
{
return rate*(a + b);
}

我们的固定值显示传了以后,就不算作参与参数个数了,所以::后面是_1和_2,不是_1和_3,这个大家要记住
为什么会有这样的场景,我们来看一下:
我们总会有场景需要这样进行设计,传固定值,这样就不会多传参了。
场景三:
我们类里面的函数怎么去绑定呢??
(1)静态成员函数
class SubType
{
public:
static int sub(int a, int b)
{
return a - b;
}
};
function<double(int, int)> Sub1 = bind(SubType::sub, placeholders::_1, placeholders::_2);//通过类名去调用
cout << Sub1(1, 2) << endl;
(2)普通函数呢??
class SubType
{
public:
int ssub(int a, int b, int rate)
{
return (a - b)*rate;
}
};
SubType st;
function<double(int, int)> Sub2 = bind(&SubType::ssub, &st, placeholders::_1, placeholders::_2, 3);
cout << Sub2(1, 2) << endl;
function<double(int, int)> Sub3 = bind(&SubType::ssub, SubType(), placeholders::_1, placeholders::_2, 3);
cout << Sub3(1, 2) << endl;
我们普通对象调用的是有隐藏的this指针,所以需要创建对象传过去,也可以传匿名对象
为什么即可以对象也可以传指针?
原因是底层都是仿函数,一个通过指针调用,一个通过对象调用。都是调用operator().
五、总结
到这里我们的C++11中篇知识点就讲解完成了,尤其C++11出了好多很不C++的用法,所以在使用上面可能没有之前好理解,但是没有关系,后面多看看,知道有这些东西,到时候知道用迷失在不知道在查查文档也就会了,现在大家可能用不到,但是总有用到的时候,所以还是希望大家去学习一下,博主也在认真的学,虽然不好理解,但是也没有办法,吃的苦中苦,方为人上人,我们下篇关于只能指针的介绍,希望各位友友们来支持博主。








![进程概念[上]](https://img-blog.csdnimg.cn/3c5a41cdf100434fabc6964087e110ee.png)