一般来说,解释型编程语言都是依靠自身运行的虚拟机,在解释程序。有时候语言为了提高运行速度,不会去直接解释程序文本,而是模拟cpu执行方式,将文本代码执行一次翻译,翻译为类似cpu执行的汇编语言去执行。有些语言会模拟出几个CPU的寄存器,有些则使用栈的方式模拟寄存器。无论采用什么方式,基本都是循环读取文件的内容,按照一定规则去解释。这也就导致了,运行速度会慢一点,因为cpu最终执行的是虚拟机,而不是编写的语言。
通常,一个解释型编程语言如果想要运行速度提升,除了对自身代码的优化和对虚拟机的优化外,就是要让代码本身可以让CPU直接能执行语言,也就是说,将编写的语言,经过几次翻译后,变为可以直接在cpu中执行的代码,这个就是jit
实现JIT最重要的一步就是动态执行被翻译成汇编的代码,下面是一个最简单的动态执行汇编的方式
1.动态执行
1.1在linux相关系统中
注:以下代码在cygwin gcc 11.3中调试通过
有如下代码
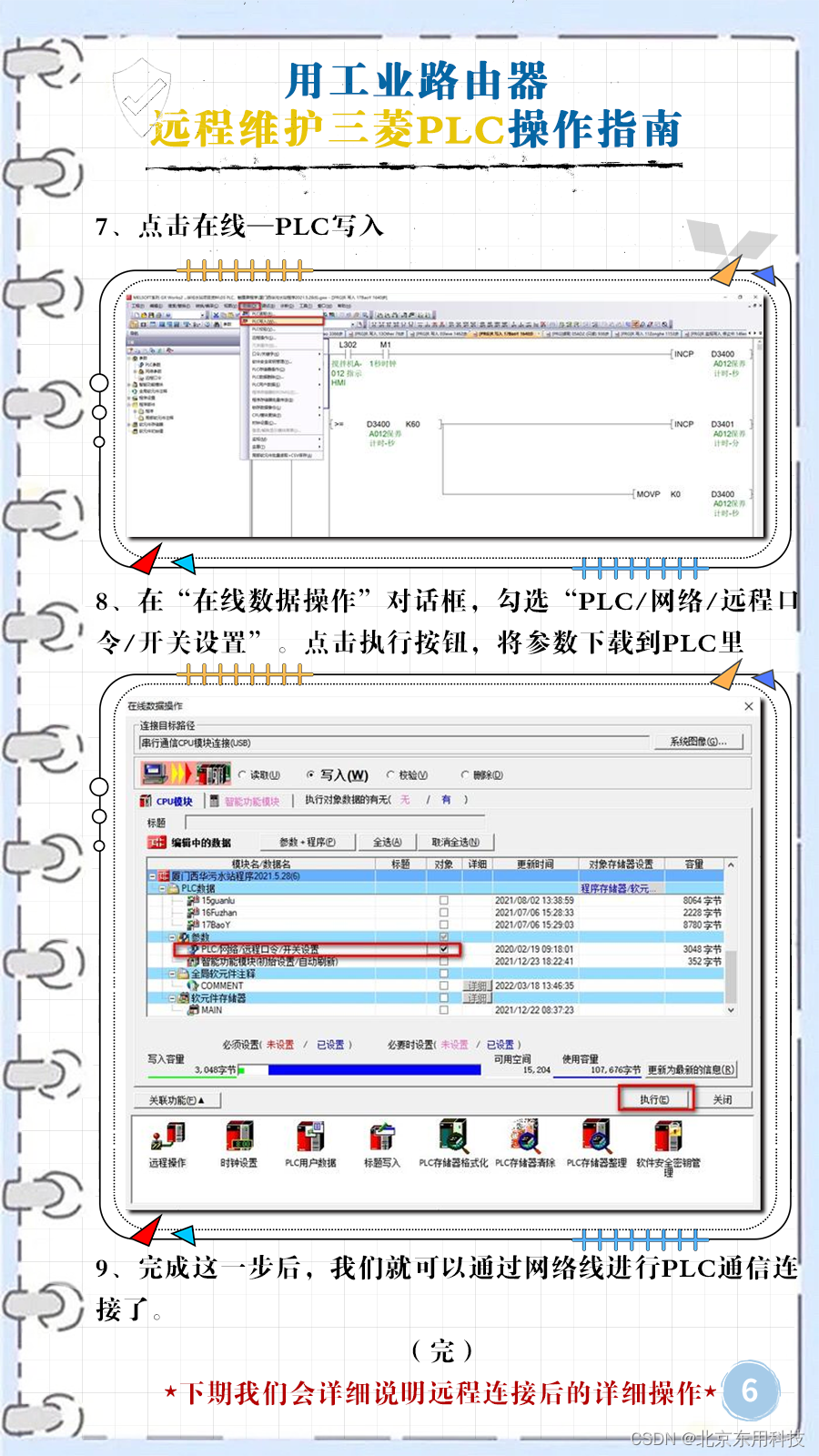
int func()
{
return 19;
}
int main(int, char**) {
printf("%d",func());
}
以上代码很简单,执行func函数返回19.然后打印出来
不过,如果func函数没有参与编译,是在程序运行时产生的,比如是从文件读取,或者人工输入,或者源文件在运行时,才被编译为字节码时,这就需要用下面的方式执行了
int main(int, char**)
{
unsigned char code[] = { 0xB8,0x13,0x00,0x00,0x00,0xC3 };
void *mem = mmap(NULL, sizeof(code), PROT_WRITE | PROT_EXEC,MAP_ANON | MAP_PRIVATE, -1, 0);
memcpy(mem, code, sizeof(code));
int(*func)() = (int(*)())mem;
printf("%d",func());
munmap(mem,sizeof(code));
return 0;
}
逐行解释一下
{ 0xB8,0x13,0x00,0x00,0x00,0xC3 };
就是return 19 翻译为汇编后的字节码,B8 是mov,C3是return
mmap是内存映射函数,它的作用就是给开拓一块大小为sizeof(code)的空间。但是这一步还不能用其他分配内存函数实现,比如,如果mmap改成malloc就不行,执行会报错,应为mmap分配的空间,是可以为这个空间设置属性的,比如可以写入PROT_WRITE |,可以执行PROT_EXEC,
int(*func)() = (int(*)())mem;
memcpy就是把要执行的汇编代码复制到这块内存里,这句是要把mmap分配的内存让他指向一个函数执行,然后通过函数执行的方式去调用内存中的代码
munmap就是吧mmap分配的内存释放了
这个就是最简单的一个动态运行方式。
1.2在windows中
如果要在windows下运行的话,mmap函数在windows里好像是没有,就需要换成VirtualAlloc,不过功能是一样的
unsigned char code[] = { 0xB8,0x13,0x00,0x00,0x00,0xC3 };
void* mem = VirtualAlloc(0, sizeof(code), MEM_COMMIT, PAGE_EXECUTE_READWRITE);
memcpy(mem, code, sizeof(code));
int(*func)() = (int(*)())mem;
int r = func();
VirtualFree(code, sizeof(code), MEM_RELEASE);
2.JIT框架xbyak
虽然从汇编翻译字节码的过程也可以自己实现,但这个过程还是比较复杂,汇编指令很多,每个指令都有自己的字节码,要记录下就很困难,但是使用了框架就会省事很多,jit框架很多,dynasm、asmjit等
还有一个 xbyak
xbyak是一个非常简单的可以跨平台的jit框架,使用C++编写,一共四个文件,不到400k。
使用时,直接在项目中直接引入xbyak.h即可。
使用xbyak编写,实际上就是写汇编,比如如下汇编
mov eax,1
ret
改为xbyak,如下
mov(eax,1)
ret()
xbyak的函数和汇编的指令是对应的,大部分写的时候改成函数调用就可以
注:以下代码在win10 vs2015中调试通过,代码仅作测试使用
2.1基本使用
从最简单的开始,首先创建xbyak使用的类
class generatorcode : public Xbyak::CodeGenerator
{
public:
generatorcode(void *userPtr = 0, size_t size = Xbyak::DEFAULT_MAX_CODE_SIZE) : Xbyak::CodeGenerator(size, userPtr)
{
}
}
然后用xbyak改写return 19那段代码
class generatorcode : public Xbyak::CodeGenerator
{
public:
generatorcode(void *userPtr *= 0, size_t size = Xbyak::DEFAULT_MAX_CODE_SIZE) : Xbyak::CodeGenerator(size, userPtr)
{
}
void func()
{
mov(eax,19);
ret();
}
}
int main(int, char**) {
generatorcode g;
g.func();
int(*func)() = g.getCode<int(*)()>();
printf("%d", func());
return 0;
}
运行结果是一样的
虽然加了一个类,但相同功能整个实现过程方便了不少
下面介绍一下xbyak的基本数据操作
2.2常用数据类型
代码如下,分别把int,double ,char* 存到一个struct中
struct datatable {
int i;
double d;
char* c;
};
class generatorcode : public Xbyak::CodeGenerator
{
private:
datatable * dt;
public:
generatorcode(datatable* _dt) : Xbyak::CodeGenerator()
{
dt = _dt;
}
void endcode()
{
ret();
}
void funcint(int a)
{
mov(eax, dword[&dt]);
mov(dword[eax],a);
}
void funcstr(char* a)
{
mov(eax, dword[&dt]);
lea(ecx, dword[a]);
mov(dword[eax+16],ecx);
}
void funcdouble(double *a)
{
mov(eax, dword[&dt]);
movsd(xm0, qword[a]);
movsd(qword[eax+8], xm0);
}
};
int main(int, char**) {
datatable * dt = new datatable();
generatorcode g(dt);
int a = 8;
double b = 3.14;
char* str = "aaa";
g.funcint(8);
g.funcdouble(&b);
g.funcstr(str);
g.endcode();
int(*func)() = g.getCode<int(*)()>();
func();
return 1;
}
结构dt运行结果如下:

常用的也就这几中数据类型的操作
xbyak的写法更接近NASM的写法,32,64位都支持,也支持MASM的一些语法,比如@@标号,同时也支持AVX,基本上用汇编写程序的指令它这都有。
qword, dword, word,byte 这几个是xbyak数据类型,如果使用的时候确认不了,就写PTR
2.3函数调用
再介绍几个常用的汇编指令,push,pop,call这几个会涉及到函数调用
class generatorcode : public Xbyak::CodeGenerator
{
public:
generatorcode() : Xbyak::CodeGenerator()
{
}
void endcode()
{
ret();
}
void abc(int a,char* b)
{
push(a);
lea(ecx, dword[b]);
push(ecx);
call(printf);
pop(ebx);
pop(ebx);
}
};
int main(int, char**) {
generatorcode g();
int a = 8;
char* str = "%d";
g.abc(a, str);
g.endcode();
int(*func)() = g.getCode<int(*)()>();
func();
return 1;
}
以上程序会调用printf打印出8
2.4综合使用
下面从一个语言的的实际出发,写一段代码
int stacklist[100] = {0};
int * intp = &stacklist[0];
void pushint()
{
*intp++ = 1;
*intp++ = 3;
}
void run()
{
int a = *(intp-2);
int b = *(intp-1);
*(intp - 2) = a + b;
intp--;
if (*(intp - 1) > 10)
{
printf(">10");
}
else
{
printf("<10");
}
}
int main(int, char**) {
pushint();
run();
return 1;
}
这个是模拟的了一个栈,然后分别压入两个int数据1,3,然后通过模拟sp指针,将两个数去取出,加在一起,如果结果大于10显示>10 ,小于10就显示<10
首先用内嵌ASM写一次看看
int stacklist[100] = {0};
int * intp = &stacklist[0];
int main(int, char**) {
char * a10 = "<10";
char * b10 = ">10";
_asm {
mov eax, intp
mov[eax], 1
add eax,4
mov[eax],3
add eax,4
mov ecx,dword ptr [eax - 8]
mov edi,dword ptr [eax - 4]
add edi, ecx
mov [eax-8],edi
sub eax,4
mov edi,dword ptr [eax-4]
cmp edi,10
jge l10
push a10
call printf
pop eax
jmp lend
l10:
push b10
call printf
pop eax
lend:
}
}
然后在使用xbyak写一次
int stacklist[100] = { 0 };
int * intp = &stacklist[0];
class generatorcode : public Xbyak::CodeGenerator
{
private:
char * a10 = "<10";
char * b10 = ">10";
public:
generatorcode() : Xbyak::CodeGenerator()
{
}
void endcode()
{
ret();
}
void abc()
{
mov(eax, dword[&intp]);
mov(dword[eax], 1);
add(eax, 4);
mov(dword[eax], 3);
add(eax, 4);
mov(ecx, dword[eax - 8]);
mov(edi, dword[eax - 4]);
add(edi, ecx);
mov(dword[eax - 8], edi);
sub(eax, 4);
mov(edi, dword[eax - 4]);
cmp(edi, 10);
jge(".l10");
push(dword[&a10]);
call(printf);
pop(eax);
jmp(".lend");
L(".l10");
push(dword[&b10]);
call(printf);
pop(eax);
L(".lend");
}
};
int main(int, char**) {
generatorcode g;
g.abc();
g.endcode();
int(*func)() = g.getCode<int(*)()>();
func();
return 1;
}
以上汇编代码仅作演示使用,实际使用中应该尽可能减少使用寄存器,将局部使用的数据存入栈内
可以看出来,写xbyak实际和写汇编几乎一样,除了几条有稍微差别外,写法基本相同,如果是按nasm的写法的话,可能就更接近了
事实上一个编译型语言做成JIT能不能更快,或者快多少,还是要看翻译后的汇编代码量,越少的代码量、越简单的数据类型,运行就会越快










![命令执行绕过 [GXYCTF2019]Ping Ping Ping1](https://img-blog.csdnimg.cn/c4a9c1cb751347df8c54f0de26ebaeaf.png)