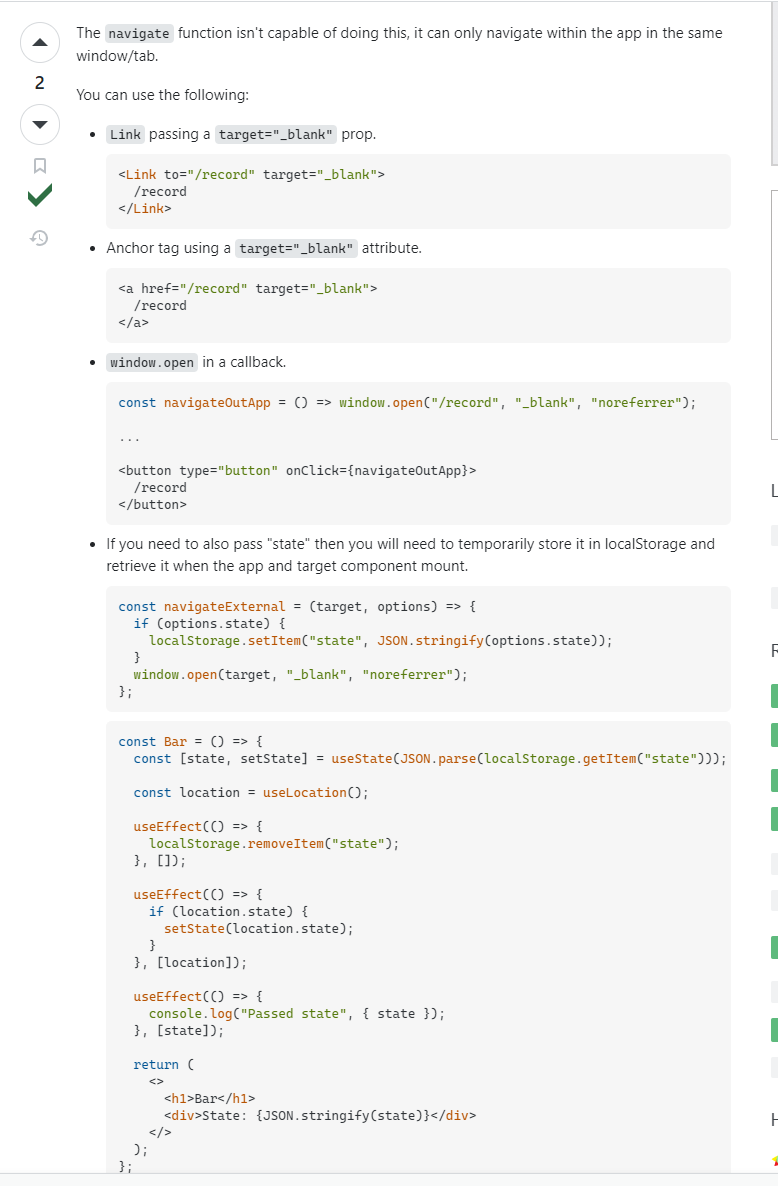
文章目录
FashionMNIST数据集 需求库导入、数据迭代器生成 设备选择 样例图片展示 日志写入 评估—计数器 模型构建 训练函数 整体代码 训练过程 日志
FashionMNIST(时尚 MNIST)是一个用于图像分类的数据集,旨在替代传统的手写数字MNIST数据集。它由 Zalando Research 创建,适用于深度学习和计算机视觉的实验。
FashionMNIST 包含 10 个类别,分别对应不同的时尚物品。这些类别包括 T恤/上衣、裤子、套头衫、裙子、外套、凉鞋、衬衫、运动鞋、包和踝靴。 每个类别有 6,000 张训练图像和 1,000 张测试图像,总计 70,000 张图像。 每张图像的尺寸为 28x28 像素,与MNIST数据集相同。 数据集中的每个图像都是灰度图像,像素值在0到255之间。 import os
import random
import numpy as np
import datetime
import torch
import torch. nn as nn
from torch. utils. data import DataLoader
import torchvision
from torchvision import transforms
import argparse
from tqdm import tqdm
import matplotlib. pyplot as plt
from torch. utils. tensorboard import SummaryWriter
def _load_data ( ) :
"""download the data, and generate the dataloader"""
trans = transforms. Compose( [ transforms. ToTensor( ) ] )
train_dataset = torchvision. datasets. FashionMNIST( root= './data/' , train= True , download= True , transform= trans)
test_dataset = torchvision. datasets. FashionMNIST( root= './data/' , train= False , download= True , transform= trans)
train_loader = DataLoader( train_dataset, shuffle= True , batch_size= args. batch_size, num_workers= args. num_works)
test_loader = DataLoader( test_dataset, shuffle= True , batch_size= args. batch_size, num_workers= args. num_works)
return ( train_loader, test_loader)
def _device ( ) :
device = torch. device( "cuda" if torch. cuda. is_available( ) else "cpu" )
return device
"""display data examples"""
def _image_label ( labels) :
text_labels = [ 't-shirt' , 'trouser' , 'pullover' , 'dress' , 'coat' ,
'sandal' , 'shirt' , 'sneaker' , 'bag' , 'ankle boot' ]
return [ text_labels[ int ( i) ] for i in labels]
def _show_images ( imgs, rows, columns, titles= None , scale= 1.5 ) :
figsize = ( rows * scale, columns * 1.5 )
fig, axes = plt. subplots( rows, columns, figsize= figsize)
axes = axes. flatten( )
for i, ( img, ax) in enumerate ( zip ( imgs, axes) ) :
ax. imshow( img)
ax. axes. get_xaxis( ) . set_visible( False )
ax. axes. get_yaxis( ) . set_visible( False )
if titles:
ax. set_title( titles[ i] )
plt. show( )
return axes
def _show_examples ( ) :
train_loader, test_loader = _load_data( )
for images, labels in train_loader:
images = images. squeeze( 1 )
_show_images( images, 3 , 3 , _image_label( labels) )
break
class _logger ( ) :
def __init__ ( self, log_dir, log_history= True ) :
if log_history:
log_dir = os. path. join( log_dir, datetime. datetime. now( ) . strftime( "%Y_%m_%d__%H_%M_%S" ) )
self. summary = SummaryWriter( log_dir)
def scalar_summary ( self, tag, value, step) :
self. summary. add_scalars( tag, value, step)
def images_summary ( self, tag, image_tensor, step) :
self. summary. add_images( tag, image_tensor, step)
def figure_summary ( self, tag, figure, step) :
self. summary. add_figure( tag, figure, step)
def graph_summary ( self, model) :
self. summary. add_graph( model)
def close ( self) :
self. summary. close( )
class AverageMeter ( ) :
def __init__ ( self) :
self. reset( )
def reset ( self) :
self. val = 0
self. avg = 0
self. sum = 0
self. count = 0
def update ( self, val, n= 1 ) :
self. val = val
self. sum += val * n
self. count += n
self. avg = self. sum / self. count
class Conv3x3 ( nn. Module) :
def __init__ ( self, in_channels, out_channels, down_sample= False ) :
super ( Conv3x3, self) . __init__( )
self. conv = nn. Sequential( nn. Conv2d( in_channels, out_channels, 3 , 1 , 1 ) ,
nn. BatchNorm2d( out_channels) ,
nn. ReLU( inplace= True ) ,
nn. Conv2d( out_channels, out_channels, 3 , 1 , 1 ) ,
nn. BatchNorm2d( out_channels) ,
nn. ReLU( inplace= True ) )
if down_sample:
self. conv[ 3 ] = nn. Conv2d( out_channels, out_channels, 2 , 2 , 0 )
def forward ( self, x) :
return self. conv( x)
class SimpleNet ( nn. Module) :
def __init__ ( self, in_channels, out_channels) :
super ( SimpleNet, self) . __init__( )
self. conv1 = Conv3x3( in_channels, 32 )
self. conv2 = Conv3x3( 32 , 64 , down_sample= True )
self. conv3 = Conv3x3( 64 , 128 )
self. conv4 = Conv3x3( 128 , 256 , down_sample= True )
self. fc = nn. Linear( 256 * 7 * 7 , out_channels)
def forward ( self, x) :
x = self. conv1( x)
x = self. conv2( x)
x = self. conv3( x)
x = self. conv4( x)
x = torch. flatten( x, 1 )
out = self. fc( x)
return out
def train ( model, train_loader, test_loader, criterion, optimizor, epochs, device, writer, save_weight= False ) :
train_loss = AverageMeter( )
test_loss = AverageMeter( )
train_precision = AverageMeter( )
test_precision = AverageMeter( )
time_tick = datetime. datetime. now( ) . strftime( "%Y_%m_%d__%H_%M_%S" )
for epoch in range ( epochs) :
print ( '\nEpoch: [%d | %d] LR: %f' % ( epoch + 1 , args. epochs, args. lr) )
model. train( )
for input , label in tqdm( train_loader) :
input , label = input . to( device) , label. to( device)
output = model( input )
loss = criterion( output, label)
optimizor. zero_grad( )
loss. backward( )
optimizor. step( )
predict = torch. argmax( output, dim= 1 )
train_pre = sum ( predict == label) / len ( label)
train_loss. update( loss. item( ) , input . size( 0 ) )
train_precision. update( train_pre. item( ) , input . size( 0 ) )
model. eval ( )
with torch. no_grad( ) :
for X, y in tqdm( test_loader) :
X, y = X. to( device) , y. to( device)
y_hat = model( X)
loss_te = criterion( y_hat, y)
predict_ = torch. argmax( y_hat, dim= 1 )
test_pre = sum ( predict_ == y) / len ( y)
test_loss. update( loss_te. item( ) , X. size( 0 ) )
test_precision. update( test_pre. item( ) , X. size( 0 ) )
if save_weight:
best_dice = args. best_dice
weight_dir = os. path. join( args. weight_dir, args. model, time_tick)
os. makedirs( weight_dir, exist_ok= True )
monitor_dice = test_precision. avg
if monitor_dice > best_dice:
best_dice = max ( monitor_dice, best_dice)
name = os. path. join( weight_dir, args. model + '_' + str ( epoch) + \
'_test_loss-' + str ( round ( test_loss. avg, 4 ) ) + \
'_test_dice-' + str ( round ( best_dice, 4 ) ) + '.pt' )
torch. save( model. state_dict( ) , name)
print ( "train" + '---Loss: {loss:.4f} | Dice: {dice:.4f}' . format ( loss= train_loss. avg, dice= train_precision. avg) )
print ( "test " + '---Loss: {loss:.4f} | Dice: {dice:.4f}' . format ( loss= test_loss. avg, dice= test_precision. avg) )
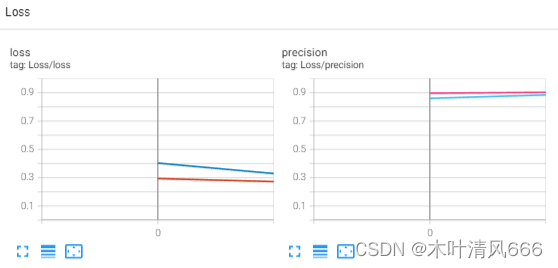
writer. scalar_summary( "Loss/loss" , { "train" : train_loss. avg, "test" : test_loss. avg} , epoch)
writer. scalar_summary( "Loss/precision" , { "train" : train_precision. avg, "test" : test_precision. avg} , epoch)
writer. close( )
import os
import random
import numpy as np
import datetime
import torch
import torch. nn as nn
from torch. utils. data import DataLoader
import torchvision
from torchvision import transforms
import argparse
from tqdm import tqdm
import matplotlib. pyplot as plt
from torch. utils. tensorboard import SummaryWriter
"""Reproduction experiment"""
def setup_seed ( seed) :
random. seed( seed)
np. random. seed( seed)
torch. manual_seed( seed)
torch. cuda. manual_seed( seed)
torch. cuda. manual_seed_all( seed)
"""data related"""
def _base_options ( ) :
parser = argparse. ArgumentParser( description= "Train setting for FashionMNIST" )
parser. add_argument( '--batch_size' , default= 8 , type = int , help = 'the batch size of dataset' )
parser. add_argument( '--num_works' , default= 4 , type = int , help = "the num_works used" )
parser. add_argument( '--epochs' , default= 100 , type = int , help = 'train iterations' )
parser. add_argument( '--lr' , default= 0.001 , type = float , help = 'learning rate' )
parser. add_argument( '--model' , default= "SimpleNet" , choices= [ "SimpleNet" ] , help = "the model choosed" )
parser. add_argument( '--log_dir' , default= "./logger/" , help = 'the path of log file' )
parser. add_argument( '--best_dice' , default= - 100 , type = int , help = 'for save weight' )
parser. add_argument( '--weight_dir' , default= "./weight/" , help = 'the dir for save weight' )
args = parser. parse_args( )
return args
def _load_data ( ) :
"""download the data, and generate the dataloader"""
trans = transforms. Compose( [ transforms. ToTensor( ) ] )
train_dataset = torchvision. datasets. FashionMNIST( root= './data/' , train= True , download= True , transform= trans)
test_dataset = torchvision. datasets. FashionMNIST( root= './data/' , train= False , download= True , transform= trans)
train_loader = DataLoader( train_dataset, shuffle= True , batch_size= args. batch_size, num_workers= args. num_works)
test_loader = DataLoader( test_dataset, shuffle= True , batch_size= args. batch_size, num_workers= args. num_works)
return ( train_loader, test_loader)
def _device ( ) :
device = torch. device( "cuda" if torch. cuda. is_available( ) else "cpu" )
return device
"""display data examples"""
def _image_label ( labels) :
text_labels = [ 't-shirt' , 'trouser' , 'pullover' , 'dress' , 'coat' ,
'sandal' , 'shirt' , 'sneaker' , 'bag' , 'ankle boot' ]
return [ text_labels[ int ( i) ] for i in labels]
def _show_images ( imgs, rows, columns, titles= None , scale= 1.5 ) :
figsize = ( rows * scale, columns * 1.5 )
fig, axes = plt. subplots( rows, columns, figsize= figsize)
axes = axes. flatten( )
for i, ( img, ax) in enumerate ( zip ( imgs, axes) ) :
ax. imshow( img)
ax. axes. get_xaxis( ) . set_visible( False )
ax. axes. get_yaxis( ) . set_visible( False )
if titles:
ax. set_title( titles[ i] )
plt. show( )
return axes
def _show_examples ( ) :
train_loader, test_loader = _load_data( )
for images, labels in train_loader:
images = images. squeeze( 1 )
_show_images( images, 3 , 3 , _image_label( labels) )
break
"""log"""
class _logger ( ) :
def __init__ ( self, log_dir, log_history= True ) :
if log_history:
log_dir = os. path. join( log_dir, datetime. datetime. now( ) . strftime( "%Y_%m_%d__%H_%M_%S" ) )
self. summary = SummaryWriter( log_dir)
def scalar_summary ( self, tag, value, step) :
self. summary. add_scalars( tag, value, step)
def images_summary ( self, tag, image_tensor, step) :
self. summary. add_images( tag, image_tensor, step)
def figure_summary ( self, tag, figure, step) :
self. summary. add_figure( tag, figure, step)
def graph_summary ( self, model) :
self. summary. add_graph( model)
def close ( self) :
self. summary. close( )
"""evaluate the result"""
class AverageMeter ( ) :
def __init__ ( self) :
self. reset( )
def reset ( self) :
self. val = 0
self. avg = 0
self. sum = 0
self. count = 0
def update ( self, val, n= 1 ) :
self. val = val
self. sum += val * n
self. count += n
self. avg = self. sum / self. count
"""define the Net"""
class Conv3x3 ( nn. Module) :
def __init__ ( self, in_channels, out_channels, down_sample= False ) :
super ( Conv3x3, self) . __init__( )
self. conv = nn. Sequential( nn. Conv2d( in_channels, out_channels, 3 , 1 , 1 ) ,
nn. BatchNorm2d( out_channels) ,
nn. ReLU( inplace= True ) ,
nn. Conv2d( out_channels, out_channels, 3 , 1 , 1 ) ,
nn. BatchNorm2d( out_channels) ,
nn. ReLU( inplace= True ) )
if down_sample:
self. conv[ 3 ] = nn. Conv2d( out_channels, out_channels, 2 , 2 , 0 )
def forward ( self, x) :
return self. conv( x)
class SimpleNet ( nn. Module) :
def __init__ ( self, in_channels, out_channels) :
super ( SimpleNet, self) . __init__( )
self. conv1 = Conv3x3( in_channels, 32 )
self. conv2 = Conv3x3( 32 , 64 , down_sample= True )
self. conv3 = Conv3x3( 64 , 128 )
self. conv4 = Conv3x3( 128 , 256 , down_sample= True )
self. fc = nn. Linear( 256 * 7 * 7 , out_channels)
def forward ( self, x) :
x = self. conv1( x)
x = self. conv2( x)
x = self. conv3( x)
x = self. conv4( x)
x = torch. flatten( x, 1 )
out = self. fc( x)
return out
"""progress of train/test"""
def train ( model, train_loader, test_loader, criterion, optimizor, epochs, device, writer, save_weight= False ) :
train_loss = AverageMeter( )
test_loss = AverageMeter( )
train_precision = AverageMeter( )
test_precision = AverageMeter( )
time_tick = datetime. datetime. now( ) . strftime( "%Y_%m_%d__%H_%M_%S" )
for epoch in range ( epochs) :
print ( '\nEpoch: [%d | %d] LR: %f' % ( epoch + 1 , args. epochs, args. lr) )
model. train( )
for input , label in tqdm( train_loader) :
input , label = input . to( device) , label. to( device)
output = model( input )
loss = criterion( output, label)
optimizor. zero_grad( )
loss. backward( )
optimizor. step( )
predict = torch. argmax( output, dim= 1 )
train_pre = sum ( predict == label) / len ( label)
train_loss. update( loss. item( ) , input . size( 0 ) )
train_precision. update( train_pre. item( ) , input . size( 0 ) )
model. eval ( )
with torch. no_grad( ) :
for X, y in tqdm( test_loader) :
X, y = X. to( device) , y. to( device)
y_hat = model( X)
loss_te = criterion( y_hat, y)
predict_ = torch. argmax( y_hat, dim= 1 )
test_pre = sum ( predict_ == y) / len ( y)
test_loss. update( loss_te. item( ) , X. size( 0 ) )
test_precision. update( test_pre. item( ) , X. size( 0 ) )
if save_weight:
best_dice = args. best_dice
weight_dir = os. path. join( args. weight_dir, args. model, time_tick)
os. makedirs( weight_dir, exist_ok= True )
monitor_dice = test_precision. avg
if monitor_dice > best_dice:
best_dice = max ( monitor_dice, best_dice)
name = os. path. join( weight_dir, args. model + '_' + str ( epoch) + \
'_test_loss-' + str ( round ( test_loss. avg, 4 ) ) + \
'_test_dice-' + str ( round ( best_dice, 4 ) ) + '.pt' )
torch. save( model. state_dict( ) , name)
print ( "train" + '---Loss: {loss:.4f} | Dice: {dice:.4f}' . format ( loss= train_loss. avg, dice= train_precision. avg) )
print ( "test " + '---Loss: {loss:.4f} | Dice: {dice:.4f}' . format ( loss= test_loss. avg, dice= test_precision. avg) )
writer. scalar_summary( "Loss/loss" , { "train" : train_loss. avg, "test" : test_loss. avg} , epoch)
writer. scalar_summary( "Loss/precision" , { "train" : train_precision. avg, "test" : test_precision. avg} , epoch)
writer. close( )
if __name__ == "__main__" :
args = _base_options( )
device = _device( )
train_loader, test_loader = _load_data( )
writer = _logger( log_dir= os. path. join( args. log_dir, args. model) )
model = SimpleNet( in_channels= 1 , out_channels= 10 ) . to( device)
optimizor = torch. optim. Adam( model. parameters( ) , lr= args. lr)
criterion = nn. CrossEntropyLoss( )
train( model, train_loader, test_loader, criterion, optimizor, args. epochs, device, writer, save_weight= True )
"""
args = _base_options()
_show_examples() # ———> 样例图片显示
"""