文章目录
- 1.数据探索与清洗
- 2.假设检验:平稳性检验
- 3.差分处理
- 4.绘制ACF与PACF图像,完成模型选择
- 4.建立ARIMA和SARIMA模型
- 5.解读summary
- 6.确定最终的模型
ARIMA模型在统计学上的三大基本假设:
- 时间序列具有平稳性(stationary),即标签值的变化规律不随时间而改变,这是从过去的时间中习得的规律可以被用于未来的基本条件。这一条件保障了当前数据中有超越时间的“客观规律”可以被提取。
- 样本与样本之间具有相关性,即历史结果可以影响未来、与未来的结果相关,这一假设保障了使用过去预测未来是可能的。
- ARIMA模型的预测标签𝑦̂ 与真实标签𝑦之间的残差𝒓等同于白噪声(White Noise)。在时间序列最严格的定义中,白噪声序列是均值为0、方差为特定𝜎2、服从正态分布、且样本与样本之间相互独立的随机序列。这样的序列是完全无序的、无法被捕捉的。当预测值与真实值之间的差异是无法捕捉的随机序列,这说明ARIMA模型已经将能够捕捉的规律全部捕捉到了。
需要注意的是,MA模型求解过程中不断估计出的 [ ϵ t , ϵ t − 1 , … , ϵ t − k ] [\epsilon_{t},\epsilon_{t-1},…,\epsilon_{t-k}] [ϵt,ϵt−1,…,ϵt−k]也是残差,但建模过程中估计出的残差与建模结束后才计算的残差序列𝒓在具体数值上有巨大的差别。序列𝒓是在ARIMA模型训练完毕后才结合真实标签计算出来的,相当于使用了最后、最新的、迭代完毕的𝛽、𝜃、𝜖值,而MA模型中的 [ ϵ t , ϵ t − 1 , … , ϵ t − k ] [\epsilon_{t},\epsilon_{t-1},…,\epsilon_{t-k}] [ϵt,ϵt−1,…,ϵt−k]是一系列中间变量,在模型迭代过程中会不断发生变化。注意不要混淆两个残差序列。
为了满足上述三个条件,我们需要在ARIMA建模之前完成平稳性检验、样本的相关性检验,并在ARIMA建模完成之后完成一系列验证白噪声的混成检验,不过有时候我们会省略样本相关性检验,因为我们将在ARIMA建模过程中使用ACF和PACF辅助判断ARIMA模型的参数,如果样本与样本之间缺乏相关性,在绘制ACF和PACF时就能够发觉这一点。
通常来说,完成一个完整的ARIMA建模过程需要下面的7个步骤: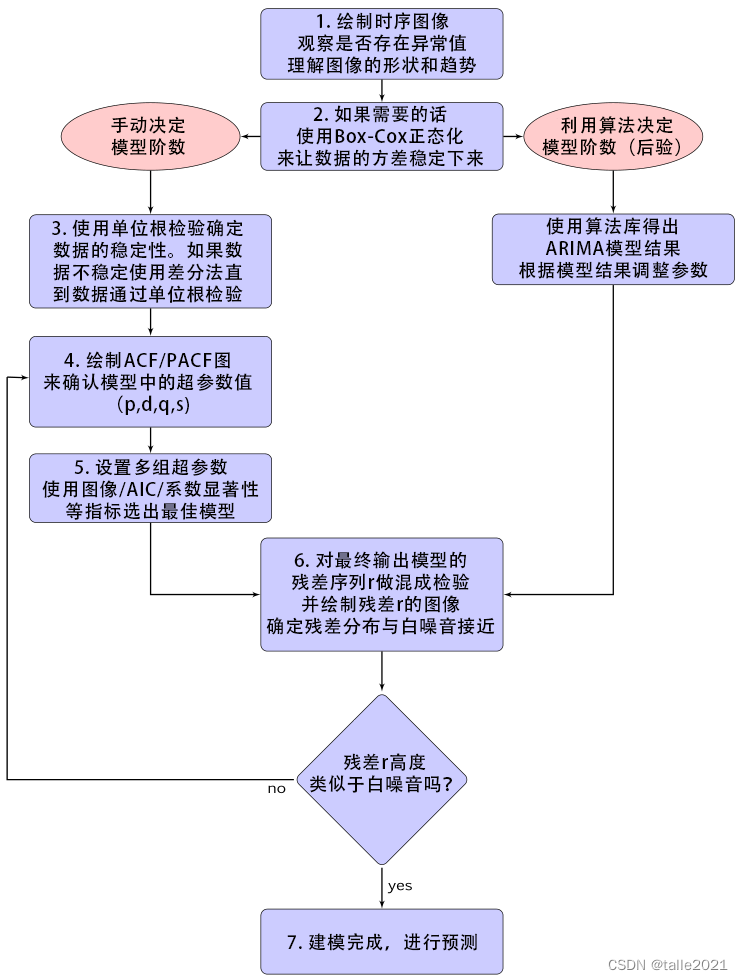
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
df=pd.read_csv(r'F:\Jupyter Files\时间序列\data\perrin-freres-monthly-champagne.csv')
df.head()
| Month | Perrin Freres monthly champagne sales millions ?64-?72 | |
|---|---|---|
| 0 | 1964-01 | 2815.0 |
| 1 | 1964-02 | 2672.0 |
| 2 | 1964-03 | 2755.0 |
| 3 | 1964-04 | 2721.0 |
| 4 | 1964-05 | 2946.0 |
1.数据探索与清洗
df["Month"].dtype
dtype(‘O’)
df.iloc[:,-1].dtype
dtype(‘float64’)
df.columns
Index([‘Month’, ‘Perrin Freres monthly champagne sales millions ?64-?72’], dtype=‘object’)
#找出缺失值所在行
df.loc[df[ 'Perrin Freres monthly champagne sales millions ?64-?72'].isnull()].index.tolist()
[105, 106]
#确定列名,检验缺失值、填补/删除缺失值等等
df.columns=["Month","Sales"]
df.drop(106,axis=0,inplace=True)
df.drop(105,axis=0,inplace=True)
#转化时间字符串为DataTime格式
df['Month']=pd.to_datetime(df['Month'])
#将时间设置为索引
df.set_index('Month',inplace=True)
df.head()
| Sales | |
|---|---|
| Month | |
| 1964-01-01 | 2815.0 |
| 1964-02-01 | 2672.0 |
| 1964-03-01 | 2755.0 |
| 1964-04-01 | 2721.0 |
| 1964-05-01 | 2946.0 |
#可视化
df.plot(figsize=(10,5),grid=True);
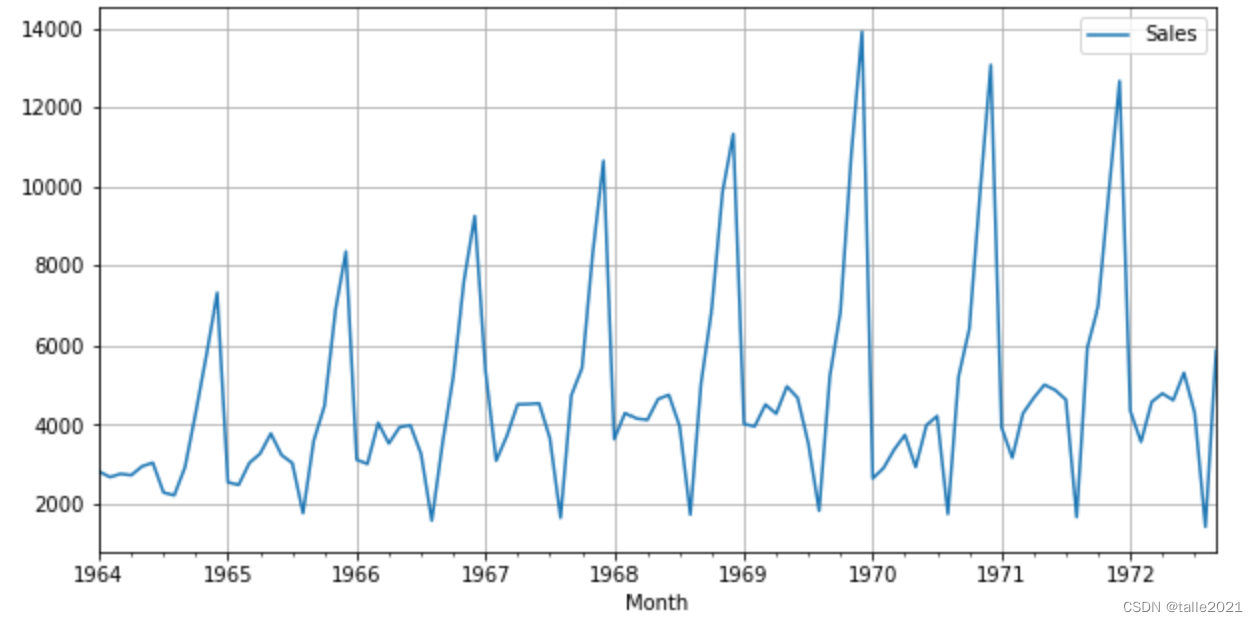
很明显,数据具有周期性,因此数据大概率是无法满足平稳性条件的。具体地来说,每年年末会出现一个峰值、一个谷底,峰值出现在每年的第四季度,谷底出现在每年的第三季度,其他时间的销售额相对均匀。从图像来看,该数据不仅整体均值呈现微微上升的趋势,数据的方差变化也较大,接下来我们可以在平稳性检验上验证我们的猜测。
2.假设检验:平稳性检验
在使用统计学模型进行建模时,往往需要完成一系列假设检验的工作。对ARIMA模型而言,必须要完成的建模前检验主要是平稳性检验。对ARIMA模型来说,如果数据是不平稳的、比如带有持续上升或下降的趋势、或者数据在不同时间阶段的波动程度明显不同,那我们则需要对数据进行差分处理直到数据平稳为止。
在这里将要使用的是Augmented Dickey-Fuller单位根检验。在概率论与数理统计当中,单位根(unit root)是趋势性的象征。如果一个序列中存在单位根,那该序列应该有较强的趋势性,在这样的序列上建模的难度会很大、模型也很容易失效,因此单位根检验能够帮助我们判断“趋势”这一因素在多大程度上影响了一个时间序列的值。如果在检验中我们发现单位根存在,则说明该时间序列受到“趋势”影响很大。
在这个检验中,两项假设如下:
- 原假设H0:数据是不平稳序列。如果该假设没有被拒绝,则表示时间序列里有单位根,意味着它是不平稳的,它很大程度上受到“趋势性”的影响。
- 备择假设H1:数据是平稳的。如果拒绝原假设,则说明该时间序列没有单位根,则数据是平稳的,它基本不受“趋势性”的影响。
在测试中,使用测试的p值来解释这个结果:
- p>0.05:无法拒绝原假设,数据有单位根且不平稳。
- p<=0.05:拒绝原假设,数据没有单位根,是平稳的序列。
from statsmodels.tsa.stattools import adfuller
result=adfuller(df["Sales"]) #这就可以完成一次检验
result
(-1.8335930563276195,
0.3639157716602467,
11,
93,
{‘1%’: -3.502704609582561,
‘5%’: -2.8931578098779522,
‘10%’: -2.583636712914788},
1478.4633060594724)
以上返回的结果分别是检验值、p值、使用的滞后数、使用的样本数、在1%、5%、10%显著性水平上的检验值、以及当前数据上使用ARIMA时可能的AIC值。在这些值当中,我们最为关心前2项数值,因此可以将前2项打包到函数中,并让函数直接输出检验的结果:
def adfuller_test(sales):
#将唯一的标签:销售额放入检验
result=adfuller(sales)
#让statsmodel的DF单位根检验返回检验值 & p值 & 添加了多少滞后 & 使用的样本量
labels = ['ADF Test Statistic','p-value']
#打包标签和结果
for value,label in zip(result,labels):
print(label+' : '+str(value) )
#如果p值小于等于0.05,则说明可以拒绝原假设,认为数据是平稳的。如果p值大于0.05,则说明需要接受原假设,数据不平稳。
if result[1] <= 0.05:
print("拒绝原假设,数据具有平稳性")
else:
print("无法拒绝原假设,数据不平稳")
return result[1]
pvalue = adfuller_test(df['Sales'])
ADF Test Statistic : -1.8335930563276195
p-value : 0.3639157716602467
无法拒绝原假设,数据不平稳
pvalue
0.3639157716602467
ADF检验值的绝对值越大(即离0越远),越有可能拒绝原假设,现在的-1.8并不是一个足够大的数,因此大概率无法拒绝原假设。同时看p值,当p值大于0.05时,无法拒绝原假设。因此数据不平稳,需要做差分处理。
3.差分处理
很明显,现在数据并不平稳,因此需要完成差分处理来让数据变得平稳。差分运算是一种独特的数学运算,对于任意函数𝑓(𝑥),差分被定义为𝑓(𝑥+1)−𝑓(𝑥)。即,自变量移动1个单位,函数值变化的量就是函数的差分。具体地来说,一个函数上不同自变量对应的差分可能不同,因此一般我们称Δ𝑦=𝑓( x 0 x_{0} x0+1)−𝑓( x 0 x_{0} x0)为函数𝑓(𝑥)在自变量点 x 0 x_{0} x0的一阶差分。很明显,差分的结果反映了离散量之间的一种变化,对于时间序列来说,差分的结果反应的是两个时间点之间标签产生的变化。
尽管ARIMA模型中自带令数据平稳的参数𝑑,但大部分时候还是会优先考虑让模型先通过单位根检验、之后再让数据进入ARIMA模型。
#使用shift函数构造差分,shift(1)函数相当于滞后1(1步差分)
df['Sales'] - df['Sales'].shift(1)
------------------------------------------------------
Month
1964-01-01 NaN
1964-02-01 -143.0
1964-03-01 83.0
1964-04-01 -34.0
1964-05-01 225.0
...
1972-05-01 -170.0
1972-06-01 694.0
1972-07-01 -1014.0
1972-08-01 -2885.0
1972-09-01 4464.0
Name: Sales, Length: 105, dtype: float64
df["Sales"].diff().dropna() #一阶差分可以直接通过diff()命令完成
--------------------------------------------------------------
Month
1964-02-01 -143.0
1964-03-01 83.0
1964-04-01 -34.0
1964-05-01 225.0
1964-06-01 90.0
...
1972-05-01 -170.0
1972-06-01 694.0
1972-07-01 -1014.0
1972-08-01 -2885.0
1972-09-01 4464.0
Name: Sales, Length: 104, dtype: float64
#通过循环,查看究竟多少步差分能够让这一序列满足单位根检验
#如果许多差分都能够满足单位根检验,通常选择ADF值最小、或差分后数据方差最小的步数
columns = ["D1","D2","D3","D4","D5","D6","D7","D8","D9","D10","D11","D12","D24","D36"]
pvalues = []
stds = []
for idx,degree in enumerate([*range(1,13),24,36]):
#打印差分的步数
print("{}步差分".format(degree))
#计算差分列
df[columns[idx]] = df["Sales"] - df["Sales"].shift(idx+1)
#进行ADF检验,提取P值,并计算差分列的标准差
pvalue = adfuller_test(df[columns[idx]].dropna())
std_ = df[columns[idx]].std()
#保存P值和标准差
pvalues.append(pvalue)
stds.append(std_)
#对结果进行打印
print("差分后数据的标准差为{}".format(std_))
print("\n")
1步差分
ADF Test Statistic : -7.189896448051006
p-value : 2.51962044738698e-10
拒绝原假设,数据具有平稳性
差分后数据的标准差为2650.968186669989
2步差分
ADF Test Statistic : -7.135995302286716
p-value : 3.4199891594729983e-10
拒绝原假设,数据具有平稳性
差分后数据的标准差为3567.6351723537286
3步差分
ADF Test Statistic : -7.285630595925722
p-value : 1.4614244887641837e-10
拒绝原假设,数据具有平稳性
差分后数据的标准差为3927.279876517501
4步差分
ADF Test Statistic : -7.253149049898573
p-value : 1.758579949850846e-10
拒绝原假设,数据具有平稳性
差分后数据的标准差为4090.0957191830116
5步差分
ADF Test Statistic : -2.8571173948549804
p-value : 0.050566743535901404
无法拒绝原假设,数据不平稳
差分后数据的标准差为3703.1920631348094
6步差分
ADF Test Statistic : -7.278597607548264
p-value : 1.5212208957659128e-10
拒绝原假设,数据具有平稳性
差分后数据的标准差为3540.5571256000353
7步差分
ADF Test Statistic : -1.74747216860766
p-value : 0.40683412640557615
无法拒绝原假设,数据不平稳
差分后数据的标准差为3726.756506409909
8步差分
ADF Test Statistic : -2.0559478573458687
p-value : 0.26259291600017703
无法拒绝原假设,数据不平稳
差分后数据的标准差为4203.561065940937
9步差分
ADF Test Statistic : -1.6682171435071937
p-value : 0.44755783870903904
无法拒绝原假设,数据不平稳
差分后数据的标准差为4041.9327997204673
10步差分
ADF Test Statistic : -1.6821939340098784
p-value : 0.44030925760785683
无法拒绝原假设,数据不平稳
差分后数据的标准差为3624.687899851875
11步差分
ADF Test Statistic : -1.8189275809847043
p-value : 0.37110598573991177
无法拒绝原假设,数据不平稳
差分后数据的标准差为2715.110310076176
12步差分
ADF Test Statistic : -7.626619157213166
p-value : 2.0605796968136632e-11
拒绝原假设,数据具有平稳性
差分后数据的标准差为760.6936383068079
24步差分
ADF Test Statistic : -1.8607723212111829
p-value : 0.35073396610651575
无法拒绝原假设,数据不平稳
差分后数据的标准差为2685.9057474278457
36步差分
ADF Test Statistic : -1.142645748518425
p-value : 0.6977692692837064
无法拒绝原假设,数据不平稳
差分后数据的标准差为3626.466460517067
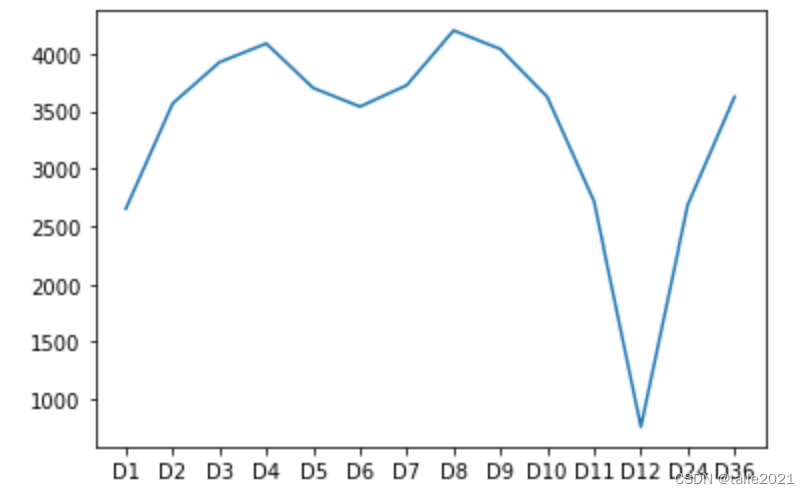
#哪些步数下数据是平稳的?
plt.plot(columns,pvalues)
plt.hlines(0.05,0,14,colors="red",linestyles="dotted");
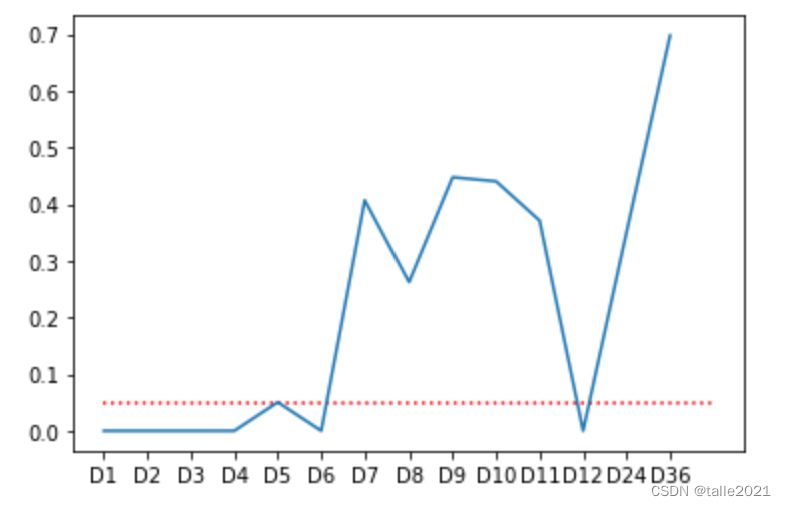
#最小的标准差对应的步数是?
plt.plot(columns,stds);
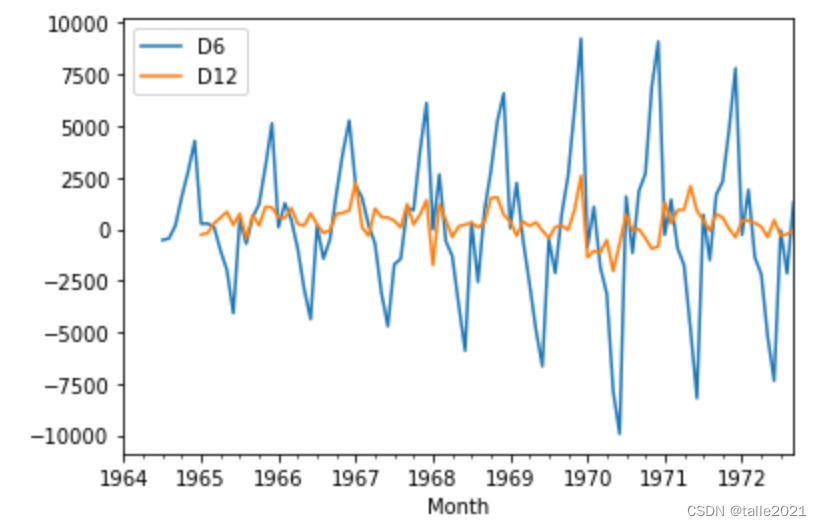
df[['D6',"D12"]].plot();
df['D12'].plot();
因此12步差分是最优的差分选择,接下来就按照12步差分后的结果进行建模。
4.绘制ACF与PACF图像,完成模型选择
from statsmodels.tsa.arima_model import ARIMA
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(df['D12'].dropna(),lags=40,ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(df['D12'].dropna(),lags=40,ax=ax2)
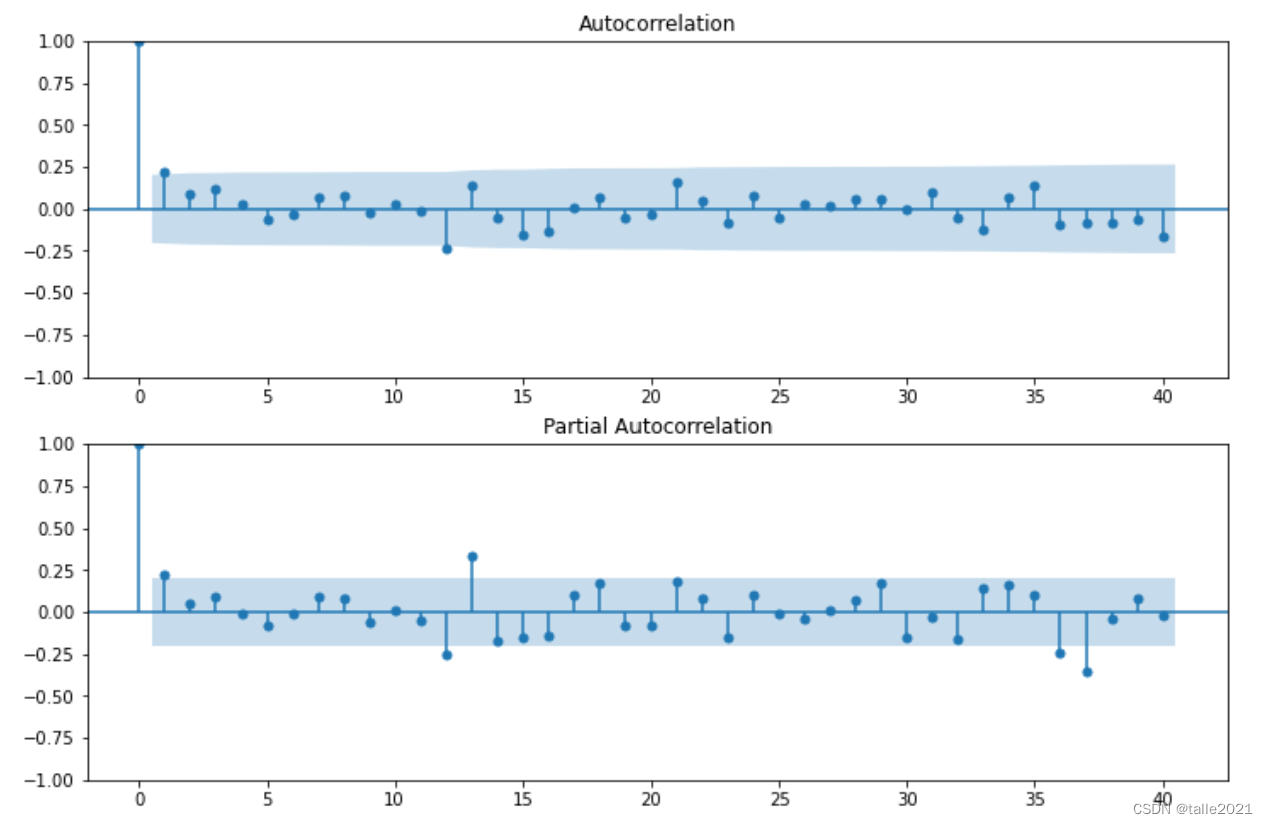
观察ACF和PACF的状态,很明显,两个自相关系数都没有呈现拖尾的情况、而是更加随机地排列,因此p和q都不为0,此时需要的至少是一个ARIMA(p,d,q)模型。
在确定p和q都不为0后,需要先确定合适的d值、再建模寻找合适的p和q。一般会先尝试[0,1,2,3]阶差分,并取这些差分当中不存在过差分问题的、方差较小、噪音较少的阶数作为d的取值。当对数据的ACF绘图时,如果滞后为1的ACF为负,就说明数据存在过差分问题。依据这些理论,打印4个不同阶差分的标准差和ACF图像:
from statsmodels.graphics.tsaplots import plot_acf
diff = [df["Sales"],df["Sales"].diff().dropna()
,df["Sales"].diff().diff().dropna()
,df["Sales"].diff().diff().diff().dropna()
]
titles = ["d=0","d=1","d=2","d=3"]
fig, (ax1, ax2, ax3, ax4) = plt.subplots(4,1,figsize=(8,14))
for idx, ts, fig, title in zip(range(4),diff,[ax1,ax2,ax3,ax4],titles):
print("{}阶差分的标准差为{}".format(idx,ts.std()))
plot_acf(ts, ax=fig, title=title)
0阶差分的标准差为2553.5026011831437
1阶差分的标准差为2650.968186669989
2阶差分的标准差为3907.4512785194675
3阶差分的标准差为6577.656456299289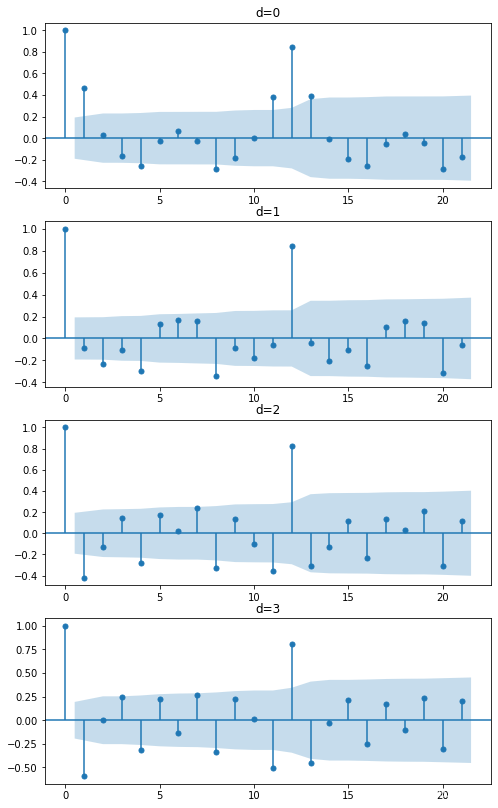
很明显,除了原始数据,其他阶差分都出现了“过差分”的情况(滞后为1的ACF值为负),且原始数据的标准差小于任何差分数据,因此可以判断对ARIMA模型而言最佳的d取值为0。
在这里,除了ARIMA(p,d,q)之外,还可以考虑使用SARIMA(p,d,q,s)模型。SARIMA是季节性ARIMA模型,非常擅长处理周期性数据,它的前三个超参数含义与ARIMA完全相同,而最后一个超参数s则代表差分的步数,这说明SARIMA模型可以同时完成多步差分和高阶差分两个任务,相比之下ARIMA模型只能做高阶差分。
在上面的平稳性检验中,已经知道当前时间序列具有较强的周期性、且能够让序列变得平稳的最佳选择是12步差分,因此自带多步差分功能、且擅长处理周期性数据的SARIMA模型可能是更好的选择。SARIMA模型规定,当原始序列明显周期性明显时,d的值至少是1,因此我们可以暂时将SARIMA模型的d值确认为1。
4.建立ARIMA和SARIMA模型
from statsmodels.tsa.arima.model import ARIMA
#在0.12及以上版本的statsmodel中,ARIMA一个类可以实现AR、MA、ARMA、ARIMA和SARIMA模型
from pandas.tseries.offsets import DateOffset
import warnings
warnings.filterwarnings("ignore")
建模之前,需要先将时间序列的索引转换为pandas规定的DataTime索引。DataTime索引可以帮助时序模型理解每个样本代表的是一个月、一分钟、还是一天,时间序列模型因此得知当前时间序列的“频率”。
df.index.inferred_freq #当前时序数据的频率为月份
‘MS’
df.index = pd.DatetimeIndex(df.index.values,
freq=df.index.inferred_freq)
由于数据具有较强的周期性,因此考虑同时建立d=0的ARIMA和d=1的SARIMA模型。
#对每个备选模型,我们进行训练、打印训练结果,并绘制预测图像
arima_0=ARIMA(endog = df['Sales'],order=(1,0,1))
arima_0=arima_0.fit()
df['arima']=arima_0.predict(start=90,end=103,dynamic=True)
df[['Sales','arima']].plot(figsize=(12,4));
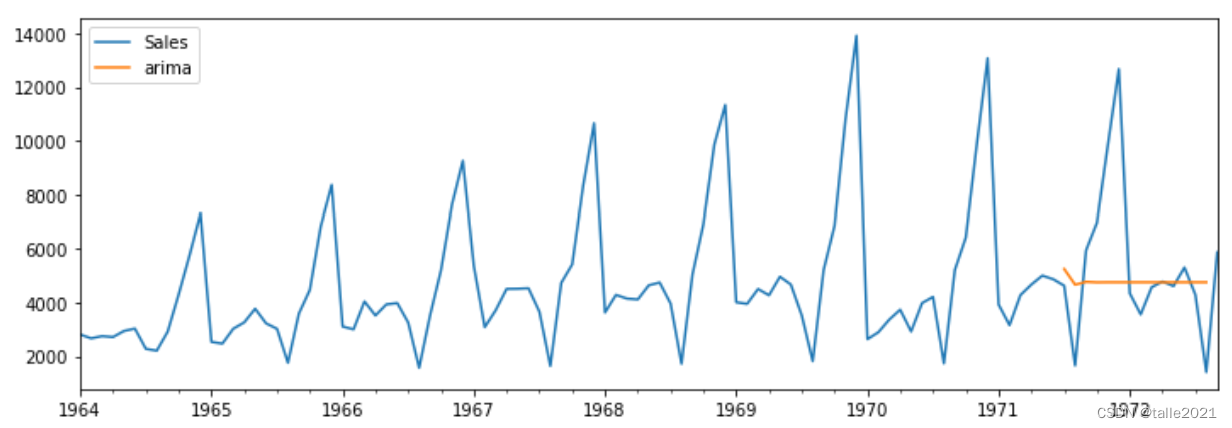
从预测出的图像大概可以看出当前参数组合是否足够优秀(很明显现在的模型在预测上没有任何作用),当预测的图像不合格时我们可以直接更换参数,当预测的图像看起来相对合理时我们可以打印当前模型的更多详情进行查看。
print(arima_0.summary(alpha=0.05))
#alpha - 人为规定的显著性水平,一般都使用0.05或者0.01
SARIMAX Results
==============================================================================
Dep. Variable: Sales No. Observations: 105
Model: ARIMA(1, 0, 1) Log Likelihood -955.880
Date: Mon, 07 Nov 2022 AIC 1919.760
Time: 00:38:08 BIC 1930.375
Sample: 01-01-1964 HQIC 1924.061
- 09-01-1972
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 4761.1524 437.563 10.881 0.000 3903.544 5618.760
ar.L1 -0.1845 0.130 -1.420 0.156 -0.439 0.070
ma.L1 0.7883 0.107 7.382 0.000 0.579 0.998
sigma2 5.046e+06 8e+05 6.306 0.000 3.48e+06 6.61e+06
===================================================================================
Ljung-Box (L1) (Q): 0.09 Jarque-Bera (JB): 10.08
Prob(Q): 0.76 Prob(JB): 0.01
Heteroskedasticity (H): 3.44 Skew: 0.73
Prob(H) (two-sided): 0.00 Kurtosis: 3.39
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
summary表单概括了statsmodel中的ARIMA类完成的所有任务,包括在建模流程中的5、6两步:即使用评估指标评估最佳模型,并完成针对残差的混成检验,接下来看看summary表单中的具体内容。
5.解读summary
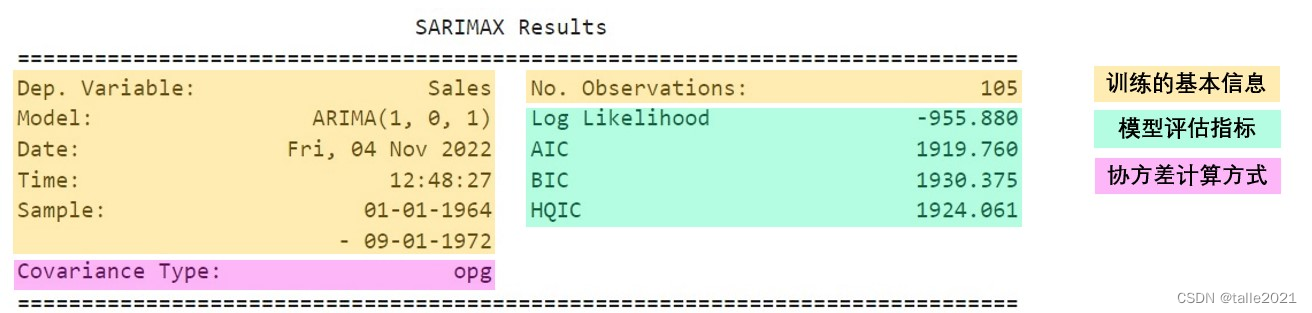
summary方法返回的第一部分是当前模型最基本的信息和最基本的评估指标。如上图所示,训练的基本信息(浅黄色部分)包括了当前建立的ARIMA模型、建模时间、样本数量等等信息,这一部分是我们在建模后几乎不会去阅读的内容,除非我们对当前模型训练的时间段有特殊的要求。同样一般也不会去关注的还有协方差的计算类型(粉色部分),在statsmodels中存在6种以上不同的协方差计算方法,默认的方法是opg(即等同于皮尔逊相关系数中的协方差计算方法)。
值得注意的是模型评估指标部分,这里列出的四个指标分别是对数似然估计、AIC、BIC和HQIC四个评估指标,其中对数似然估计Log Likehood是越大越好,而其他三个指标AIC、BIC和HQIC是越小越好。通常我们会直接关注AIC的指标,优先选出AIC最低的模型进行进一步的研究和观察。

summary方法返回的第二部分是整张表单中最为重要的部分,这一部分展示了训练好的ARIMA模型中每一个具体的项的值、以及这些项的显著性水平,结合这张表单中的内容和建立的ARIMA模型时设置的p、d、q值,可以写出当前ARIMA模型的具体公式。
以现在的ARIMA(1,0,1)为例,当前ARIMA由MA(1)和RA(1)共同构成,因此公式如下:
y
(
1
,
0
,
1
)
=
β
0
+
β
1
y
t
−
1
+
ϵ
t
+
θ
1
ϵ
t
−
1
y_{(1,0,1)}=\beta_{0}+\beta_{1}y_{t-1}+\epsilon_{t}+\theta_{1}\epsilon_{t-1}
y(1,0,1)=β0+β1yt−1+ϵt+θ1ϵt−1
在这个公式中,常数
β
0
\beta_{0}
β0就对应着表格左侧第一项constant(英文直译:常数),AR模型的唯一项
β
1
y
t
−
1
\beta_{1}y_{t-1}
β1yt−1就对应着ar.L1,MA模型的唯一项
θ
1
ϵ
t
−
1
\theta_{1}\epsilon_{t-1}
θ1ϵt−1就对应着ma.L1。如此不难发现,ar.L1中的L1指的是滞后1,表示值带有滞后1这一项的AR模型,ma.L1同理。该表格中左侧的项是与ARIMA的项一一对应的,因此当我们设置的p、d、q值不同时,该表格中反馈的项也会不一样。
在此基础上,该表格中值得关注的列有:
coef:该项的系数,比如
ar.L1的coef就是 β 1 \beta_{1} β1的取值,ma.L1的coef就是 θ 1 \theta_{1} θ1的取值。当该项是常数项时,coef就等于该项本身。
std err:当前项的标准误,衡量当前项对整个ARIMA模型的预测损失的影响。一个项的std err越大,说明这个项对当前模型的损失贡献越大,进一步说明模型对这个项的参数估计可能越不准确。比如上面的表格中,很明显对损失贡献非常巨大的是 ϵ t \epsilon_{t} ϵt,说明模型当前给出的 5.046 ∗ e 6 5.046*e^{6} 5.046∗e6这个值带来了巨大的损失,模型在拟合当前项的时候遭遇了巨大的困难。
𝑷>|𝒛|:该项的系数在统计学上是否显著的p值。在这里我们完成的是针对每一个系数的单变量检验。
单变量检验的原假设(H0):当前系数coef为0(当前项与标签不相关)
单变量检验的备择假设(H1):当前系数coef不为0(当前项与标签相关)很明显,对模型来说理想的状态是拒绝原假设、接受备择假设,因此在我们规定的显著性水平𝛼(0.05)下,如果有任意项的p值大于𝛼,则说明当前项的系数没能通过显著性检验,模型对当前项的系数没有足够的信心。例如,在当前表格中,
ar.L1的p值为0.156,大于显著性水平0.05,则说明系数-0.1845很可能是不可靠的、无法使用。在一个模型当中,如果很多系数的p值都大于0.05,则可能说明模型处于复杂度过高的状态(即,许多项看起来都与标签无关,所以可能创造了许多原本不需要的项)。此时可以选择更简单的模型。
在读表格的这一部分的时候,首先会观察p值,确定是否有任何项的p值大于设置的显著性水平𝛼。如果存在这样的项,那大概率就不会关注当前的模型了。在ARIMA模型选择过程中,我们选出的模型应当是所有项的p值都小于显著性水平的模型。
当模型的图像看起来合理、AIC值较小、且summary第二部分的p值没有任何大于0.05的项目时,我们才会看summary表单的最后一部分。Summary表单的第三部分是针对残差完成的各项假设检验。在混成检验的定义中,残差是真实标签与当前ARIMA的预测标签之间的差异,即:𝒓=𝒚−𝒚̂ 。
#对已经建好的模型,我们可以使用如下的属性调出该模型的残差r
arima_0.resid
----------------------------------------------------------
1964-01-01 -1946.152444
1964-02-01 -1334.461564
1964-03-01 -1492.756776
1964-04-01 -1331.169605
1964-05-01 -1193.671956
...
1972-05-01 -790.077042
1972-06-01 1147.266451
1972-07-01 -1265.917337
1972-08-01 -2435.669426
1972-09-01 2418.085584
Freq: MS, Length: 105, dtype: float64
当预测值与真实值之间的差异是无法捕捉的、完全无规律的随机数,就说明ARIMA模型已经将能够捕捉的规律全部捕捉到了,因此我们希望残差序列𝑟是白噪声序列。在时间序列最严格的定义中,白噪声序列是均值为0、方差为特定𝜎2、服从正态分布、且样本与样本之间相互独立的随机序列,因此针对残差序列𝑟,statsmodel中的ARIMA自动完成以下三项检验:
-
Ljung-Box test
Ljung的发音是"杨",一般在中文环境中我们称该检验为LBQ检验。LBQ检验是检查样本之间是否存在自相关性的检验。
LBQ检验原假设(H0):样本之间是相互独立的
LBQ检验备择假设(H1):样本之间不是相互独立的,存在一些内在联系如果残差序列是白噪声,那残差序列的样本之间应当是独立的,因此我们想要的是无法拒绝原假设的结果。故而,在查看LBQ测试的p值时,我们希望这是一个大于显著性水平(0.05)、令我们接受原假设的p值。总结一下,LBQ下的Prob(Q)项大于0.05时模型可用,否则可考虑更换模型的超参数组合。
-
Heteroskedasticity test
这是异方差检验。在一个序列当中,随机抽出不同的子序列并计算这些子序列的方差,如果每个子序列的方差不一致,则称该序列存在“异方差现象”,否则则称该序列为“同方差序列”。在时间序列中,白噪音应当是同方差序列,因此我们对残差做异方差检验,可以帮助我们进一步确认残差是否高度类似于白噪音数据。在统计学中,有多种方法来完成异方差检验,Statsmodels执行的是the White’s test。
异方差检验(White’s test)原假设(H0):该序列同方差
异方差检验(White’s test)备择假设(H1):该序列异方差很明显我们想要的是接受原假设的结果,因此同LBQ测试,我们希望异方差检验的p值是大于显著性水平的(大于0.05)。总结一下,异方差检验的Prob(H)大于0.05时模型可用,否则可考虑更换超参数组合。
-
Jarque-Bera test
雅克贝拉检验(根据葡萄牙语发音音译)是正态性检验中的一种,用于检验当前序列是否符合正态分布。
雅克-贝拉检验原假设(H0):序列是正态分布的
雅克-贝拉检验备择假设(H1):序列不是正态分布的时间序列中的白噪声是需要满足正态性条件的,因此我们希望检验结果无法拒绝原假设,因此我们希望该检验的p值是大于显著性水平的。总结一下,雅克-贝拉检验的Prob(JB)大于0.05时模型可用,否则可考虑更换超参数组合。
6.确定最终的模型
对于ARIMA模型,我们建立如下9个备选模型,而对SARIMA模型,我们同样建立9个备选模型:
#备选模型
arimas = [ARIMA(endog = df['Sales'],order=(1,0,1))
,ARIMA(endog = df['Sales'],order=(1,0,2))
,ARIMA(endog = df['Sales'],order=(2,0,1))
,ARIMA(endog = df['Sales'],order=(2,0,2))
,ARIMA(endog = df['Sales'],order=(1,0,3))
,ARIMA(endog = df['Sales'],order=(3,0,1))
,ARIMA(endog = df['Sales'],order=(3,0,2))
,ARIMA(endog = df['Sales'],order=(2,0,3))
,ARIMA(endog = df['Sales'],order=(3,0,3))
]
#SARIMA模型规定,最少要使用1阶差分
sarimas = [ARIMA(endog = df['Sales'],seasonal_order=(1,1,1,12))
,ARIMA(endog = df['Sales'],seasonal_order=(1,1,2,12))
,ARIMA(endog = df['Sales'],seasonal_order=(2,1,1,12))
,ARIMA(endog = df['Sales'],seasonal_order=(2,1,2,12))
,ARIMA(endog = df['Sales'],seasonal_order=(1,1,3,12))
,ARIMA(endog = df['Sales'],seasonal_order=(3,1,1,12))
,ARIMA(endog = df['Sales'],seasonal_order=(3,1,2,12))
,ARIMA(endog = df['Sales'],seasonal_order=(2,1,3,12))
,ARIMA(endog = df['Sales'],seasonal_order=(3,1,3,12))
]
def plot_summary(models,summary=True,model_name=[]):
"""绘制图像并打印summary的函数"""
for idx,model in enumerate(models):
m = model.fit()
if summary:
print("\n")
print(model_name[idx])
print(m.summary(alpha=0.01))
else:
df["model"] = m.predict(start=90,end=103,dynamic=True)
df[['Sales','model']].plot(figsize=(12,2),title="Model {}".format(idx))
plot_summary(arimas,False) #先进行图像的绘制,从预测结果中选出效果可能比较好的参数组合
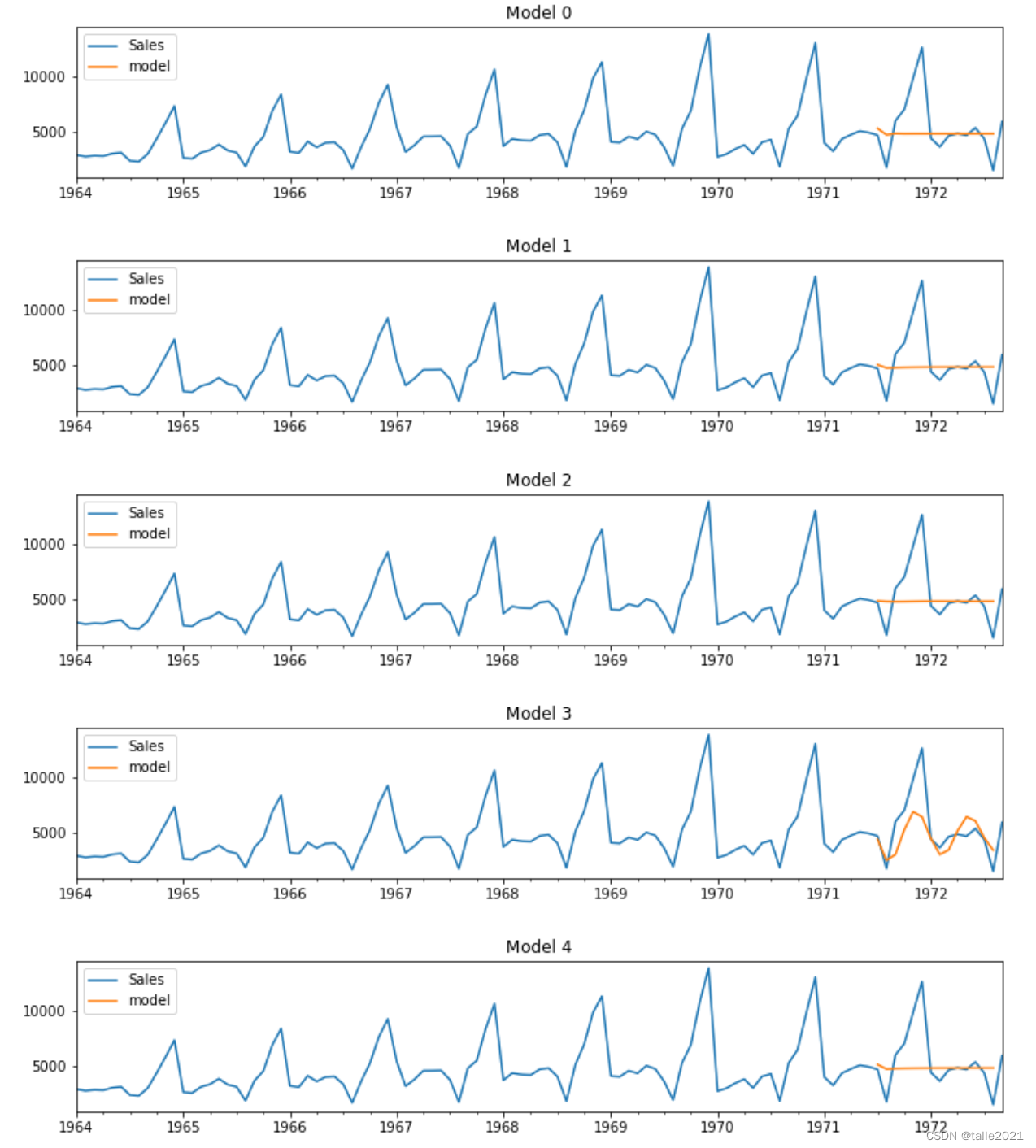
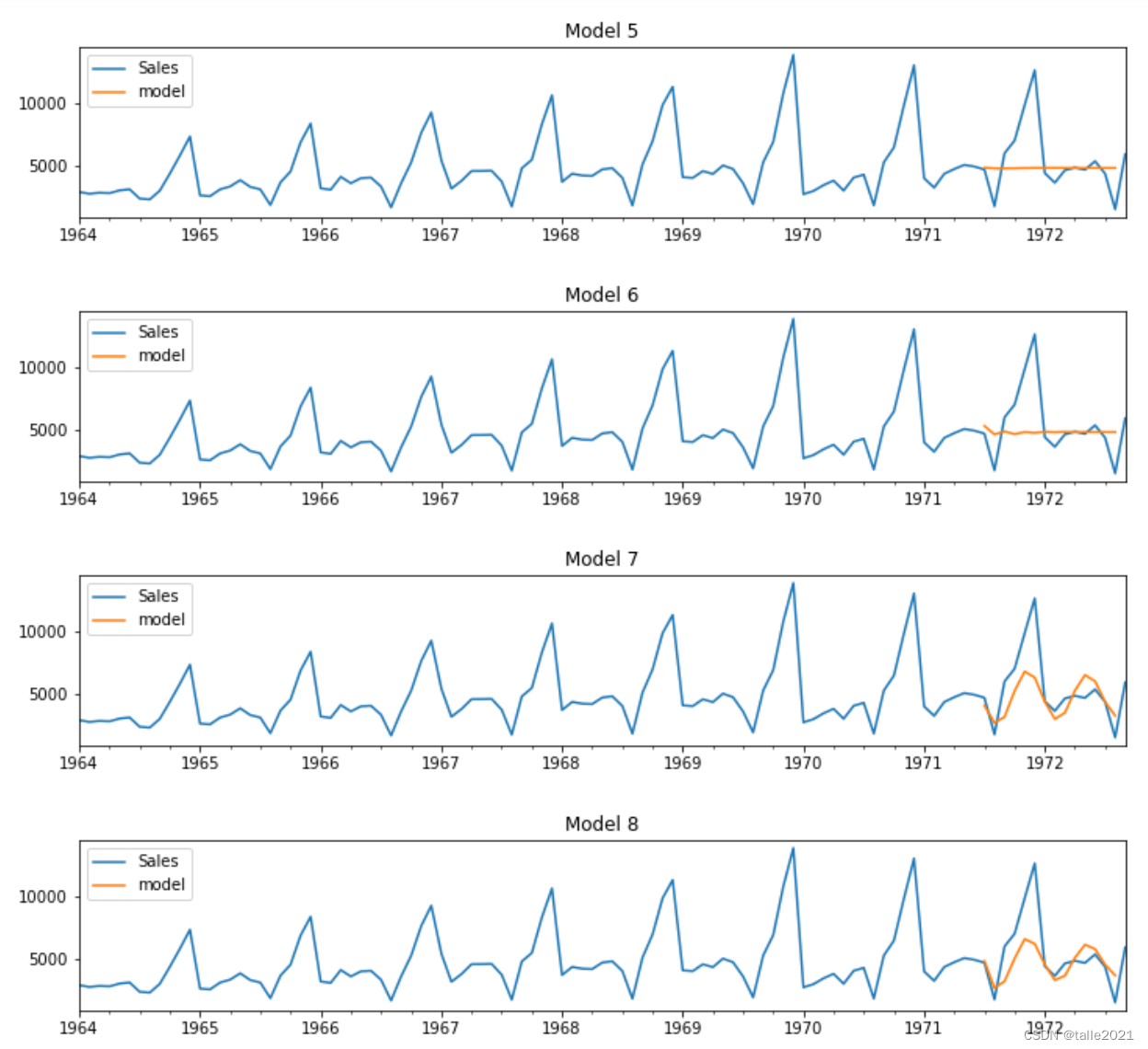
ARIMA系列模型看起来都问题很大,虽然索引为3、7、8的模型大略地捕捉到了一点点趋势,但是和准确的预测比起来还是有很大地差异。因此我们考虑不查看summary,直接继续绘制SARIMA备选模型的图像。
plot_summary(sarimas,False) #先进行图像的绘制,从预测结果中选出效果可能比较好的参数组合
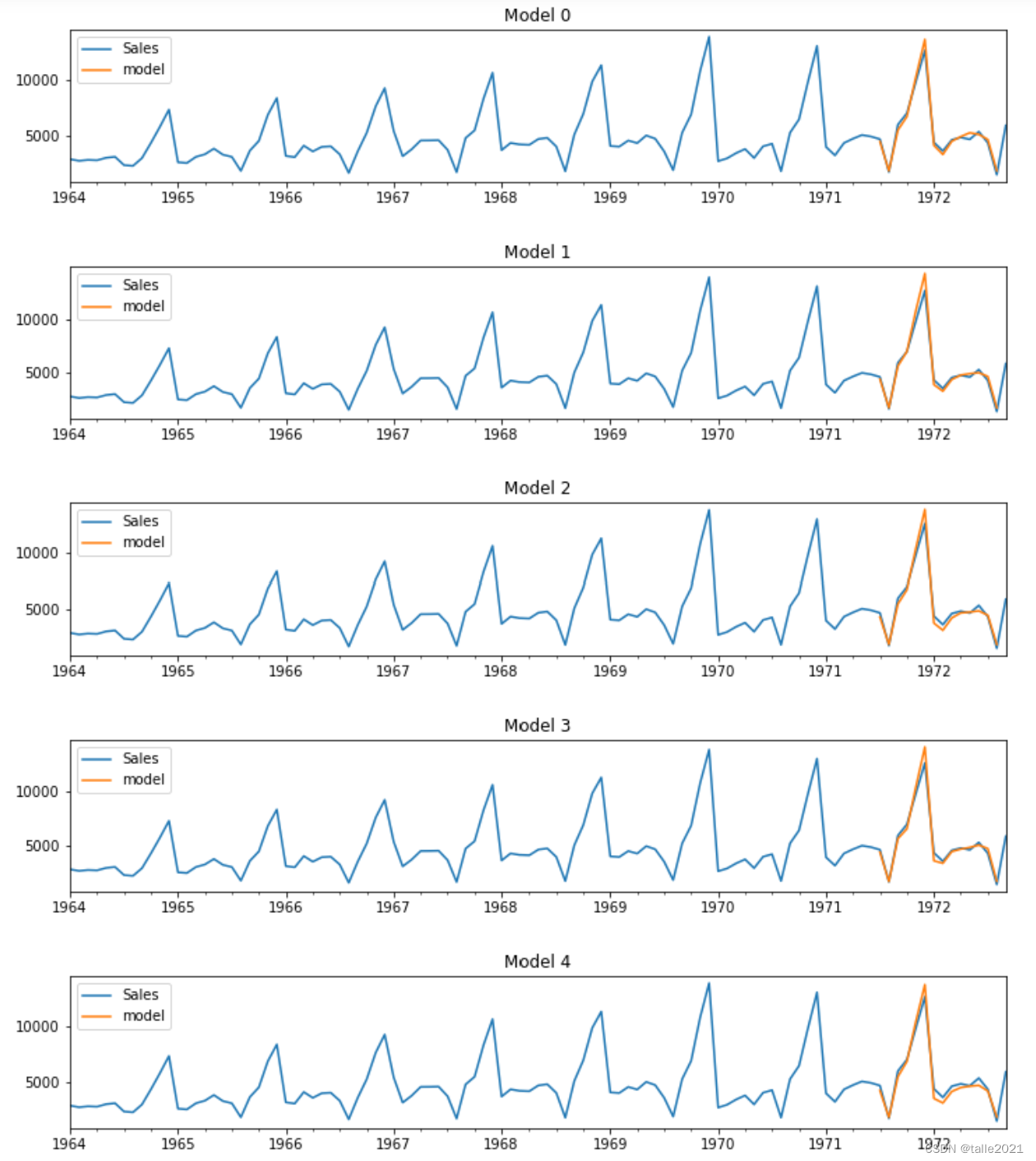
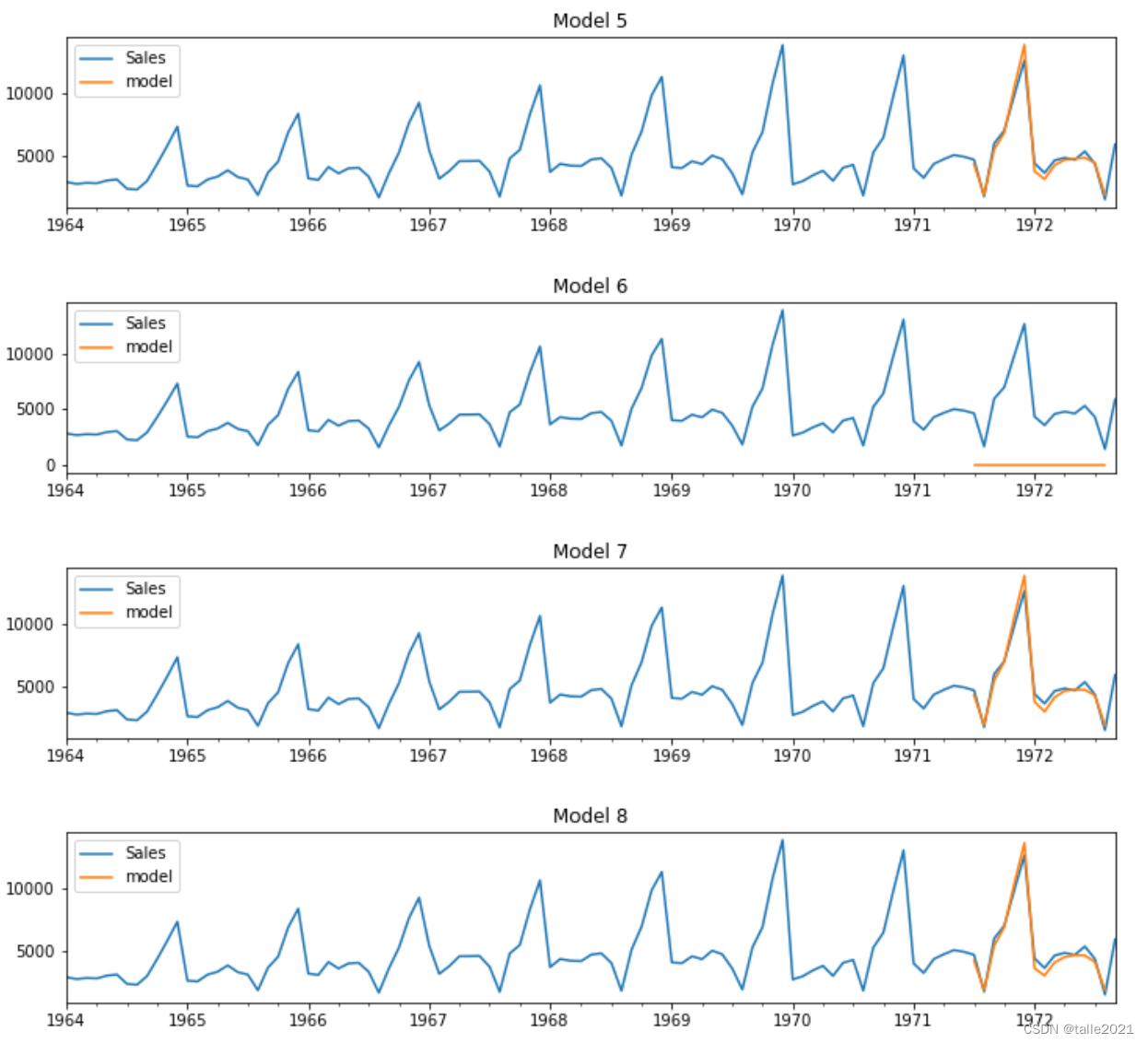
可以看出,SARIMA的情况明显比ARIMA要好很多,除了索引为6的模型看起来明显不可用之外,其他的SARIMA模型看起来都能够较为精准地捕捉到数据的趋势,其中1、2、3、5号模型表现最佳。接下来查看这些SARIMA模型的summary总结,来观察这些模型能否被使用。
#打印较好的参数组合的summary
plot_summary([sarimas[1],sarimas[2],sarimas[3],sarimas[5]]
,model_name=["SARIMA01","SARIMA02","SARIMA03","SARIMA05"])
SARIMA01
SARIMAX Results
===================================================================================
Dep. Variable: Sales No. Observations: 105
Model: ARIMA(1, 1, [1, 2], 12) Log Likelihood -754.700
Date: Mon, 07 Nov 2022 AIC 1517.400
Time: 00:39:04 BIC 1527.530
Sample: 01-01-1964 HQIC 1521.490
- 09-01-1972
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.005 0.995]
------------------------------------------------------------------------------
ar.S.L12 0.9999 0.001 722.272 0.000 0.996 1.004
ma.S.L12 -1.2211 0.065 -18.750 0.000 -1.389 -1.053
ma.S.L24 0.2267 0.012 19.401 0.000 0.197 0.257
sigma2 3.346e+05 2.13e-07 1.57e+12 0.000 3.35e+05 3.35e+05
===================================================================================
Ljung-Box (L1) (Q): 7.95 Jarque-Bera (JB): 8.97
Prob(Q): 0.00 Prob(JB): 0.01
Heteroskedasticity (H): 2.31 Skew: -0.51
Prob(H) (two-sided): 0.02 Kurtosis: 4.14
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[2] Covariance matrix is singular or near-singular, with condition number 5.48e+27. Standard errors may be unstable.
SARIMA02
SARIMAX Results
================================================================================
Dep. Variable: Sales No. Observations: 105
Model: ARIMA(2, 1, [1], 12) Log Likelihood -748.863
Date: Mon, 07 Nov 2022 AIC 1505.725
Time: 00:39:05 BIC 1515.856
Sample: 01-01-1964 HQIC 1509.816
- 09-01-1972
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.005 0.995]
------------------------------------------------------------------------------
ar.S.L12 0.6280 0.304 2.067 0.039 -0.155 1.411
ar.S.L24 0.2032 0.145 1.403 0.161 -0.170 0.576
ma.S.L12 -0.6536 0.303 -2.158 0.031 -1.434 0.127
sigma2 6.321e+05 8.62e+04 7.331 0.000 4.1e+05 8.54e+05
===================================================================================
Ljung-Box (L1) (Q): 5.35 Jarque-Bera (JB): 6.96
Prob(Q): 0.02 Prob(JB): 0.03
Heteroskedasticity (H): 2.24 Skew: -0.29
Prob(H) (two-sided): 0.03 Kurtosis: 4.21
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
SARIMA03
SARIMAX Results
===================================================================================
Dep. Variable: Sales No. Observations: 105
Model: ARIMA(2, 1, [1, 2], 12) Log Likelihood -777.105
Date: Mon, 07 Nov 2022 AIC 1564.210
Time: 00:39:09 BIC 1576.873
Sample: 01-01-1964 HQIC 1569.323
- 09-01-1972
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.005 0.995]
------------------------------------------------------------------------------
ar.S.L12 0.0018 8.19e-05 21.392 0.000 0.002 0.002
ar.S.L24 0.9982 7.8e-05 1.28e+04 0.000 0.998 0.998
ma.S.L12 -0.0231 0.000 -196.782 0.000 -0.023 -0.023
ma.S.L24 -0.9725 0.000 -2002.197 0.000 -0.974 -0.971
sigma2 2.066e+05 1.56e-09 1.32e+14 0.000 2.07e+05 2.07e+05
===================================================================================
Ljung-Box (L1) (Q): 6.35 Jarque-Bera (JB): 11.30
Prob(Q): 0.01 Prob(JB): 0.00
Heteroskedasticity (H): 2.81 Skew: -0.49
Prob(H) (two-sided): 0.01 Kurtosis: 4.40
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[2] Covariance matrix is singular or near-singular, with condition number 1.12e+27. Standard errors may be unstable.
SARIMA05
SARIMAX Results
================================================================================
Dep. Variable: Sales No. Observations: 105
Model: ARIMA(3, 1, [1], 12) Log Likelihood -748.521
Date: Mon, 07 Nov 2022 AIC 1507.042
Time: 00:39:11 BIC 1519.705
Sample: 01-01-1964 HQIC 1512.155
- 09-01-1972
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.005 0.995]
------------------------------------------------------------------------------
ar.S.L12 0.4978 0.432 1.152 0.250 -0.616 1.611
ar.S.L24 0.1899 0.127 1.501 0.133 -0.136 0.516
ar.S.L36 0.0886 0.165 0.538 0.590 -0.335 0.513
ma.S.L12 -0.5404 0.411 -1.316 0.188 -1.598 0.518
sigma2 5.819e+05 7.55e+04 7.706 0.000 3.87e+05 7.76e+05
===================================================================================
Ljung-Box (L1) (Q): 5.46 Jarque-Bera (JB): 6.61
Prob(Q): 0.02 Prob(JB): 0.04
Heteroskedasticity (H): 2.27 Skew: -0.30
Prob(H) (two-sided): 0.03 Kurtosis: 4.16
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
总结一下4个模型的各项检验结果:
| 模型编号 | 模型 | AIC | 系数单变量检验 (alpha=0.01) | 残差相关性检验 (alpha=0.01) | 残差异方差检验 (alpha=0.01) | 残差正态性检验 (alpha=0.01) |
|---|---|---|---|---|---|---|
| 01 | (1,1,2,12) | 1517.400 | ✔ | 不通过 | ✔ | ✔ |
| 02 | (2,1,1,12) | 1505.725 | 不通过 | ✔ | ✔ | ✔ |
| 03 | (2,1,2,12) | 1564.210 | ✔ | ✔ | ✔ | 不通过 |
| 05 | (3,1,1,12) | 1507.042 | 不通过 | ✔ | ✔ | ✔ |
单从AIC来看,02和05号模型有显著的优势,这两个模型都是AR模型的阶数§高于MA模型的阶数(q)的模型,因此我们可以认为当前时间序列数据是更适应于AR模型的。由于更适应当前数据,02和05号模型展现出的情况也更加偏向过拟合:系数单变量检验没有通过,说明模型中的某些项可能与标签无关,模型复杂度高于数据的需求,同时残差的白噪声混成检验全部通过了,说明模型已经提取了尽量多的信息,在学习能力上并无问题。仔细对比02和05号模型的单变量检验结果,不难发现05号模型的系数单变量检验的p值会更高,02号模型虽然也没有通过系数的单变量检验,但相对的p值会更低一些,这说明05号模型的过拟合情况更严重。
相对的,01和03号模型的AIC较高,这两个模型都通过系数的单变量检验,但在残差的白噪声混成检验中出现问题,这说明这两个模型的项中没有多于的项、但模型却没能提取到足够多的信息,因此01和03号模型处于略微欠拟合的状态。
在这种情况下,我们考虑优先从02和05号开始进行改善,如果能够一定程度上降低这两个模型的复杂度,说不定就能够找到能够通过所有检验的模型。那如何改进呢?首先02和05号模型相比,05号模型的AR阶数更高,这说明增加AR阶数后系数的单变量检验更不容易通过,因此我们应该考虑在02号模型上再次降低模型的复杂度。
于是我们提出以下三个模型来进行尝试:
updates = [ARIMA(df["Sales"],seasonal_order=(1,1,1,12)) #00号模型,不过在最初画图的时候没有被我们选出来
,ARIMA(df["Sales"],seasonal_order=(2,0,1,12)) #取消高阶差分
,ARIMA(df["Sales"],seasonal_order=(2,1,1,4)) #降低多步差分的步数
]
plot_summary(updates,False) #先进行图像的绘制,从预测结果中选出效果可能比较好的参数组合
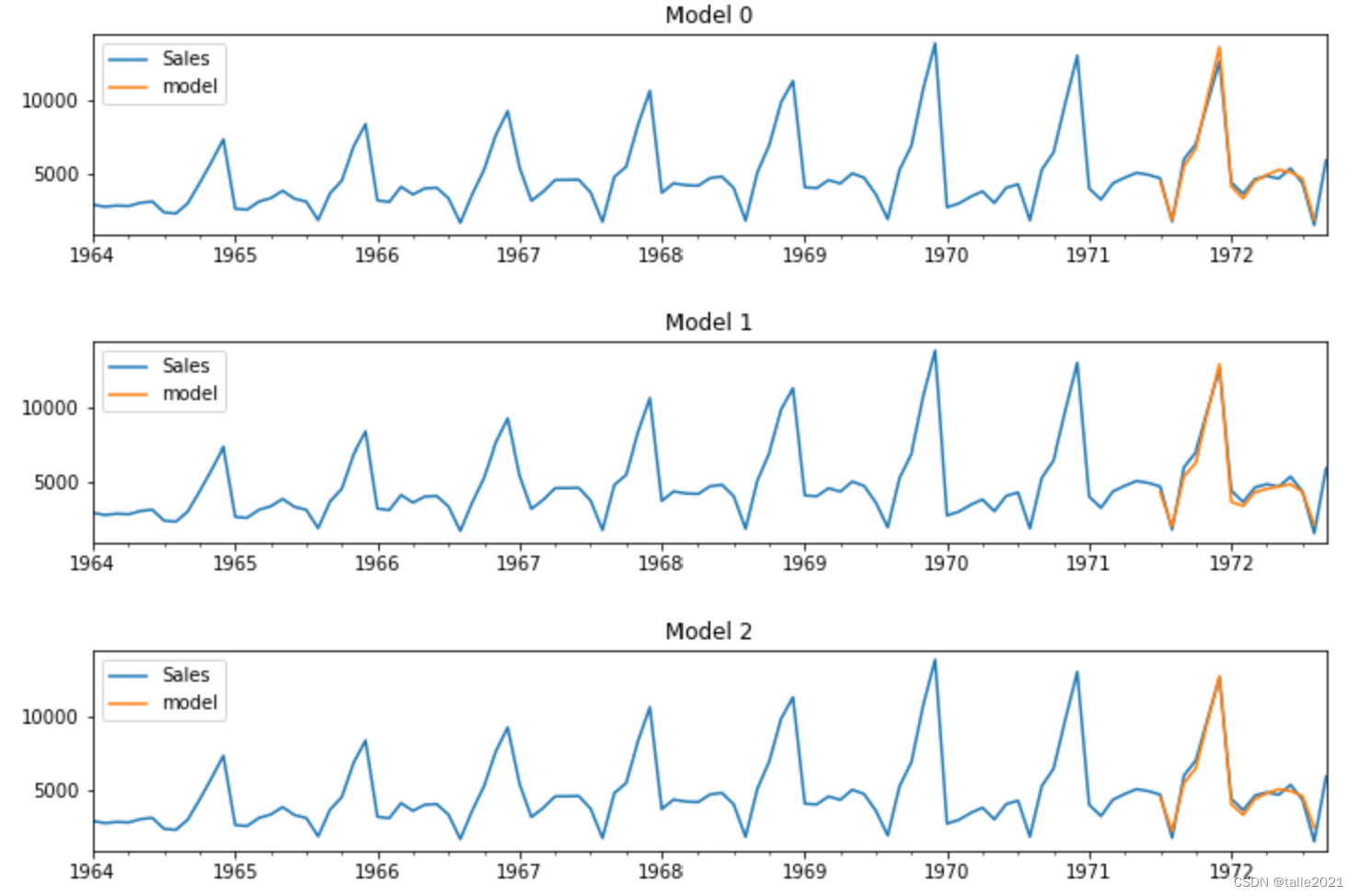
plot_summary(updates,True,["降低p的阶数","降低差分阶数","降低差分步数"])
降低p的阶数
SARIMAX Results
================================================================================
Dep. Variable: Sales No. Observations: 105
Model: ARIMA(1, 1, [1], 12) Log Likelihood -750.716
Date: Fri, 04 Nov 2022 AIC 1507.432
Time: 22:44:41 BIC 1515.030
Sample: 01-01-1964 HQIC 1510.500
- 09-01-1972
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.005 0.995]
------------------------------------------------------------------------------
ar.S.L12 0.9804 0.127 7.709 0.000 0.653 1.308
ma.S.L12 -0.9228 0.281 -3.288 0.001 -1.646 -0.200
sigma2 5.969e+05 1.06e+05 5.625 0.000 3.24e+05 8.7e+05
===================================================================================
Ljung-Box (L1) (Q): 4.22 Jarque-Bera (JB): 8.04
Prob(Q): 0.04 Prob(JB): 0.02
Heteroskedasticity (H): 2.29 Skew: -0.27
Prob(H) (two-sided): 0.02 Kurtosis: 4.33
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
降低差分阶数
SARIMAX Results
================================================================================
Dep. Variable: Sales No. Observations: 105
Model: ARIMA(2, 0, [1], 12) Log Likelihood -863.134
Date: Fri, 04 Nov 2022 AIC 1736.269
Time: 22:44:42 BIC 1749.539
Sample: 01-01-1964 HQIC 1741.646
- 09-01-1972
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.005 0.995]
------------------------------------------------------------------------------
const 4759.7849 865.591 5.499 0.000 2530.171 6989.399
ar.S.L12 -0.0444 0.050 -0.885 0.376 -0.174 0.085
ar.S.L24 0.9528 0.026 36.663 0.000 0.886 1.020
ma.S.L12 0.9814 0.198 4.946 0.000 0.470 1.492
sigma2 5.778e+05 0.002 2.75e+08 0.000 5.78e+05 5.78e+05
===================================================================================
Ljung-Box (L1) (Q): 11.83 Jarque-Bera (JB): 7.38
Prob(Q): 0.00 Prob(JB): 0.03
Heteroskedasticity (H): 2.24 Skew: 0.28
Prob(H) (two-sided): 0.02 Kurtosis: 4.17
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[2] Covariance matrix is singular or near-singular, with condition number 1.65e+27. Standard errors may be unstable.
降低差分步数
SARIMAX Results
===============================================================================
Dep. Variable: Sales No. Observations: 105
Model: ARIMA(2, 1, [1], 4) Log Likelihood -855.998
Date: Fri, 04 Nov 2022 AIC 1719.996
Time: 22:44:42 BIC 1730.457
Sample: 01-01-1964 HQIC 1724.231
- 09-01-1972
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.005 0.995]
------------------------------------------------------------------------------
ar.S.L4 -0.9877 0.040 -24.678 0.000 -1.091 -0.885
ar.S.L8 -0.9678 0.021 -46.140 0.000 -1.022 -0.914
ma.S.L4 0.1253 0.161 0.777 0.437 -0.290 0.540
sigma2 8.886e+05 9.36e+04 9.489 0.000 6.47e+05 1.13e+06
===================================================================================
Ljung-Box (L1) (Q): 15.85 Jarque-Bera (JB): 139.28
Prob(Q): 0.00 Prob(JB): 0.00
Heteroskedasticity (H): 0.43 Skew: 1.46
Prob(H) (two-sided): 0.02 Kurtosis: 7.96
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
结果总结如下:
| 模型编号 | 模型 | AIC | 系数单变量检验 (alpha=0.01) | 残差相关性检验 (alpha=0.01) | 残差异方差检验 (alpha=0.01) | 残差正态性检验 (alpha=0.01) |
|---|---|---|---|---|---|---|
| 原始模型 | (2,1,1,12) | 1505.725 | 不通过 | ✔ | ✔ | ✔ |
| 降低AR的阶数 | (1,1,1,12) | 1507.432 | ✔ | ✔ | ✔ | ✔ |
| 降低差分阶数 | (2,0,1,12) | 1736.269 | 不通过 | 不通过 | ✔ | ✔ |
| 降低差分步数 | (2,1,1,4) | 1719.996 | 不通过 | 不通过 | ✔ | 不通过 |
不难发现,SARIMA(1,1,1,12)模型可以通过所有的检验、并拿到一个较低的AIC分数,如此就可以确定SARIMA(1,1,1,12)为当前最合适的模型。相比之下,随意降低差分阶数、或是降低我们之前使用差分运算确定好的差分步数,可能大规模破坏模型的原始假设。因此当模型的复杂度遭遇问题时,需要尽量在p和q上来进行调整,而不要改变已经确定好的差分步数和阶数。