开发Flink程序过程与Flink常见数据类型
- DataStream API
- Flink三层API
- DataStream API概述
- 开发Flink程序过程
- 添加依赖
- 创建执行环境
- 执行模式
- 创建Data Source
- 应用转换算子
- 创建Data Sink
- 触发程序执行
- 示例
- Flink常见数据类型
- 基本数据类型
- 字符串类型
- 时间和日期类型
- 数组类型
- 元组类型
- 列表类型
- 映射类型
- POJO类型
- Row类型
- 可序列化类型
- 类型提示
DataStream API
Flink三层API
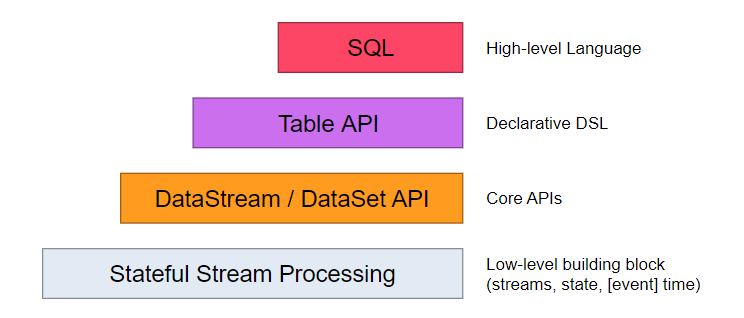
SQL & TableAPI
SQL & TableAPI同时适用于批处理和流处理,意味着可以对有界数据流和无界数据流以相同的语义进行查询,并产生相同的结果。除了基本查询外,它还支持自定义的标量函数,聚合函数以及表值函数,可以满足多样化的查询需求。
DataStream & DataSetAPI
DataStream & DataSetAPI是Flink数据处理的核心API,支持使用Java语言或Scala语言进行调用,提供了数据读取,数据转换和数据输出等一系列常用操作的封装。
StatefulStreamProcessing
StatefulStreamProcessing是最低级别的抽象,它通过ProcessFunction函数内嵌到DataStreamAPI中。ProcessFunction是Flink提供的最底层API,具有最大的灵活性,允许开发者对于时间和状态进行细粒度的控制。
DataStream API概述
Flink的DataStream API是Flink中最主要的API之一,它用于处理无限流数据。DataStreamAPI支持高级的流处理操作,例如窗口计算、状态管理、流分区等,并且在处理大规模数据时表现出色。
由于Flink DataSet和DataStream API的高度相似,并且DataStream API提供流批一体处理的能力,官方也推荐直接使用DataStream API,因此学习DataStream API如何使用即可。
流(STREAMING)执行模式适用于需要连续增量处理,而且预计无限期保持在线的无边界作业。
批(BATCH)执行模式适用于有一个已知的固定输入,而且不会连续运行的有边界作业。
开发Flink程序过程
确定需求:明确想要解决的问题或实现的功能。
导入依赖:在项目中导入Apache Flink相关的依赖,可以使用Maven、Gradle或其他构建工具来管理依赖关系。
创建StreamExecutionEnvironment:使用StreamExecutionEnvironment.getExecutionEnvironment()创建Flink的执行环境对象,它用于配置和执行流处理作业。
读取数据:从适合的数据源(例如文件、Kafka、Socket等)读取数据,可以使用readTextFile()、addSource()等方法来读取数据并转换为DataStream。
转换操作:对读取到的数据进行处理和转换操作,可以使用诸如map、flatmap、filter等方法来进行各种转换和处理。
窗口操作(可选):如果需要对数据进行窗口操作(例如滚动窗口、滑动窗口等),可以使用Flink提供的窗口操作方法。
结果处理:将转换后的数据写入文件、数据库、消息队列或其他输出源,或者使用print()、collect()等方法将数据打印到控制台。
设置作业配置和调优(可选):根据需求和性能要求,可以设置作业的并行度、时间特性、状态后端、容错机制、资源配置等。
执行作业:通过调用env.execute()方法来执行流处理作业。作业将提交到Flink集群或本地运行。
监控和调试(可选):可以通过Flink的监控界面查看作业的状态和指标,并使用日志和调试工具追踪和解决问题。
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.17.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.0</version>
</dependency>
创建执行环境
Flink程序可以在各种上下文环境中运行:
可以在本地 JVM 中执行程序
可以提交到远程集群上运行
创建执行环境是使用StreamExecutionEnvironment类,调用这个类的静态方法来创建执行环境。
获取到程序执行环境后,还可以对执行环境进行灵活的设置。
可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。
1.本地执行环境
使用createLocalEnvironment()方法创建一个本地执行环境
可以在调用时传入一个参数,指定默认的并行度,默认并行度是电脑CPU核心数
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(2);
2.集群执行环境
使用createRemoteEnvironment("node01", 8888,"/root/demo.jar")方法创建一个集群执行环境
需要在调用时指定JobManager的主机名和端口号,以及在集群中运行的Jar包
/**
* JobManager 主机名
* JobManager 进程端口号
* 提交给JobManager的JAR包
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("node01", 8888,"/root/demo.jar");
3.自适应执行环境
使用getExecutionEnvironment()方法根据当前运行的上下文直接得到正确的执行环境
如果程序独立运行,则返回一个本地执行环境。如果创建了jar包,然后在命令行调用它并提交到集群执行,则返回集群的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
4.本地执行环境+Web UI
使用createLocalEnvironmentWithWebUI(conf)方法创建一个本地执行环境,同时启动Web监控UI。
需要创建一个配置文件,设置相关参数,如设置Web UI端口,默认使用端口8081
Configuration conf = new Configuration();
conf.set(RestOptions.BIND_PORT, "8082");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
执行模式
DataStream API执行模式包括:流执行模式、批执行模式和自动模式。
流执行模式Streaming
流执行模式是DataStream API最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是Streaming执行模式。
批执行模式Batch
批执行模式是专门用于批处理的执行模式
自动模式AutoMatic
在自动模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
配置批执行模式
执行模式可以通过 execute.runtime-mode 设置来配置。有三种可选的值:
STREAMING: 经典 DataStream 执行模式(默认)
BATCH: 在 DataStream API 上进行批量式执行
AUTOMATIC: 让系统根据数据源的边界性来决定
1.通过命令行配置
提交作业时,增加
execution.runtime-mode参数,指定值为BATCH。
bin/flink run -Dexecution.runtime-mode=BATCH
2.通过代码配置
// 创建流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 基于执行环境调用setRuntimeMode方法,传入BATCH模式。不建议,推荐通过命令行传递参数
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
创建Data Source
创建执行环境后,可以使用其提供的一些方法,通过这些方法可以创建Data Source
例如:从文件中读取数据:可以直接逐行读取数据,像读CSV文件一样,或使用任何第三方提供的source
String filePath = "data/test.text";
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile(filePath);
应用转换算子
这将生成一个DataStream,然后可以在上面应用转换算子transformation来创建新的派生DataStream。可以调用DataStream上具有转换功能的方法来应用转换。
例如: 应用一个map的转换算子,它将通过把原始集合中的每一个字符串转换为一个整数来创建一个新的DataStream。
DataStream<String> text = ...;
DataStream<Integer> parsed = text.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
创建Data Sink
一旦有了包含最终结果的DataStream,就可以通过创建sink把它写到外部系统。
// 简单skin:将DataStream以文本格式写入path指定的文件
parsed.writeAsText("data/out");
// 控制台打印
parsed.print();
触发程序执行
需要调用StreamExecutionEnvironment 的execute()、executeAsync()方法来触发程序执行
execute()方法将等待作业完成,然后返回一个JobExecutionResult,其中包含执行时间和累加器结果。
JobExecutionResult result = env.execute();
如果不想等待作业完成,使用executeAsync() 方法来触发作业异步执行。它会返回一个 JobClient,可以通过它与刚刚提交的作业进行通信。
JobClient jobClient = env.executeAsync();
JobExecutionResult jobExecutionResult = jobClient.getJobExecutionResult().get();
示例
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
DataStreamSource<String> text = env.readTextFile("data/test.text");
// 应用转换算子
DataStream<Integer> parsed = text.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
int number = Integer.parseInt(value);
System.out.println("number = " + number);
return number;
}
});
// 简单skin:将DataStream以文本格式写入path指定的文件
parsed.writeAsText("data/out");
// 控制台打印
parsed.print();
// 触发执行
env.execute();
}
Flink常见数据类型
原始数据类型:例如布尔值、整数(byte、short、int、long)、浮点数(float、double)和字符(char)
字符串类型:表示为 Java 类型 String 或 scala 类型 String
时间和日期类型:包括 Timestamp 和 Date,以及 Interval 类型,用于表示时间间隔
数组类型:数组是同一类型的元素的有序集合
元组类型:元组是不同类型的元素的有序集合
列表类型:列表是具有相同元素类型的有序元素集合
映射类型:映射是键值对的无序集合,键和值可以是任何类型
POJO类型:POJO 是普通的 Java 对象,它们包含字段或属性,可以通过名称或 getter 和 setter 方法进行访问
Row类型:Row 是一个有序的、命名的字段集合。与POJO类型类似,但没有setter 和getter方法
可序列化类型:即实现 java.io.Serializable 接口的类型
基本数据类型
Flink支持Java中的所有基本数据类型,例如布尔值、整数(byte、short、int、long)、浮点数(float、double)和字符(char)。
在Flink中定义一个int类型的流
DataStream<Integer> stream = env.fromElements(1, 2, 3, 4, 5);
字符串类型
字符串类型在Flink中也很常见,可以使用Java或Scala中的String类型表示。
DataStream<String> stream = env.fromElements("hello", "world");
时间和日期类型
时间和日期类型包括DATE、TIME、TIMESTAMP类型,用于表示时间间隔。
DataStream<Tuple2<String, Timestamp>> stream = env.fromElements(
Tuple2.of("event-1", new Timestamp(System.currentTimeMillis())),
Tuple2.of("event-2", new Timestamp(System.currentTimeMillis() - 1000))
);
数组类型
数组是同一类型的元素的有序集合。包括基本数据类型数组(PRIMITIVE_ARRAY)和复杂数据类型数组(OBJECT_ARRAY。其中,基本数据类型数组可以是任意基本数据类型的数组,而复杂数据类型数组则可以是结构体或者嵌套的数组。
DataStream<int[]> stream = env.fromElements(new int[]{1, 2, 3}, new int[]{4, 5, 6});
元组类型
元组是复合类型,包含固定数量的各种类型的字段。Java API提供了从Tuple1到Tuple25,不支持空字段
元组是不同类型的元素的有序集合。也就是说元组的每个字段都可以是任意Flink 类型,包括更多元组,从而产生嵌套元组
DataStream<Tuple3<String, Integer, Double>> stream = env.fromElements(
Tuple3.of("a", 1, 1.1),
Tuple3.of("b", 2, 2.2)
);
列表类型
列表是具有相同元素类型的有序元素集合。
DataStream<List<String>> stream = env.fromElements(Arrays.asList("hello", "world"), Arrays.asList("foo", "bar"));
映射类型
映射是键值对的无序集合,键和值可以是任何类型。
Map<String, Integer> map1 = new HashMap<>();
map1.put("a", 1);
map1.put("b", 2);
Map<String, Integer> map2 = new HashMap<>();
map2.put("c", 3);
map2.put("d", 4);
DataStream<Map<String, Integer>> stream = env.fromElements(map1, map2);
POJO类型
POJO是普通的Java对象,它们包含字段或属性,可以通过名称或getter和setter方法进行访问
Flink对POJO 类型的要求如下:
类是公有public的
有一个无参的构造方法
所有属性都是公有public的,要么必须可通过 getter 和 setter 函数访问
所有属性的类型都是可以序列化的
public class Person {
public String name;
public int age;
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
}
DataStream<Person> stream = env.fromElements(
new Person("Alice", 25),
new Person("Bob", 30)
);
Row类型
Row是一个有序的、命名的字段集合。与 POJO类型类似,但没有setter 和 getter 方法。可以认为是具有任意个字段的元组,并支持空字段。
可序列化类型
即实现 java.io.Serializable 接口的类型。
public class MySerializableClass implements Serializable {
private int value;
public MySerializableClass(int value)
类型提示
Flink的类型提示Type Hints机制,它可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。也就是说可以帮助Flink更好地理解数据集中元素的类型,从而提高程序的性能。
使用TypeHint或Types类来指定数据集元素的类型
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> input = env.fromCollection(Arrays.asList("a b", "b c", "c d"));
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = input
.flatMap(
(String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
// 显式地提供类型信息:对于flatMap传入Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple2<String, Long>。只有显式设置系统当前返回类型,才能正确解析出完整数据
.returns(new TypeHint<Tuple2<String, Integer>>() {
})
// .returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy(value -> value.f0)
.sum(1);
sum.print();
env.execute();
}


![进程概念[上]](https://img-blog.csdnimg.cn/3c5a41cdf100434fabc6964087e110ee.png)